

May 23, 2024
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 4, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les transformateurs sont devenus une technologie révolutionnaire, redéfinissant la façon dont les ordinateurs comprennent le langage humain. Contrairement aux modèles traditionnels qui traitent les mots les uns après les autres, Transformers peut examiner une phrase entière en une seule fois, ce qui les rend incroyablement efficaces pour saisir les nuances du langage. Le Transformateur a été présenté pour la première fois dans l'ouvrage intitulé L'attention est tout ce dont vous avez besoin. Ils ont été principalement développés pour résoudre tout type de tâche qui transforme une séquence d'entrée en une séquence de sortie, telle que la traduction vocale, la transformation texte-parole, etc.
Les modèles de langage ont parcouru un long chemin, passant d'algorithmes simples basés sur des règles à des réseaux neuronaux sophistiqués. Au départ, ces modèles ne pouvaient que suivre des règles prédéfinies ou compter la fréquence des mots. Puis sont apparus les modèles statistiques, qui prédisaient les mots en fonction des mots précédents, mais avaient du mal à utiliser des phrases plus longues. L'introduction de réseaux neuronaux, en particulier les RNN et les LSTM, a marqué une amélioration significative, permettant aux modèles de mémoriser davantage de contexte. Cependant, ils continuaient à traiter le texte de manière séquentielle, ce qui limitait leur compréhension des structures linguistiques complexes.
Les Transformers ont révolutionné le traitement du langage grâce à leur capacité à traiter toutes les parties d'une phrase simultanément. Cela permet non seulement d'accélérer le temps de traitement, mais également de mieux comprendre le contexte, quelle que soit la distance entre les mots dans une phrase. L'idée principale de Transformers est le « mécanisme d'attention personnelle », qui permet au modèle de peser l'importance de chaque mot d'une phrase par rapport à tous les autres. Cette avancée technologique a permis des avancées en matière de traduction automatique, de génération de contenu et même de compréhension et de génération de texte semblable à un humain, établissant ainsi une nouvelle norme dans le domaine de la PNL.
Dans ce blog, nous allons essayer d'explorer en détail l'architecture du Transformer à la vanille.

Transformers, une nouvelle architecture d'IA, a établi de nouvelles références dans la façon dont les machines comprennent et génèrent le langage. À la base, plusieurs concepts essentiels les rendent exceptionnellement efficaces pour traiter de grandes quantités de données textuelles. Examinons ces concepts fondamentaux en analysant l'architecture et les principaux composants qui définissent les Transformers.
L'architecture de Transformers repose sur deux piliers : l'encodeur et le décodeur. L'encodeur lit et traite le texte saisi, le transformant en un format compréhensible par le modèle. Imaginez-le comme absorbant une phrase et la décomposant dans son essence. De l'autre côté, le décodeur prend ces informations traitées et les parcourt pour produire la sortie, comme pour traduire la phrase dans une autre langue. Ce va-et-vient rend Transformers si puissant pour des tâches telles que la traduction, où la compréhension du contexte et la génération de réponses précises sont essentielles.
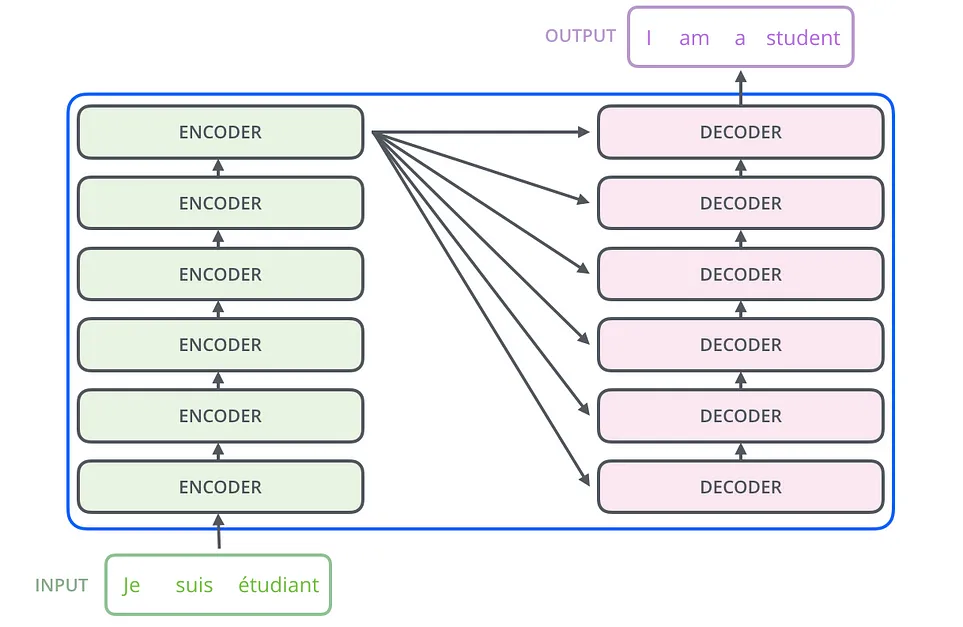
Le mécanisme d'auto-attention est au cœur de l'encodeur et du décodeur du Transformer. Cela permet au modèle d'évaluer l'importance de chaque mot d'une phrase par rapport à tous les autres mots. Ainsi, contrairement aux anciens modèles qui pouvaient perdre la trace des mots précédents dans une longue phrase, Transformers conserve une compréhension globale de l'ensemble du contexte.

Comme les Transformers traitent tous les mots d'une phrase simultanément, ils ont besoin d'un moyen de comprendre l'ordre des mots. C'est là qu'intervient le codage positionnel. Chaque mot reçoit un code unique qui représente sa position dans la phrase, ce qui permet au modèle de saisir le flux et la structure de la langue, essentiels pour comprendre le sens des phrases.
S'appuyant sur l'idée d'attention personnelle, l'attention multitête permet au modèle d'examiner la phrase sous différents angles. En divisant le mécanisme d'attention en plusieurs « têtes », Transformers peut traiter simultanément divers aspects du texte, tels que la grammaire et la sémantique, ce qui permet de mieux comprendre l'entrée.


En approfondissant les mécanismes de Transformers, vous découvrirez une architecture élégante conçue pour la compréhension et la génération de langages complexes. Nous explorerons ici les subtilités de l'encodeur et du décodeur, ainsi que la façon dont ils fonctionnent de concert pour traiter et produire le langage.
La fonction principale du codeur est de traiter la séquence d'entrée. Chaque mot de la phrase d'entrée est converti en vecteurs, qui sont de riches représentations numériques contenant l'essence de la signification du mot. Mais le travail de l'encodeur ne s'arrête pas là. Il doit également comprendre le contexte de chaque mot, son lien avec les mots qui le précèdent et le suivent.
Pour ce faire, l'encodeur utilise une série de couches, chacune composée de mécanismes d'auto-attention et de réseaux neuronaux à anticipation. Le mécanisme d'auto-attention permet à l'encodeur d'évaluer l'importance des autres mots de la phrase lorsqu'il considère un mot spécifique. Ce processus est représenté mathématiquement par la génération de vecteurs Q (requête), K (clé) et V (valeur), ce qui facilite une compréhension dynamique du contexte de la phrase.

Le décodeur prend le relais de l'encodeur, chargé de générer la séquence de sortie. Il commence par un jeton spécial indiquant le début de la sortie et utilise le contexte fourni par l'encodeur pour générer un mot à la fois. La couche d'auto-attention du décodeur garantit que chaque mot généré est approprié en fonction des mots qui l'ont précédé, tandis que la couche d'attention encodeur-décodeur permet au décodeur de se concentrer sur les parties pertinentes de la séquence d'entrée.
Cette étape du modèle Transformer est celle où se produit la génération de la langue proprement dite, qu'il s'agisse de traduire une phrase dans une autre langue, de résumer un texte ou même de générer un contenu créatif. La capacité du décodeur à prendre en compte à la fois le contexte immédiat (les mots précédents de la sortie) et le contexte plus large (la séquence d'entrée telle que traitée par l'encodeur) est cruciale pour produire un langage cohérent et pertinent sur le plan contextuel.
La véritable puissance de Transformers réside dans la synergie entre l'encodeur et le décodeur. Alors que l'encodeur fournit une compréhension approfondie de la phrase d'entrée, le décodeur exploite ces informations pour produire une sortie précise et pertinente. Cette interaction est médiatisée par le mécanisme d'attention du codeur et du décodeur, qui permet au décodeur d'interroger la sortie du codeur à chaque étape du processus de génération.
Ce mécanisme de collaboration garantit que la sortie a non seulement un sens linguistique, mais qu'elle constitue également une représentation ou une transformation fidèle de l'entrée. C'est cette synergie entre encodeur et décodeur qui permet à Transformers d'exceller dans un large éventail de tâches de traitement du langage, de la traduction automatique à la génération de contenu.
Les transformateurs ont non seulement révolutionné le domaine du traitement du langage naturel (NLP), mais ont également démontré leur polyvalence en étendant leur portée à d'autres domaines. Voici comment ils ont un impact :
Traduction: Les transformateurs ont considérablement amélioré la traduction automatique, offrant des niveaux de fluidité et de compréhension proches de ceux des humains. Google Translate en est un excellent exemple, où les modèles Transformer tels que BERT et GPT ont joué un rôle essentiel dans l'amélioration de la qualité des traductions dans de nombreuses langues.

Récapitulatif du texte: Les outils de synthèse automatisés, alimentés par les modèles Transformer, peuvent désormais produire des résumés concis de longs articles, rapports et documents, tout en conservant le contexte et les nuances du texte d'origine. Des outils tels que la série GPT d'OpenAI ont joué un rôle déterminant dans l'avancement de ce domaine, en fournissant aux utilisateurs des informations rapides à partir de longs contenus.
En brisant les barrières du texte, Transformers s'est aventuré dans le monde visuel. Les transformateurs de vision (ViT) appliquent les principes de l'attention personnelle aux pixels de l'image, obtenant ainsi des résultats de pointe dans les tâches de reconnaissance d'image. Cette approche a remis en question les réseaux de neurones convolutifs (CNN) classiques, offrant une nouvelle perspective sur le traitement de l'information visuelle.

Le moteur de recherche de Google a été suralimenté par BERT (Bidirectional Encoder Representations from Transformers), ce qui lui permet de mieux comprendre le contexte des requêtes de recherche. Cela a considérablement amélioré la pertinence des résultats de recherche, rendant la recherche d'informations plus précise pour les utilisateurs du monde entier.
Les chatbots pilotés par l'IA, qui tirent parti de la technologie Transformer, offrent des interactions plus engageantes et plus humaines. Les entreprises ont intégré ces chatbots avancés à leur service client pour fournir une assistance immédiate et contextuelle, améliorant ainsi la satisfaction client et l'efficacité opérationnelle.
GPT-3.5 et GPT-4 d'OpenAI font date dans grands modèles de langage, démontrant une capacité étonnante à générer du texte semblable à un humain, à répondre à des questions et même à coder. Ses applications vont de la création de contenu à l'aide à la programmation, mettant en valeur le vaste potentiel des transformateurs dans divers secteurs.
Alors que nous évoluons dans le paysage évolutif de l'intelligence artificielle, Transformers est à l'avant-garde de cette aventure, avec un avenir plein de promesses et de potentiel. Leur développement rapide et leur intégration dans divers domaines laissent entrevoir la voie vers des innovations encore plus révolutionnaires. Nous examinons ici les avancées et les orientations futures, ainsi que les défis et les opportunités qui nous attendent.
Le dévoilement de GPT-4 par OpenAI représente une avancée monumentale dans le domaine des grands modèles linguistiques, repoussant les limites de ce que l'IA peut accomplir en matière de compréhension et de génération de langues. Le GPT-4 surpasse non seulement ses prédécesseurs en termes de taille mais également en termes de sophistication, offrant une génération de texte encore plus nuancée, des capacités de résolution de problèmes et une meilleure compréhension des nuances du langage humain. L'horizon de GPT-4 s'étend à l'amélioration de l'interaction homme-IA, à l'automatisation de tâches complexes et à la fourniture de solutions innovantes pour d'innombrables applications. Au-delà du GPT-4, l'accent est mis de plus en plus sur la nécessité de rendre ces modèles plus efficaces, interprétables et capables de gérer un éventail encore plus large de tâches, marquant ainsi une avancée significative vers des systèmes véritablement intelligents.
Alors que nous envisageons l'avenir avec des modèles tels que GPT-4, nous sommes confrontés à des défis et à des opportunités essentiels en matière d'évolutivité, d'interprétabilité et d'éthique. L'agrandissement et la complexité de ces puissants modèles nécessitent beaucoup de puissance de calcul et d'énergie, ce qui soulève des questions quant aux coûts et à l'impact environnemental. Dans le même temps, il est important que nous puissions comprendre comment ces modèles prennent des décisions, en particulier lorsqu'ils sont utilisés dans des domaines importants tels que la santé ou la finance. En outre, nous devons tenir compte de l'aspect éthique des choses, par exemple comment empêcher la diffusion de fausses informations et comprendre les effets du remplacement des emplois par l'IA. Pour résoudre ces problèmes, toutes les personnes impliquées dans l'IA, des développeurs aux dirigeants gouvernementaux, devront déployer des efforts afin de garantir que la croissance des modèles Transformer soit responsable et bénéfique pour la société.
En résumé, les Transformers ont considérablement remodelé le paysage de l'intelligence artificielle et du traitement du langage naturel. Leur architecture unique, capable de comprendre le contexte et les nuances du langage, a permis des avancées remarquables dans des domaines tels que la traduction, la synthèse de texte et même au-delà du domaine du texte pour la reconnaissance d'images, etc.
Parmi les principaux points à retenir, citons l'importance du mécanisme d'auto-attention qui permet à Transformers de traiter des séquences entières de données simultanément, et l'utilisation innovante des encodages positionnels pour maintenir l'ordre des séquences dans le traitement des données. En outre, l'évolutivité de ces modèles, associée à la nécessité d'interprétabilité et de considérations éthiques, trace la feuille de route pour les développements futurs dans ce domaine.
Les transformateurs ne sont pas simplement une avancée technologique ; ils représentent un changement dans la façon dont nous envisageons les capacités de l'IA. Ils offrent un aperçu d'un futur où l'IA pourra comprendre et interagir avec le langage humain avec une profondeur et une flexibilité sans précédent, ouvrant de nouvelles voies pour l'automatisation, la créativité et l'efficacité dans tous les secteurs. Alors que nous continuons à explorer et à repousser les limites de la technologie Transformer, leur rôle dans la conception de l'avenir de l'IA reste essentiel, laissant entrevoir un environnement dans lequel le partenariat entre les humains et les machines atteindra de nouveaux sommets en matière de collaboration et d'innovation.
L'architecture du transformateur LLM est une conception de réseau neuronal révolutionnaire qui traite simultanément des séquences d'entrée entières. Il exploite un mécanisme d'attention personnelle pour comprendre en profondeur le contexte des mots, contrairement aux anciens modèles. Cela permet à de grands modèles linguistiques de comprendre et de générer efficacement du texte semblable à celui d'un humain, ce qui favorise les avancées en matière de traduction automatique et de création de contenu aux États-Unis.
Oui, les modèles LLM (Large Language Models) s'appuient largement sur l'architecture des transformateurs dans le développement des LLM actuels. Transformers a révolutionné le traitement du langage en traitant des phrases entières simultanément, améliorant ainsi la compréhension du contexte et la vitesse de traitement. Cette innovation fondamentale reste cruciale pour que les LLM modernes puissent générer un texte semblable à celui d'un humain et effectuer efficacement des tâches linguistiques complexes pour les utilisateurs aux États-Unis.
Un transformateur dans LLM est une architecture d'IA qui traite des phrases entières simultanément. Il utilise un mécanisme d'auto-attention pour comprendre en profondeur les relations entre les mots et le contexte. Cette technologie révolutionnaire a révolutionné la façon dont les grands modèles linguistiques apprennent et génèrent du texte semblable à celui d'un humain, essentiel pour les applications avancées et une compréhension efficace des langues.
L'architecture qui sous-tend les modèles LLM (Large Language Models) est connue sous le nom d'architecture de transformateur LLM. Cette conception intelligente les aide à comprendre et à générer un texte semblable à celui d'un humain en traitant les informations d'une manière unique. Il leur permet d'apprendre des modèles complexes à partir d'énormes quantités de données.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception






.png)

.webp)
.webp)
.webp)



.webp)
.webp)


