Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.
9,9
Série de Aceleradores TrueFoundry: Acelerador de Processamento Inteligente de Documentos
O OCR e o Processamento de Documentos não são um problema resolvido?
Embora muitos acreditem que o OCR e o processamento de documentos são tecnologias resolvidas, a entrada manual de dados custa às empresas dos EUA cerca de US$ 15.000 a US$ 30.000 por funcionário por ano. Fonte: O desgaste operacional e de tempo devido ao processamento manual de documentos ainda é significativo porque:
OCR Tradicional: Frágil e de Baixo Desempenho
Os métodos tradicionais de OCR (Visão Computacional + Regras + PNL) apresentam baixa adaptabilidade a vários formatos de escrita e layouts, muitas vezes falhando em considerar o contexto e os requisitos de formato de dados.
Baixa Adaptabilidade: Mesmo os melhores sistemas tradicionais de OCR estabilizam em 85-90% de precisão para documentos complexos, com conteúdo manuscrito caindo para uma taxa de precisão de meros 64%. Fonte
Má qualidade de imagem ou iluminação: 300 DPI é o mínimo padrão para resultados ideais de OCR
Ruído
Inclinação e Orientação
Dependência de Modelo e Layout: Ajustado para funcionar em um modelo específico, requer pipelines de processamento subsequente personalizados ou uma alteração no modelo para cada novo tipo de documento/atualização de modelo. Ex.: Novo formato de fatura de um fornecedor, uma coluna ligeiramente deslocada em um relatório
Cegueira de Contexto: O OCR em nível de caractere falha em diferenciar caracteres semelhantes, perdendo a compreensão do contexto em todo o documento. Ex. "50mg Metformina" pode ser lido como "5Omg Metformina", o que está incorreto para qualquer tarefa médica subsequente.
OCR/LLM Accuracy by Document Type
Document Type
Traditional OCR
SmolDocling (2B)
Qwen-VL-Max (18B)
GPT-4o
Gemini 2.5 Pro
Claude 3.7 Sonnet
Human Baseline
Clean Printed Text
97–98%
92–95%
97–98%
99–99.5%
99–99.5%
99–99.5%
99.8%
Tables & Forms
80–85%
83–87%
91–94%
96–98%
95–97%
95–97%
98–99%
Handwriting (Print)
70–80%
65–75%
80–85%
86–90%
88–92%
89–93%
96–98%
Handwriting (Cursive)
50–70%
60–70%
75–80%
82–90%
80–89%
81–90%
95–97%
Low-Quality Scans
60–75%
80–85%
90–93%
93–96%
92–95%
93–95%
95–97%
Mathematical Notation
70–80%
75–80%
88–93%
92–96%
94–97%
94–96%
97–99%
OCR Baseado em LLM: Imprevisível e Caro
OCRs baseados em LLM resolvem alguns desafios nos métodos tradicionais, mas introduzem novas complexidades:
Não resolvido para texto manuscrito: Apesar de GPT-4V e Claude 3.5 Sonnet alcançarem 82-90% de precisão em texto manuscrito, uma melhoria significativa, isso ainda fica aquém dos limites críticos para negócios. Ex. Na área da saúde, uma taxa de erro de 10-18% em prescrições manuscritas poderia ser literalmente fatal.
Difícil de escalar:
Proibitivamente caro: Para organizações que processam milhões de documentos por ano.
Respostas mais lentas:
Difícil manter SLAs em sistemas auto-hospedados
Tempos de inatividade e picos de latência com provedores terceirizados
Saídas inconsistentes:
Alucinações - ex., um valor completamente fabricado para uma cláusula em um documento legal
Dificuldade em gerar saída estruturada
Mesmo prompt, respostas diferentes
Em setores como serviços financeiros e saúde, que processam milhões de documentos críticos anualmente, um sistema que possa escalar de forma confiável e gerar resultados de alta qualidade a baixo custo é essencial
Quão bom é o seu pipeline de processamento de documentos? (Métricas práticas)
Operational Metrics & World-Class Benchmarks
Metric
Definition (Short)
World-Class Benchmark
Straight-Through Processing (STP)
% of documents processed end-to-end without human touch
85–95% for structured documents
Field Extraction Accuracy
Correctness of extracted key fields (names, amounts, dates)
99%+ for critical fields
Time to Value
Time from document receipt to structured data availability
<2 min (simple docs), <10 min (complex forms)
Human Edit Rate
% of data requiring manual correction
<5% while maintaining 99%+ accuracy
Processing Cost per Document
Total cost (compute, labor, infra) per processed page
$0.02–$0.15 per page (depending on complexity)
Apresentando o Acelerador de Processamento Inteligente de Documentos da TrueFoundry
O Processamento Inteligente de Documentos (IDP) da TrueFoundry é um Acelerador baseado em IA Generativa que combina práticas prontas para produção com um pipeline de OCR altamente personalizável e preciso para construir e implementar fluxos de trabalho de processamento de documentos de ponta a ponta.
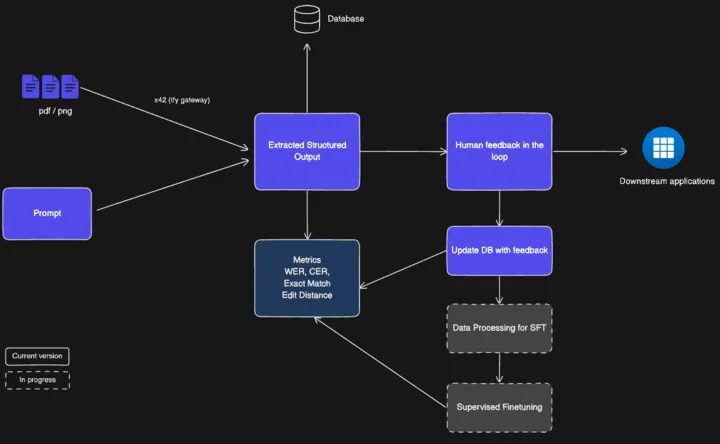
Como Funciona: Potencialize suas aplicações com dados estruturados em minutos!
O acelerador ingere seus PDFs, imagens ou faxes e os limpa: remoção de ruído, correção de inclinação e aumento de escala. Assim, os modelos começam com uma imagem nítida. Em seguida, ele classifica cada documento (fatura, receita, nota manuscrita) e anexa o esquema correto, prompts e regras de domínio. O modelo de extração extrai campos estruturados e pontuações de confiança; um motor de regras os valida e enriquece com verificações e pesquisas. Os itens são encaminhados a um revisor através de uma interface de usuário simples, e cada correção retroalimenta o sistema para melhorá-lo continuamente.
Componentes Personalizáveis e Modulares
O Acelerador é composto por componentes modulares plugáveis que juntos podem construir tanto um protótipo inicial quanto uma aplicação completa pronta para produção.
Componentes Básicos
Suporte a Múltiplos Modelos (Código Aberto e Código Fechado)
Humano no Circuito (HITL) e Feedback
Infraestrutura de Ajuste Fino Integrada
Monitoramento e Observabilidade
Integração de Base de Conhecimento (RAG + Grafo de Conhecimento)
Componentes Avançados
Classificação e Roteamento Automatizados
OCR Sensível à Região e Caixas Delimitadoras
Descoberta Automática de Esquemas (Zero-Shot)
Validação e Pós-Processamento
Conformidade e Auditabilidade
Nosso Design foi validado em múltiplas Implementações Empresariais
Desenvolvido para Escolha e Controle
O acelerador é agnóstico a modelos, de código aberto ou fechado, e pode rotear entre provedores para otimização de preço/desempenho e failover. Especialistas permanecem no circuito com uma interface de revisão ajustada ao domínio, cujas edições se tornam dados de treinamento.
Operacional desde o primeiro dia.
Você obtém observabilidade em tempo real (latência, throughput, custo por documento) além de KPIs de negócios — STP, precisão de campo e taxa de edição. A validação e o enriquecimento aplicam regras entre campos e normalizam formatos antes que os dados cheguem às aplicações downstream.
Adaptável, especialmente para aqueles Casos de Uso Empresariais complexos
A descoberta de esquemas, o OCR com reconhecimento de região e o embasamento em base de conhecimento lidam com layouts complexos; os logs de auditoria preservam cada ação, pontuação e substituição para ambientes regulamentados.
Como garantimos que este sistema escala?
Nossa arquitetura é um projeto agnóstico de nuvem, baseado em microsserviços, projetado para confiabilidade, escalabilidade e eficiência de custos de nível empresarial. Ao desacoplar componentes centrais com filas de mensagens assíncronas, o sistema lida com cargas de trabalho flutuantes e falhas de componentes sem perda de dados, evitando o vendor lock-in.
Camada de Ingestão
Gateway LLM sem estado: Ponto de entrada único (autenticação/limite de taxa) que enfileira cada documento para um tópico de mensagem.
Buffer durável: Uploads brutos são gravados em armazenamento de objetos para reprodução, auditoria e recuperação.
Pipeline de Processamento
Isolamento de serviço: Workers separados para classificação, extração e validação; cada um pode ser atualizado e escalado independentemente.
Autoescalonamento independente: Extratores que exigem muita CPU/GPU escalam durante picos sem impactar estágios mais leves.
Tarefas idempotentes: Tarefas reproduzíveis com deduplicação garantem novas tentativas seguras e saídas "exatamente uma vez".
Gerenciamento de Dados e Estado
Armazenamento portátil: Buckets compatíveis com S3 armazenam documentos e artefatos com versionamento.
Backbone relacional: DB compatível com PostgreSQL rastreia metadados, estado do fluxo de trabalho e filas HITL.
Contratos de esquema: Interfaces claras entre serviços permitem mudanças seguras e retrocompatíveis.
Camada de Feedback e MLOps
Loop humano: Correções verificadas são capturadas com proveniência para dados de treinamento.
Loop fechado: Pipelines automatizados de retreinamento/avaliação/implantação enviam modelos aprimorados de volta para produção.
Lançamentos controlados: O registro de modelos, as verificações A/B e as reversões mantêm as melhorias seguras e auditáveis.
Conclusão
O OCR moderno não é uma questão "resolvida", especialmente quando precisão, escala e custo são importantes. O IDP Accelerator da TrueFoundry oferece uma abordagem pragmática e pronta para produção, com extração multimodelos, validação automatizada e um sistema de intervenção humana que aprimora continuamente o sistema. O resultado é um processamento direto mais rápido, maior precisão no nível do campo nos documentos que realmente impulsionam seu negócio e uma plataforma que suas equipes podem operar, não apenas uma demonstração para admirar.
Este acelerador ajuda você a processar mais documentos de forma eficiente e econômica, mantendo a integridade dos dados para auditores, especialistas e operadores, permitindo a implementação imediata sem a necessidade de engenharia personalizada extensiva.
Piloto em produção: Conecte-se conosco usando este link. Podemos criar um protótipo funcional para o seu caso de uso e ajudá-lo a entregar uma aplicação pronta para produção em 1/10 do tempo normal de desenvolvimento!
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.






























.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




