

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
.webp)
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Hier ist ein Szenario, das gerade in Produktionsumgebungen stattfindet.
Sie stellen den standardmäßigen Open-Source-GitHub-MCP-Server bereit. Das Ziel ist einfach: Sie möchten, dass Ihr Mitarbeiter im technischen Support die Problemkommentare liest und sie für das Team zusammenfasst. Es funktioniert perfekt. Der Agent stellt eine Verbindung her, führt einen list_tools-Handshake durch und beginnt mit dem Abrufen von Daten.
Zwei Tage später halluziniert derselbe Agent. Anstatt einen Thread zusammenzufassen, entscheidet es aufgrund eines missverstandenen Kommentars, dass das Projektarchiv „veraltet“ ist, und ruft delete_repo auf.
Warum ist das passiert? Es war kein Prompt-Injection-Angriff. Es war kein böswilliger Insider. Es war ein grundlegendes architektonisches Versagen.
Der Standard-GitHub-MCP-Server wie die Stripe-, Postgres- und Kubernetes-Server, die Sie auf GitHub finden, ist binär. Es macht jeden API-Endpunkt verfügbar, den es umschließt. Wenn der Server delete_repo unterstützt und Sie dem Agenten die Verbindungszeichenfolge geben, hat der Agent delete_repo. Es gibt kein systemeigenes .gitignore für Toolfunktionen. Es gibt keinen chmod für JSON-RPC-Tooldefinitionen.
Dennoch setzen wir routinemäßig Agenten mit „Root Access“ auf unsere kritischste Infrastruktur ein, da es der MCP-Standardimplementierung an Granularität mangelt.
Dies ist ein Startpunkt für die Einführung in Unternehmen. Wir brauchen keine weiteren „KI-Richtliniendokumente“ oder strenge Warnungen in den Systemaufforderungen. Wir benötigen ein Architekturmuster, das MCP-Server in sichere, bereichsspezifische Schnittstellen unterteilt.
Wir nennen das den Virtual MCP Server.
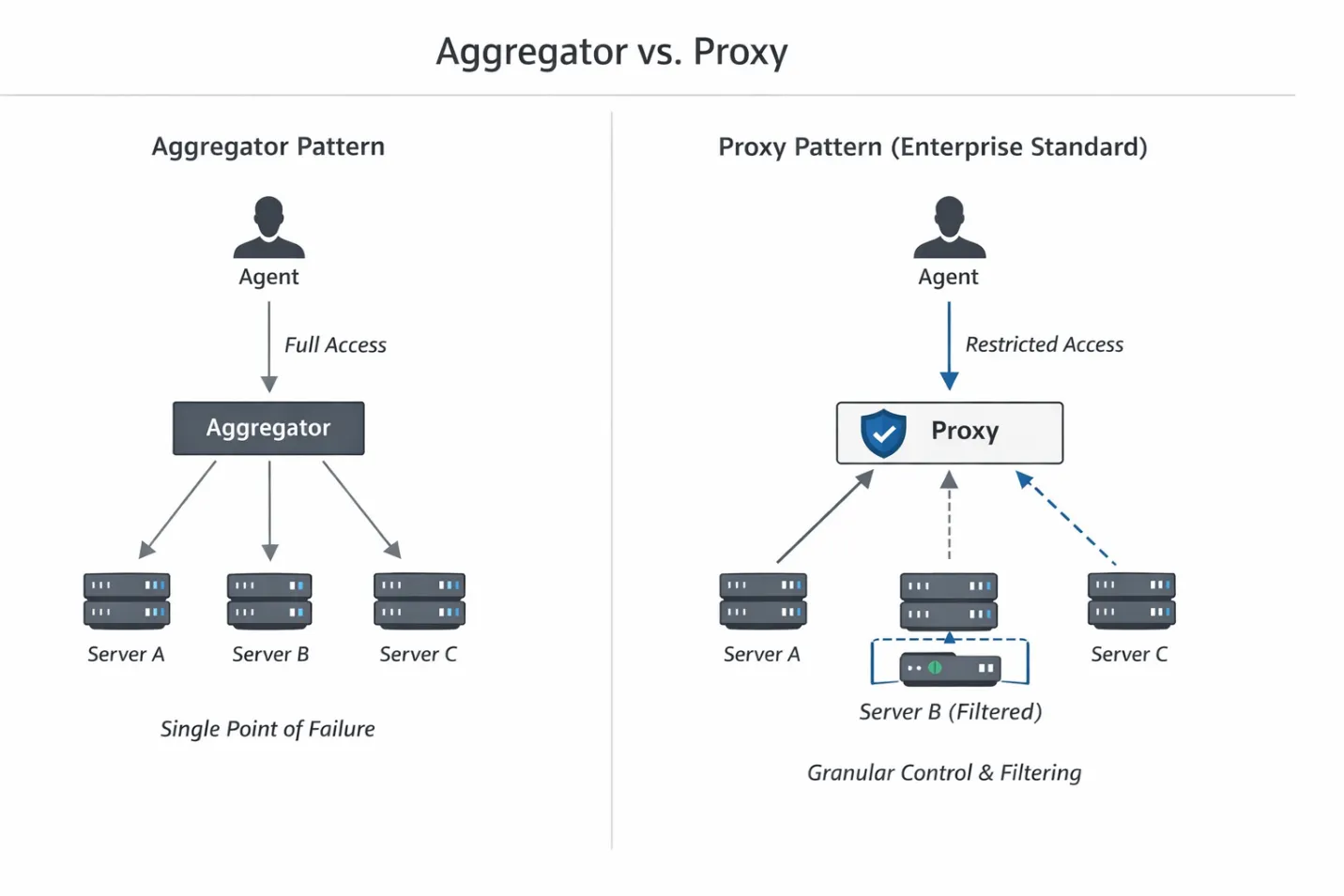
Um dies zu lösen, müssen wir uns ansehen, wie wir den Verkehr zwischen dem LLM und den Tools weiterleiten. Derzeit zeichnen sich im Ökosystem zwei dominante Muster ab (die in der Gartner- und TrueFoundry-Dokumentation häufig zitiert werden): der Aggregator und der Proxy.
Der Proxy führt eine Nutzlastinspektion durch, bevor Anfragen das Backend erreichen, sodass unsichere Tools zum Zeitpunkt der Erkennung entfernt werden können. Er ermöglicht es uns, die Tools/List-JSON-RPC-Reaktionen abzufangen und die Tools, von denen der Agent nicht wissen sollte, dass sie existieren, operativ zu entfernen.
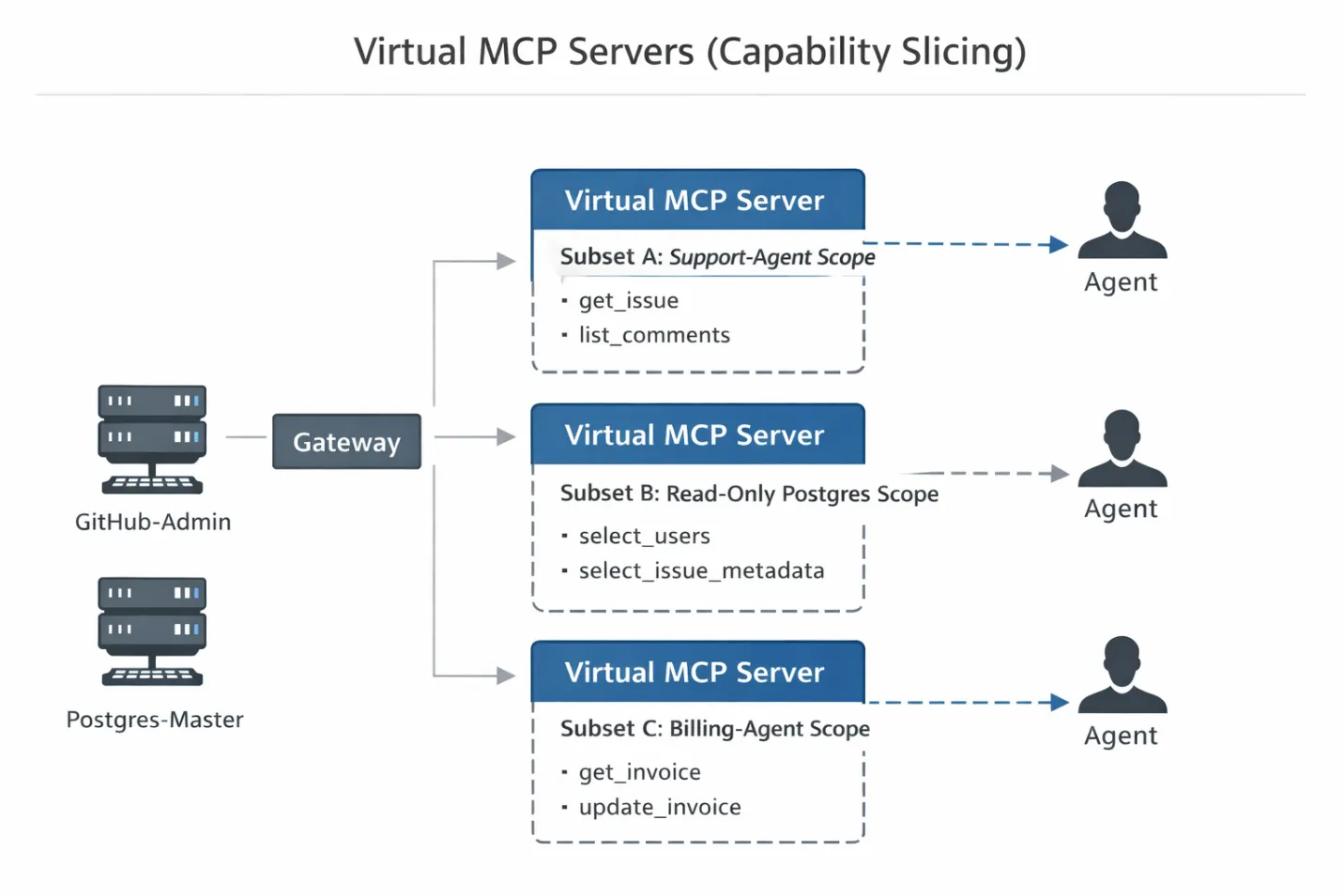
Dies bringt uns zum zentralen Implementierungsmuster: dem Virtual MCP Server.
Ein virtueller MCP-Server ist ein logisches Konstrukt. Er verweist auf bestimmte Tools von physischen MCP-Servern, ohne deren Ausführungslogik zu duplizieren oder die Infrastruktur erneut bereitzustellen. Das ist wo MCP gegen API wird für Unternehmensteams praktisch: Herkömmliche APIs schränken den Zugriff in der Regel auf Endpunktebene ein, während MCP auch entscheiden muss, welche Tools bei der Erkennung sichtbar sind, bevor ein Agent überhaupt einen Anruf tätigt. Stellen Sie sich das wie eine VIEW in SQL vor: Sie ermöglicht es Ihnen, einem bestimmten Benutzer (dem Agenten) eine eingeschränkte Teilmenge von Daten (oder in diesem Fall Funktionen) zu präsentieren, ohne die zugrunde liegende Tabelle (den physischen Server) zu ändern.
So implementieren Sie dieses Muster in einer Produktions-Gateway-Architektur:
Schritt 1: Die Backend-Verbindung (Das „Service Account“) Zunächst verbinden Sie Ihre Raw-MCP-Server mit hohen Rechten mit dem Gateway.
Schritt 2: The Slice (Das Manifest) Als Nächstes definieren Sie ein Virtual Server-Manifest. Dies ist eine Konfigurationsdatei (in der Regel YAML oder JSON), die genau definiert, welche Tools von den physischen Servern einem bestimmten Agentenbereich ausgesetzt sind.
Anstatt Zugriff auf github-all zu gewähren, erstellen Sie ein Slice. So sieht eine typische virtuelle Serverkonfiguration aus:

Schritt 3: Die Kundenansicht (Der Handshake) Wenn der Agent seine Verbindung initialisiert, führt er den standardmäßigen JSON-RPC-Tools/List-Handshake mit dem Gateway durch.
Da der Agent mit dem virtuellen Server mit Support-Agent-Scope verbunden ist, fängt das Gateway diese Anfrage ab. Es filtert die Masterliste anhand des in Schritt 2 definierten Manifests und gibt eine bereinigte Liste zurück.
Das Ergebnis? Es ist technisch unmöglich, dass der Agent einen Aufruf von delete_repo halluziniert. Diese Funktion existiert einfach nicht in ihrem Kontextfenster. Sie haben dem Model nicht nur gesagt: „Tun Sie es nicht „, Sie haben die Hände weggenommen, die es dafür benutzen würde.
Also, wo sitzt TrueFoundry eigentlich in dieser Architektur?
Nicht als Hosting-Ebene und nicht als Convenience Wrapper. In einem MCP-Stack für die Produktion fungiert TrueFoundry als Protokoll-Gateway und Steuerungsebene. Es befindet sich direkt im Ausführungspfad zwischen der LLM-Laufzeit und den Tools, wo die Durchsetzung weiterhin möglich ist.
Diese Positionierung ist wichtig. Da das Gateway die MCP-Verbindung beendet, kann es die JSON-RPC-Nutzlast in Echtzeit analysieren und analysieren. Es leitet nicht nur Anfragen weiter. Es interpretiert Absicht, Identität und Umfang, bevor ein Tool überhaupt ausgeführt wird.
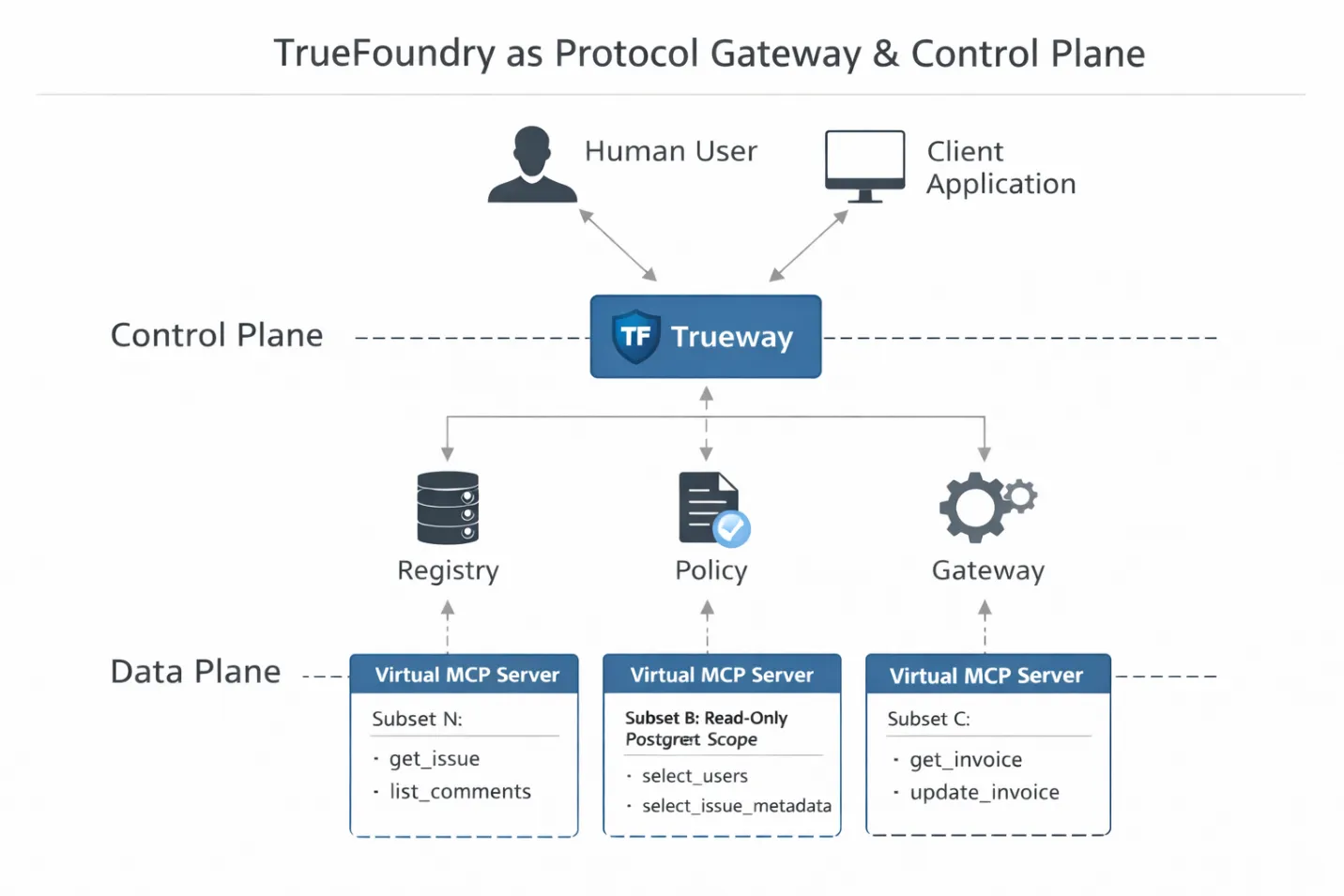
Das ermöglicht drei konkrete technische Fähigkeiten.
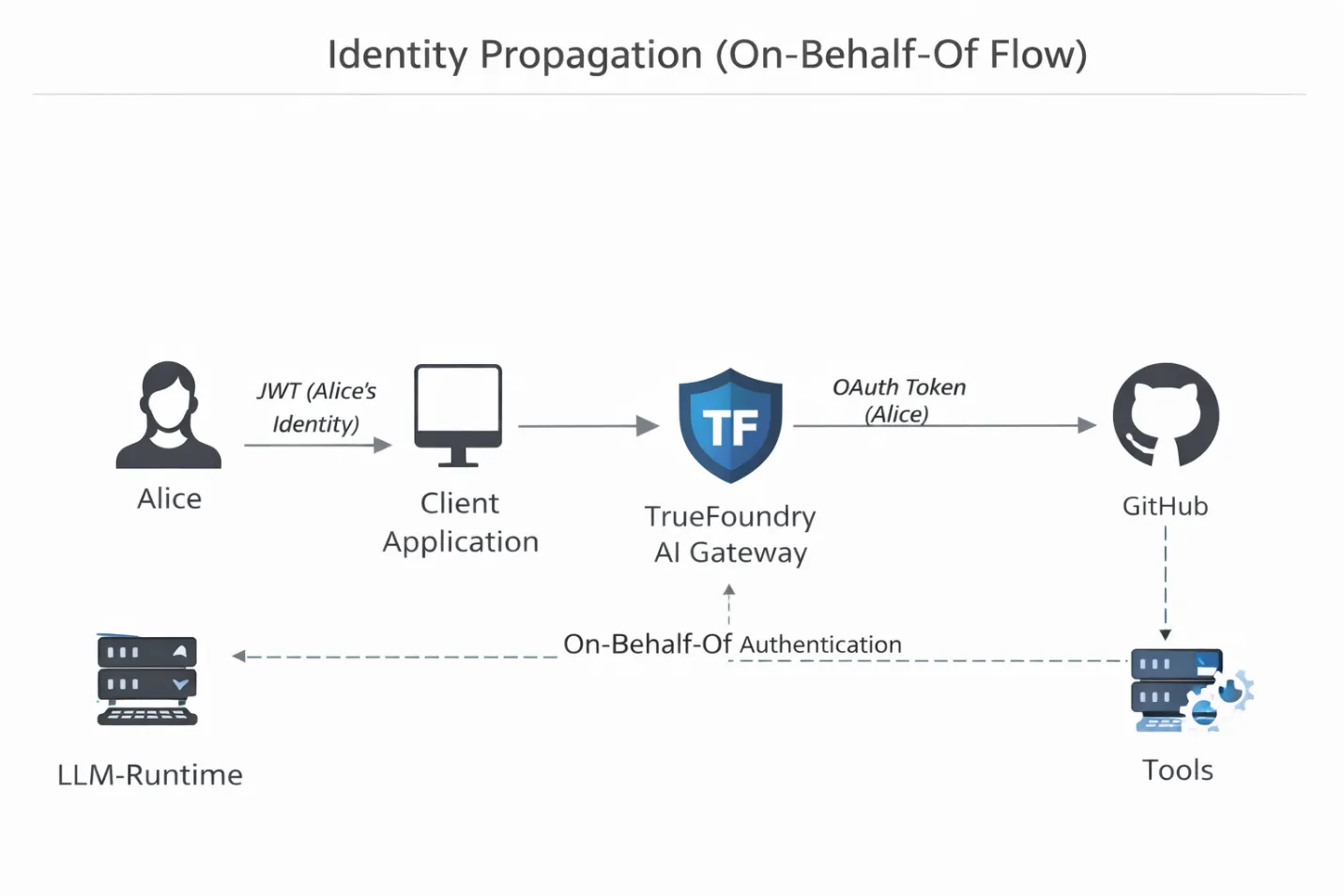
Die meisten DIY-Agent-Stacks leiden unter dem Problem des „generischen Schlüssels“. Agenten werden mit einem gemeinsamen API-Token ausgeführt. Wenn also etwas schief geht, sehen Sie in den Protokollen nur „Der Agent hat es getan“. Es gibt keine Rechenschaftspflicht. Das Gateway von TrueFoundry überprüft das JWT des eingehenden Clients, ordnet es dem authentifizierten menschlichen Benutzer zu und injiziert das richtige OAuth- oder Service-Token stromabwärts. Wenn Alice ein Repository nicht löschen kann, kann das auch der Agent, der in ihrem Namen handelt, nicht. Die Autorität des Agenten ist nicht mehr theoretisch. Es ist kryptografisch gebunden.
Das Gateway ist der Ort, an dem virtuelle MCP-Server real werden. TrueFoundry verwaltet die Routing-Tabellen, die einen virtuellen Serverbereich physischen MCP-Servern und zugelassenen Tools zuordnen. Wenn ein Agent versucht, etwas außerhalb seines deklarierten Bereichs aufzurufen, gibt das Gateway einen strukturierten JSON-RPC-Fehler zurück. Beim Modell kommt es nicht zu einem unbemerkten Ausfall. Es wird ein eindeutiges „Tool nicht gefunden“ angezeigt, was ihm hilft, sich selbst zu korrigieren, anstatt zu halluzinieren.
Da das Gateway die Verbindung beendet, kann es den MCP-Verkehr puffern und verfolgen. Dies ermöglicht die Überprüfung von Tool-Interaktionen im PCAP-Stil. Wenn ein Agent in einer Schleife feststeckt oder eine schlechte Entscheidung trifft, können Sie die exakte Reihenfolge der Werkzeuganrufe wiederholen, ohne die teuren Inferenzschritte, die dazu geführt haben, erneut ausführen zu müssen. Beim Debuggen geht es vom Rätselraten zur Inspektion über.
Zusammengenommen ist dies der Unterschied zwischen der Hoffnung, dass sich ein Agent verhält, und der Durchsetzung, dass er sich nicht schlecht benehmen kann. Die Zugriffskontrolle verlagert sich von Eingabeaufforderungen hin zur Infrastruktur, wo sie hingehört.
Virtuelle Server steuern, welche Tools ein Agent sehen kann. Leitplanken kontrollieren, wie diese Tools verwendet werden. Nur weil ein Agent erlaubt sql_query aufzurufen, bedeutet nicht, dass es erlaubt sein sollte, SELECT * FROM users auszuführen und die gesamte Kundendatenbank in ihr Kontextfenster zu laden.
Hier kommen Leitplanken ins Spiel. In der TrueFoundry-Architektur agieren Guardrails als Middleware, die die JSON-RPC-Nutzlast auf der Protokollebene abfängt und den Datenverkehr überprüft, bevor er ausgeführt wird.
Input Guardrails (Die „WAF“ für Agenten) Wir können Python-Middleware oder einfache Regex-Regeln schreiben, die Werkzeugargumente validieren vor Die Anfrage erreicht den Backend-Container.
Ausgangsleitplanken (Verhinderung von Datenverlust) Agenten neigen dazu, „ausführliche Informationen durchsickern“ zu lassen. Sie holen mehr Daten ab, als sie benötigen, und fassen sie zusammen.
In herkömmlicher Software überprüfen Sie die Protokolle, wenn ein API-Aufruf fehlschlägt. Sie sehen einen 500 Internal Server Error und einen Stack-Trace.
In agentischen Systemen ist der „Ausfall“ oft verstummt. Der Agent ruft ein Tool auf, erhält ein Ergebnis, interpretiert es aber falsch. Oder er ruft das Tool mit leicht falschen Argumenten auf, die zwar technisch funktionieren, aber Datenmüll zurückgeben. In den Standardanwendungsprotokollen wird „200 OK“ angezeigt, aber das Ergebnis ist falsch.
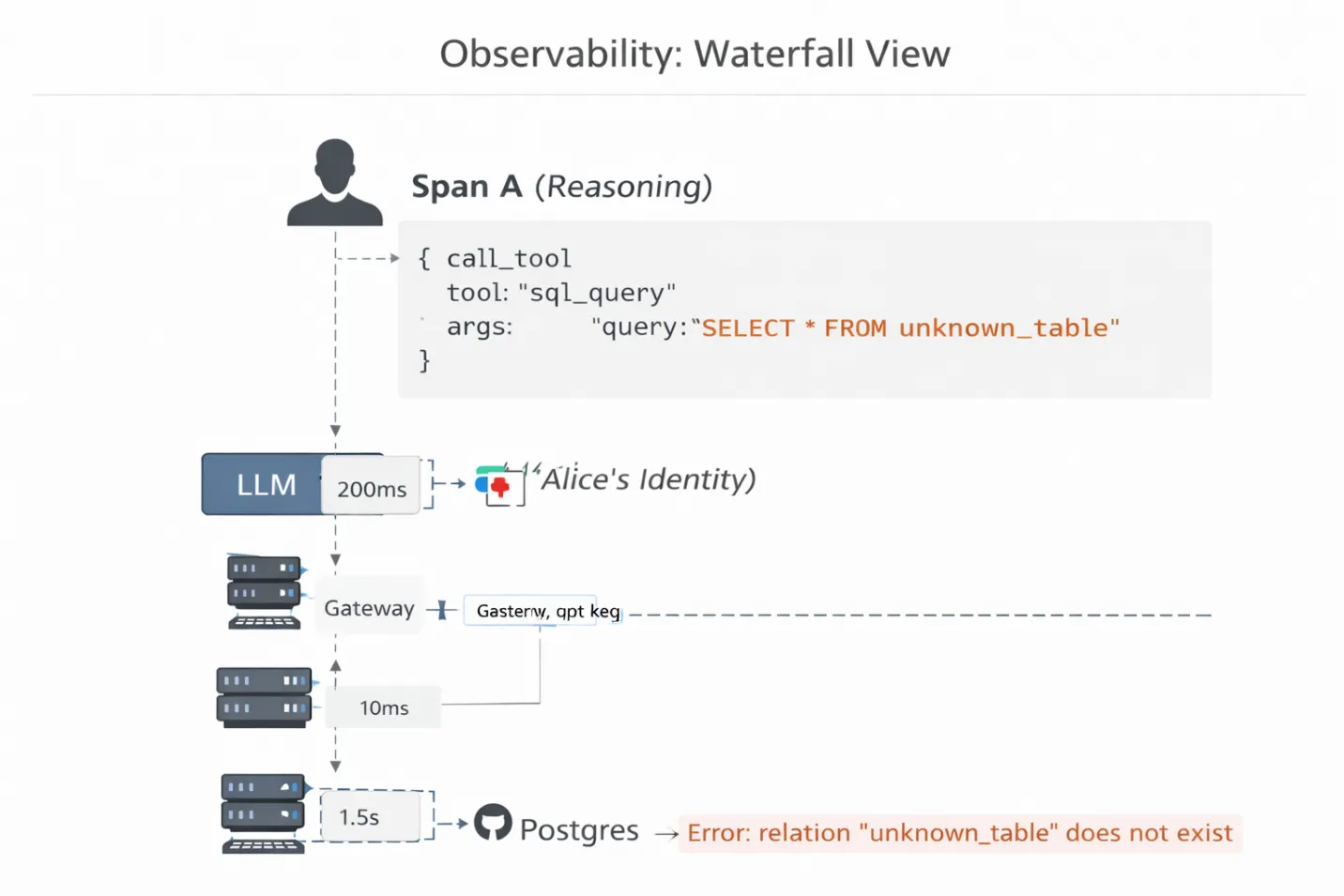
Um dies zu debuggen, benötigen Sie Distributed Tracing for MCP.
TrueFoundry bietet eine Wasserfallvisualisierung der Ausführungskette des Agenten. Sie sehen nicht nur „Anfrage fehlgeschlagen“. Du siehst die Latenz und die Nutzlast bei jedem Hop:
Warum das wichtig ist: Sie können Span C genauer untersuchen und sehen exakt SQL-Abfrage, die der Agent generiert hat. Möglicherweise stellen Sie fest, dass der Agent einen Tabellennamen halluziniert, der nicht existiert, oder einen veralteten API-Parameter verwendet. Ohne diese Sichtbarkeit auf Protokollebene debuggen Sie eine Blackbox, indem Sie raten.
Der Übergang von „Chatbot“ zu „Agent“ ist quasi der Übergang von „Textgenerierung“ zu „Remote Code Execution“. Genau diese Realität sorgt dafür, dass die meisten Unternehmenspiloten in der PoC-Phase am Ball bleiben.
TrueFoundry schließt diese Lücke. Wenn Sie das Virtual MCP Server-Muster über das AI Gateway implementieren, hören Sie auf, Ihr Sicherheitsteam zu bitten, einem probabilistischen Modell zu vertrauen, und beginnen, ihnen eine deterministische Architektur zu zeigen. Sie setzen nicht nur ein Tool ein, sondern eine Oberfläche mit definiertem Umfang, die Identität berücksichtigt, die von Natur aus den Explosionsradius begrenzt.
Für Unternehmen liefert TrueFoundry nicht nur die „Leitungen“ für MCP, sondern auch die Ventile, Manometer und Schleusen. Es macht aus einem rücksichtslosen „Root Access“ -Agenten einen vertrauenswürdigen digitalen Mitarbeiter. Ohne RBAC würden Sie keinen Kubernetes-Produktionscluster betreiben. Ohne TrueFoundry sollten Sie keinen Agenten-Stack für Unternehmen ausführen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




