

August 27, 2025
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Die ML-Infrastrukturlandschaft bietet einige der beeindruckendsten Lösungen zur Vereinfachung der ML-Pipeline. TrueFoundry kann eine Lösung sein, wenn Sie sich auf einige der unten genannten Probleme beziehen:
Der Hauptgrund, den wir für Verzögerungen bei den Zeitplänen gefunden haben, ist die Abhängigkeit zwischen den Teams und das Fehlen von Fähigkeiten mit unterschiedlichen Personas. TrueFoundry erleichtert es Datenwissenschaftlern, Kubernetes mithilfe von Python zu trainieren und bereitzustellen. Es ermöglicht Infrastrukturteams auch, Sicherheitsbeschränkungen und Kostenbudgets festzulegen. In den meisten Unternehmen, mit denen wir gesprochen haben, sieht der Implementierungsablauf etwa wie folgt aus:
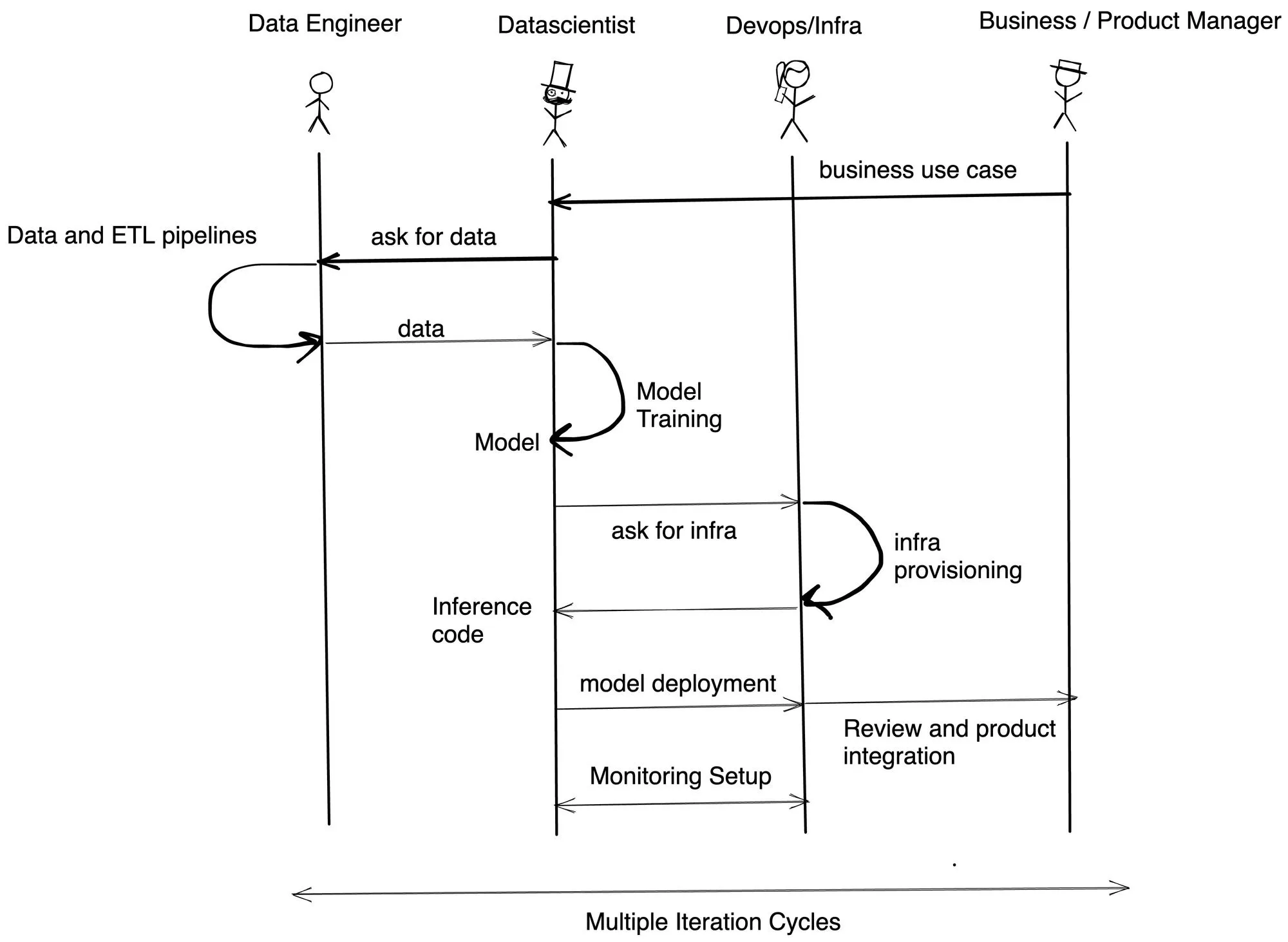
TrueFoundry hilft Ihnen dabei, die Entwicklungszeit um mindestens das Drei- bis Vierfache zu reduzieren, indem Datenwissenschaftler das Modell eigenständig bereitstellen und evaluieren können, ohne sich auf das Infra/DevOps-Team verlassen zu müssen.
Bei TrueFoundry ähnelt der Ablauf dem folgenden:
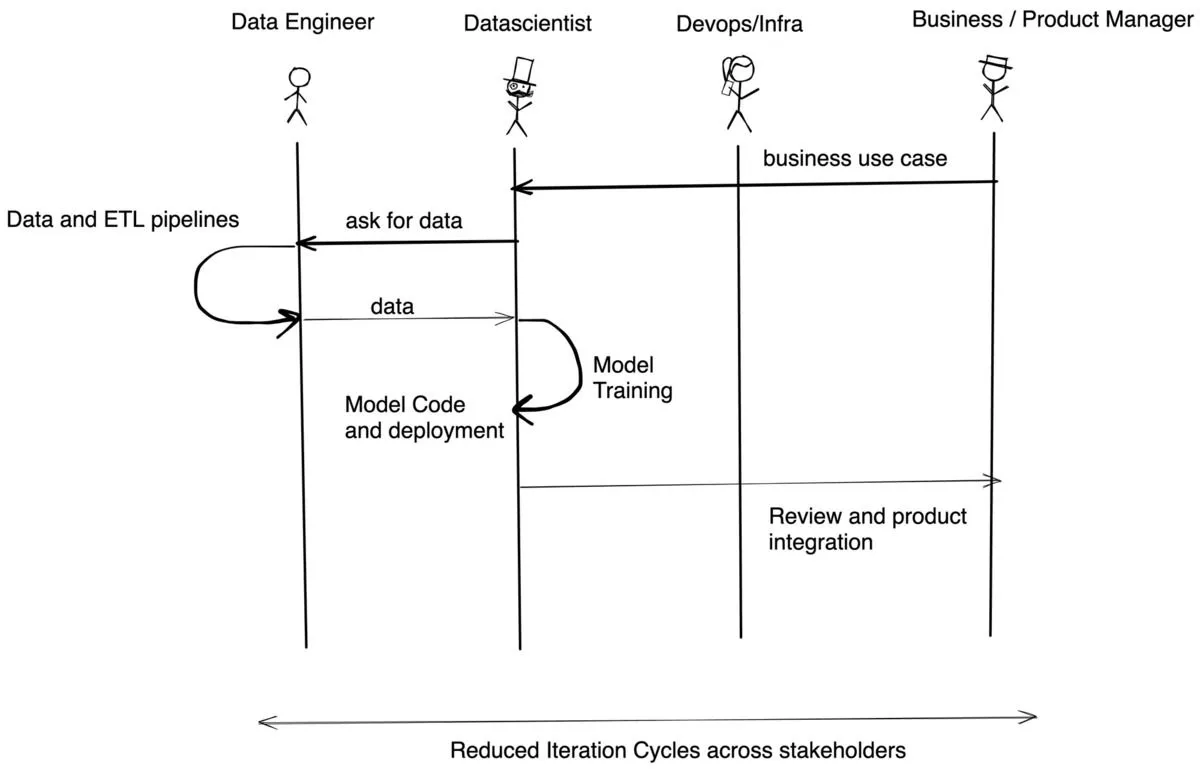
TrueFoundry ist Kubernetes-nativ und funktioniert über EKS-, AKS-, GKE- (Standard- und Autopilot-Cluster) oder lokale Cluster. ML erfordert im Vergleich zur Standard-Softwareinfrastruktur einige benutzerdefinierte Dinge — wie dynamische Knotenbereitstellung, GPU-Unterstützung, Volumes für schnelleren Zugriff, Kostenbudgetierung und Entwicklerautonomie. Wir kümmern uns um alle wichtigen Details in den Clustern, sodass Sie sich auf die Entwicklung der besten Anwendungen mithilfe einer hochmodernen Infrastruktur konzentrieren können.
Wir stellen Python-APIs zur Verfügung — Sie müssen also nie mit YAML interagieren. Wir bieten YAML-Unterstützung auch, wenn Sie ihn in Ihren CI/CD-Pipelines verwenden möchten. Beispielsweise können Sie mit TrueFoundry eine Inferenz-API mithilfe des folgenden Codes bereitstellen:
Dienst = Dienst (
name= „Fastapi“,
image=BUILD (
build_spec=PythonBuild (
command="uvicorn app:app --port 8000 --host 0.0.0.0",
Anforderungen_Pfad=“ requirements.txt „,
)
),
Anschlüsse= [
Hafen (
Anschluss = 8000,
<Provide a host value based on your configured domain>Gastgeber =““
)
],
Resources=Ressourcen (
cpu_request=0,5,
CPU-Limit = 1,
Speicheranforderung = 1000,
Speicherlimit = 1500
),
env= {
„UVICORN_WEB_CONCURRENCY“: „1",
„UMGEBUNG“: „dev“
}
)
service.deploy (workspace_fqn="tfy-cluster/mein-workspace“)
TrueFoundry wird vollständig auf Ihrem eigenen Kubernetes-Cluster bereitgestellt. Die Daten bleiben in Ihrer eigenen VPC, Docker-Images werden in Ihrer eigenen Docker-Registry gespeichert und alle Modelle verbleiben in Ihrem eigenen Blob-Speichersystem. Sie können mehr über die TrueFoundry-Architektur lesen hier.
Kubernetes unterstützt in der Regel Autoscaling mithilfe von HPA auf Basis von CPU und Arbeitsspeicher. Bei ML-Workloads ist die automatische Skalierung auf der Grundlage der Anzahl der Anfragen jedoch in vielen Fällen viel besser. Eine weitere Herausforderung beim Autoscaling kann die hohe Startzeit von Modellen sein, die auf große Bildgrößen und Modell-Downloadzeiten zurückzuführen ist. Truefoundry löst diese Probleme, indem es die Startzeit von Containern in Sekunden, das Zwischenspeichern von Modellen für ein schnelleres Laden und schnellere Inferenzzeiten ermöglicht.
Können wir einige Open-Source-LLM-Modelle verwenden?
Mit TrueFoundry können Sie die Open-Source-LLMs auf Ihrer eigenen Infrastruktur bereitstellen und optimieren. Wir haben bereits die besten Einstellungen für die gängigsten Open-Source-Modelle herausgefunden, sodass Sie sie mit den optimalen Einstellungen und den niedrigsten Kosten trainieren und bereitstellen können.
Wir hosten einen internen LLM-Spielplatz, auf dem Sie entscheiden können, welche LLMs Sie für die Unternehmensentwickler auf die Whitelist setzen möchten, einschließlich intern gehosteter, und verschiedene Entwickler können mit den internen Daten experimentieren. Hier ist ein kurzes Video dazu:
Jupyter Notebooks sind für den täglichen Entwicklungszyklus von Data Scientists unverzichtbar. Jupyter Notebooks lokal auf dem eigenen Computer auszuführen, ist aus den folgenden Gründen nicht immer eine Option:
Wir haben große Anstrengungen unternommen, um Jupyter Notebooks reibungslos auf Kubernetes auszuführen. Jupyter-Notebooks auf TrueFoundry bieten im Vergleich zu JupyterLab- oder Kubeflow-Notebooks die folgenden Vorteile:
TrueFoundry bietet eine Modellregistrierung, die verfolgen kann, welche Modelle sich in welcher Phase befinden, sowie das Schema und die API aller Modelle in der Registrierung.
TrueFoundry ermöglicht das Aufteilen oder Spiegeln des Datenverkehrs von einem Modell auf ein anderes. Dies ist besonders nützlich, wenn Sie eine neue Modellversion einige Zeit im Live-Verkehr testen möchten, bevor Sie sie in die Produktion überführen. Truefoundry unterstützt auch die Rollout-Strategien Canary und Blue-Green bei der Modellbereitstellung.
Wir haben große Anstrengungen unternommen, um sicherzustellen, dass wir uns um die grundlegenden Unterschiede der Kubernetes-Cluster zwischen den Clouds kümmern. Entwickler können denselben Code in jeder Umgebung schreiben und bereitstellen, ohne sich Gedanken über die zugrunde liegende Infrastruktur machen zu müssen. Wir überprüfen, ob die zugrunde liegenden Komponenten von Kubernetes installiert sind, überprüfen inkompatible Migrationen und informieren die Entwickler entsprechend.
Wir machen Entwicklern die Kostentransparenz von Dienstleistungen zugänglich und bieten Einblicke, um die Kosten zu senken. Alle unsere aktuellen Kunden konnten nach der Einführung von TrueFoundry eine Kostensenkung von mindestens 30% verzeichnen.
Wahre Gießerei ist ein ML Deployment (PaaS over Kubernetes), das zur Vereinfachung entwickelt wurde Einsatz von KI-Modellen, beschleunigen die Arbeitsabläufe der Entwickler und behalten die volle Kontrolle über die Infrastruktur. Über unsere Plattform ermöglichen wir Teams für maschinelles Lernen bereitstellen und überwachen Modelle innerhalb von 15 Minuten mit 100% iger Zuverlässigkeit, Skalierbarkeit und der Möglichkeit, innerhalb von Sekunden rückgängig zu machen. So können sie Kosten sparen und Modelle schneller für die Produktion freigeben, wodurch ein echter Geschäftswert erzielt wird.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




