



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 26, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
Os sistemas LLM em produção comportam-se como sistemas distribuídos. Um único pedido de utilizador pode desencadear múltiplas chamadas de modelo, chamadas de ferramentas e novas tentativas. Sem um limite de execução único, a telemetria torna-se fragmentada e a depuração torna-se um trabalho de adivinhação.
Esta publicação mostra como conectar o TrueFoundry AI Gateway ao Elastic Cloud para que os rastreios do gateway fluam para o Elastic Observability usando OpenTelemetry. Irá configurar um endpoint OTLP e uma chave API no gateway.
Quando as aplicações comunicam diretamente com os fornecedores de modelos, não há um local consistente para aplicar políticas e capturar rastreios. Um gateway cria essa superfície consistente para que a governação, o encaminhamento e a geração de telemetria sejam centralizados.
TrueFoundry AI Gateway estabelece um único ponto de entrada governado para pedidos de modelos e agentes. As aplicações e os agentes comunicam com o proxy do gateway em vez de comunicarem diretamente com os fornecedores. Esta arquitetura torna as decisões de encaminhamento e a geração de telemetria consistentes em cada pedido.
O gateway pode exportar rastreios usando protocolos OpenTelemetry padrão para que possa enviar o mesmo fluxo de rastreios para a plataforma de observabilidade que as suas equipas já utilizam.
Elastic Cloud é um serviço gerido para o Elastic Stack que suporta fluxos de trabalho de pesquisa, observabilidade e segurança. Pode analisar registos, métricas e rastreios em escala, o que o torna um destino natural para os rastreios do gateway.
O TrueFoundry AI Gateway suporta a exportação de rastreios OpenTelemetry para plataformas externas como o Elastic Cloud para que possa usar o Elastic para observabilidade, mantendo o TrueFoundry como a camada de acesso LLM unificada.
Esta integração usa OpenTelemetry de ponta a ponta. O gateway exporta rastreios OTEL e o Elastic Cloud os ingere através do seu endpoint OTLP gerido.
Na consola do Elastic Cloud, abra a sua implementação ou projeto serverless, depois vá a Adicionar dados, depois Aplicações, depois OpenTelemetry. Copie o URL do endpoint OTLP gerido e copie o valor da chave API mostrado para os cabeçalhos de autenticação. As implementações alojadas no Elastic Cloud requerem a versão 9.2 ou posterior para o endpoint OTLP gerido.
No painel de controlo do TrueFoundry, vá a AI Gateway, depois Controlos, depois Definições. Desloque-se até à secção Configuração OTEL e abra o editor para a configuração do exportador.
Ative o Exportador de Traces OTEL. Defina o Tipo de Configuração como http. Defina o endpoint de traces para o endpoint OTLP gerenciado que você copiou do Elastic Cloud. Escolha a codificação Json ou Proto.
Uma configuração mínima fica assim.
Tipo de configuração: http
Endpoint de traces: https://<your motlp endpoint>
Codificação: Json ou Proto
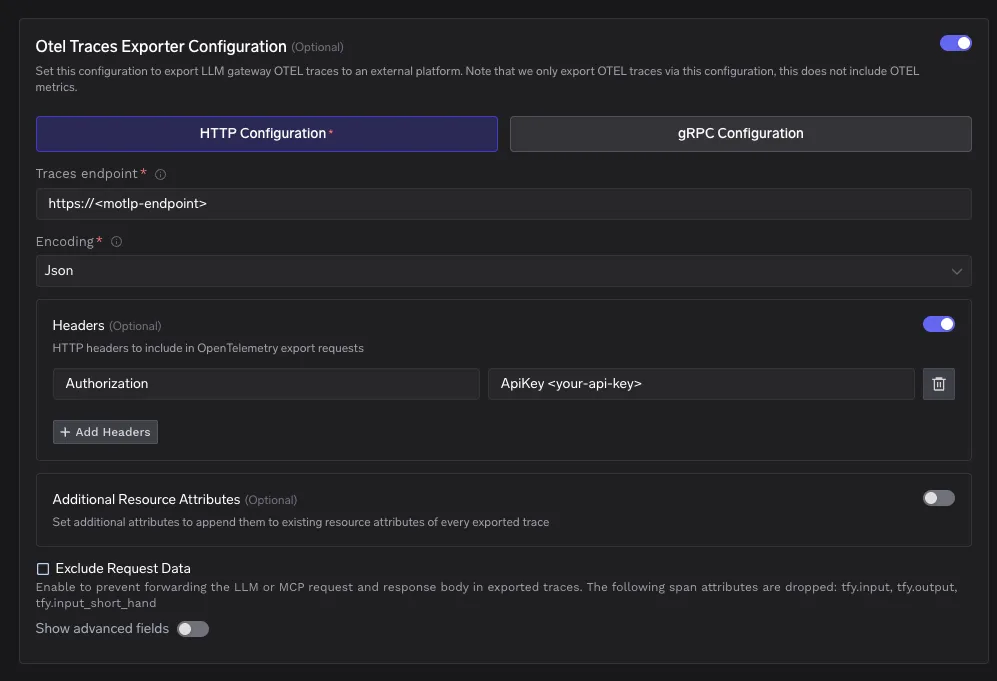
Adicione um cabeçalho HTTP chamado Authorization com o valor no formato ApiKey. O prefixo ApiKey é obrigatório.
Authorization: ApiKey <your api key>
Salve a configuração de exportação OTEL. Depois disso, todos os traces do gateway serão exportados para o Elastic Cloud automaticamente.
Envie algumas requisições através do gateway. Em seguida, abra o Kibana e vá para Observability, depois APM, depois Services e procure pelo serviço chamado tfy-llm-gateway. A partir daí você pode inspecionar traces e transações para cada requisição.
O endpoint OTLP gerenciado do Elastic Cloud suporta Json e Proto. Json é mais fácil de ler durante a depuração. Proto é mais eficiente para dados de alto volume.
Você pode definir Atributos de Recurso Adicionais na configuração do exportador para anexar tags consistentes a cada trace exportado. Isso é útil para filtragem em nível de ambiente e tenant no Elastic.
Se vir um erro de autenticação que menciona um prefixo ApiKey, então o cabeçalho de Autorização não está formatado corretamente e deve começar com ApiKey. Se vir HTTP 429, então a sua implementação pode estar a atingir os limites de taxa de ingestão e deve considerar alterações de plano ou ajustes de amostragem.
Quando o AI Gateway exporta rastreamentos para o Elastic Cloud, obtém um único local para analisar os rastreamentos do gateway com os mesmos fluxos de trabalho de observabilidade que já utiliza para o resto da sua stack. O Elastic reúne logs, métricas, rastreamentos e visualizações de APM numa única plataforma para que o seu tráfego LLM não fique isolado dos sinais de aplicação e infraestrutura.
Pode depurar um único pedido de utilizador de ponta a ponta abrindo o rastreamento no Elastic. A UI de Rastreamentos mostra o rastreamento distribuído para que possa ver o caminho completo da execução. O mapa de serviços ajuda-o a compreender as dependências dos serviços. Os detalhes da transação fornecem informações de tempo e metadados do pedido para que possa identificar rapidamente o passo lento.
Pode detetar regressões mais cedo ao observar tendências em vez de incidentes isolados. O Elastic Observability oferece dashboards e funcionalidades de análise que ajudam as equipas a passar da telemetria bruta para insights. Inclui também capacidades de deteção de anomalias que podem revelar padrões incomuns em vários sinais.
Pode executar fluxos de trabalho de monitorização específicos para LLM dentro do Elastic. O Elastic destaca casos de uso de observabilidade de LLM, como o rastreamento de latência, erros, prompts, respostas, uso e custos. Com o AI Gateway como limite de execução, pode tornar esta cobertura consistente em todas as chamadas de modelo que fluem através do gateway.
Pode tornar os rastreamentos mais fáceis de filtrar e agrupar adicionando atributos de recurso na configuração do exportador do gateway. Isto é útil para metadados de ambiente e tags de inquilino, para que as equipas possam segmentar os rastreamentos por produção, staging ou unidade de negócio dentro do Elastic.
O TrueFoundry AI Gateway oferece um limite de execução consistente para todo o tráfego LLM. O Elastic Cloud oferece uma superfície de observabilidade madura para rastreamentos e fluxos de trabalho de nível de serviço. Com o OpenTelemetry a conectá-los, pode depurar e operar sistemas LLM com o mesmo rigor que espera de qualquer sistema distribuído em produção.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




