Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
9,9
Analyse comparative de la passerelle TrueFoundry LLM : c'est incroyablement rapide ⚡
TrueFoundry LLM Gateway fournit une interface unifiée compatible avec OpenAI à divers fournisseurs de LLM tels que Anthropic, OpenAI, Bedrock, Gemini et bien d'autres
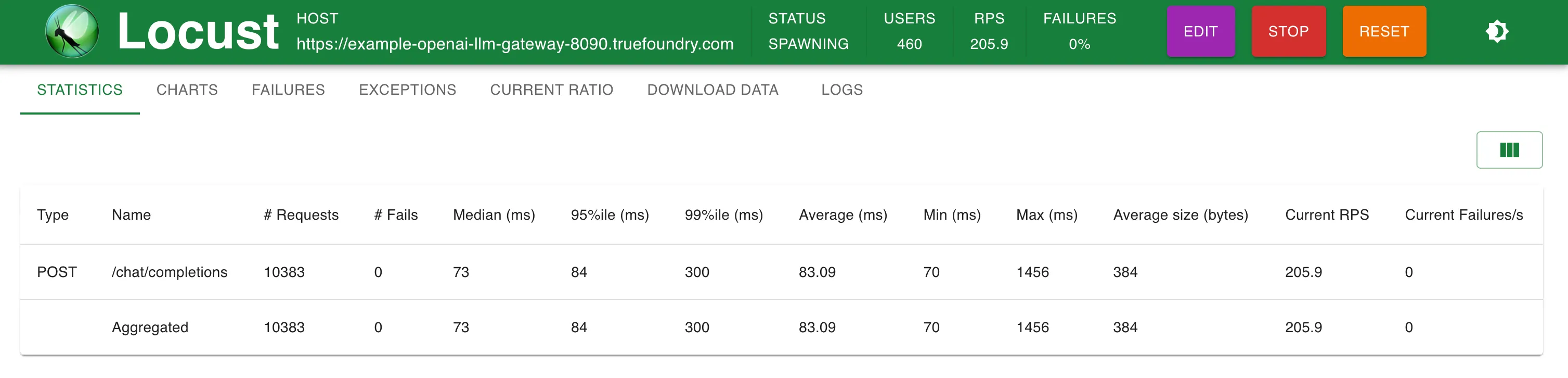
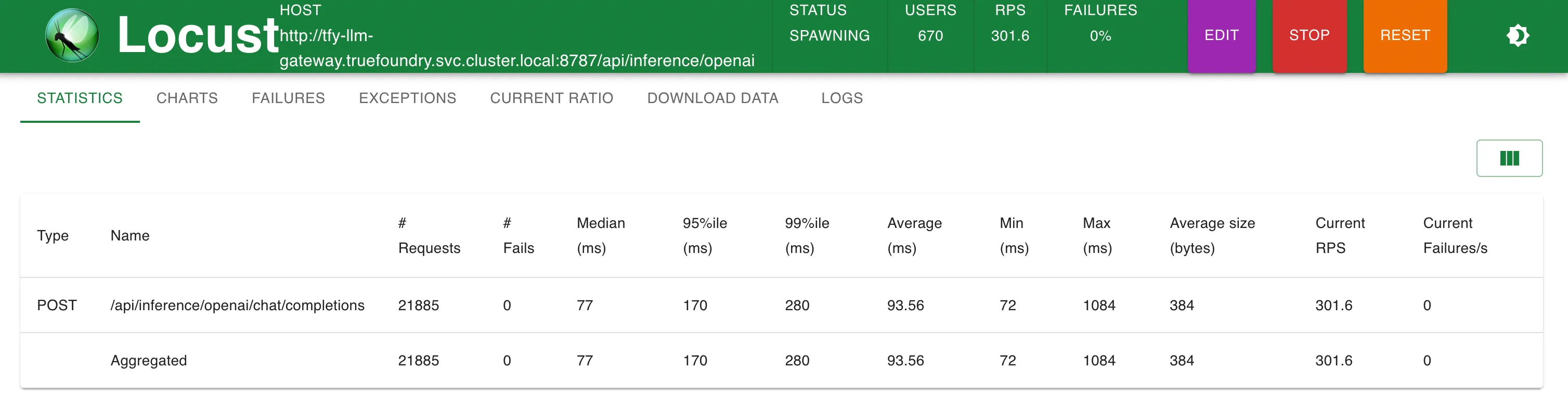
TrueFoundry LLM Gateway s'adapte parfaitement à 350 RPS sur une seule réplique d'un processeur tout en utilisant 270 Mo de mémoire. Nous avons comparé avec un autre produit de passerelle, LitelLM, sur une configuration similaire et LitelLM n'a pas réussi à dépasser 50 RPS
TrueFoundry LLM Gateway n'ajoute qu'une latence supplémentaire de 3 à 5 ms, tandis que LiteLM ajoute entre 15 et 30 ms par demande.
Pourquoi votre organisation a-t-elle besoin d'une passerelle LLM ?
Une passerelle LLM fournit une interface unifiée pour gérer l'utilisation de la LLM par votre organisation :
API unifiée: Accédez à plusieurs fournisseurs de LLM via un seul Compatible avec OpenAI interface, aucune modification de code n'est nécessaire
Sécurité des clés d'API: Gestion centralisée et sécurisée des accréditations
Gouvernance et contrôle: définissez des limites, des contrôles d'accès et un filtrage du contenu
Limitation de débit: Prévenir les abus et garantir une utilisation équitable
Observabilité: suivez l'utilisation, les coûts, la latence et les performances
Équilibrer la charge: acheminez automatiquement les demandes entre les fournisseurs
Gestion des coûts: Surveillez les dépenses et définissez des alertes budgétaires
Pistes d'audit: enregistrez toutes les interactions LLM à des fins de conformité
Quelle est la rapidité de TrueFoundry LLM Gateway ?
Configuration du test de charge
Pour notre expérience de test de charge, nous avons configuré un faux service de point de terminaison OpenAI à l'aide de TrueFoundry. Le service simulerait le format de requête et de réponse OpenAI sans produire de jetons.
Nous avons également déployé la passerelle TrueFoundry LLM et le serveur proxy LiteLLM, tous deux exécutés sur une seule réplique avec 1 unité centrale et 1 Go de mémoire.
Nous avons ajouté notre faux fournisseur OpenAI aux passerelles TrueFoundry et LiteLM. Lors des tests de charge, nous avons adressé des requêtes au faux serveur OpenAI de 3 manières différentes :
Configuration 1 : Directement sans utiliser de proxy ou de passerelle
Configuration 2 : via la passerelle TrueFoundry LLM déployée sur 1 unité centrale et 1 Go de mémoire
Configuration 3 : via le serveur proxy LiteLM déployé sur 1 unité centrale et 1 Go de mémoire
RPS
10 RPS
50 RPS
200 RPS
300 RPS
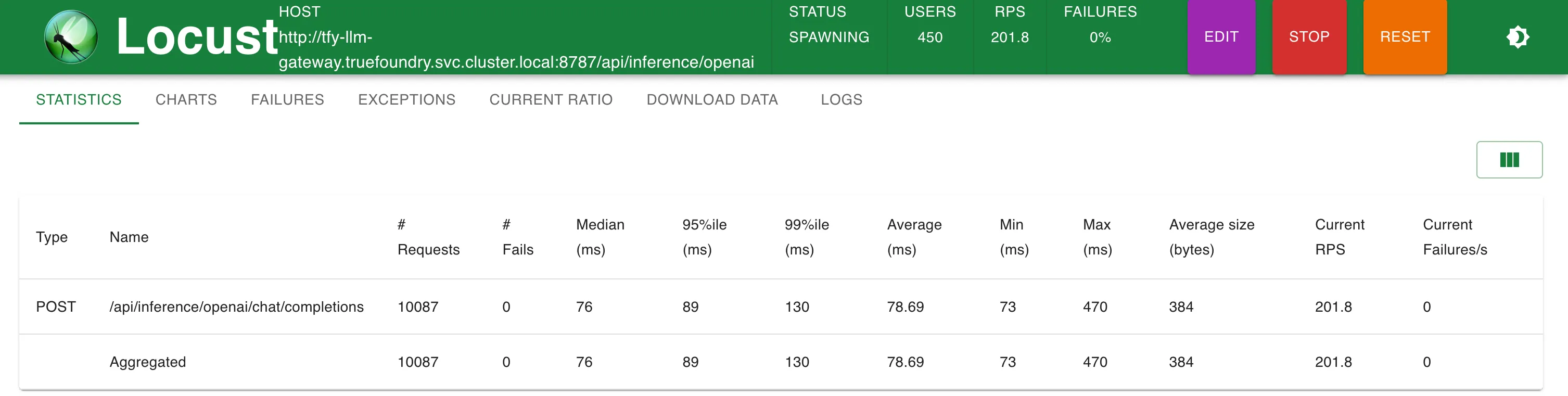
OpenAI direct (Setup 1)
73 ms
73 ms
73 ms
73 ms
TrueFoundry LLM Gateway (Setup 2)
76 ms (+3 ms)
76 ms (+3 ms)
76 ms (+3 ms)
77 ms (+4 ms)
LiteLLM Proxy (Setup 3)
88 ms (+15 ms)
99 ms (+26 ms)
Could not scale to 200 RPS
Could not scale to 300 RPS
Observations
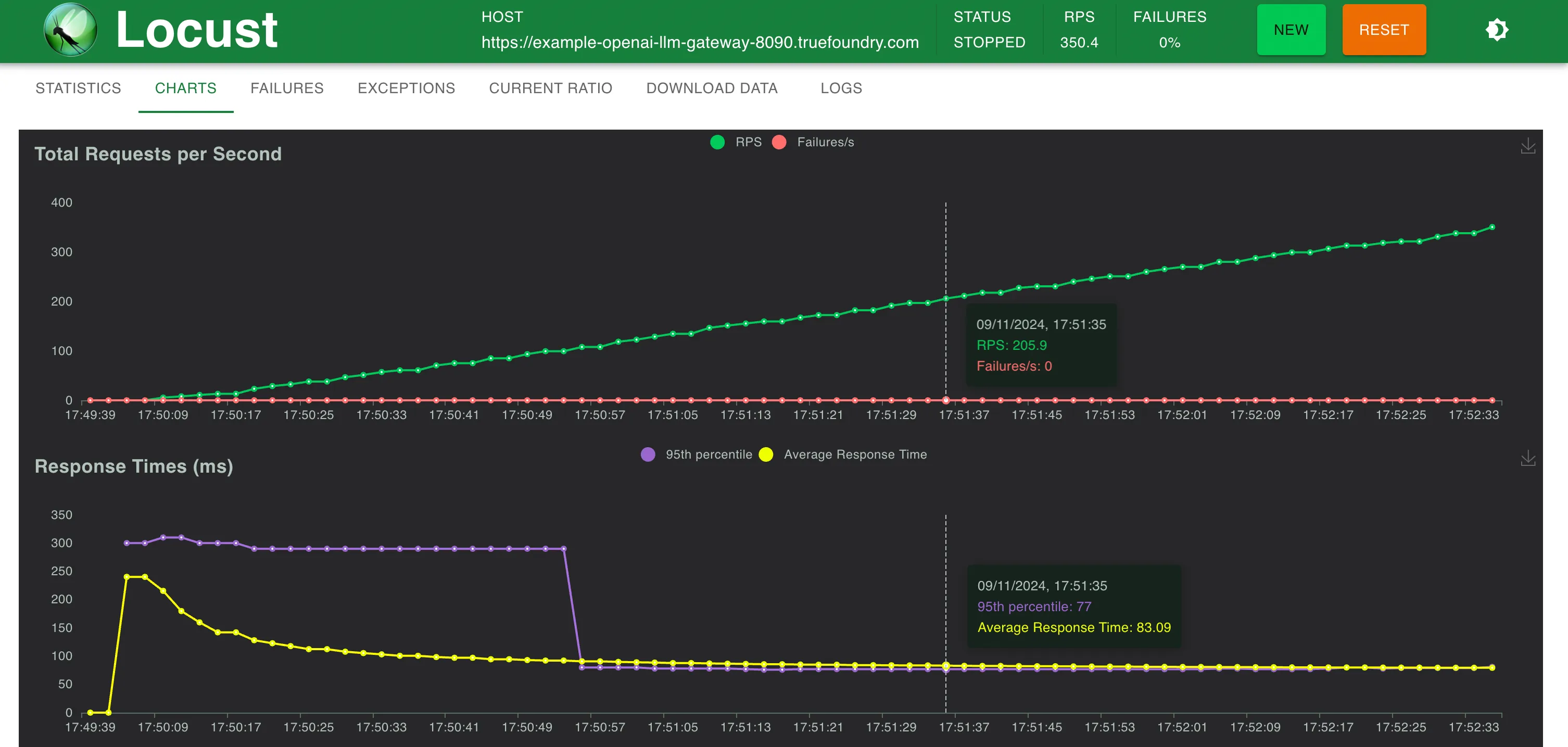
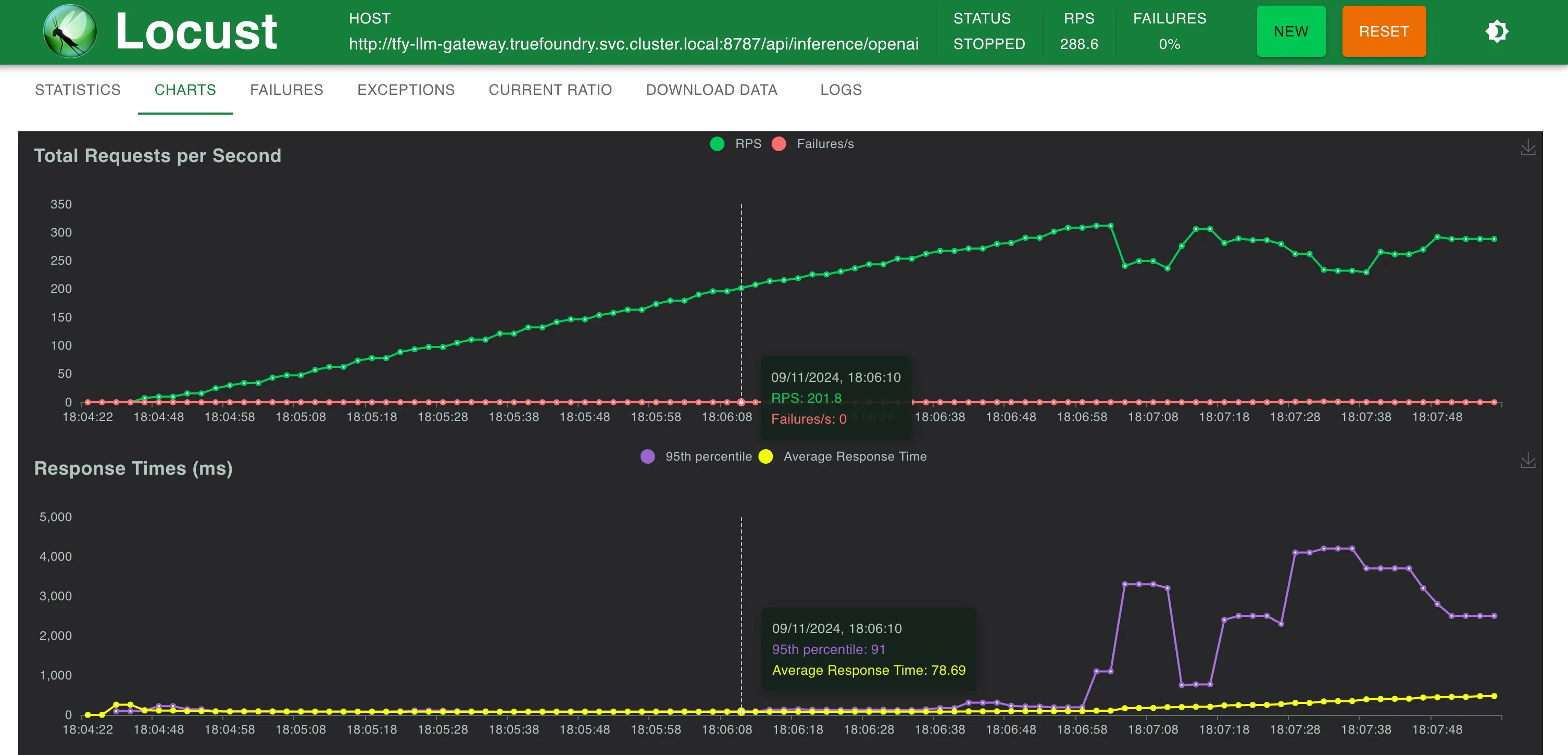
TrueFoundry Gateway n'ajoute que 3 ms supplémentaires de latence jusqu'à 250 RPS et 4 ms à RPS > 300
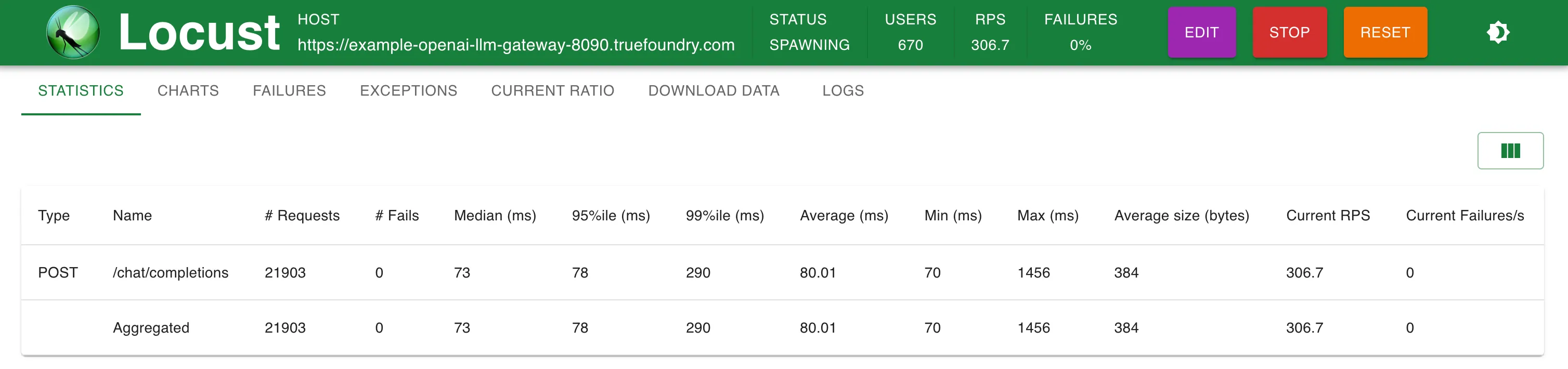
TrueFoundry LLM Gateway a pu évoluer sans aucune dégradation des performances jusqu'à environ 350 RPS (1 processeur virtuel, machine de 1 Go) avant que l'utilisation du processeur n'atteigne 100 % et les latences ont commencé à être affectées. Avec plus de processeurs ou plus de répliques, la passerelle LLM peut gérer des dizaines de milliers de requêtes par seconde.
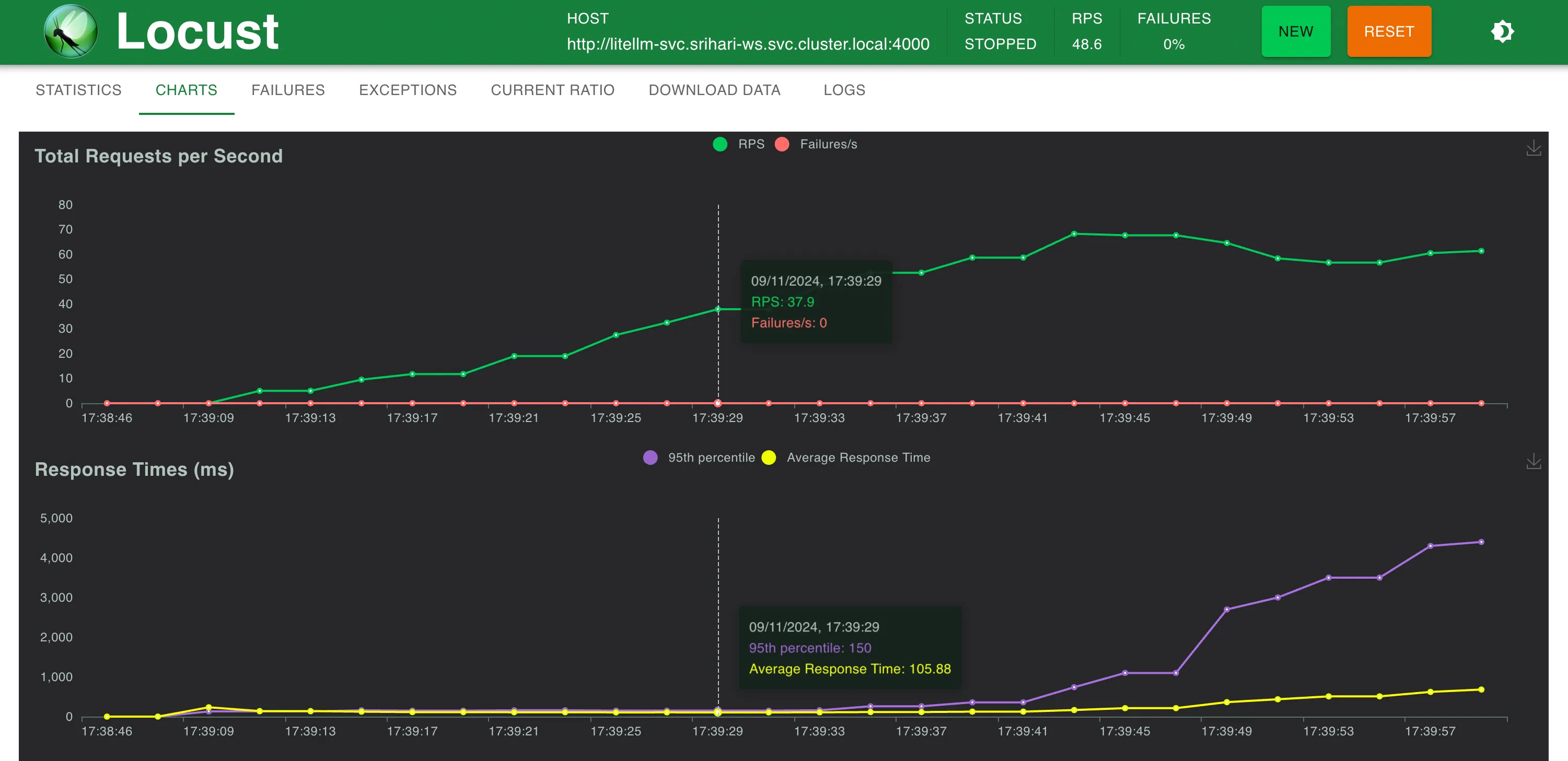
LitellM sur la même machine n'a pas pu évoluer au-delà de 40 à 50 RPS avant d'atteindre la limite du processeur
Plus de mesures
Configuration 1 : appel direct aux terminaux OpenAI
Statistiques @ 200 RPS
Statistiques à 300 RPS
Temps de réponse par rapport au RPS
Configuration 2 : passerelle TrueFoundry LLM
Statistiques @ 200 RPS
Statistiques à 300 RPS
Temps de réponse par rapport au RPS
Configuration 3 : LiteLM
Statistiques à ~58 RPS
Temps de réponse par rapport au RPS
Caractéristiques de vitesse de LLM Gateway
Frais généraux quasi nuls: Latence supplémentaire de seulement 3 à 5 ms
Backend optimisé: Construit avec le framework Node.js performant
Mise en cache de la configuration : La configuration est stockée en mémoire pour une recherche rapide
Routage intelligent: Frais de traitement minimaux
Prêt pour Edge: déployez à proximité de vos applications
Haute capacité: UNE t2,2 x grand La machine d'instance AWS (43$ par mois sur place) peut évoluer jusqu'à environ 3 000 RPS sans problème.
Déploiement en périphérie de TrueFoundry LLM Gateway
Fournisseurs pris en charge
Vous trouverez ci-dessous une liste complète des fournisseurs LLM populaires pris en charge par TrueFoundry LLM Gateway :
Provider
Streaming Supported
GCP
✅
AWS
✅
Azure OpenAI
✅
Self Hosted Models on TrueFoundry
✅
OpenAI
✅
Cohere
✅
AI21
✅
Anthropic
✅
Anyscale
✅
Together AI
✅
DeepInfra
✅
Ollama
✅
Palm
✅
Perplexity AI
✅
Mistral AI
✅
Groq
✅
Nomic
✅
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge




































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


