






October 26, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Wir sind zurück mit einer weiteren Folge von True ML Talks. Darin tauchen wir tief in die Recommend-API, SlackGPT und LLMs von Slack ein und wir sprechen mit Katrina Ni.
Katrina Ni ist eine leitende ML-Ingenieurin sowie eine leitende Mitarbeiterin des technischen Personals bei Slack. Sie hat dort das ML-Team geleitet und mit der Empfehlungs-API, der Spam-Erkennung, für alle Produktfunktionen gearbeitet.
📌
Unsere Gespräche mit Katrina werden die folgenden Aspekte behandeln:
- Anwendungsfälle von ML und Gen AI bei Slack
- Infrastruktur bei Slack mit Fokus auf ML
- Schulung, Validierung, Bereitstellung und Überwachung der Recommend-API bei Slack
- Messung der geschäftlichen Auswirkungen der Recommend-API
- Auswirkungen des Kundendatenschutzes auf die Trainingsinfrastruktur
- Aufbau von Slack GPT und Herausforderungen bei der Ausbildung von LLMS
- Die Zukunft von Prompt Engineering in Sprachmodellen
- Bleiben Sie über die Fortschritte bei LLMs auf dem Laufenden
Slack stützt sich auf qualifizierte Data-Engineering-Teams und robuste Data-Warehouse-Lösungen. Sie verwenden Airflow für die Auftragsplanung und die Verarbeitung großer Datenmengen und bieten so wichtige Unterstützung bei ML-Aufgaben.
Die Infrastruktur von Slack basiert auf Kubernetes und unterstützt deren Microservices-Architektur. Ihr Cloud-Team entwickelte ein auf Kubernetes basierendes Framework für die einfache Bereitstellung von Microservices, das Flexibilität und Skalierbarkeit bietet.
Um ihren spezifischen Bedürfnissen gerecht zu werden, entwickelte Slack einen maßgeschneiderten Feature-Store, anstatt bestehende Lösungen zu verwenden. Dieser benutzerdefinierte Store verwaltet und nutzt Funktionen für ML-Anwendungen effizient.
Ein engagiertes Team von Slack erstellte eine Orchestrierungsebene auf Kubernetes, um die Bereitstellung von Microservices zu optimieren und in interne Dienste wie die Konsole zu integrieren. Es verbessert zwar die Nutzung von Kubernetes, aber für Anwendungen, die stark von Datenbanken abhängig sind, bestehen nach wie vor Herausforderungen.
In den Anfängen von Slack wurden Anstrengungen unternommen, um effektive Einbettungs- und Fraktionsmechanismen zu entwickeln. Dazu gehörten die Verarbeitung riesiger Datenmengen, um Benutzerinteraktionen zu verstehen und numerische Einbettungen für Benutzer und Kanäle zu generieren. Ein Ergebnis war ein Einbettungsdienst, der auf Nutzeraktivitäten basierte, ein anderes, das auf Nachrichten basierte, obwohl er zu diesem Zeitpunkt noch nicht weit verbreitet war.
Später verlagerte sich der Fokus darauf, diese Einbettungen zu verwenden, um ein benutzerfreundlicheres Produkt zu entwickeln. Es entstand das Konzept der Empfehlungen, bei dem Bereiche identifiziert wurden, in denen die Nutzer von Vorschlägen profitieren könnten, z. B. das Empfehlen von Kanälen oder Nutzern. Dies führte zur Entwicklung der Recommend-API, die in verschiedene Teile der Slack-Plattform integriert war und bestehende Einbettungen nutzte, um relevante Daten auf der Grundlage von Nutzeraktivitäten abzurufen. Die API beinhaltete auch den Feature-Store, bereicherte die Daten mit zusätzlichen Funktionen und wendete Filter- und Bewertungsmechanismen an.
Im Laufe der Entwicklung wurde die Recommend-API in verschiedene Funktionen von Slack integriert, sodass die Plattform ihren Nutzern relevante Kanäle oder Nutzer empfehlen konnte, was deren Nutzererlebnis optimierte und das Engagement steigerte.
Weitere Informationen zu SlackGPT finden Sie im unten angegebenen Blog.
Hier ist ein Bild aus demselben Blog, das einen wirklich guten Überblick über die Recommend-API-Infrastruktur von Slack gibt
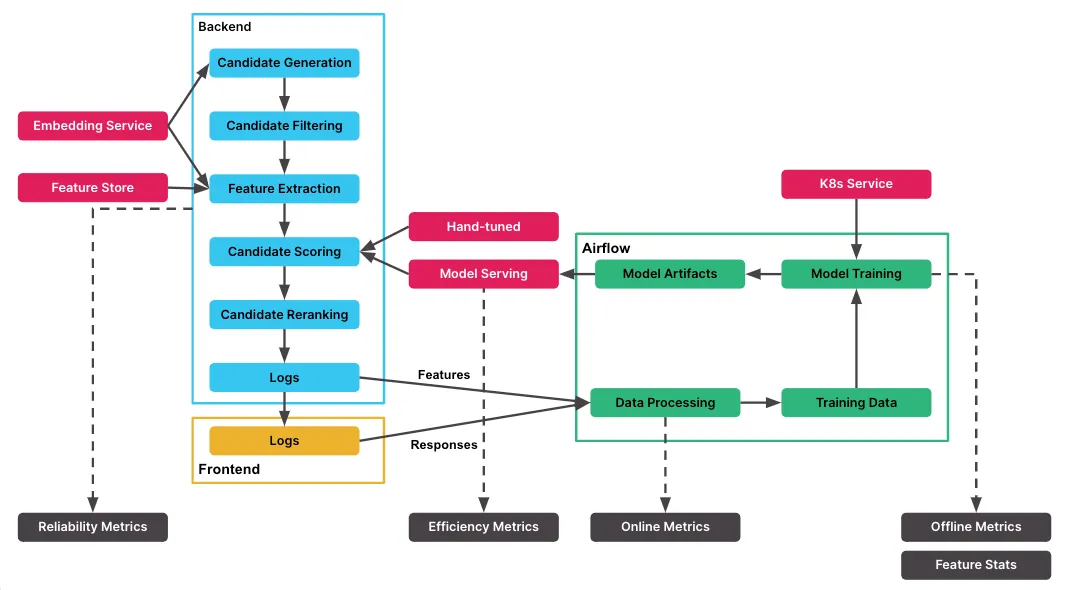
Durch die Nutzung von Kubernetes, Airflow und einem hierarchischen Ansatz für Training und Validierung stellt Slack sicher, dass die Modelle der Recommend-API effektiv und zuverlässig sind, und bietet Nutzern personalisierte Empfehlungen. AB-Tests garantieren eine strenge Bewertung der Modellleistung in einer Online-Umgebung vor der Bereitstellung und tragen so zu einem robusten und datengesteuerten ML-Operations-Framework bei Slack bei.
1. Hierarchisches Korpus und Anwendungsfälle: Die Modelltrainingspipeline bei Slack folgt einem hierarchischen Ansatz. Es beginnt mit einem hierarchischen Korpus, das Kanäle oder Benutzer umfasst. Es gibt mehrere Anwendungsfälle wie Daily Digest, Composer oder Kanalbrowser, die auf bestimmte Funktionen innerhalb von Slack zugeschnitten sind.
2. Modellauswahl und Experimentieren: Für jeden Anwendungsfall werden verschiedene Modelle trainiert und mit ihnen experimentiert, angefangen mit großen Regressionsmodellen bis hin zur Untersuchung anderer Algorithmen wie XGBoost oder LightGBM. Die Modellparameter werden fein abgestimmt, und es wird mit verschiedenen Datenvariationen experimentiert, um das am besten geeignete Modell zu identifizieren.
3. Schulungspipeline mit Kubernetes und Airflow: Die Trainingspipeline wird mithilfe von Kubernetes und Airflow orchestriert. Kubernetes-Cluster erledigen Modelltrainingsaufgaben effizient, wobei Airflow den Arbeitsablauf von der Datenerfassung bis zum Training verschiedener Modelle für verschiedene Anwendungsfälle verwaltet.
4. Protokollierung und Offline-Metriken: Während des Trainings protokolliert das Team Offline-Metriken und Modellparameter für die zukünftige Überwachung und Analyse.
5. Nahtlose Ergänzung und Verwaltung von Modellen: Die Architektur ermöglicht das nahtlose Hinzufügen neuer Quellen oder Modelle für das Training mit minimalen Codeänderungen.
6. Validierung und AB-Tests: Vor der Bereitstellung der Modelle in der Produktion wird eine strenge Validierung durchgeführt. Dabei werden Offline-Metriken wie AUC verglichen, um Modelle zu klassifizieren oder zu bewerten. AB-Tests werden ausgiebig genutzt, um Modelle mit besseren Online-Metriken für den Einsatz auszuwählen.
7. Internes AB-Testframework: Slack verfügt über ein internes AB-Testframework, das vom ML-Team und den Produktteams bei der Einführung neuer Funktionen verwendet wird. Das Framework ermöglicht datengestützte Entscheidungen, indem die Modellleistung anhand verschiedener Geschäftskennzahlen verglichen wird.
Die ML-Modelle von Slack werden in Kubernetes-Clustern bereitgestellt, wobei GRPC als Schnittstelle für die Bearbeitung von Anfragen verwendet wird. GRPC bietet Sicherheit, Effizienz und schnellere Verarbeitung im Vergleich zu JSON-basierten APIs wie FastAPI. Trotz seiner Einschränkungen gewährleistet GRPC eine robuste und effiziente Kommunikation zwischen der API und den Modellen und trägt so zu einem reibungslosen Bereitstellungsprozess bei.
Die Bereitstellungsstrategie beinhaltet die Nutzung der automatischen Skalierungsfunktionen von Kubernetes, sodass Modelle die Ressourcennutzung je nach Bedarf anpassen können. Mit einer riesigen Nutzerbasis verarbeitet Slack eine beträchtliche Anzahl von Anfragen, durchschnittlich etwa 100 Anfragen pro Sekunde.
Die Implementierung von GRPC und die Einrichtung des Servercluster-Microservices erforderten gezielte Anstrengungen, erwiesen sich jedoch als effektiv bei der Skalierung und der Optimierung der Modellleistung.
1. Offline- und Online-Metriken verfolgen: Die Modellüberwachungspipeline von Slack verfolgt effizient Offline- und Online-Metriken. Offline-Metriken wie Genauigkeit, F1 und ROC werden protokolliert, und spezielle Dashboards ermöglichen die Visualisierung. Online-Kennzahlen, einschließlich der Akzeptanzrate, werden ebenfalls über ein separates Dashboard überwacht.
2. Erkennung von Anomalien und Merkmalsdrift: Slack verwendet sein eigenes Framework zur Erkennung von Anomalien, um Funktionsabweichungen zu überwachen. Regelmäßige Umschulungen der Models (tägliche Schulungen und wöchentliche Einsätze) reduzieren die Auswirkungen von Funktionsabweichungen und machen sie weniger besorgniserregend.
3. Automatisierte Umschulungspipeline: Die Umschulungspipeline wird mithilfe von Airflow automatisiert, wodurch sichergestellt wird, dass die Modelle mit den neuesten Daten auf dem neuesten Stand sind.
4. Automatisierte Dashboards für die Visualisierung: Dateningenieure haben benutzerfreundliche Dashboards entwickelt, die die Modellleistung und Metriken visualisieren. Die Dashboards werden automatisch mit neuen Daten aktualisiert, sodass neue Anwendungsfälle leichter verfolgt werden können.
5. Mühelose Integration neuer Anwendungsfälle: Das Hinzufügen neuer Anwendungsfälle zur Überwachungs- und Umschulungspipeline ist dank des automatisierten Integrationsframeworks, das von Dateningenieuren eingerichtet wurde, mühelos.
Durch den Einsatz von Automatisierung und regelmäßigen Schulungen werden die ML-Modelle von Slack kontinuierlich überwacht, optimiert und sind in der Produktion zuverlässig. Das robuste MLOps-Framework trägt zu einer nahtlosen und effizienten Modellbereitstellung für die große Nutzerbasis von Slack bei.
Slack verwendet verschiedene Metriken, um die geschäftlichen Auswirkungen der Recommend-API zu bewerten und so wertvolle Einblicke in deren Leistung und Effektivität zu gewinnen. Die wichtigsten verwendeten Metriken sind:
Durch die Analyse dieser Metriken und die Optimierung der Recommend-API auf der Grundlage von Nutzerfeedback stellt Slack sicher, dass die API das Nutzererlebnis deutlich verbessert, Verbindungen fördert und positive Geschäftsergebnisse innerhalb der Plattform erzielt.
Das Engagement von Slack für den Datenschutz der Kunden hat einen erheblichen Einfluss auf die Architektur und die Datenverarbeitungspraktiken der Trainingsinfrastruktur. Der strenge Fokus auf den Datenschutz spiegelt sich in verschiedenen Aspekten des MLOps-Stacks wider und gewährleistet den sicheren und gesetzeskonformen Umgang mit sensiblen Informationen. So wirkt sich der Datenschutz der Kunden auf die Trainingsinfrastruktur von Slack aus:
Slack führte Slack GPT ein, eine leistungsstarke KI zur Sprachgenerierung für Zusammenfassungen, um der Informationsflut auf der Plattform entgegenzuwirken und die Benutzerproduktivität zu steigern.
Der Aufbau von Slack GPT war mit Herausforderungen verbunden und erforderte Infrastrukturinnovationen für das Training umfangreicher Sprachmodelle. Dazu gehörten die Einrichtung von Clustern, die Verwendung von Kubernetes und die Erforschung paralleler Verarbeitungstechniken. Um die Qualität der Zusammenfassung zu verbessern, führte das Team eine schnelle Optimierung durch und erarbeitete sorgfältig Eingabeaufforderungen, um das Verhalten des Modells zu beeinflussen und kohärente Zusammenfassungen zu generieren.
Eine systematische Bewertung der Prompts war von entscheidender Bedeutung, und das Team entwickelte Tools zur Bewertung der Effektivität von Prompts, sodass mit verschiedenen Prompts experimentiert werden konnte. Die Überbrückung der Lücke zwischen Offline- und Online-Bewertung stellte sicher, dass sich die bei der Offline-Exploration beobachtete Qualität nahtlos auf das Online-Nutzererlebnis übertragen ließ.
Während Slack in KI-Funktionen investiert, spielen ML-Techniker eine zentrale Rolle bei der Optimierung der Benutzererfahrung durch Erkundung, Bewertung und systematische Verbesserung von KI-gesteuerten Funktionen wie Slack GPT.
Weitere Informationen zu SlackGPT finden Sie unter dem folgenden Link.
Prompt Engineering ist für Sprachmodelle von entscheidender Bedeutung und wirkt sich auf die Antwortqualität aus. Derzeit erfordert es Versuch und Irrtum, da es an einem standardisierten Ansatz mangelt. Zu den zukünftigen Möglichkeiten gehören:
Prompt Engineering ist ein aktiv erforschter Bereich, der darauf abzielt, ein Gleichgewicht zwischen manueller Intervention und Automatisierung herzustellen und so die Zukunft der KI-gestützten Kommunikation zu gestalten.
Für Datenwissenschaftler und ML-Ingenieure ist es unerlässlich, über die kontinuierlichen Fortschritte bei großen Sprachmodellen (LLMs) auf dem Laufenden zu bleiben.
Viele Experten in der KI- und NLP-Community nutzen Twitter als wertvolle Plattform, um in Echtzeit auf Informationen über neue Forschungsergebnisse, Modellveröffentlichungen und Durchbrüche im LLM-Bereich zuzugreifen. Wenn sie einflussreichen Forschern und Praktikern auf Twitter folgen, können sie sich schnell über die neuesten Trends und Updates auf diesem Gebiet informieren.
Darüber hinaus bleiben Fachkräfte durch Interaktionen mit ihren Kollegen auf dem Laufenden. Innerhalb ihrer Teams werden wichtige Neuigkeiten, wie die Veröffentlichung von LLMs wie Llama-2 und deren Integration mit Plattformen wie SageMaker, geteilt, wodurch eine kollaborative Lernumgebung geschaffen wird.
Während sich einige Datenwissenschaftler und ML-Ingenieure auf das Lesen von Forschungsarbeiten konzentrieren, priorisieren andere praktische Anwendungsfälle. Sie neigen eher dazu, zu untersuchen, wie sich neue Entwicklungen direkt auf ihre Arbeit auswirken und die Anwendungen von LLMs in realen Szenarien verbessern können.
Schaue weiter TrueML YouTube-Serie und lese das ganze TrueML Blog-Serie.
Wahre Gießerei ist ein ML Deployment PaaS über Kubernetes, um die Workflows von Entwicklern zu beschleunigen und ihnen gleichzeitig volle Flexibilität beim Testen und Bereitstellen von Modellen zu bieten und gleichzeitig die volle Sicherheit und Kontrolle für das Infra-Team zu gewährleisten. Über unsere Plattform ermöglichen wir Teams für maschinelles Lernen bereitstellen und überwachen Modelle innerhalb von 15 Minuten mit 100% iger Zuverlässigkeit, Skalierbarkeit und der Möglichkeit, innerhalb von Sekunden rückgängig zu machen. So können sie Kosten sparen und Modelle schneller für die Produktion freigeben, wodurch ein echter Geschäftswert erzielt wird.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




