




August 1, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 18, 2026

Blazingly fast way to build, track and deploy your models!
For most of the agent era, context strategy was a moving van: load everything the agent might conceivably need — the conventions doc, the full tool catalog, the reference material — into the window up front, and hope the model finds the relevant parts. A growing context-engineering pattern inverts that. JIT context — JIT as in just-in-time, the same idea as the just-in-time compilers in your browser — is the pattern Anthropic's context-engineering guidance put at the center of the discipline: it keeps the window almost empty of payloads and full of pointers: the agent knows what exists — skills by their metadata, data by its references, tools by a thin index — and the heavy content gets loaded only at the moment it's needed, then released. For many long-running agents, JIT context is becoming the safer default, and preloading everything a deliberate exception. This post is the engineering of that inversion — what to load late, what must stay preloaded, and why JIT context is ultimately a runtime property rather than a prompting habit.
Lucia, a platform engineer, inherited an agent whose system context had grown the way attics do. Someone had preloaded the full engineering handbook "so it follows conventions." Someone else had inlined all forty tool descriptions "so it knows its options," then three thousand lines of API reference "so it stops guessing schemas." Every addition had a reason; the sum was an agent that started every run with most of its window already spent, paid for that dead weight again on every one of its thirty loop steps, and — the part that finally got attention — performed worse than a stripped-down prototype on the same tasks. The fix that worked felt almost insulting in its simplicity: take nearly everything out, leave behind one-line descriptions of what exists and where, and let the agent pull the handbook section, the schema, the procedure at the moment a step actually needed it. Same knowledge, different tense. The attic became a library with a catalog.
That refactor has a name now — JIT context — and it's converging from three directions: Anthropic's context-engineering guidance (September 2025) made retrieve-at-runtime over preload a core principle; the skills ecosystem made progressive disclosure the loading model for packaged knowledge; and harness builders made offloading and isolation default runtime behavior. This post connects those threads, layer by layer, ending at the question context posts in this series always reach: who should be doing this work — your prompt authors, or the runtime under them?
The preloading instinct is rational in a chat world. A single-turn exchange has one shot at context, so you front-load; worst case, the model ignores the excess. Agents broke both assumptions. A loop re-sends its window on every step, so excess is billed repeatedly, not once. And the excess isn't ignored — long-context research and practitioner experience agree that models degrade as windows fill with low-relevance text, the failure mode the community calls context rot. The instruction-manual approach — read everything before you click Start — turns out to be how you make an agent slower, costlier, and dumber simultaneously.
JIT context inverts the default. The window's standing contents shrink to the genuinely always-needed (task, core instructions, recent steps) plus a catalog — compact descriptions of what exists and how to get it: a skill as its name and a sentence, a dataset as a path, a prior result as a handle. When a step needs the payload, the agent (or the harness on its behalf) fetches it, uses it, and lets it fall out of the hot window afterward. Anthropic's formulation is the one to internalize: maintain lightweight identifiers, load data at runtime. The window stops being a warehouse and becomes a workbench.
The pattern isn't new — it's borrowed, knowingly, from interface design. Progressive disclosure is the 1990s UX principle that users shown fifty settings freeze, while users shown three settings and an "Advanced" toggle succeed; you reveal complexity at the moment of intent, not before. The community has been explicit about the transplant: an agent whose window is stuffed with everything it might need loses effectiveness exactly the way a user facing a cluttered screen does, and the cure is the same staging of information. The agent knows a capability exists — that's the metadata, always visible, cheap. The capability's full weight — instructions, scripts, reference files — stays behind the toggle until the agent decides to use it.
The name itself carries a pedigree worth borrowing from. If you have a CS background, the closest analogy is JIT compilation: rather than compiling an entire program ahead of time, a JIT compiler translates each piece at the moment it's executed — when the runtime knows the code path is actually being taken and has live information about how it's being used. The win is twofold: you don't pay to compile code that never runs, and the compilation you do is better-informed because it happens with runtime context in hand. JIT context maps onto that almost exactly. Preloading is ahead-of-time compilation: you pay attention and tokens for everything that might be needed, decided before the task reveals what it actually requires. JIT context defers the load to the moment of use — the reference in the window is the symbol the runtime can resolve, and the agent's activation is the call site that triggers resolution. The lesson is the same one compiler writers learned decades ago: holding everything ready up front is more expensive than fetching on demand, and the fetch, done right, is cheap and better-targeted because it happens when you finally know what the task needs.
What makes the transplant more than a metaphor is that the loading boundary is enforceable in software. A UI can only encourage users toward the right disclosure; a harness can implement it — deciding mechanically what enters the window and when, the same way a virtual-memory system decides what's resident. That analogy (context window as RAM, external stores as disk, the harness as the pager) is the systems-engineering way to hear everything that follows: JIT context is paging for attention.
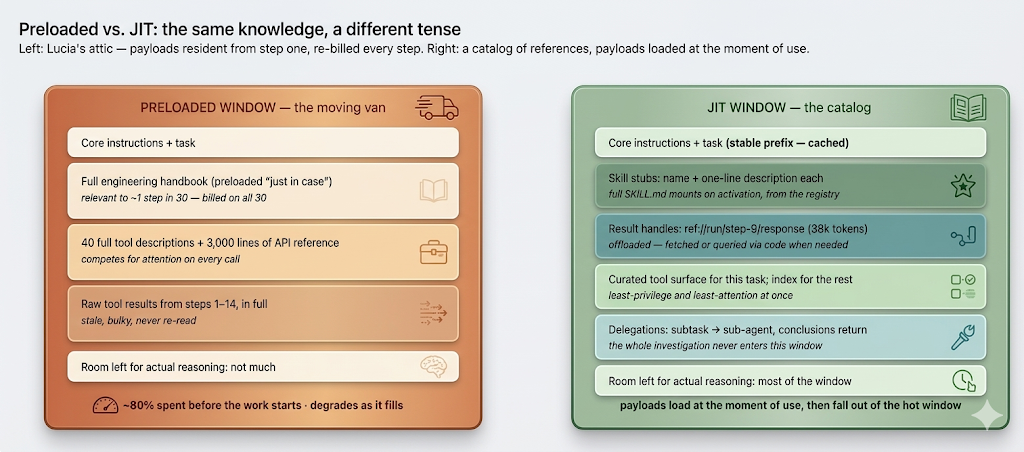
Three compounding effects pay for the pattern. Attention: every preloaded token competes with the task for the model's focus, and the degradation isn't linear politeness — irrelevant bulk actively erodes performance on what matters, which is why Lucia's stripped prototype beat the loaded production agent. JIT is the architectural defense against context rot: the window holds signal because noise was never admitted. Cost: in a loop, the window is re-sent every step, so a preloaded handbook isn't one payment but thirty; the arithmetic of our token-burn work applies, and JIT attacks the largest term — the standing weight that rides along everywhere. Freshness: a preloaded copy is a snapshot that ages as the run proceeds, while a reference resolves to the current state of the file, the ticket, the database at the moment of use — for long-running agents, late loading isn't just cheaper, it's more correct.
The honest column in the ledger: JIT buys these at the price of retrieval latency on the steps that load (usually trivial next to a model call, but nonzero), a new failure mode (an unresolvable reference must surface as an honest error, not a hallucinated payload), and a dependency on description quality — the agent loads from the catalog's one-liners, so a bad stub hides a good payload. None of these reverse the verdict; all belong in the design.
Skills are where the pattern is most visible, because the SKILL.md ecosystem was built around it. A skill sits dormant as a directory; what the agent sees by default is the metadata — a name and a tight description — and the heavy contents (step-by-step procedure, reference files, scripts) are injected only when the agent activates the skill because the task matches. That's progressive disclosure as a loading model, and it changes what a skill library can be: an organization can maintain dozens of deep procedures without any agent paying for more than the catalog, because depth costs nothing until it's used. The corollary practitioners learn quickly: the description is load-bearing — it's the entire basis on which the agent decides to load, so a boring, precise stub beats a clever one.
On TrueFoundry this is the Skills Registry's native behavior: versioned SKILL.md artifacts, published with RBAC, referenced by name, and mounted on demand into the run. The registry adds what the laptop version lacks — provenance on the payloads being JIT-loaded: with versioning, RBAC, and audit history, teams can make “which procedure version did this run use?” an auditable fact rather than a guess, which matters precisely because the content isn't sitting statically in a reviewable prompt. JIT loading without versioning is dynamic behavior with no audit trail; the registry closes that gap.
The second layer is tool results — in long runs, often the bulk of the window. The naive loop pastes a 38,000-token API response into context because that's where results go; JIT inverts it with large-result offloading: the payload lands in storage, the window receives a compact handle (what it is, how big, where it lives), and the content is fetched only if a later step genuinely needs to read it. The same move appears in modern agent systems: bulky outputs are held externally while the model works with concise previews or references instead of raw payloads, and old tool outputs are replaced in place with pointers.
Code mode is the stronger form: many "read the data" steps never needed the data in the window at all — they needed a computation over it. Filtering ten thousand log lines, joining two exports, counting failures by type: the agent writes code that runs against the offloaded payload in a sandbox and returns the answer — three lines into context instead of ten thousand. The window holds conclusions; the sandbox holds bulk. Both behaviors are defaults of the harness's context-engineering suite, which is the right place for them: no model can be prompted into not receiving a payload — only the runtime that feeds the model can decide what enters.
At ground level the mechanics are unglamorous and worth seeing once. The harness intercepts the tool result before it becomes a message; over the inline threshold, the payload goes to run-scoped storage and the model receives the handle — typed, sized, addressable — so the conversation structure the API requires stays intact while the token footprint collapses by three orders of magnitude:
What the model actually sees: offloading and code mode at the message level (illustrative)
// Step 9, naive loop: the raw payload becomes the message — 38,120 tokens,
// re-sent on every subsequent step of the run.
// Step 9, JIT loop: the harness offloads and substitutes a handle — 41 tokens.
{ "role": "tool", "content": {
"offloaded": true,
"ref": "tfy://runs/8c2e/steps/9/result",
"content_type": "application/json",
"tokens": 38120,
"preview": "orders[] — 4,212 records, fields: id, status, region, total"
} }
// Later step, code mode: the agent computes over the payload in the sandbox
// — the answer enters the window; the 4,212 records never do.
df = read_ref("tfy://runs/8c2e/steps/9/result")
failed = df[df.status == "failed"].groupby("region").total.sum()
print(failed.to_dict()) # → {"emea": 41230.50, "apac": 9120.00}Two implementation details separate a robust version of this from a fragile one. The preview line is doing real work — it's the catalog entry that lets the model decide whether a later fetch is warranted, so it should carry schema and shape, not just a byte count. And in a robust implementation, handles should be run-scoped and access-controlled like any other resource: a reference the model can emit is a reference an injected prompt can probe, so resolution goes through the same gateway authorization as a tool call.
The pattern generalizes from content to work. A context-heavy subtask — investigate this log corpus, survey these files — can be JIT-delegated to a sub-agent: a fresh, isolated window absorbs the exploration, and only the distilled conclusion returns. The parent's window never contains the investigation, the way a JIT window never contains the unread handbook — the delegation rung of our tool/skill/sub-agent spectrum, read as a context instrument. The same logic applies to tool surfaces: forty preloaded descriptions are forty standing claims on attention, so the JIT posture is a curated, task-relevant set resident (the harness's preload-tools control) with the long tail discoverable on demand — making least-attention and least-privilege the same configuration.
And when a long run's history itself becomes the bulk, compaction is the cleanup counterpart to the prevention above: summarize the transcript, preserve decisions and open threads, drop the spent detail. A managed run breathes — references accumulate, payloads visit, summaries replace history — instead of monotonically filling toward the rot threshold.
JIT context as configuration, not prompting heroics (illustrative)
agent:
name: support-investigator
model: claude-sonnet-4-6
instructions: ./core.md@v6 # the stable prefix — small, cached, preloaded
skills: # catalog resident; SKILL.md mounts on activation
- refund-policy@v7
- incident-runbook@v3
mcp_servers:
- support-db: [lookup_ticket] # curated surface resident; long tail on demand
subagents:
- { name: log-analyzer, mcp_servers: [logs-readonly] } # JIT a whole subtask
harness:
tool_results: { max_inline_tokens: 4000 } # larger results offloaded, handle in window
code_mode: enabled # compute over payloads instead of reading them
compaction: { trigger_fill: 0.6 } # history summarized before it rotsThe field names above are illustrative, not a literal schema. Note in particular that sub-agents are primarily a context-isolation mechanism — they keep a heavy subtask out of the parent's window — not a privilege boundary. When you need hard privilege separation, enforce it with separate agents or scoped MCP grants and their own credentials, not by nesting a sub-agent.
An honest treatment has to draw the other boundary, because "JIT everything" is its own failure mode. The window's opening segment — core instructions, the essential tool descriptions, the agent's standing identity — should be preloaded and byte-stable, for an economic reason as much as a cognitive one: provider prompt caching makes a stable prefix dramatically cheaper on every subsequent call, and a prefix that shifts because something was "dynamically optimized" into it breaks the cache and re-bills the full segment. JIT the variable suffix; freeze the prefix — and place the cache breakpoint deliberately at the boundary, since providers cache the marked prefix and bill the suffix fresh, so a JIT mount that lands above the breakpoint silently invalidates the whole cached segment. The two patterns aren't in tension — they're the same discipline applied to content with different change rates, and the practical test is simple: if it's needed on most steps and rarely changes, preload it and keep it stable; if it's needed on few steps or changes during the run, catalog it and load late.
The test resolves into a default per kind of content:
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada






.webp)




.webp)


.webp)


