














November 5, 2025
|
5 min read

Published: June 26, 2026

Blazingly fast way to build, track and deploy your models!
Enterprises are moving AI applications into production faster than ever and the operational reality on the other side looks very different from a prototype. Application teams need to ship and iterate quickly. Platform and quality teams need to know what every model call did and why and whether the output was correct. The harder question is this: how do you observe and evaluate hundreds of model calls across multiple providers and multiple agent frameworks without writing custom instrumentation inside every application?
At TrueFoundry our approach is to keep the execution layer uniform and let teams plug in the observability and evaluation system they already use. That is why we are announcing a native integration between the TrueFoundry AI Gateway and LangSmith from LangChain. The gateway becomes the single execution boundary that every model call and every agent step passes through and LangSmith becomes the system of record where those calls turn into traces and evaluations and dataset runs the team can act on.
The TrueFoundry AI Gateway establishes a single, governed entry point for all model and agent requests. Applications and agents no longer talk directly to model providers. They talk to the gateway proxy. This architectural decision matters because it creates a consistent surface for policy enforcement, routing decisions, and telemetry generation. The gateway determines which model is used, under what constraints, in which environment, and with what safeguards. It also becomes the one place where production behavior can be observed comprehensively.
For platform leaders, this is the point where AI systems stop being a collection of python scripts and start behaving like infrastructure.
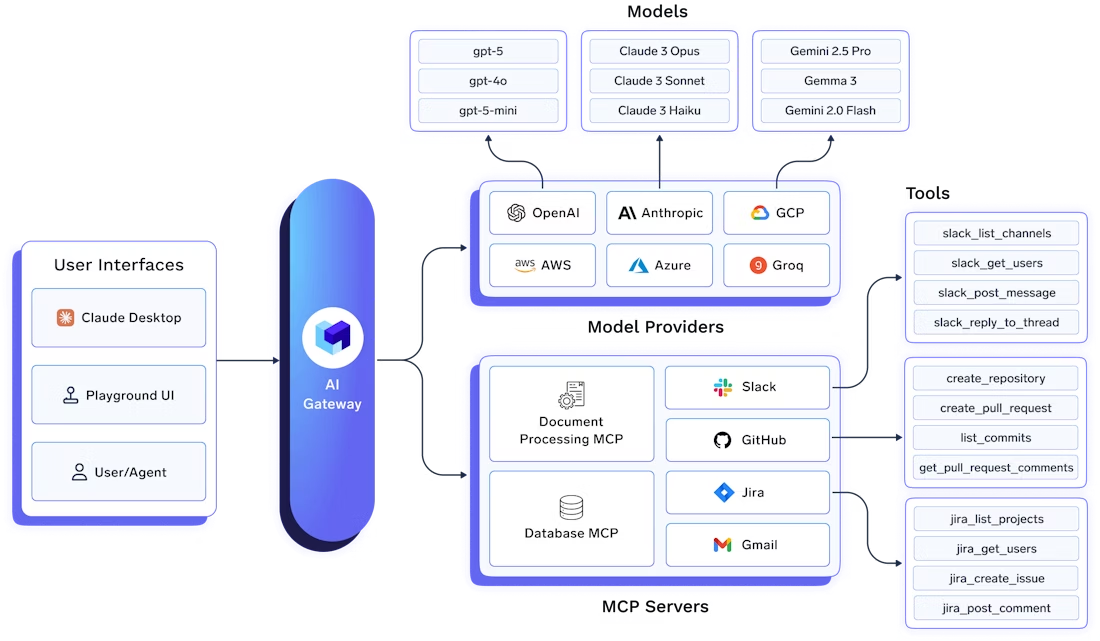
While the gateway governs where and how requests execute, LangSmith is the place you go to reconstruct what actually happened as structured trace data rather than scattered logs. In LangSmith’s terminology, a trace captures the end-to-end sequence of steps for a single request (from input to final output), and each step inside that trace is a run, a single unit of work such as an LLM call, a chain step, prompt formatting, or any other operation you want visibility into. Traces are organized into projects (a container for everything related to a given application or service), and multi-turn conversations can be linked as threads so you can inspect behavior across an entire dialogue rather than one isolated request. Read here if you want to dive deeper: Observability concepts
LangSmith also treats feedback as a first-class concept, letting you attach scores and criteria to runs - whether that feedback comes from humans, automated evaluators, or online evaluators running on production traffic. This is what makes it more than “monitoring”: it supports an evaluation loop where you can run offline evaluations on curated datasets before shipping, and online evaluations on real user interactions in production to detect regressions and track quality in real time.
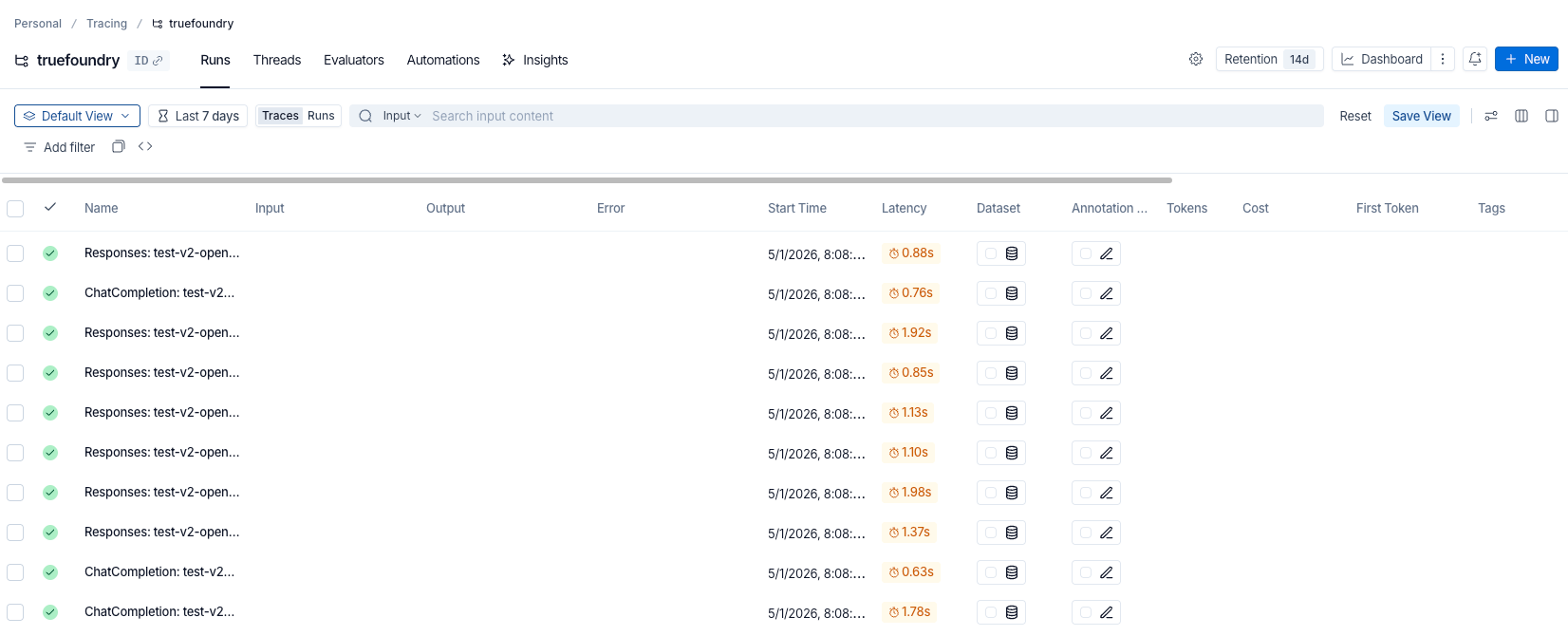
This is how traces from the TrueFoundry AI Gateway appear in the LangSmith UI. Each model call shows up as its own run with the operation type and latency captured at the gateway level.
Most enterprises already operate a centralized observability stack that anchors their incident response and SRE practice. The challenge with LLM systems is that the telemetry generated by model calls (prompts, completions, token usage, cache hits, guardrail decisions, agent step graphs) does not map cleanly onto the metrics and traces those tools were originally designed for. Teams typically end up choosing between two unsatisfactory options:
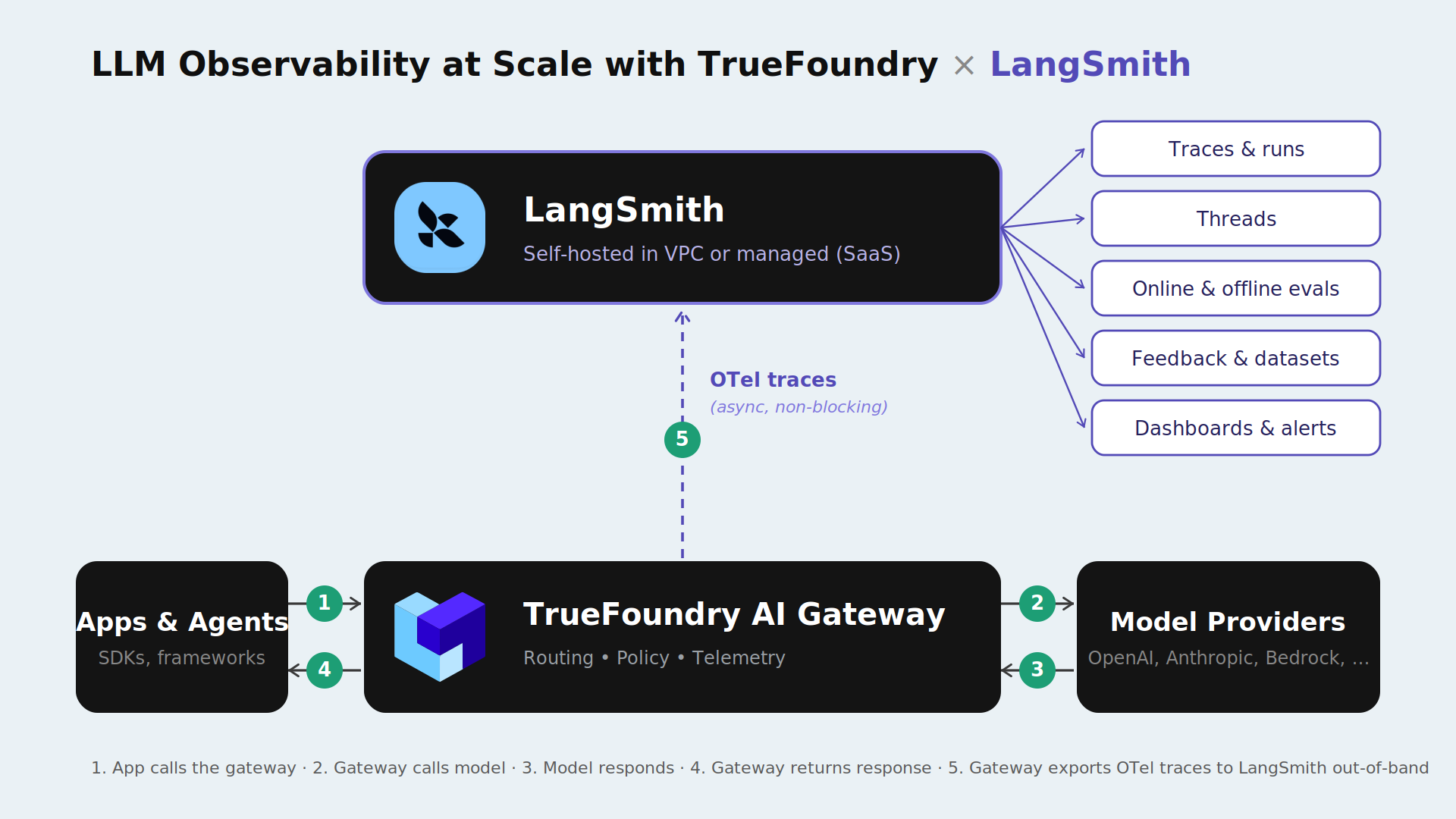
On the TrueFoundry side, you enable the AI Gateway’s OpenTelemetry traces exporter. The gateway remains responsible for generating and storing traces that you can view inside the TrueFoundry Monitor UI, and exporting those traces is an additive operation that doesn’t change TrueFoundry’s own storage behavior. Check OTEL export docs here: TrueFoundry
On the LangSmith side, you provide an API key for authentication and (optionally) a project name so traces land in a predictable project rather than the default. LangSmith’s OpenTelemetry guide documents the OTLP headers used for authentication and project routing. Docs: LangChain

See our documentation here: LangSmith

If you’re deploying to Kubernetes, the official “Self-host LangSmith on Kubernetes” guide is Helm-based and is explicit about what you must provide upfront: a LangSmith license key, an API key salt, and (if using basic auth) a JWT secret. It also recommends using external managed Postgres/Redis/ClickHouse for production rather than in-cluster defaults, because trace volume can grow quickly. For more in-depth reading, we would recommend going through LangSmith’s self-host on Kubernetes docs: Self-host on Kubernetes.
To simplify this setup on TrueFoundry, we maintain a Helm chart repository at github.com/truefoundry/tfy-langsmith-charts that packages LangSmith along with the required backend services.
For AI leaders, the TrueFoundry–LangSmith integration provides a shared foundation where execution, observability, and evaluation stay aligned as systems scale. It lets teams manage LLM applications with the same rigor as distributed services meeting enterprise requirements without slowing development because production AI needs production-grade infrastructure.
The partnership is intentionally composable: TrueFoundry governs and routes execution, LangSmith records and evaluates behavior, and OpenTelemetry connects them. Together, they function as a practical control plane that moves organizations from promising demos to dependable, accountable AI in production.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.







.png)

.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




