




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
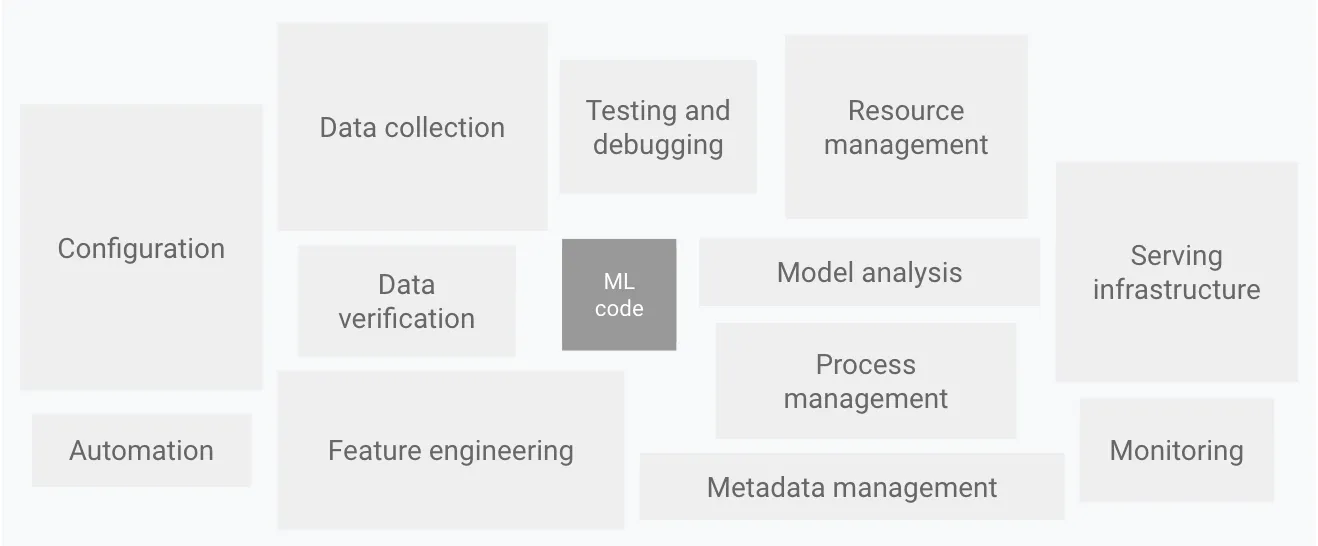
Blazingly fast way to build, track and deploy your models!
A equipe da Truefoundry trabalhou arduamente no último mês adicionando recursos à nossa plataforma de Implantação de ML. Nosso objetivo é construir uma plataforma de implantação que torne absolutamente fácil implantar modelos e serviços de ML, ao mesmo tempo em que aplica os melhores princípios de engenharia e segurança. Para construir uma ótima plataforma de ML, precisamos ter uma plataforma de engenharia sólida, e é por isso que grande parte do foco inicial tem sido na entrega de uma plataforma robusta para implantar código.
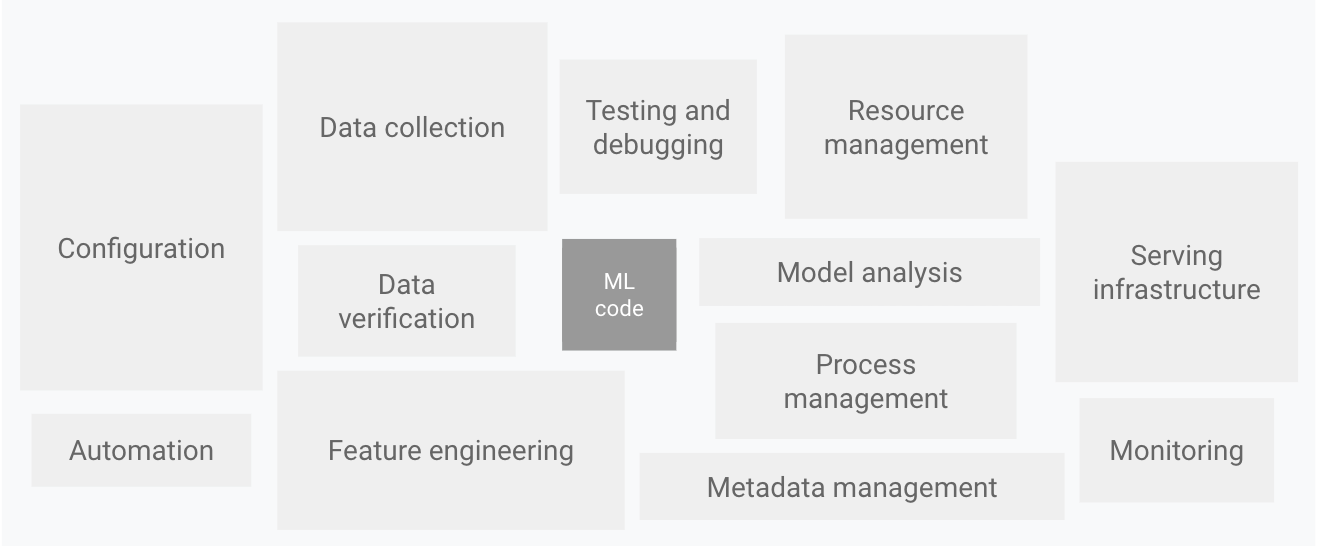
De todas as partes da plataforma de ML descritas acima, nós nos concentramos na infraestrutura de serviço, monitoramento e toda a automação relacionada.
Muito trabalho foi dedicado à construção da nossa plataforma de implantação sobre Kubernetes. O objetivo tem sido tornar a implantação absolutamente fácil em menos de 5 minutos, onde a plataforma se encarrega de construir a imagem a partir do código-fonte, armazená-la em um registro Docker e, finalmente, implantar o aplicativo no Kubernetes. Algumas das atualizações do nosso último mês incluem o seguinte:
Modelos de aprendizado de máquina podem ter latência de inferência ou desempenho muito diferentes, dependendo do tipo de instância. Por exemplo, ao testar a latência de inferência de um modelo 'hugging face' em processadores Intel vs. AMD, descobrimos que os processadores Intel eram cerca de 30% mais rápidos. É por isso que agora temos uma opção para permitir que os usuários escolham o tipo de instância ao implantar suas cargas de trabalho. Se o tipo de instância não for selecionado, a carga de trabalho pode ser implantada em qualquer tipo de instância disponível.

Anteriormente, tínhamos um link do Grafana para exibir logs e métricas. Embora o Grafana fosse altamente personalizável, o controle de permissões e acesso não era realmente possível no Grafana. Além disso, ele se mostrou um pouco lento e difícil de entender para usuários que não estavam acostumados com o Grafana. É por isso que implementamos nossa própria interface de usuário para exibir logs e métricas, o que deve ser suficiente na maioria dos casos. Ainda oferecemos a integração com Grafana na nuvem pública para usuários mais avançados.

Agora podemos adicionar usuários como editor, visualizador ou administrador em grupos secretos.

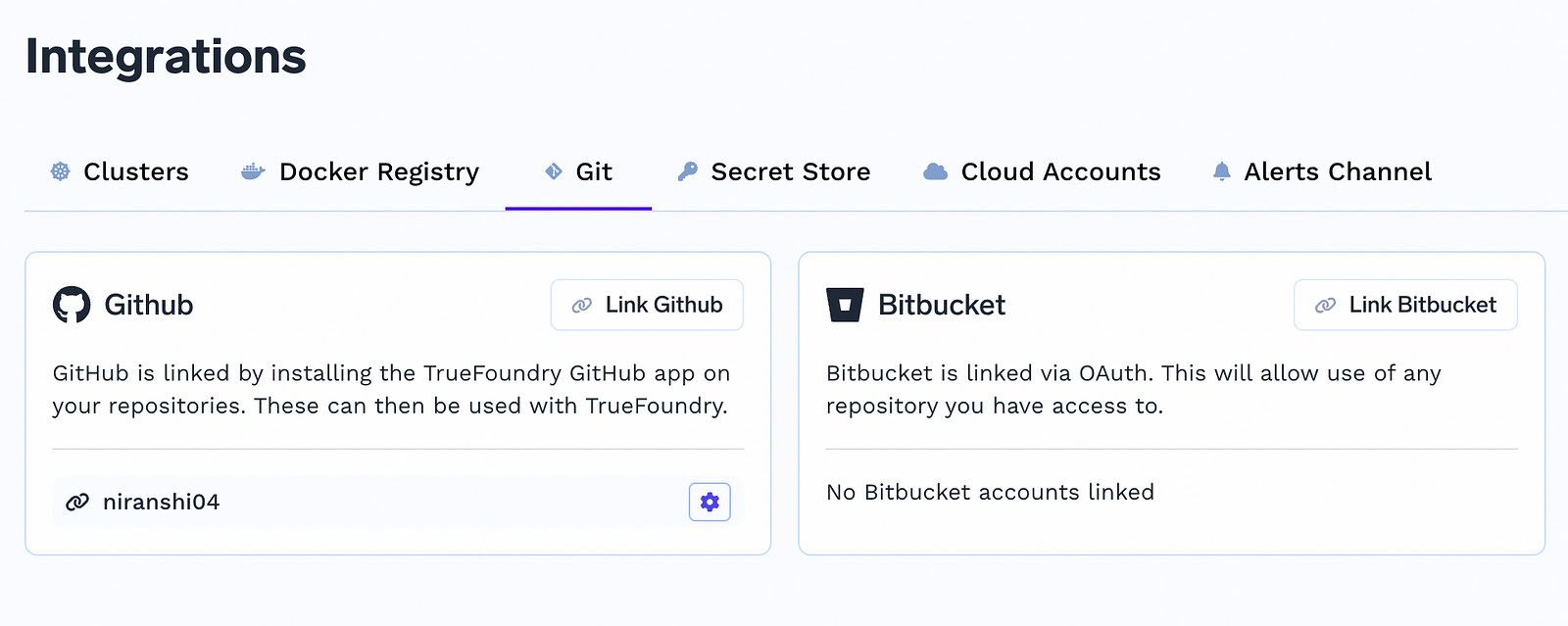
Agora podemos implantar diretamente no Truefoundry a partir de qualquer repositório Github ou Bitbucket. Os usuários podem integrar-se com seus próprios repositórios privados usando o Fluxo Oauth e selecionar os parâmetros apropriados para implantar o aplicativo.
No próximo mês, estamos trabalhando em alguns recursos empolgantes, como:
Fique ligado e envie-nos o seu feedback!
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




