Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
9.9
Mapping the On-Prem AI Market: From Chips to Control Planes
As enterprises push GenAI into production, many are rediscovering the benefits of on‑premise deployments—whether to curb cloud costs, meet strict compliance requirements, or deliver ultra‑low latency. But an on‑premise AI stack isn’t a single appliance you can rack and forget. It’s a layered ecosystem of hardware, orchestration, data platforms, and serving frameworks that must all work in concert.
This guide walks through each layer of the modern on‑prem AI stack and shows the value proposition for each component.
Why On‑Premise AI Is Gaining Traction
Enterprises across finance, healthcare, manufacturing, and government are facing tougher data‑sovereignty regulations, rising cloud bills, and performance SLAs that public cloud can’t always meet. Together, these layers form the foundation of an on premise AI platform that enterprises can scale, govern, and operate independently of public cloud constraints.
Data Control & Compliance: Keep sensitive data entirely behind your firewall. When data is sent to a public cloud, its exact physical location and the legal jurisdiction it falls under can become ambiguous, creating significant compliance risks and complicating audits. An on-premise setup allows an organization to tailor its entire AI stack to comply with these regulations, providing a defensible framework that adheres to legal standards and avoids the complexities of cross-border data transfer issues.
Performance & Latency: Co‑locate compute and storage for real‑time inference. By processing data locally, on-premise AI can offer significantly lower and, more importantly, more predictable latency. This consistent, high-throughput performance is essential for applications that require instant, cross-modal decision-making, such as analyzing a stream of sensor data while cross-referencing it with historical records. This performance advantage extends to integration with existing enterprise systems. On-premise solutions, due to their flexibility and customizability, can often be more easily and reliably integrated with legacy databases, ERP systems, and other operational technology that may not be compatible with standardized cloud environments.
Cost Predictability: Shift from variable pay‑as‑you‑go rates to fixed infrastructure investments. Hidden fees for data egress, API calls, storage tiering, and fluctuating compute prices can quickly erode the initial benefits of low CapEx, leading to what some analyses have termed "pure waste" in cloud spending. In contrast, an on-premise deployment, despite its high initial cost, offers predictable, manageable long-term OpEx. For organizations with sustained AI usage, on-premise infrastructure often proves to be the more cost-effective option over a three-to-five-year horizon.
Custom Integration: Seamlessly connect to legacy systems, edge devices, or proprietary hardware.
Yet building and operating this stack in‑house brings capital expenses, specialized talent requirements, and ongoing maintenance overhead.
What Is a Modern On‑Premise AI Stack?
A modern on-premise AI stack is a complex, multi-layered system where each component plays a crucial role. It is not a monolithic entity but an interdependent ecosystem of hardware and software designed to deliver robust, scalable, and efficient AI capabilities. Understanding this stack requires a layer-by-layer deconstruction, from the physical infrastructure that provides the raw power to the high-level platforms that enable the AI workflow
Each layer must be architected to maximize utilization, ensure reliability, and allow seamless scaling—without locking you into a single vendor.
Hardware & Physical Infrastructure
This is the bedrock of the entire AI stack, the physical manifestation of computational power. It comprises the compute engines that perform the calculations, the storage systems that hold the vast datasets, and the networking fabric that connects everything. The performance and limitations of this layer dictate the potential of all subsequent layers
Compute Engines
GPUs: Originally designed for rendering 3D graphics, GPUs have become the workhorse of the AI revolution due to their massively parallel architecture. NVIDIA has established a dominant position in this market with its data center GPUs, such as the A100, H100, and the forthcoming B200 series. These chips, equipped with thousands of specialized cores (e.g., Tensor Cores), can deliver performance for AI training that is up to 20 times faster than traditional CPUs. They are the current de facto standard for building high-performance on-premise AI training clusters.
CPUs: While GPUs handle the heavy lifting of parallel processing, CPUs remain essential components of the AI server. They manage the overall system operations, handle sequential processing tasks, and orchestrate the data flow to and from the GPUs. The latest generation of multi-core CPUs from Intel and AMD provide the necessary general-purpose compute power to support the specialized accelerators
ASICs/TPUs: The emerging and disruptive trend in AI compute is the rise of Application-Specific Integrated Circuits (ASICs). These are chips designed from the ground up for a single purpose: running AI workloads. Google's Tensor Processing Units (TPUs) are a prime example, optimized for the matrix operations at the heart of neural networks. In the on-premise market, a new class of startups is challenging the GPU monopoly with specialized ASICs. Companies like Groq are developing chips for ultra-low-latency inference, while SambaNova Systems and Cerebras are creating novel architectures (Reconfigurable Dataflow Units and Wafer-Scale Engines, respectively) that promise greater TCO and power efficiency for large-scale training and inference. These specialized accelerators represent the future of AI hardware, offering a path beyond the power and cost limitations of general-purpose GPUs.
Enterprise Servers & Storage
High-Performance Servers: Leading enterprise hardware vendors such as Hewlett Packard Enterprise (HPE) with its ProLiant and Apollo lines, Dell Technologies with its PowerEdge servers, Supermicro, and IBM with its Power Systems, provide the server chassis for on-premise AI. These are not standard servers; they are specifically engineered to accommodate multiple high-power GPUs, provide massive amounts of high-speed memory (RAM), and incorporate advanced cooling solutions to handle the thermal output of the accelerators.
High‑Performance Storage: AI is fueled by data, and the storage layer must provide rapid, concurrent access to massive datasets without creating a bottleneck. This requires a move beyond traditional storage. High-performance, low-latency storage solutions like NVMe (Non-Volatile Memory Express) SSDs and distributed file systems are essential. The data itself is typically organized into data lakes for storing vast quantities of raw, unstructured data (images, text, logs) and data warehouses for structured, analytics-ready data. A critical emerging component, especially for generative AI, is the vector database, which is optimized for storing and querying the high-dimensional vector embeddings that represent unstructured data.
High‑Speed Networking
InfiniBand & RDMA fabrics deliver up to 400 Gbps of low‑latency throughput, ensuring that GPUs remain fed with data during distributed training or parallel inference. The networking layer is the "nervous system" of the AI data center, responsible for the seamless transfer of data between the storage systems and the compute nodes. For large-scale AI, particularly distributed training where a single model is trained across hundreds or thousands of GPUs, standard Ethernet networking is insufficient and can become a major performance bottleneck. To prevent the powerful GPUs from sitting idle while waiting for data, on-premise AI clusters rely on high-bandwidth, low-latency networking fabrics. Technologies like InfiniBand and RDMA (Remote Direct Memory Access) are critical. InfiniBand, for example, can support throughput of up to 400 gigabits per second, ensuring that data can be moved between servers and storage at the speed required to keep the compute engines fully utilized. This high-speed interconnect is a non-negotiable component of any serious on-premise AI infrastructure.
The Orchestration and Management Layer
Sitting atop the physical hardware, the orchestration and management layer consists of the software that abstracts, partitions, and manages the underlying resources. This layer transforms a rigid collection of physical servers into a flexible, scalable, and efficient platform for developing and running AI applications.
The Role of Virtualization and Containerization
The foundational technologies for resource management are virtualization and containerization. They allow for the efficient partitioning and isolation of workloads.
Virtual Machines (VMs): Virtualization has been a staple of the data center for decades. A hypervisor creates multiple virtual machines on a single physical server, each with its own full operating system. While robust and well-understood, VMs have a larger resource footprint and slower startup times compared to containers. However, they remain relevant, especially for modernizing legacy applications alongside new AI workloads. Platforms like IBM Fusion and Vates VMS are specifically designed to provide a unified on-premise platform that can manage both VMs and containers, often with features like direct GPU.
Containers (e.g., Docker): Containerization is the modern, lightweight approach to workload isolation. A container packages an application and all its dependencies (libraries, configuration files) into a single, portable unit that shares the host operating system's kernel. This results in a much smaller footprint, faster startup times, and greater resource efficiency than VMs. For AI, this means that a model and its specific environment can be encapsulated into an immutable container image. This image can then be deployed consistently across a developer's laptop, a testing server, and the production cluster, eliminating the "it worked on my machine" problem and ensuring reproducibility.
Kubernetes: The AI Data Center OS
While Docker provides the container format, Kubernetes provides the at-scale management. Kubernetes is an open-source platform that automates the deployment, scaling, networking, and management of containerized applications across a cluster of machines. It has become the undisputed standard for container orchestration and is the engine behind most modern cloud-native applications, whether in the public cloud or on-premise.
For on-premise AI, Kubernetes is the critical link between the application layer and the hardware. Enterprise-grade Kubernetes distributions like Red Hat OpenShift are specifically designed for on-premise and hybrid cloud deployments, providing the security, management, and support that businesses require.
The benefits of using Kubernetes for AI workloads are profound:
Automated Scaling and Load Balancing: Kubernetes can automatically scale the number of container replicas up or down based on computational demand and distribute inference requests across them, ensuring high availability and performance.
Resource Management and Scheduling: Kubernetes has GPU-aware scheduling capabilities, allowing it to intelligently place AI workloads on nodes that have the necessary accelerator hardware available, maximizing the utilization of these expensive resources.
Resilience and Self-Healing: If a container or a node fails, Kubernetes can automatically restart it or reschedule it on a healthy node, providing the resilience needed for long-running model training jobs and mission-critical inference services.
In essence, Kubernetes provides the dynamic, automated, and resilient operating system for the on-premise AI data center.
Data & ML Enablement
Data Platforms & Governance
This is the highest software layer of the stack, containing the specialized tools and platforms that data scientists and machine learning engineers use to execute the end-to-end AI lifecycle. This layer leverages the underlying hardware and orchestration to manage data and to build, train, deploy, and monitor AI models.
The Data Fabric (Data Platforms)
Before any model can be built, data must be managed. Data platforms provide a unified environment for the entire data lifecycle, from ingestion and processing to storage and governance.
Cloudera Data Platform (CDP): A dominant player in the on-premise and hybrid data landscape, Cloudera has evolved from its roots in the Hadoop ecosystem to become a comprehensive enterprise data platform. The CDP Private Cloud offering is specifically designed to run on-premise, typically on top of a Kubernetes cluster like Red Hat OpenShift. It provides a unified open data lakehouse architecture that can handle both structured and unstructured data at petabyte scale. Critically for enterprise AI, it integrates robust, centralized security through Apache Ranger and a unified governance and metadata framework called Shared Data Experience (SDX), ensuring that consistent security policies are applied to all data and analytics across the hybrid environment.
Databricks and Hybrid Connectivity: While Databricks is primarily a cloud-native platform, its prominence in the AI space means that many organizations are building solutions to connect their on-premise data sources, such as a Cloudera cluster, to their Databricks environment. This reality underscores the hybrid nature of modern enterprise AI, where data gravity often necessitates keeping large datasets on-premise while leveraging cloud-based tools for certain analytics or collaboration tasks.
MLOps & Experimentation
MLOps (Machine Learning Operations) is a set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently. MLOps platforms are the tools that enable these practices, automating the entire ML lifecycle and bridging the gap between data science (building models) and IT operations (running them in production).
Key functions of an MLOps platform include: experiment tracking (logging all parameters, metrics, and artifacts), model versioning and registry, building automated CI/CD (Continuous Integration/Continuous Deployment) pipelines for models, managing model deployment, and monitoring model performance for issues like data drift.
The on-premise MLOps market features a mix of powerful open-source and commercial platforms:
Open-Source:MLflow is a leading open-source MLOps platform, widely adopted for its flexibility, framework-agnostic approach, and comprehensive features for experiment tracking and model management. It allows teams to build robust MLOps workflows without vendor lock-in.
Commercial Platforms: End-to-end managed platforms like DataRobot, Iguazio (acquired by McKinsey), offer comprehensive solutions that cover the entire lifecycle, often with a focus on ease of use, automation, and enterprise-grade support.
Augment platform choice with TrueFoundry’s AI Gateway RBAC, guardrails, and budgets to ensure policies are enforced seamlessly across teams and models
Serving & Scaling AI in Production
Once a model is trained and validated, it must be deployed to a production environment where it can receive input data and return predictions—a process called inference. Model serving is a specialized task that requires software optimized for high throughput and low latency.
NVIDIA Triton Inference Server: A high-performance, open-source inference server from NVIDIA. Its key strengths are its ability to run models from nearly any framework (TensorFlow, PyTorch, ONNX, etc.) and its capacity for concurrent model execution, which allows multiple models or multiple instances of the same model to run on a single GPU, maximizing hardware utilization.
KServe: A standard for model serving on Kubernetes. KServe provides a scalable and extensible platform for deploying models. Its standout features include serverless inference capabilities (with autoscaling that can scale pods down to zero when not in use, saving resources) and an "InferenceGraph" that supports advanced deployment strategies like canary rollouts, A/B testing, and model ensembles.
Seldon Core: Another powerful, open-source model serving platform for Kubernetes. Seldon Core is also known for its robust support for advanced deployment patterns, including A/B tests, canary deployments, and multi-armed bandits (MABs), making it a strong choice for organizations that need to rigorously test and optimize models in production.
Other Frameworks: The ecosystem also includes other powerful open-source tools like Haystack, which is a framework for building complex agentic and RAG pipelines, and Ray, a distributed compute engine often used as the backbone for training and serving large-scale AI applications.
TrueFoundry operates as a gateway/control plane above these servers, so you can mix-and-match (Triton for CV models, vLLM for LLMs, KServe for serverless edges) while keeping one consistent interface, policy, and telemetry layer.
The Application and Control Layer: AI Gateway and MCP
The layers described so far provide the foundation for building and running AI models. However, to make these models securely and efficiently accessible to end-user applications and to enable complex, agentic workflows, a final software layer is required: the Application and Control Layer. This layer acts as the central nervous system for all AI interactions, providing governance, security, and a standardized interface for communication. It consists of two critical, emerging components: the AI Gateway and the Model Context Protocol (MCP).
The AI Gateway: A Centralized Control Plane
An AI Gateway is a specialized middleware that serves as a single, centralized control point for all AI-related traffic between applications and the underlying AI models. Deployed within the on-premise environment, often on Kubernetes, it provides a critical set of functions for managing AI at an enterprise scale.
Unified Access and Intelligent Routing: The gateway offers a single, consistent API endpoint for developers, abstracting away the complexity of interacting with multiple different models (e.g., a mix of fine-tuned open-source models and specialized commercial models). It can perform context-based routing, directing requests to the most appropriate model based on factors like cost, performance requirements, or the specific use case, optimizing both efficiency and outcomes.
Robust Security and Governance: For on-premise AI, security is paramount. The AI Gateway acts as a policy enforcement point, integrating with enterprise security architecture to manage authentication, authorization, and role-based access control (RBAC). It inspects both inbound prompts and outbound responses in real-time to prevent prompt injection attacks and data leakage of sensitive information like Personally Identifiable Information (PII), ensuring compliance with regulations like GDPR and HIPAA.
Comprehensive Observability and Cost Control: The gateway provides a unified dashboard for monitoring all AI interactions, tracking key metrics like latency, error rates, and token usage. This centralized observability is crucial for troubleshooting and performance optimization. Furthermore, it enables granular cost control by enforcing token-based rate limiting and usage budgets, preventing runaway costs and allowing for accurate chargebacks to different business units.
The Model Context Protocol (MCP): The Universal Language for AI Agents
While the AI Gateway manages the flow of requests, the Model Context Protocol (MCP) is an open standard that revolutionizes what those requests can do. MCP provides a standardized way for AI models to discover and interact with external tools, data, and services, turning them from isolated "brains" into capable, integrated agents.
A Standardized Interface for Tools: Instead of building brittle, custom code for every integration, MCP allows enterprise systems (like databases, CRMs, or internal APIs) to announce their capabilities through a lightweight "MCP server". The AI application, acting as an "MCP host," can then query these servers to understand what tools are available and how to use them, effectively creating a plug-and-play ecosystem for AI agents.
Enabling On-Premise Agentic AI: A key advantage of MCP is that it is an open, auditable protocol that can be deployed entirely within an organization's firewall. This allows enterprises to build powerful, autonomous AI agents that can securely interact with proprietary internal systems without exposing sensitive data to external services.
Preventing Vendor Lock-In: Because MCP is a model-agnostic standard supported by major players like Anthropic, OpenAI, and Microsoft, it decouples the AI model from the tool integrations. This gives enterprises the flexibility to swap out the underlying LLM—for instance, moving from a commercial API to a self-hosted, fine-tuned model—without having to rebuild the entire integration stack, thus preserving technological sovereignty.
Together, the AI Gateway and MCP form a powerful control and application layer that makes on-premise AI not just possible, but also secure, manageable, and truly integrated into the fabric of the enterprise.
TrueFoundry’s MCP Gateway combines both: governance and observability for every request, plus secure, audited tool-calling via MCP so agents can act on your internal systems without data leaving your network.
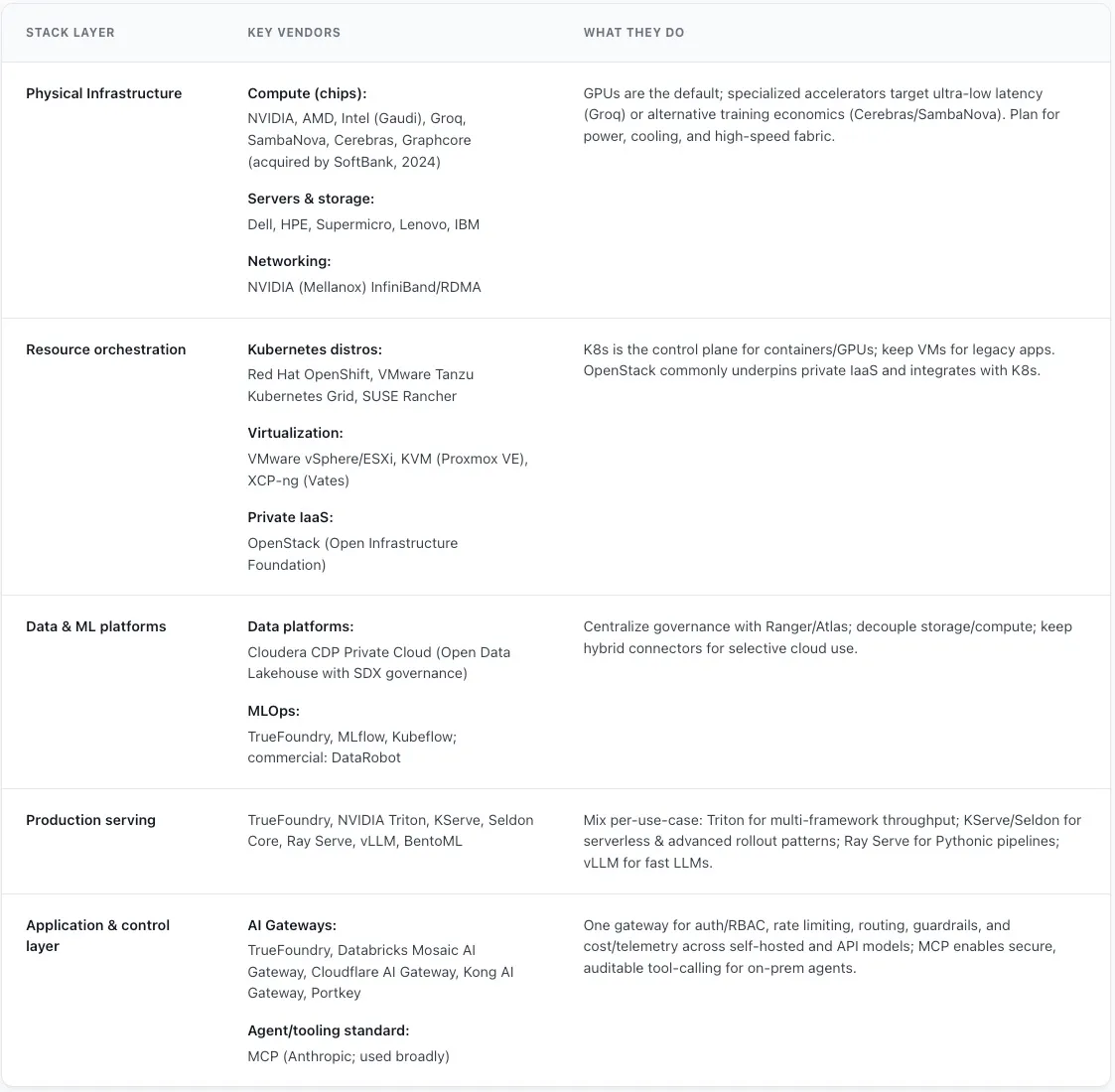
Vendor Mapping Across the On-Premise AI Stack
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.




























.webp)
.webp)
.webp)
.webp)







.png)
.webp)