

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Kurzversion: Kimi-K2 Thinking (Moonshot AI) ist ein offenes, toolbewusstes „Denkmodell“, das mehrstufiges Denken, eine langfristige Werkzeugorchestrierung und riesige Kontextfenster fördert. Bei Humanity's Last Exam (HLE) und mehreren agentischen Benchmarks erzielt es bundesweit führende Zahlen (insbesondere, wenn der Zugriff auf Tools aktiviert ist). Dies spricht eindeutig dafür, dass die nächste große Herausforderung im Bereich LLMs Denken + Werkzeuge + langer Kontext, nicht nur die Anzahl der Rohparameter.
Benutzen Truefoundry KI-Gateway um es jetzt auszuprobieren.
Benchmarks wie MMLU, Codierungstests und Chat-Benchmarks haben uns viel erzählt, aber sie messen mehrstufiges Denken, Tool-Orchestrierung oder langfristige Planung nicht vollständig. Eine neue Klasse von „Denkmodellen“ trainiert explizit diese Fähigkeiten: Das Modell muss internes, schrittweises Denken mit externen Toolaufrufen (Suche, Code-Interpreter, Surfen im Internet) verknüpfen und die Kohärenz über viele aufeinanderfolgende Schritte hinweg aufrechterhalten.
Kimi-K2 Thinking ist ein Paradebeispiel für diesen Trend. Es ist als agentisches System konzipiert: Es begründet, entscheidet, Tools aufzurufen, nimmt die Tool-Outputs auf und setzt die Argumentation fort — und das alles, während der Kontext über Hunderte von Schritten hinweg beibehalten wird. Das Ergebnis: Erhebliche Gewinne bei Benchmarks wie HLE und BrowseComp, die hart durchdacht sind.
Die wichtigsten technischen Highlights der offiziellen Modellkarte:
Diese Elemente — MoE-Skala, riesiger Kontext, explizite Tool-Orchestrierung und effiziente Low-Bit-Inferenz — sind die Bausteine, die Kimi-K2 eher wie ein Agent als wie ein Konversationstransformator agieren lassen.
Die letzte Prüfung der Menschheit (HLE) soll ein sehr anspruchsvoller Benchmark im Prüfungsstil sein, bei dem echte Argumentation im Vordergrund steht, nicht Abrufen oder Abkürzungen. Es enthält domänenintensive, oft mehrstufige Aufgaben aus Mathematik, Naturwissenschaften, Ingenieurwissenschaften und anderen Fächern. Da HLE-Probleme in der Regel eine mehrstufige Argumentation und in einigen Fällen eine externe Suche oder Berechnung erfordern, ist es ein hervorragender Stresstest für Tools, die einen langen Kontext haben. Bei der Entwicklung von Kimi-K2 standen HLE und andere agentische Benchmarks im Vordergrund — auf der Modellkarte wird HLE als eines der wichtigsten Bewertungsziele hervorgehoben.
Laut den veröffentlichten Bewertungsergebnissen von Moonshot AI:
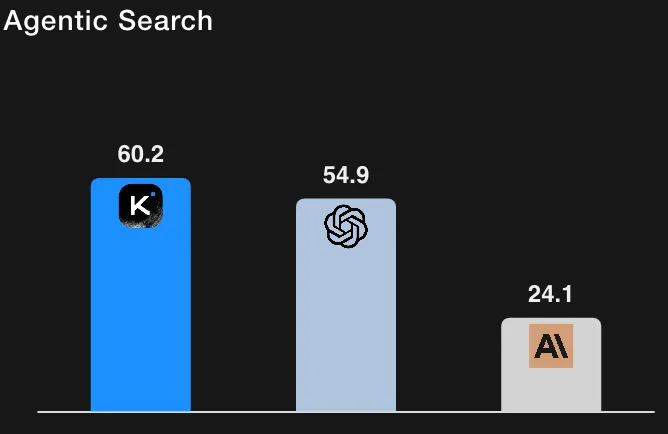
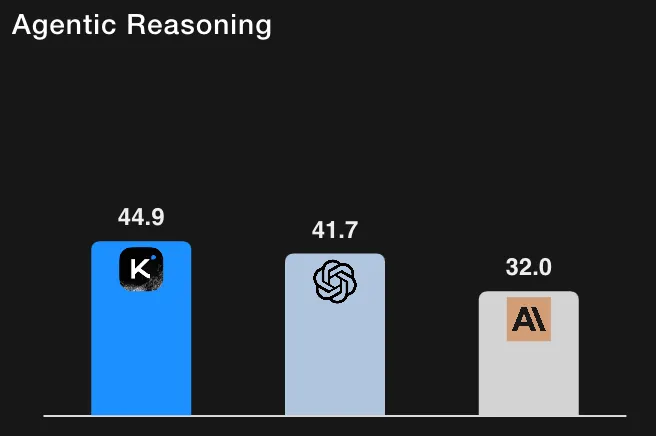
Zum Vergleich: GPT-5 (Hoch) bei HLE mit Tools (deren interne Wiederholungen) bei ~ 41,7% und Claude Sonnet 4,5 bei ~ 32,0% (Denkmodus). Aufgrund der Kimi-K2-Ergebnisse liegt es daher vor den gemeldeten Ausgangswerten für HLE-Läufe mit aktivierten Werkzeugen. (Alle Zahlen stammen aus der Bewertungstabelle und den Fußnoten von Moonshot AI.)
Wichtige Nuance: Die Modellkarte dokumentiert sorgfältig, wie der Zugriff auf Tools, Richtereinstellungen, Token-Budgets und Kontextbeschränkungen gehandhabt wurde. Die Autoren stellen außerdem fest, dass einige Basiszahlen aus offiziellen Posts stammen, während andere intern erneut getestet wurden. Kurzum: Dies sind starke Signale, aber die Leser sollten beachten, dass sie von Moonshot AI gemeldet werden und auf dem detaillierten Bewertungsprotokoll basieren, das mit den Ergebnissen beschrieben wird.
Wir haben 50 Datenzeilen von HLE abgetastet und hier sind die Ergebnisse
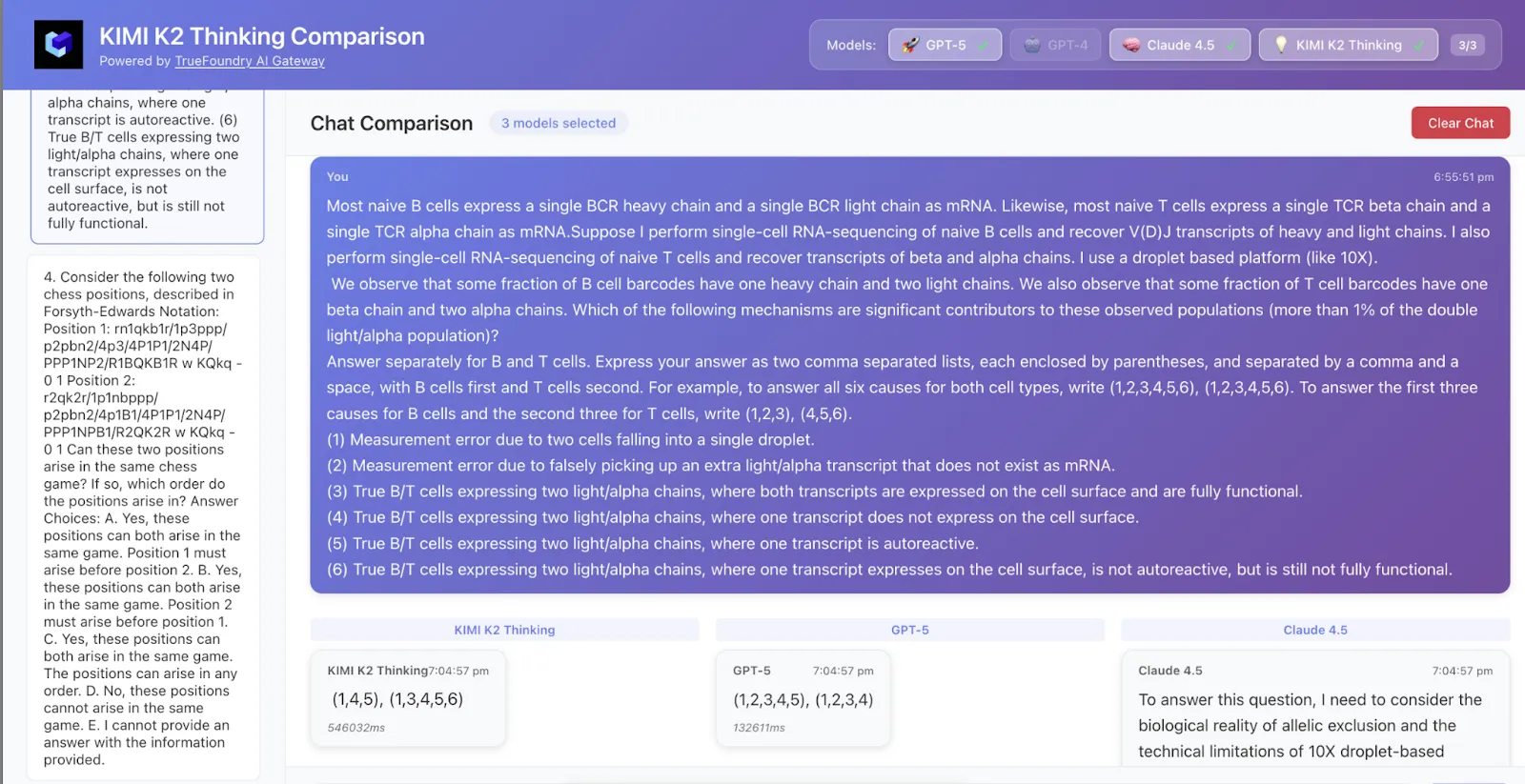
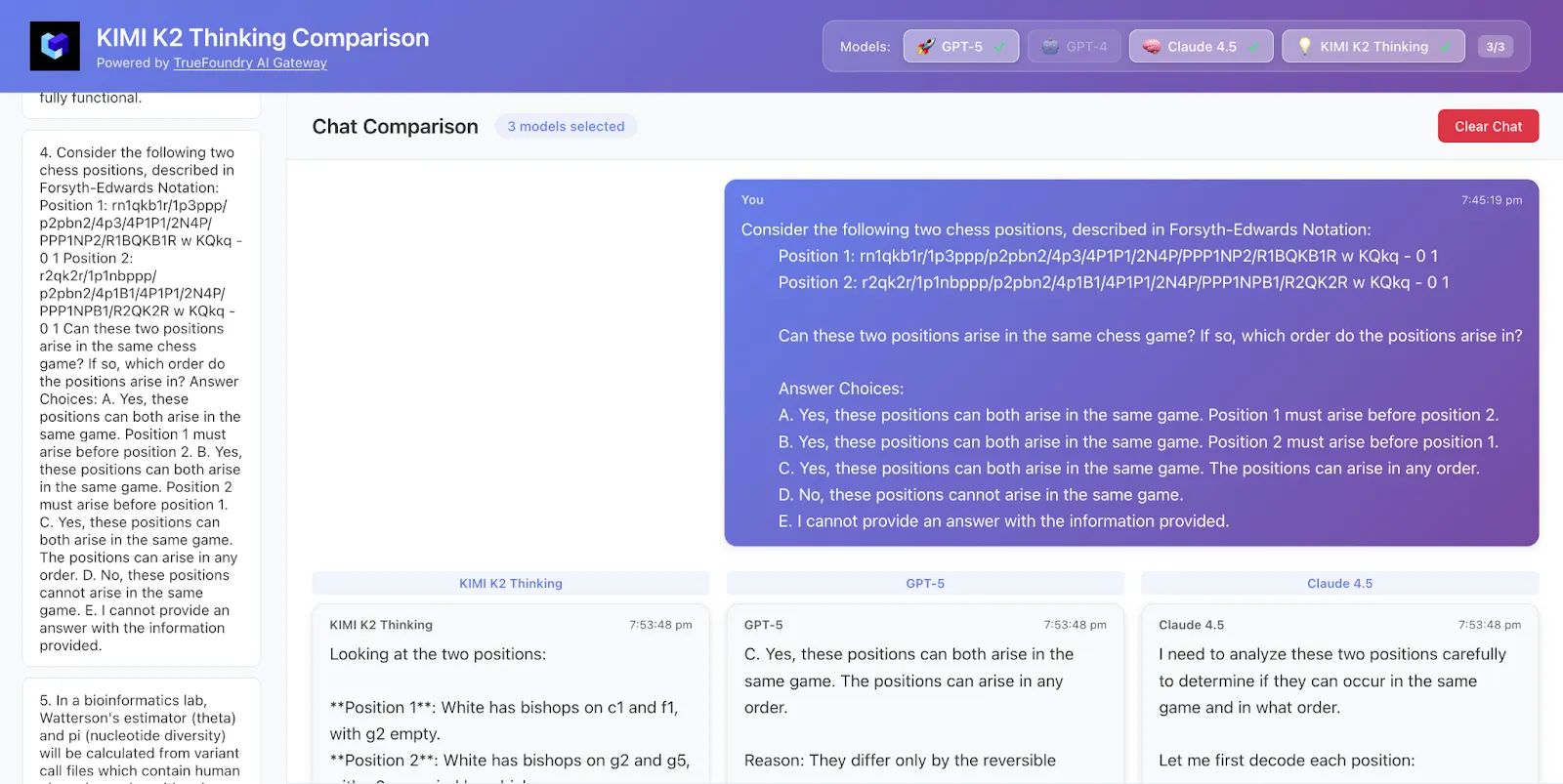
Kimi K2 hat sowohl die Antwort als auch die Logik richtig verstanden, während GPT-5 nur die richtige Antwort erhielt und Claude nicht richtig war.
Kimi-K2 ist ungefähr Verdoppelung der HLE-Leistung ohne Werkzeuge → mit Werkzeugen (≈ 24→ 45%) zeigt einen entscheidenden Punkt:
Einfach ausgedrückt: Die HLE-Gewinne deuten darauf hin, dass das Kernproblem wie Ein Modell begründet und verwendet Werkzeuge, nicht nur die Rohmodellgröße.
Abgesehen von Benchmarks ist es am aufregendsten, wie zugänglich diese Art von Funktionen wird. Sie müssen nicht monatelang warten, um zu experimentieren — du kannst es selbst ausprobieren. TrueFoundry KI-Gateway macht es einfach, direkt auf Kimi-K2 Thinking und andere innovative Modelle zuzugreifen, sie mit Ihren eigenen Daten zu vergleichen oder sie in Workflows zu integrieren.
Wenn Sie mehr persönliche Hilfe wünschen, eine Demo buchen — Das Team kann Ihnen die Leistung, die Einsatzoptionen, die Kosten und die Bewertung dieser Modelle anhand Ihrer Aufgaben erläutern. Wir bleiben auf dem Laufenden über den Markt und stellen sicher, dass neue Modelle so schnell wie möglich für Ihren Verbrauch verfügbar sind.
Fazit: Kimi-K2 Thinking ist nicht nur ein weiteres LLM — es ist ein sichtbarer Einblick in die Zukunft vernünftiger Agenten: offen, effizient, toolbewusst und darauf ausgelegt, Probleme in mehreren Schritten zu lösen. Probieren Sie es aus, vergleichen Sie es anhand Ihrer eigenen Probleme und sehen Sie, wie viel Unterschied die agentische Tool-Orchestrierung bei realen Aufgaben macht.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




