

May 22, 2024
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les intégrations vectorielles sont des outils sophistiqués utilisés pour convertir des données complexes et souvent non numériques, telles que du texte, des images et du son, dans un format numérique que les algorithmes d'apprentissage automatique peuvent comprendre et traiter. Cette transformation est réalisée en représentant les données sous forme de points dans un espace de grande dimension. Chaque dimension correspond à une caractéristique des données, capturant ses caractéristiques uniques.
Par exemple, dans le domaine du traitement de texte, des mots ou des phrases peuvent être convertis en vecteurs, chaque vecteur représentant l'essence sémantique et syntaxique du mot. De même, dans le traitement d'image, les intégrations peuvent capturer diverses caractéristiques visuelles telles que les bords, les couleurs ou les textures. La beauté des intégrations vectorielles réside dans leur capacité à maintenir les relations et les similitudes entre les points de données, ce qui est crucial pour des tâches telles que les recherches de similarité, le regroupement et la classification.
Les intégrations vectorielles sont indispensables dans de nombreuses applications d'apprentissage automatique, car elles améliorent considérablement l'efficience et l'efficacité de divers algorithmes. Dans le contexte des systèmes de recommandation, les intégrations aident à identifier les éléments similaires aux préférences passées de l'utilisateur, personnalisant ainsi les suggestions pour améliorer l'engagement et la satisfaction des utilisateurs. En PNL, les intégrations sont essentielles pour des tâches telles que la traduction automatique et l'analyse des sentiments, où la relation entre les mots doit être comprise et quantifiée.
De plus, les intégrations jouent un rôle crucial dans les systèmes de reconnaissance d'images et de voix, car elles permettent à ces technologies d'interpréter et de répondre aux entrées visuelles et auditives avec une précision remarquable. Cette fonctionnalité est vitale non seulement pour les applications destinées aux utilisateurs, telles que les assistants numériques et le support client automatisé, mais également dans des domaines tels que l'imagerie médicale où une interprétation précise et rapide peut faciliter le diagnostic.
Les intégrations vectorielles transforment des données abstraites et complexes en un format structuré, ce qui les rend accessibles à des fins d'analyse et d'interprétation. Cette transformation est essentielle pour développer des solutions d'IA à la fois évolutives et adaptables, faisant de l'intégration vectorielle une technologie clé de voûte de l'apprentissage automatique moderne.
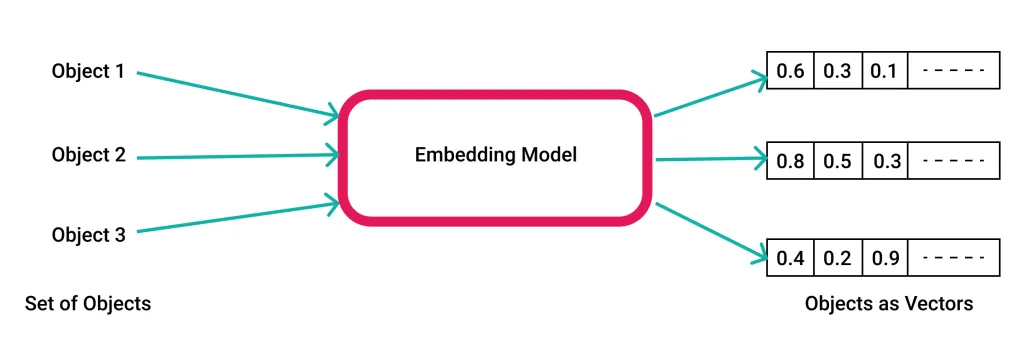
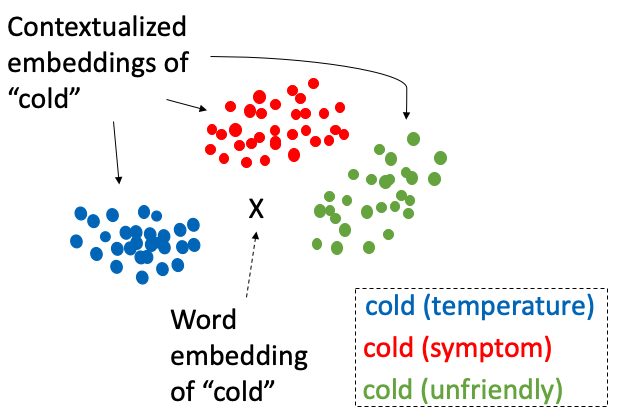
Les intégrations vectorielles sont des représentations mathématiques dans lesquelles des objets, tels que des mots, des images ou des sons, sont mappés à des vecteurs de nombres réels dans un espace vectoriel prédéfini. Chaque point de cet espace représente un objet distinct, et la disposition de ces points reflète les relations et les propriétés sous-jacentes des objets. Par exemple, dans le cas des intégrations de mots, les mots qui apparaissent dans des contextes similaires auront des vecteurs proches les uns des autres dans l'espace vectoriel.
Cette méthode de représentation permet de traduire des données complexes dans un langage que les modèles d'apprentissage automatique peuvent traiter efficacement. En convertissant les données en vecteurs, les intégrations aident les modèles à reconnaître des modèles, à faire des prédictions ou à obtenir des informations qui seraient difficiles à extraire de données brutes.
Le processus de transformation des données en intégrations vectorielles comporte plusieurs étapes, qui commencent généralement par la sélection de caractéristiques qui décrivent les objets de manière significative. Ces caractéristiques peuvent aller de la présence de mots spécifiques dans un texte à l'intensité et à la fréquence des pixels d'une image. L'étape suivante consiste à coder ces caractéristiques dans un format numérique qui capture efficacement l'essence des données.
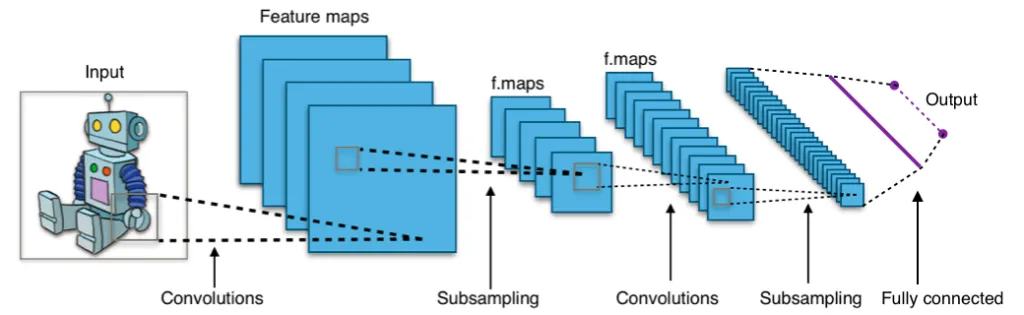
Par exemple, lorsqu'il s'agit de texte, une approche courante consiste à utiliser des modèles tels que Word2Vec ou BERT, qui analysent les contextes dans lesquels les mots apparaissent et attribuent des vecteurs numériques similaires à des mots ayant des significations similaires. Dans le traitement d'image, des techniques telles que les réseaux de neurones convolutifs (CNN) identifient et codent les motifs et les structures de l'image dans un format vectoriel.
Les intégrations vectorielles sont polyvalentes et peuvent être appliquées à un large éventail de types de données :
Les intégrations vectorielles permettent non seulement de traiter et d'analyser ces divers types de données à l'aide de l'apprentissage automatique, mais elles améliorent également la précision et les performances des algorithmes qui leur sont appliqués.
Les intégrations vectorielles sont généralement situées dans un espace de grande dimension, ce qui peut être difficile à visualiser mais qui est essentiel pour saisir les relations complexes au sein des données. Dans ce contexte, un espace de grande dimension fait référence à un espace mathématique comportant plus de dimensions que les trois dimensions spatiales auxquelles nous sommes habitués. Ces dimensions supplémentaires permettent aux intégrations de coder diverses caractéristiques et aspects des données, fournissant ainsi une représentation plus riche et plus nuancée.
La haute dimensionnalité permet de distinguer efficacement les points de données. Par exemple, dans un espace de grande dimension, même si deux mots tels que « heureux » et « joyeux » sont similaires, ils peuvent toujours être différenciés en fonction de leur utilisation dans différents contextes, ce qui serait représenté par de subtiles différences dans leurs coordonnées vectorielles.
Les métriques de distance sont fondamentales pour l'utilité des intégrations vectorielles. Ils mesurent le degré de similitude ou de dissemblance de deux points de données dans l'espace vectoriel. Les mesures de distance couramment utilisées sont les suivantes :
Ces indicateurs sont essentiels pour des tâches telles que le clustering, dont l'objectif est de regrouper des éléments similaires, ou les recherches du plus proche voisin, qui permettent de trouver les éléments les plus proches ou les plus similaires à un élément de requête donné.
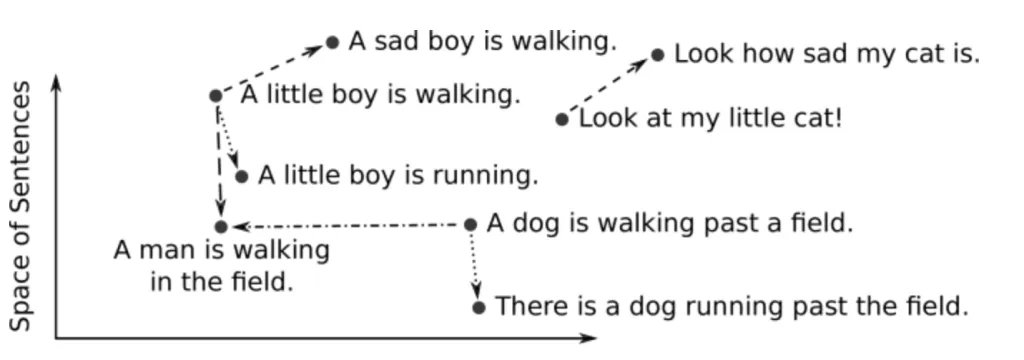
Les intégrations vectorielles nous permettent de visualiser et d'interpréter les relations entre différents points de données en examinant leur proximité dans l'espace vectoriel. Par exemple, dans un modèle d'intégration de mots bien construit, les mots ayant des significations similaires sont situés plus près les uns des autres. Cette proximité peut être visualisée à l'aide de techniques de réduction de dimensionnalité telles que t-SNE ou PCA, qui réduisent les données de haute dimension en deux ou trois dimensions qui peuvent être facilement tracées et examinées.
Ces visualisations sont non seulement utiles pour valider la qualité des intégrations, mais constituent également un outil puissant pour explorer et comprendre les modèles sous-jacents des données.
L'ingénierie des caractéristiques est une étape cruciale dans la création d'intégrations vectorielles efficaces, en particulier lorsque des connaissances de domaines spécifiques peuvent être exploitées pour améliorer les performances du modèle. Ce processus implique la sélection, la modification ou la création de fonctionnalités à partir de données brutes qui rendent les intégrations résultantes plus significatives et utiles pour des applications spécifiques.
Par exemple, en imagerie médicale, des caractéristiques telles que l'intensité des pixels, la texture de l'image et la présence de certaines formes peuvent être cruciales. Les intégrations créées à partir de ces fonctionnalités techniques peuvent aider les modèles d'apprentissage automatique à détecter des anomalies ou à diagnostiquer des maladies avec plus de précision en mettant en évidence des modèles médicalement pertinents dans les données.
Alors que l'ingénierie des fonctionnalités repose sur des techniques manuelles et une expertise dans le domaine, les méthodes d'apprentissage automatisées utilisent des algorithmes pour apprendre à créer des intégrations directement à partir de données. Cette approche est particulièrement répandue dans le traitement de grandes quantités de données ou lorsque l'ingénierie manuelle des fonctionnalités n'est pas possible.
Pour les données textuelles, des modèles tels que Word2Vec, GloVe et BERT apprennent automatiquement les intégrations de mots en analysant de grands corpus de texte. Ces modèles capturent les relations sémantiques et syntaxiques entre les mots en fonction de leur contexte au sein du corpus, créant ainsi des intégrations qui peuvent représenter efficacement la signification des mots.
Dans le domaine du traitement d'images, les réseaux de neurones convolutifs (CNN) sont utilisés pour générer automatiquement des intégrations. Les architectures populaires telles que VGG et Inception sont conçues pour capturer des caractéristiques d'image complexes à différents niveaux d'abstraction. En faisant passer des images à travers ces réseaux, chaque couche capture différents aspects de l'image, aboutissant à une intégration complète qui représente l'image entière.
Pour les données audio, des intégrations peuvent être créées à partir de spectrogrammes, des représentations visuelles du spectre des fréquences du son tel qu'il varie dans le temps. Ces intégrations capturent les caractéristiques essentielles du son, telles que la hauteur, le ton et le rythme, qui sont cruciales pour des tâches telles que la reconnaissance vocale ou la classification des genres musicaux.
Les intégrations vectorielles sont particulièrement utiles dans les applications de clustering, où l'objectif est de regrouper des éléments similaires en fonction de leurs caractéristiques codées dans les intégrations. Cette capacité est cruciale dans de nombreux domaines, qu'il s'agisse de l'organisation de grands ensembles de données ou de l'identification de modèles dans des données qui ne sont pas immédiatement apparents.
Par exemple, dans le commerce électronique, le regroupement de produits similaires permet une gestion des stocks plus efficace et des systèmes de recommandation des clients améliorés. De même, dans l'analyse des réseaux sociaux, le clustering peut aider à identifier des groupes d'utilisateurs ayant des intérêts similaires, améliorant ainsi la publicité ciblée et la diffusion de contenu.
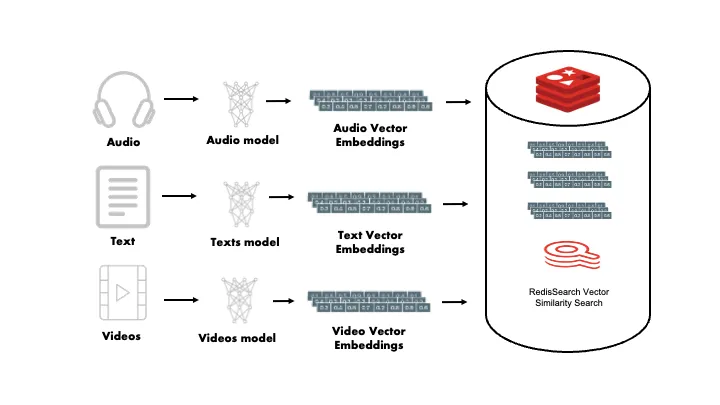
Les intégrations vectorielles font partie intégrante du fonctionnement des systèmes de recommandation, qui reposent largement sur la recherche de similitudes entre les éléments et les utilisateurs. En mappant les utilisateurs et les produits dans le même espace d'intégration, ces systèmes peuvent facilement identifier les produits à recommander en fonction de la proximité des vecteurs des utilisateurs et des articles.
Par exemple, sur les plateformes de streaming telles que Netflix ou Spotify, les intégrations permettent de personnaliser la diffusion du contenu, garantissant ainsi aux utilisateurs plus de chances de voir des films, des émissions ou de la musique correspondant à leurs préférences et habitudes de visionnage passées. Cela améliore non seulement la satisfaction des utilisateurs, mais stimule également l'engagement et la rétention.
Dans les tâches de classification, les intégrations vectorielles sont utilisées pour attribuer des étiquettes aux points de données en fonction des représentations apprises. Cette application est très répandue dans des domaines tels que la détection du spam, où les e-mails sont classés comme spam ou non en fonction de leur contenu intégré, et dans l'analyse des sentiments, où le texte est classé comme positif, négatif ou neutre.
En outre, dans le secteur de la santé, les modèles de classification utilisant des intégrations peuvent aider à prédire les diagnostics des patients en fonction de leurs symptômes et des résultats des tests, aidant ainsi les cliniciens à prendre des décisions médicales plus rapides et plus précises.
Les intégrations vectorielles simplifient le processus de recherche de similarité, qui consiste à trouver dans un ensemble de données des éléments similaires à un élément de requête. Cette fonctionnalité est essentielle pour des tâches telles que la déduplication, dans le cadre de laquelle des entrées de données similaires ou dupliquées doivent être identifiées et fusionnées ou supprimées.
Dans le domaine de la détection des anomalies, les intégrations peuvent aider à identifier les valeurs aberrantes dans les données qui s'écartent de la norme, ce qui est essentiel pour la détection des fraudes ou la sécurité du réseau. De même, dans la recherche d'images inversée, les intégrations permettent aux systèmes de récupérer des images visuellement similaires à une image de requête, ce qui est utile dans les médiathèques numériques et la vente en ligne.
Bien que les intégrations vectorielles offrent des avantages considérables, leur mise en œuvre et leur utilisation présentent des défis, principalement en ce qui concerne les ressources informatiques. La génération et le stockage d'intégrations, en particulier dans les applications à grande échelle, nécessitent une mémoire et une puissance de traitement importantes. De plus, la dimensionnalité des intégrations, facteur clé de leur efficacité, peut encore accroître ces exigences.
Les organisations doivent prendre en compte les compromis entre la qualité de l'intégration et les coûts de calcul. Des solutions d'évolutivité, telles que des infrastructures informatiques distribuées ou des systèmes de stockage efficaces tels que l'indexation approximative du voisin le plus proche (ANN), sont souvent nécessaires pour relever efficacement ces défis dans les environnements de production.
Les intégrations vectorielles peuvent être sensibles à de petites modifications des données d'entrée, ce qui entraîne des modifications disproportionnées de l'espace d'intégration. Cette sensibilité peut avoir une incidence négative sur les performances des modèles de machine learning, en particulier dans les environnements dynamiques où les données évoluent au fil du temps.
Il est crucial de développer des intégrations robustes capables de gérer de telles variations sans dégradation significative des performances. Des techniques telles que l'augmentation des données, des méthodes d'entraînement robustes et l'apprentissage continu sont utilisées pour améliorer la stabilité et la durabilité des intégrations.
La dimensionnalité des intégrations vectorielles est un paramètre essentiel qui influe à la fois sur leur efficacité et leur efficience. Des dimensions plus élevées peuvent capturer des informations plus détaillées sur les données, mais au prix d'une complexité informatique accrue et d'un risque de surajustement.
Pour choisir la bonne dimensionnalité, il faut trouver un équilibre entre la granularité des informations capturées par les intégrations et l'efficacité informatique et la capacité de généralisation des modèles qui les utilisent. Des techniques telles que la réduction de la dimensionnalité ou l'utilisation de stratégies de régularisation pendant l'entraînement peuvent aider à gérer efficacement cet équilibre.
Les intégrations vectorielles se sont révélées être une innovation essentielle dans le domaine de l'apprentissage automatique, transformant la façon dont les données complexes sont analysées et utilisées dans divers secteurs. En permettant la traduction de données abstraites et non structurées en formats numériques exploitables, les intégrations ont ouvert la voie à des applications sophistiquées qui améliorent la prise de décision, personnalisent les expériences et rationalisent les opérations.
Qu'il s'agisse d'améliorer la précision des systèmes de recommandation ou de permettre un clustering et une classification plus efficaces, la polyvalence et l'utilité des intégrations vectorielles sont indéniables. Cependant, alors que nous continuons à repousser les limites de ce que ces outils peuvent accomplir, il est essentiel de relever les défis liés à leur utilisation, notamment les exigences en matière de calcul, la sensibilité aux transformations des données et les implications éthiques de la prise de décision automatisée.
À l'avenir, l'avenir des intégrations vectorielles est prometteur et promet de nouvelles avancées en matière d'algorithmes et d'architectures de modèles. Au fur et à mesure que ces technologies seront intégrées dans les applications en temps réel, leur impact sur les opérations commerciales et la vie quotidienne ne fera que croître. Pour les chercheurs, les développeurs et les entreprises, l'évolution continue des intégrations vectorielles représente un terrain fertile pour l'innovation et une opportunité de développer les capacités de l'intelligence artificielle.
À mesure que nous progressons, l'exploration et le déploiement responsable d'intégrations vectorielles seront cruciaux pour réaliser le plein potentiel de l'IA, ce qui en fera un domaine passionnant pour la poursuite de la recherche et du développement.
Pour approfondir le monde fascinant des intégrations vectorielles et améliorer votre compréhension de leurs applications et des technologies sous-jacentes, voici quelques articles universitaires, didacticiels et outils recommandés :
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception






.png)

.webp)
.webp)
.webp)



.webp)
.webp)


