Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.
9,9
Gemini 3 gegen Kimi-K2 Thinking gegen Grok-4.1 gegen GPT-5.1: Wer gewinnt eigentlich die letzte Prüfung der Menschheit?
Published: April 22, 2026
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Verarbeitet mehr als 350 RPS auf nur 1 vCPU — kein Tuning erforderlich
Wenn Google sagt „Alles planen“ mit Gemini 3 behauptet Moonshot, Kimi-K2 Thinking sei das neue Argumentation SOTA, Xai nennt Grok-4 „das intelligenteste Modell der Welt“, und OpenAI treibt GPT-5.1 weiter voran. Es ist schwer zu wissen, was real ist und was nur Vibes sind.
Anstelle einer weiteren Mauer von Benchmark-Charts ist hier eine engere Frage:
Was passiert, wenn Sie Gemini 3, Kimi-K2 Thinking, Grok-4.1 und GPT-5.1 denselben Problemen im Stil von Humanity's Last Exam unterziehen und tatsächlich zuschauen? wie denken sie?
In diesem Beitrag:
Warum Die letzte Prüfung der Menschheit (HLE) ist zum „Endboss“ der akademischen Benchmarks geworden.
Ein kurzer Rundgang durch Gemini 3, Kimi-K2 Thinking, Grok-4.1 und GPT-5.1 als „denkende“ Modelle.
Fünf konkrete Fallstudien im HLE-Stil in den Bereichen Mathematik, multimodale Physik, Wissenschaft mit langen Kontexten, Spieltheorie und Planung.
Wie führe die gleichen Experimente selbst durch über das TrueFoundry AI Gateway.
1. Die letzte Prüfung der Menschheit in 2 Minuten
Benchmarks wie MMLU werden im Grunde an der Grenze „fertig“. Viele Topmodelle liegen dort über 90%, daher sagt ein anderes Modell mit +1 oder − 1% nicht viel darüber aus, wie es ist, tatsächlich damit zu arbeiten.
Die letzte Prüfung der Menschheit (HLE) ist anders:
Es ist eine von Experten kuratierte Prüfung für Mathematik, Naturwissenschaften, Ingenieurwesen, Wirtschaftswissenschaften, Geisteswissenschaften, Recht und mehr.
Es mischt Mehrfachauswahl und Exact-Match Fragen, von denen viele erfordern mehrere nicht offensichtliche Argumentationsschritte.
Ein Teil der Fragen ist multimodale, was die Modelle zwingt, gemeinsam über Text und Bilder nachzudenken.
Entscheidend ist, dass selbst die besten Modelle heute noch weit entfernt von menschlichem Expertenniveau auf HLE, und ihr Selbstvertrauen ist oft schlecht kalibriert.
Die Autoren fragen explizit die Leute die Rohfragen nicht erneut zu veröffentlichen, weil sie wollen, dass HLE ein nützlicher langfristiger Benchmark bleibt. Also in diesem Beitrag:
Wir nicht anzeigen der ursprüngliche Wortlaut einer Frage.
Stattdessen beschreiben wir fünf repräsentative Aufgaben im „HLE-Stil“ und wie sich die Models auf ihnen verhalten.
Sie können diese Muster selbst reproduzieren, indem Sie den öffentlichen HLE-Datensatz oder ähnliche Probleme aus Ihrer eigenen Domain verwenden.
2. Vier „denkende“ Modelle im Jahr 2025
Wir vergleichen hier keine „Chatbots“, wir schauen uns Models an, die explizit als Begründer: tiefe Gedankenkette, Tools, langer Kontext, Planung.
Gemini 3 (Pro + Deep Think)
Google präsentiert Zwillinge 3 als sein bisher leistungsfähigstes Modell:
Stärker Argumentation und multimodales Verständnis als die Gemini 2.5-Generation.
Konkurrenzfähige Ergebnisse bei HLE ohne Tools sowie hervorragende Leistung bei GPQA, MMMU-Pro, Video-MMMU und anderen Argumentationsbenchmarks.
Ein großer Fokus auf Agenten mit langfristigem Horizont, die Tools aufrufen: Die Geschichte „alles planen“, einschließlich der besten Ergebnisse bei Planungsbenchmarks wie Vending-Bench.
Gemini 3 enthüllt auch eine Tiefes Nachdenken Modus, der mehr Rechenleistung und Token für schwierige Probleme ausgibt, um etwas mehr Genauigkeit herauszuholen.
Kimi-K2-Denken
Moonshots Kimi-K2-Denken ist ein Modell des „Denkens“ mit offenem Gewicht:
Architektur aus einer Mischung von Experten mit einem riesigen Gesamtparameterbudget, aber einer kleineren aktiven Teilmenge pro Token.
Langer Kontext (Hunderttausende von Tokens) und sehr schwerer Gedankengang von Design.
Öffentliche Analysen zeigen oft, dass Kimi-K2 Thinking und seine „Heavy“ -Variante bei HLE und anderen Argumentationsbenchmarks ganz oben oder nahe an der Spitze stehen.
Wenn Sie jemals gesehen haben, dass ein Modell herausläuft Seiten des internen Monologs für eine mathematische Aufgabe: Das ist die Ästhetik im Kimi-Stil.
Grok-4//Grok-4.1
Axis Grok-4 Die Zeile hat folgende Tonhöhe:
Ein sehr leistungsfähiger Argumentation Modell mit nativer Toolnutzung und Internetsuche.
Stark bei HLE-, GPQA- und langfristigen Aufgaben, bei denen Agenten ein kohärentes Verhalten über viele Schritte hinweg beibehalten müssen.
Grok-4.1 konzentriert sich stärker auf „emotionale“ und kreative Intelligenz, behält aber dennoch die zentrale Argumentationsstärke bei.
Stellen Sie sich GROK-4.x als das Modell vor, das wirklich ein Agentin: planen, suchen, handeln, reflektieren, wiederholen.
GPT-5.1 (GPT-5-Familie)
OpenAIs GPT-5 Familie ist die Grundlage, nach der die meisten Menschen streben:
Sehr stark in breiten Benchmark-Suiten: Codierung, Argumentation, multimodaler, langer Kontext.
Wenn ich in einem hoher „Denkaufwand“/„Denkmodus“, es weist mehr Token auf und berechnet schwierige Probleme und neigt dazu, die Lücke zu fortgeschrittenen Benchmarks wie HLE und GPQA zu schließen.
Wir beziehen uns auf GPT-5.1 Thinking as GPT-5-variant, that runs in this high performance profile.
3. Wie wir sie verglichen haben (ohne dass HLE durchsickert)
Das Ziel hier war nicht, eine weitere Bestenliste aufzubauen, sondern zu sehen wie This models verhalten sich bei Aufgaben im HLE-Stil.
Auf hohem Niveau:
We have selected a series of repräsentative HLE-Fragen (Mathematik, multimodale Physik, lange naturwissenschaftliche Passagen, Spieltheorie, Planung).
Für jede Frage verwendeten wir eine konsistente Eingabeaufforderung „Prüfungsmodus“:
„Vernunft Schritt für Schritt. “
„Erkläre dein Denken. “
„Ende mit endgültiger Antwort:... und Zuversicht: ... “
Wir haben genau die gleiche Frage und das gleiche Gerüst gestellt:
Kimi-K2-Thinking
Grok-4.1
GPT-5.1 Thinking
Gemini 3 Pro (und wo verfügbar, Gemini 3 Deep Think)
All dies wurde durch die verkabelt TrueFoundry KI-Gateway:
Ein Endpunkt, an den wir OpenAI, Google, Xai, Moonshot und über 1000 andere Modelle anschließen.
A location to protokollieren of responses, tokens, latency and costs per call.
Eine Reihe von Authentifizierungen, Kontingenten und Leitplanken für alle Anbieter.
To later more — we show us first the five case studies.
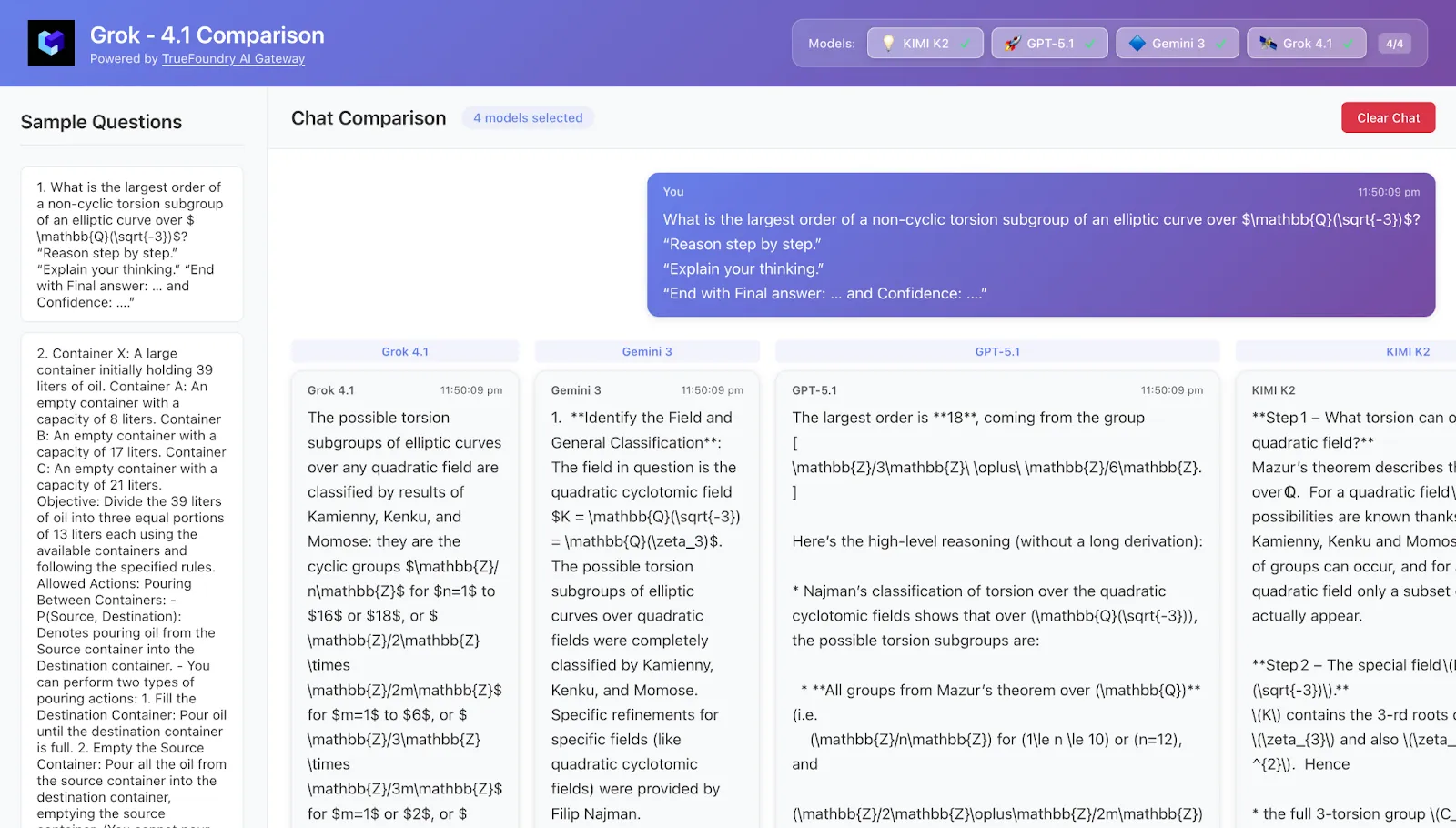
4. Fallstudie 1 — Tiefgründiges Rechnen: Genauigkeit versus tokenhungriges Denken
Question Eine mathematische Aufgabe für Hochschulabsolventen (denken Sie an Zahlentheorie/Kombinatorik):
Einzelne kurze Antwort (eine Ganzzahl oder ein einfacher Ausdruck).
Benötigt ~4—6 non-offensive Argumentation Steps.
Sehr schwer richtig zu erraten, ohne wirklich durchzuarbeiten.
What we view us
Hat das Modell Richten Sie die Struktur ein richtig (z. B. richtiger Theorem/Klassifikation)?
Führt die Argumentation zu Ende, ohne ein Minuszeichen zu verlieren?
Wie viele Spielmarken es brennt, dorthin gelangen?
• Wein kalibriert ist sein Vertrauen?
Typisches beobachtetes Muster
Kimi-K2-Thinking
Extrem langer Gedankengang: erinnert an relevante Theoreme, untersucht mehrere mögliche Ansätze, oft Verzweigungen und Rückschritte.
Sehr stark in Bezug auf Genauigkeit, besonders im Modus „Schwer“, gibt aber oft deutlich mehr Tokens als andere.
Selbst bei sehr heiklen Problemen liegt das Selbstbewusstsein häufig bei 90— 100%.
Grok-4.1
Mutig und explorativ: skizziert schnell eine intuitive Antwort und versucht dann, sie zu rechtfertigen.
Wenn es richtig ist, sieht es brillant aus; wenn es falsch ist, kann es sein sehr selbstbewusst.
GPT-5.1 Thinking
Gute Struktur: zählt übersichtlich auf, kennzeichnet sie und weist sauber auf sie zurück.
Oftmals sind die Vertrauensschätzungen etwas bescheidener, insbesondere wenn das Problem mehrere tiefgründige Fakten erfordert.
Gemini 3 (Profi/Deep Think)
Mehrstufiges Denken, aber merklich prägnanter als die Textwände von Kimi-K2.
The Deep Think mode includes a major of the HLE gap to Kimi/Grok, but in his reasons something major.
Essen zum Mitnehmen Wenn du jagst jeder zusätzliche Punkt Kimi-K2 Thinking and GROK-4.x as the market leader, gefolgt von Gemini 3 Deep Think. Wenn es dich interessiert Costs and speed Gemini 3 and GPT-5.1 Thinking are not only in bezug auf die reine Genauigkeit, sondern auch attraktiv, weil sie ähnliche Ergebnisse erzielen und gleichzeitig weniger tokenhungrig sind.
5. Fallstudie 2 — Multimodale Physik: „Schau dir das Diagramm an“
Question Eine diagrammlastige physikalisch-technische Frage:
Ein Schaltplan, ein Freikörperdiagramm oder ein optischer Aufbau wird als Bild eingebettet.
Die Frage verlangt nach einer numerischen Antwort (z. B. Strom, Winkel, Zeit).
Du kannst nicht richtig antworten ohne Analysieren Sie die Abbildung richtig.
What we view us
Hat das Modell beschreiben das Diagramm ist also, dass das Bild entspricht?
Macht es Annonahmen nicht vorhanden auf dem Bild?
Wie gut kombiniert es Bild und Text zu einer kohärenten Leitung?
Typisches beobachtetes Muster
Zwillinge 3
Ganz bewusst mit dem Bild selbst: „Der Pfeil zeigt nach links“, „es gibt drei Widerstände hintereinander“, „die Masse wird durch zwei Federn befestigt“.
Weniger Halluzinationen über den Inhalt des Diagramms.
Insgesamt fühlt es sich an und wie am meisten geerdet in seiner multimodalen Argumentation.
GPT-5.1 Thinking
Starkes multimodales Verständnis, aber oft weniger explizit: Es verwendet das Diagramm korrekt, beschreibt es jedoch nicht immer im Detail.
Wenn es fehlschlägt, liegt es normalerweise daran, dass der Text falsch gelesen wurde und nicht das Bild.
Kimi-K2-Thinking
Sobald die Gegebenheiten stimmen, ist die Physik solide.
Under pressure can but to count elements in the chart (z. B. the number of components) and this error then to a very long line.
Grok-4.1
I'm style similar like GPT-5.1: intuitiv, oft richtig, aber gelegentlich zu selbstbewusst bei einer falsch interpretierten Zeile oder Bezeichnung.
Essen zum Mitnehmen When a major your work last in the HLE style following Charts, Schaltpläne or visual rätsel, Der multimodale Stack von Gemini 3 ist herausragend. GPT-5.1, Kimi-K2 und Grok-4.1 sind alle leistungsfähig, neigen aber dazu, Details zu „sehen“, die nicht ganz da sind.
6. Fallstudie 3 — Wissenschaft mit langem Kontext: Lesen, nicht nur lösen
Question Eine lange, dichte Wissenschaftspassage (Biologie/ Medizin/ Chemie):
Multiple absätze, the a experiment, methods, results and vorbehalte.
Dann eine Frage, die erfordert Integration von Information in der gesamten Passage, nicht nur der letzte Absatz.
What we view us
Hat das Modell zusammenfassen die Passage richtig?
Bet es the Overview Variabels, Conditions and Exceptions absatzübergreifend?
Identifiziert es richtig, welche Details eigentlich wichtig um die Frage zu beantworten?
Typisches beobachtetes Muster
Zwillinge 3
Gut darin, lange Passagen komprimieren laserfokussierte Aufzählungspunkte.
Delikt dazu, wichtige Fakten neu formulieren und dann „aus den Anmerkungen“ zur Antwort argumentieren.
Widerspricht selbst selten, wenn auf frühere Teile der Passage Bezug genommen wird.
GPT-5.1 Thinking
Hervorragend im Verfolgen von Variablen und Versuchsaufbauten; fühlt sich an wie ein vorsichtiger TA.
Oft die sauberste „Lesen → Zusammenfassen → Ableiten“ -Pipeline.
Kimi-K2-Thinking
Sehr detailliert: wiederholt einen Großteil der Passage und leitet manchmal die Hintergrundtheorie neu ab.
This depth is useful, but because of the bloss length can some sometimes deviation or internal widersprüche.
Grok-4.1
Sehr gut beim Ausextrahieren praktische Implikationen („This deutet darauf hin, dass Treatment A vorzuziehen ist, wenn...“).
Beschönigt manchmal seltene Randfälle, die im Text erwähnt werden.
Essen zum Mitnehmen Für HLE-Stil „lies das und verstehe es tatsächlich“ Questions, Gemini 3 and GPT-5.1 Thinking are especially strong: they fassen knackig zusammen, bewahren wichtige Details und halten die Logik klar. Kimi-K2 and Grok-4.1 are also performance able, but their longer reports offer more possibilities to drive.
7. Fallstudie 4 — Spieltheorie und Mikroökonomie: Wer argumentiert wie ein TA?
Question Eine Frage zur Mikroökonomie/Spieltheorie:
Mehrere Spieler, ein kleines Action-Set und Auszahlungsbeschreibungen.
You are required to find equal weight, strategies to charactering or comparar welfare results.
What we view us
Hat das Modell zähle alle relevanten Fälle?
Hält es die Logik der Fallanalyse bis zur endgültigen Antwort konsistent?
Ist es bewusst, Feinheiten wie gemischte Strategien, Dominanz oder Symmetrie?
Typisches beobachtetes Muster
Kimi-K2-Thinking
Liest dich wie ein Masterstudent: many individual analysis, explizite Konstruktion von Gegenbeispielen, sorgfältige Abwägung von Randfällen.
Sehr stark, wenn sie den gesamten Argumentationsbaum sehen möchten.
Grok-4.1
Intuitiv ausgezeichnet bei Gründung von Anreizen („Wenn Spieler A abweicht, gewinnt er X, das kann auch kein Gleichgewicht sein“).
Manchmal kommt es früh zu einem intuitiven Gleichgewicht und muss zum Umdenken angestoßen werden.
GPT-5.1 Thinking
Systematisch: zeichnet Fälle auf (Fall 1, Fall 2,...), fasst die Ergebnisse zusammen und verknüpft sie reibungslos.
Gute Balance zwischen Tiefe und Kürze.
Zwillinge 3
Ähnlich wie GPT-5.1 aufgebaut, mit einer etwas starken Tendenz, explizit zurückzugehen („Lass uns die Annahme überdenken, dass...“), insbesondere in einem Modus im Deep Think-Stil.
Essen zum Mitnehmen Zu spieltheoretischen HLE-Fragen Kimi-K2-Thinking und Grok-4.1 I feel an a personal teacher assistant in next: much explizite fallwork and intuitive discussion. Zwillinge 3 und GPT-5.1 Sie kommen mit weniger Umherirren zur Antwort, was vorzuziehen ist, wenn Sie Ausgaben direkt in Code- oder Entscheidungspipelines weiterleiten.
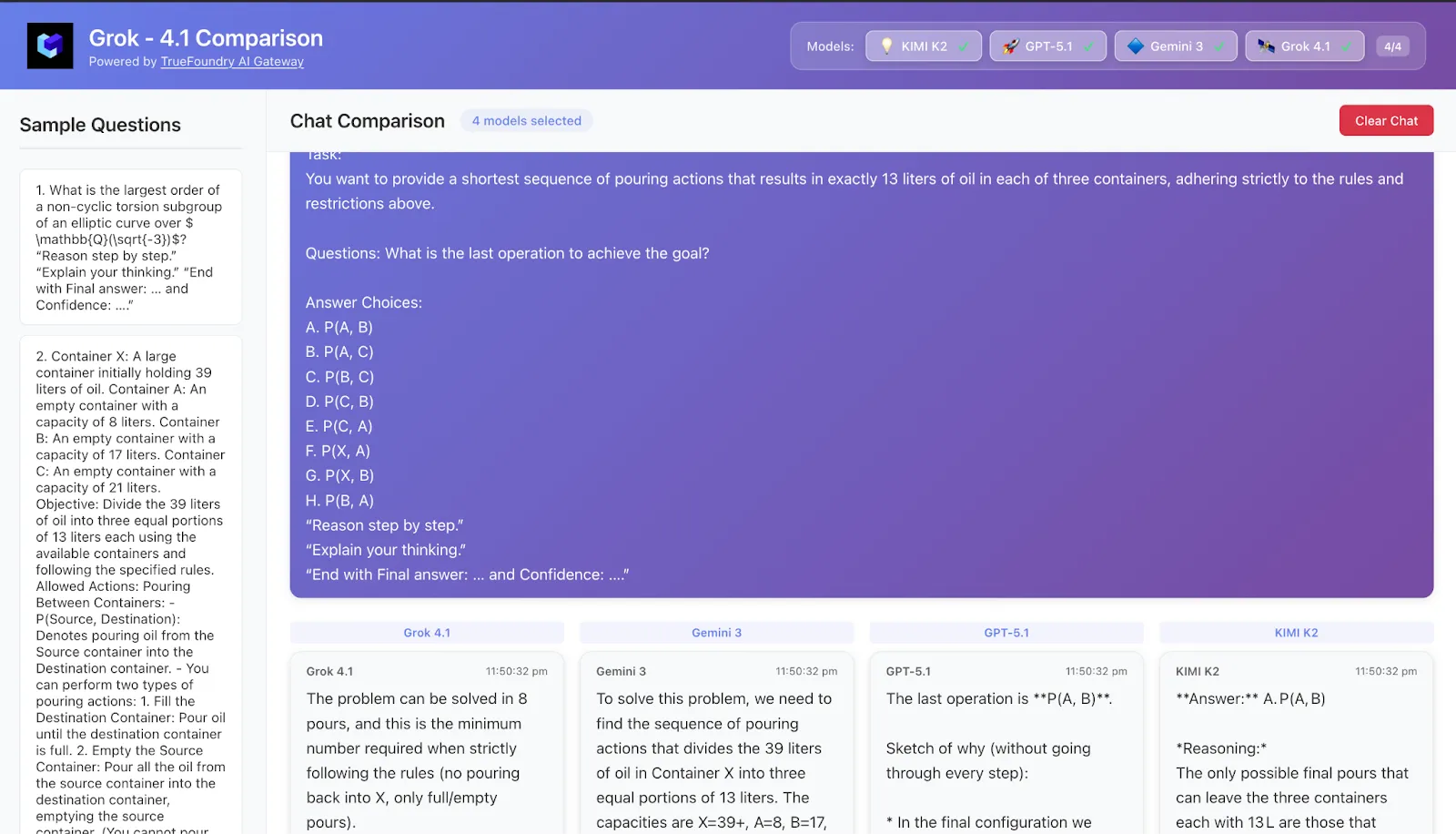
8. Fallstudie 5 — Planungsprobleme: Mini-Agenten innerhalb einer Eingabeaufforderung
Question Ein Puzzle im Stil von Planung und Operations Research:
Multiple container, capacity and gieß rules or an planning and management facility.
Sie müssen eine Richtlinie oder eine Folge von Aktionen auswählen, mit denen ein Ziel erreicht wird minimale Schritte under einschränkungen.
What we view us
Hat das Modell richte den Zustandsraum ein eindeutig?
Simuliert Sequenzen korrekt, ohne frühere Aktionen zu vergessen?
Hält es an den Einschränkungen, die es selbst festgelegt hat?
Typisches beobachtetes Muster
Grok-4.1
Sehr agentenähnlich: schreibt explizit Status aus („Nach Schritt 3: Inventar ist X, Y, Z“), vergleiche alles mit dem Ziel und korrigiert den Kurs bei Bedarf.
Fühlt sich am ehesten an, als ob man einen echten Planungsagenten innerhalb einer einzigen Eingabeaufforderung verwenden würde.
Zwillinge 3
Similar planning style: repeated the goal and the einschränkungen, is an policy before and simulated then several stages.
Sehr gut bei den Überblick nicht verlieren The condition over longer sequence hinweg, was good to his tonheight with longer horizont/Vending-Bank.
GPT-5.1 Thinking
Gute konzeptionelle Planung, aber in vielen Schritten anfälliger für kleine Rechen- oder Buchhaltungsfehler.
Wenn gefragt wird, ob die „kürzeste Sequenz“ garantiert werden soll, ist manchmal ein zweiter Versuch erforderlich.
Kimi-K2-Thinking
Bietet viele detaillierte Simulationen, aber die Kombination aus langem CoT und komplexem Zustand führt manchmal zu kleinen Inkonsistenzen (z. B. eine Menge, die sich nicht zwischen den Schritten ändert).
Essen zum Mitnehmen Bei HLE-tasks with planning geschmack Grok-4.1 und Zwillinge 3 fühle mich wie die zuverlässigsten Mini-Agenten. Kimi-K2 and GPT-5.1 sind sehr leistungsfähig, aber ihre langen Denkprozesse können ihnen manchmal widerstehen, wenn die Zustandsverfolgung entscheidend ist.
9. Ebenfalls... wer „gewinnt“ die letzte Prüfung der Menschheit?
Wenn du nur ansiehst HLE-Schlagzeilenprozentsätze, Kimi-K2 Thinking (especially Heavy-Variants) and some Grok-4-Configurations are currently an or in the area of the tip, with Gemini 3 Deep Think dicht dahinter und GPT-5 Pro einen Tick tiefer.
Aber HLE ist auf der besten Art chaotisch:
Die Genauigkeit liegt immer noch weit unter menschlichen Experten.
Vertrauen ist oft falsch kalibriert: Modelle können sehr sicher und sehr falsch.
Verschiedene Bereiche anzeigen (Mathematik gegen Naturwissenschaften gegen Planung gegen Geisteswissenschaften) verschiedene Gewinner.
Aus den fünf Fallstudien:
Kimi-K2-Thinking
Am besten, wenn du willst maximale Tiefe and feel it well to take token and latence, to get the last part performance.
Grok-4.1
Leuchtet weiter planning and agentenähnliches Denken; wenn Ihre Aufgaben wie Simulationen oder mehrstufige Geschäftsentscheidungen erscheinen, fühlt sich Grok sehr natürlich an.
GPT-5.1 Thinking
Eine starke, sichere Standardeinstellung: hervorragende Lesbarkeit langer Kontexte, allgemein saubere Struktur und sehr einfache Integration in bestehende Systeme.
Gemini 3 (Pro + Deep Think)
Besonders überzeugend auf multimodales Denken, strukturiertes Leseverständnis, und Planning — and the pitch „Alles planen“ is not only marketing, he shows also there, how long, statusbehaftete problems be solved.
Es gibt keinen einzigen Gewinner für Humanity's Last Exam. Das „beste“ Modell ist das, das scheitert am wenigsten schlimm on your actual tasks, under your actual einschränkungen.
10. Wie haben wir das über TrueFoundry AI Gateway ausgeführt
Unter der Haube haben wir keine vier separaten Integrationen gebaut. Alles ging durch die TrueFoundry KI-Gateway (truefoundry.com/ai-gateway):
Ein Endpunkt for OpenAI (GPT-5.1), Google (Gemini 3), xAI (GROK-4.x), Moonshot (Kimi-K2) and hunderte other models.
zentralisiert Observability: Logs for Request, Responses, Token, Latenz and error between providers.
Eingebaut Administration and Safety: RBAC, Auditprotokolle und Bereitstellungsoptionen, mit denen Daten in Ihrer Cloud oder vor Ort gespeichert werden.
Auf der Experimentierseite bedeutete das:
We have our test gurt once with the gateway.
We have gpt-5.1-thinking, kimi-k2-thinking, grok-4.1, gemini-3-pro and gemini-3-deep-Think als einfach registriert verschiedene Modell-IDs.
The exchange between them was a einzeilige configuration change, no new SDK integration.
11. Probiere Gemini 3 (und den Rest) bei deiner eigenen „letzten Prüfung“ aus
Wenn du das Muster in diesem Beitrag reproduzieren (oder herausfordern) möchtest:
Wähle deine Prüfung aus.
Use HLE or an internal „last testing“, that was created on your own domain: research questions, support tickets, code reviews, post-mortems of cases.
Laßt es durch mehrere Modelle laufen.
Richten Sie Ihren Evaluationsgurt auf das TrueFoundry AI Gateway und führen dieselben Eingabeaufforderungen für Gemini 3, Kimi-K2 Thinking, Grok-4.1 and GPT-5.1 Thinking aus.
Verglichen sie an einem Ort.
Sie sehen Korrektheit, Argumentationsqualität, Tokennutzung, Latenz und Kosten nebeneinander.
Sie entscheiden, welches „Denkmodell“ tatsächlich seine Note verdient dein Tasks.
Denn 2025 is the single measure, the really count, not HLE, MMLU or GPQA — es ist die Prüfung, die wie Ihre eigene Arbeit aussieht. Und sie müssen nicht für ein einziges Modell in Bezug auf den Glauben entscheiden, wenn sie vier von ihnen hinter sich lassen können Adern Gateway and you allow the results for you speak.
Häufig gestellte Fragen
Was ist der Unterschied zwischen Kimi K2 und Gemini 3?
Gemini 3 von Google konzentriert sich auf multimodales Verständnis und starke Funktionen zum Aufrufen von Tools mit einem Deep Think-Modus. Kimi-K2 Thinking, a model with offenem weight, is known for his comprehensive, longer context and his detailed thinking chains. Wenn man Kimi K2 im Vergleich zu Gemini 3 versteht, lassen sich verschiedene Ansätze zur fortgeschrittenen KI-Problemlösung erkennen.
Warum ist Kimi K2 der Beste?
Kimi-K2 Thinking eignet sich am besten für komplexes Denken und tiefgründige Problemlösungsaufgaben. Aufgrund seines langen Kontextes und seiner schweren Gedankenkette eignet sich**kimi k2** hervorragend für Herausforderungen, die einen ausführlichen internen Monolog erfordern, wie z. B. fortgeschrittene mathematische Probleme und Benchmarks wie Humanity's Last Exam, die oft zu den besten Vorbildern gehören.
Gemini 3 gegen GPT-5: Was ist besser?
Unser Blog befasst sich mit Gemini 3 und GPT-5.1, indem wir ihre Leistung bei Humanity's Last Exam bewerten. We found out, that „better“ from the specific argument task and the model behavior. The analysis by TrueFoundry, the through our AI Gateway is performed, hebt ihre einzigartigen Problemlösungsansätze hervor und hilft Ihnen dabei, die optimale Lösung für Ihre KI-Lösungen zu finden.
Gemini 3 gegen Grok-4: Welches Modell schneidet besser ab?
Beim Vergleich von Gemini 3 und Grok-4 zeichnen sich beide als leistungsstarke Argumentationsagenten aus und zeigen eine starke Leistung bei komplexen Aufgaben wie Humanity's Last Exam. Gemini 3 zeichnet sich durch ein fortgeschrittenes multimodales Verständnis und einen Deep Think-Modus aus, während Grok-4 sich auf die Verwendung nativer Tools und agentischer Fähigkeiten konzentriert. The optimum performance depends often by the requirements of the respective task.
Welches KI-Modell eignet sich am besten für Argumentationsaufgaben?
For complex thinking provides models like Gemini 3, Kimi-K2 Thinking and GPT-5.1 strong skills. In unserem Blog wird bewertet, wie die einzelnen Programme bei verschiedenen Herausforderungen abschneiden, und hilft Ihnen dabei, ihre spezifischen Stärken zu verstehen. The best choice with comparison of Gemini 3 with Kimi K2 Thinking with GPT 5, depends last by the individual requirements your projects and the art of the necessary argument ab.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last






























.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




