

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 12, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les grands modèles linguistiques (LLM) offrent de puissantes fonctionnalités, mais ils entraînent également des coûts d'infrastructure élevés, des modèles d'utilisation imprévisibles et des risques d'utilisation abusive. À mesure que les entreprises intègrent les LLM dans des outils destinés aux clients, des copilotes internes et des plateformes d'API, le besoin d'un accès contrôlé et fiable devient essentiel. C'est là que la limitation du débit joue un rôle clé.
Dans le contexte de l'inférence LLM, la limitation traditionnelle du débit de demandes par seconde (RPS) n'est pas suffisante. Les LLM sont gourmands en ressources, basés sur des jetons et leur charge de calcul est très variable. Une seule invite à un modèle de paramètres de 70B peut consommer des milliers de jetons et avoir un impact significatif sur la latence du GPU. Sans contrôles appropriés, l'infrastructure partagée peut rapidement devenir instable ou coûter trop cher.
Cet article explique comment fonctionne la limitation de débit dans un Passerelle IA, pourquoi elle est essentielle pour une infrastructure d'IA évolutive et comment TrueFoundry l'active par défaut pour garantir une utilisation équitable, une rentabilité et des performances de niveau production dans les déploiements multi-locataires.
La limitation de débit est un mécanisme utilisé pour contrôler le nombre de demandes qu'un client peut envoyer à un système dans un laps de temps spécifique. Il s'agit d'une fonctionnalité essentielle de la technologie moderne. Passerelles IA gestion du trafic LLM. Il garantit l'équité, prévient les surcharges et maintient la disponibilité, en particulier dans les environnements multi-utilisateurs. Les API traditionnelles appliquent souvent des limites simples, telles que 100 requêtes par minute et par utilisateur, ce qui fonctionne bien pour les services REST standard.
Cependant, les LLM fonctionnent de manière très différente. Chaque demande peut imposer une charge radicalement différente à l'infrastructure en fonction de la taille d'entrée, du type de modèle et du résultat attendu. Par exemple, une demande de 20 jetons vers un modèle 7B peut être exécutée rapidement, tandis qu'une demande de 2000 jetons vers un modèle 65B peut bloquer les GPU pendant plusieurs secondes. Même deux requêtes identiques adressées à des modèles différents peuvent varier de 5 fois ou plus en termes de coût de calcul.
Cela rend les limites basées sur les demandes insuffisantes. Les passerelles LLM modernes doivent adopter une limitation de débit tenant compte des jetons, qui tient compte du nombre réel de jetons traités et de la charge de calcul par appel.
Les principaux facteurs pris en compte dans la limitation des taux tenant compte des jetons sont les suivants :
Par rapport aux limites de demandes fixes, les limites tenant compte des jetons :
Dans les flux de travail d'IA génératifs, la limitation du débit devient encore plus critique. Un seul utilisateur peut déclencher un traitement backend à grande échelle via des instructions détaillées, l'ingestion de documents ou des agents en plusieurs étapes. Sans contrôles, cela peut entraîner une congestion du processeur graphique, une latence élevée ou des coûts imprévus.
L'utilisation dans le monde réel est souvent imprévisible, en raison des applications frontales, des boucles de test ou de l'automatisation. La limitation du débit garantit la stabilité et l'efficacité de ces interactions, même lorsque l'infrastructure est partagée entre les utilisateurs ou les locataires.
Pour tout déploiement LLM de niveau production, la limitation intelligente du débit n'est pas une fonctionnalité optionnelle, mais une exigence fondamentale en matière d'évolutivité, de fiabilité et de contrôle des coûts.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

La limitation du débit est bien plus qu'une simple garantie de backend. Pour les plateformes desservant les LLM, en particulier celles proposant des API publiques ou mutualisées, il constitue une couche stratégique pour la stabilité, la gouvernance et l'alignement des activités. Qu'il s'agisse d'OpenAI, d'Anthropic ou de plateformes créées avec TrueFoundry, les limites de débit répondent à plusieurs objectifs essentiels.
Protégez l'infrastructure contre les abus
L'inférence générative basée sur l'IA est gourmande en ressources. Une rafale soudaine de longues instructions ou de requêtes simultanées peut surcharger les files d'attente du GPU, augmenter la latence ou même interrompre les services. Les limites de débit garantissent que le trafic est traité de manière contrôlée et hiérarchisée, évitant ainsi l'épuisement des ressources.
Faites respecter l'équité entre les utilisateurs ou les locataires
Dans les systèmes multi-utilisateurs, l'utilisation d'un client ne doit pas dégrader les performances des autres. Les limites de débit permettent de renforcer l'isolement entre les utilisateurs, les équipes ou les clés d'API. Cela garantit des niveaux de service constants quel que soit le nombre d'utilisateurs actifs à la fois.
Aligner l'utilisation sur les plans tarifaires
De nombreuses plateformes Gen AI monétisent en fonction de jetons ou de niveaux d'utilisation. Les limites de débit contribuent à faire respecter ces limites. Par exemple :
Évitez les surprises et les dépassements de coûts
L'utilisation du LLM peut évoluer rapidement et silencieusement. Sans limites appropriées, la consommation de jetons et l'utilisation du GPU peuvent augmenter en flèche. La limitation des taux aide les plateformes à éviter les coûts d'infrastructure imprévus et à maintenir le contrôle budgétaire.
Améliorez la fiabilité et l'expérience utilisateur
Lorsque l'utilisation est contrôlée, les files d'attente du système restent stables. Cela se traduit par une latence plus faible, des taux de réussite plus élevés et une expérience utilisateur plus cohérente, ce qui est particulièrement important dans les environnements de production dotés de contrats de niveau de service.
Dans les systèmes basés sur LLM, toutes les demandes n'ont pas le même impact. Une courte demande adressée à un petit modèle peut utiliser un minimum de ressources, tandis qu'une longue requête adressée à un modèle de grande taille peut consommer beaucoup de temps sur le processeur graphique. En raison de cette variabilité, les plateformes modernes appliquent des limites de débit sur plusieurs dimensions au lieu de se fier uniquement au nombre de demandes.
Voici les dimensions les plus couramment utilisées pour limiter efficacement le débit :
L'utilisation de ces dimensions donne aux équipes de la plateforme la flexibilité nécessaire pour aligner l'utilisation des ressources sur les contraintes de l'infrastructure, les besoins des utilisateurs et les attentes en matière de niveau de service.
TrueFoundry fournit un système de limitation de débit robuste et flexible qui permet aux équipes de la plateforme de contrôler l'accès aux terminaux LLM en fonction des demandes ou de l'utilisation de jetons. Cela garantit une allocation équitable du calcul, prévient les abus et aligne l'utilisation sur les politiques organisationnelles ou les plans de facturation.
Au cœur du mécanisme de limitation de débit de TrueFoundry se trouve un système de configuration basé sur des règles qui permet aux équipes de définir des politiques précises pour les utilisateurs, les équipes, les comptes virtuels, les modèles et les métadonnées des demandes.
Configuration basée sur des règles
La limitation de débit dans TrueFoundry est définie par une liste de règles, chacune spécifiant :
Les règles sont évaluées dans l'ordre, de sorte que les règles plus spécifiques doivent être placées au-dessus des règles plus générales pour garantir une correspondance correcte.
Types de limites pris en charge
TrueFoundry prend en charge les limites basées sur les demandes et les limites basées sur les jetons sur différents intervalles de temps :
Cela permet d'appliquer des politiques qui reflètent l'utilisation réelle du calcul, ce qui est particulièrement important lors de la diffusion d'instructions de longueur variable à des modèles de tailles différentes.
Cas d'utilisation courants
La flexibilité du système de configuration permet de prendre en charge un large éventail de cas d'utilisation :
Exemple de configuration
nom : ratelimiting-config
type : configuration de limitation du débit de passerelle
règles :
- id : « règle spécifique »
quand :
sujets : ["user : bob@email.com «]
modèles : ["openai-main/gpt4"]
limite à : 1000
unité : requests_per_day
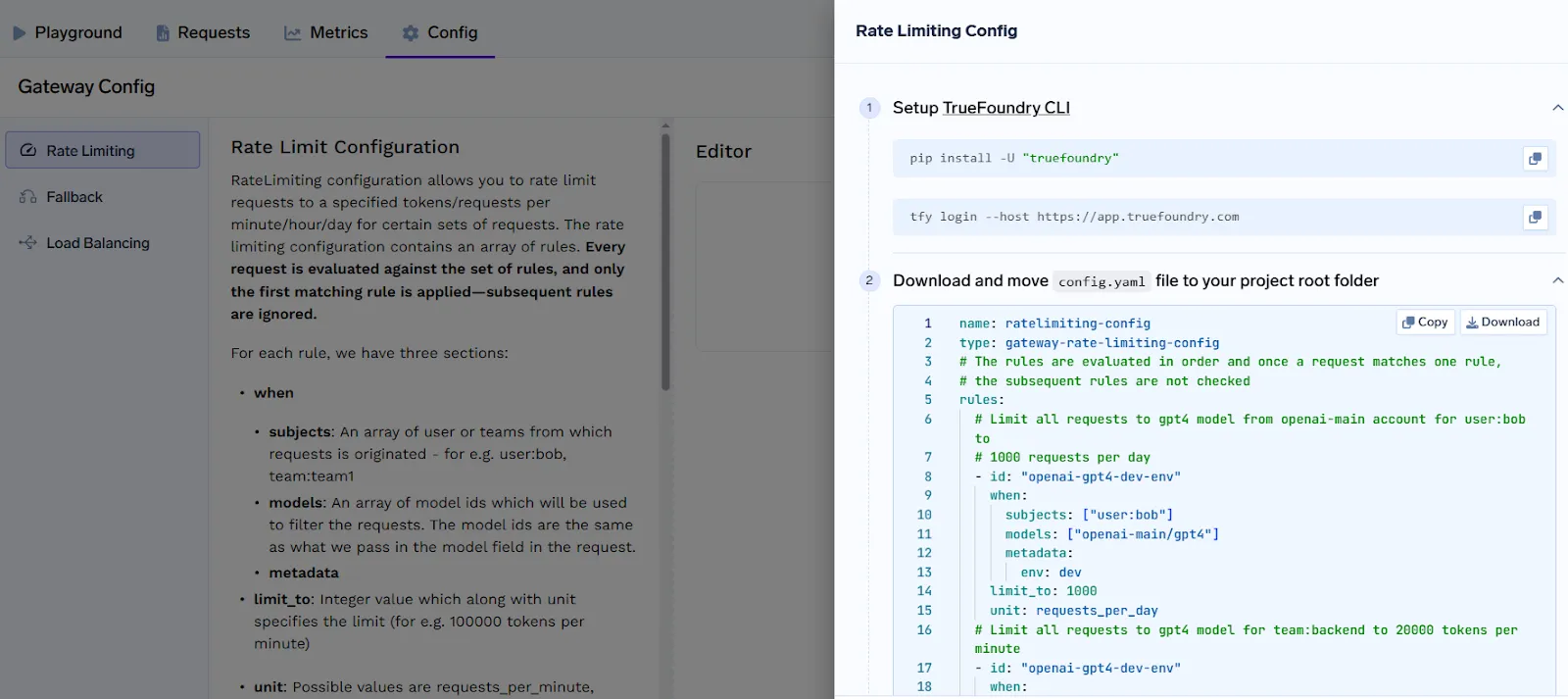
Cet exemple limite l'utilisation du GPT-4 par un utilisateur spécifique à 1 000 requêtes par jour. Le système de limitation de débit de TrueFoundry est conçu pour être à la fois puissant et facile à gérer. Grâce à des contrôles tenant compte des jetons, à un ciblage granulaire et à des politiques claires basées sur YAML, les équipes peuvent faire évoluer en toute confiance l'utilisation du LLM tout en gardant le contrôle de l'infrastructure et des coûts.
Comment appliquer la configuration
1. Installez la CLI TrueFoundry :
pip install -U « truefoundry »
essayez de vous connecter --host https://app.truefoundry.com
2. Placez votre config.yaml dans le répertoire de votre projet.
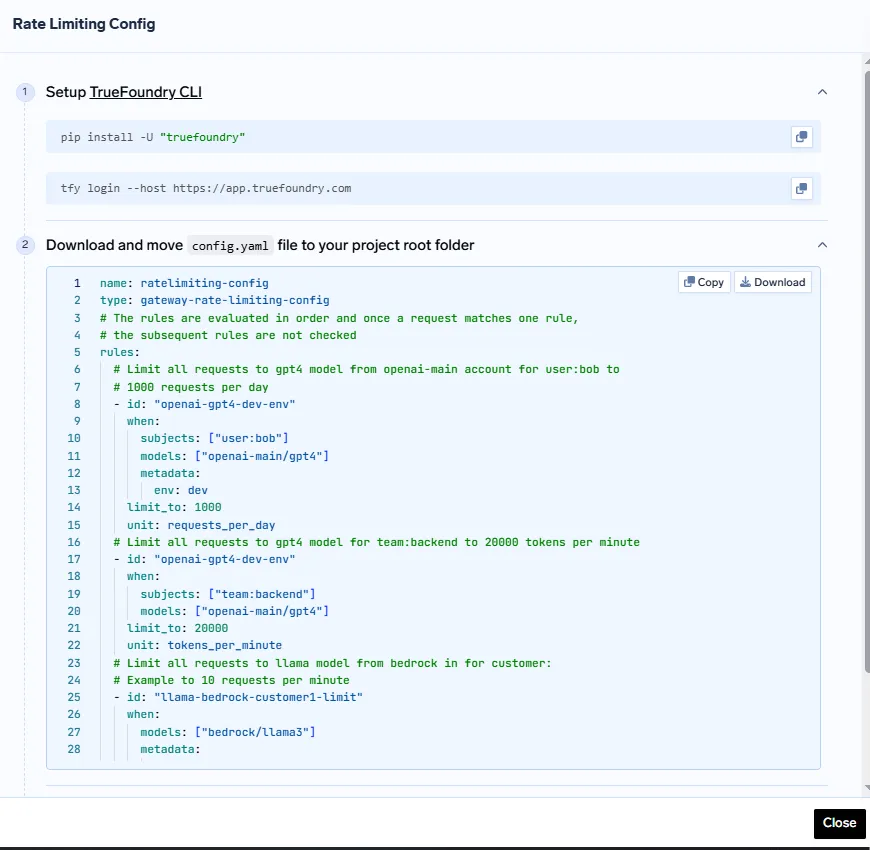
3. Appliquez la configuration à l'aide de :
essayez d'appliquer -f config.yaml
Cette approche déclarative garantit que les limites de débit sont contrôlées par version, reproductibles et conformes aux meilleures pratiques de GitOps.
Feedback en temps réel sur les limites de débit
Le système de limitation de débit de TrueFoundry est conçu pour fournir un feedback immédiat et transparent aux clients lorsque les limites sont dépassées ou presque épuisées. Cela aide les développeurs à comprendre les limites d'utilisation et à gérer la limitation avec élégance dans leurs applications.
Lorsqu'une demande dépasse la limite de débit définie :
Ce mécanisme de feedback favorise un meilleur comportement des clients, permet une logique de nouvelle tentative automatisée et garantit que l'utilisation reste dans les limites des quotas sans conjectures.
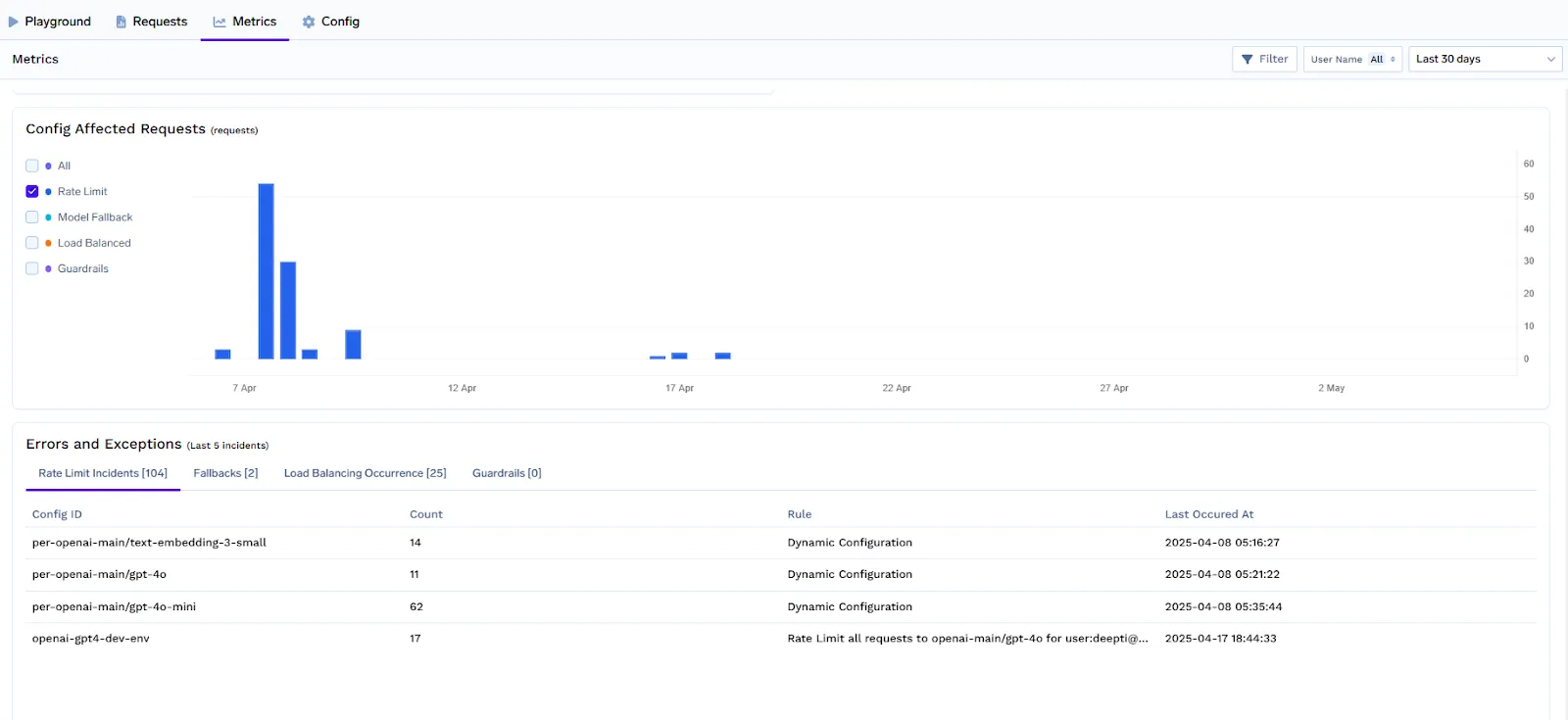
Tableaux de bord et alertes
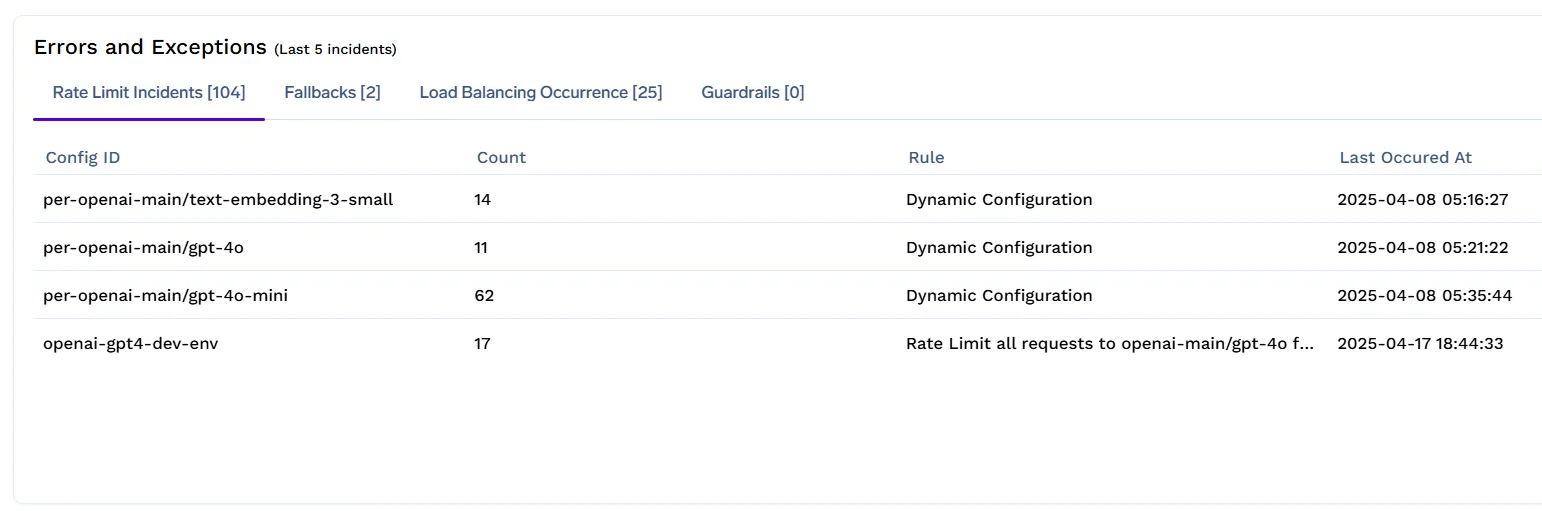
TrueFoundry fournit une observabilité intégrée pour aider les équipes de la plateforme à surveiller et à optimiser les politiques de limites de débit en temps réel.
À l'aide du tableau de bord LLM Gateway, vous pouvez suivre :
Ces informations permettent de détecter les abus, d'ajuster les limites de manière proactive et de garantir aux utilisateurs de grande valeur un service cohérent.
Lorsque les API LLM échouent, que ce soit en raison de limites de débit, d'erreurs internes ou de pannes temporaires, les mécanismes de secours assurent le bon fonctionnement de vos applications. Au lieu de renvoyer les erreurs à l'utilisateur final, TrueFoundry peut automatiquement acheminer la demande vers un modèle ou un fournisseur de sauvegarde, en maintenant la disponibilité avec un minimum de perturbations.
Les règles de secours sont déclenchées en fonction de conditions spécifiques telles que l'ID du modèle, l'utilisateur ou l'équipe demandeur et des codes de réponse tels que 429 ou 500. Lorsqu'une demande répond à ces conditions, elle est acheminée vers un ou plusieurs modèles alternatifs spécifiés dans la configuration de secours. Ces cibles de repli peuvent éventuellement inclure des remplacements de paramètres tels que la température ou les jetons maximum, ce qui permet d'affiner le comportement en fonction du fournisseur du modèle. Seule la première règle d'appariement est appliquée lors de l'évaluation, ce qui garantit une gestion prévisible et déterministe des défaillances.
Une règle de repli typique dans TrueFoundry inclut les éléments suivants :
Exemple de configuration de secours :
nom : model-fallback-config
type : gateway-fallback-config
# Les règles sont évaluées dans l'ordre. Une fois qu'une demande correspond à une règle, les règles suivantes ne sont pas vérifiées.
règles :
# Revenir à gpt-4 sur Azure ou AWS si openai-main/gpt-4 échoue avec 500 ou 503.
# La cible openai-main remplace également certains paramètres de requête tels que temperature et max_tokens.
- identifiant : « openai-gpt4-fallback »
quand :
modèles : ["openai-main/gpt4"]
codes d'état de réponse : [500, 503]
modèles_de secours :
- cible : openai-main/gpt-4
override_params :
température : 0,9
nombre maximum de jetons : 800
# Revenir à LLama3 sur Azure ou AWS si bedrock/llama3 échoue avec 500 ou 429 pour customer1.
- identifiant : « llama-bedrock-customer1-fallback »
quand :
modèles : ["bedrock/llama3]
métadonnées :
identifiant du client : customer1
codes d'état de réponse : [500, 429]
modèles_de secours :
- cible : aws/llama3
- cible : azure/lama3
La passerelle LLM Gateway de TrueFoundry prend en charge de manière native la configuration déclarative de secours dans le cadre de son système de configuration. Cela permet aux équipes de définir des politiques de routage tolérantes aux pannes et de préserver la disponibilité sans intervention manuelle, en particulier lorsqu'elles travaillent avec plusieurs fournisseurs. Ensemble, la limitation intelligente du débit et la solution de repli automatisée constituent la base des services d'IA de haute disponibilité de génération.
Dans toute plateforme d'IA mutualisée, la limitation des tarifs est cruciale pour garantir la stabilité, l'équité et la gouvernance des coûts. Il permet aux équipes de définir des limites d'accès non seulement pour les utilisateurs individuels, mais également entre les équipes, les comptes virtuels et les modèles spécifiques sans avoir besoin d'une logique personnalisée.
La passerelle de TrueFoundry prend en charge la limitation de débit déclarative via la configuration YAML, où les règles sont évaluées dans l'ordre. La première règle de correspondance est appliquée, ce qui signifie que les règles les plus spécifiques doivent être placées en haut, tandis que les règles plus génériques doivent être placées plus bas dans la configuration. Cette structure garantit un contrôle par couches tout en maintenant des configurations propres et lisibles.
Chaque règle peut inclure les éléments suivants :
Exemples de limitation des tarifs pour locataires multiples
Limiter les demandes spécifiques des utilisateurs : Supposons que vous souhaitiez limiter toutes les requêtes au modèle gpt4 depuis le compte openai-main pour les utilisateurs bob@email.com et jack@email.com à 1000 requêtes par jour :
- identifiant : « limite utilisateur gpt4 »
quand :
sujets : ["utilisateur : bob@email.com «, « utilisateur : jack@email.com «]
modèles : ["openai-main/gpt4"]
limite à : 1000
unité : requests_per_day
Appliquez des limites à l'échelle de l'équipe : Si vous souhaitez limiter le nombre total de demandes pour l'équipe « frontend » à 5 000 par jour
- id : « limite d'interface d'équipe »
quand :
sujets : ["team:frontend"]
limite à : 5000
unité : requests_per_day
Restreindre les comptes virtuels : Si vous souhaitez plafonner le nombre de demandes pour le compte virtuel « va-james » à 1500 par jour
- identifiant : « va-james-limit »
quand :
sujets : ["virtualaccount:va-james"]
limite à : 1500
unité : requests_per_day
Définissez des plafonds globaux pour tous les utilisateurs et modèles :
- identifiant : « {utilisateur} - {model} -daily-limit »
quand : {}
limite à : 1000000
unité : tokens_per_day
Cette configuration permet aux équipes de la plateforme de segmenter l'utilisation entre les unités commerciales, d'appliquer des quotas par environnement et de protéger les terminaux des modèles coûteux tout en prenant en charge des charges de travail d'IA évolutives et fiables.
La limitation de débit est bien plus qu'un simple contrôle du backend. Il s'agit d'un outil essentiel pour une utilisation fiable, rentable et équitable de l'infrastructure LLM à grande échelle. Que vous exploitiez une plateforme mutualisée, que vous proposiez un accès hiérarchisé aux clients ou que vous exécutiez des charges de travail internes d'IA entre équipes, la mise en œuvre de limites de débit intelligentes tenant compte des jetons garantit la prévisibilité de votre système sous pression.
Outre la limitation du débit, des fonctionnalités telles que le routage de secours, le feedback en temps réel et la configuration granulaire fournissent aux équipes d'ingénierie les outils nécessaires pour équilibrer performances et contrôle. La passerelle LLM Gateway de TrueFoundry associe ces fonctionnalités à une interface déclarative, permettant aux équipes de la plateforme de définir des politiques transparentes, vérifiables et alignées sur les objectifs de l'organisation.
Alors que l'adoption générative de l'IA s'accélère, les systèmes qui appliquent un contrôle d'accès intelligent sans sacrifier l'expérience utilisateur ou la disponibilité définiront la prochaine génération de résilience de l'infrastructure. Si vous créez ou développez une passerelle IA, la limitation du débit n'est pas simplement un élément à prendre en compte. C'est quelque chose à régler dès le premier jour.
La limitation de débit dans la passerelle LLM fait référence au mécanisme utilisé pour contrôler la fréquence des demandes entrantes ou le volume de jetons qu'un utilisateur, une équipe ou une application peut traiter dans un laps de temps spécifique. Contrairement à la limitation des API traditionnelles, elle prend en compte les jetons et prend en compte la charge de calcul réelle des différentes architectures de modèles, garantissant ainsi que les requêtes gourmandes en ressources ne bloquent pas le système.
La mise en œuvre d'une limitation de débit dans les environnements de passerelles LLM permet de contrôler les coûts en évitant les pics inattendus de consommation de jetons et l'emballement des scripts. En fixant des quotas quotidiens ou horaires précis, les entreprises peuvent plafonner les dépenses pour des utilisateurs spécifiques ou des environnements hors production, garantissant ainsi que les expériences d'IA restent dans les limites d'un budget prévisible tout en se protégeant contre les surprises coûteuses en matière de facturation.
La limitation du débit dans les configurations de passerelles LLM est essentielle pour protéger l'infrastructure contre les abus et garantir une haute disponibilité pour tous les utilisateurs. Cela empêche un seul « voisin bruyant » d'épuiser les quotas des fournisseurs ou la capacité du GPU, ce qui entraînerait une augmentation de la latence et de fréquentes erreurs 429 « requêtes trop nombreuses ». Cette couche de gestion est essentielle pour maintenir des SLA stables en production.
Les stratégies courantes de limitation du débit dans la passerelle LLM incluent les limites de demande par minute (RPM) et de jeton par minute (TPM), qui fournissent une mesure précise de l'utilisation des ressources. Les passerelles avancées prennent également en charge des limites hiérarchisées en fonction des rôles des utilisateurs ou des types de modèles, ce qui permet de donner une priorité plus élevée aux tâches critiques tandis que les charges de travail de développement les moins prioritaires sont limitées en période de congestion.
Bien qu'elle n'ajoute qu'une petite étape de traitement, la limitation de débit dans la passerelle LLM entraîne généralement moins de 4 millisecondes de surcharge, ce qui est négligeable par rapport aux secondes nécessaires à la génération du modèle. En fait, il améliore souvent la latence perçue en empêchant la saturation des files d'attente du backend, garantissant ainsi un traitement fluide des demandes sans provoquer de délais d'attente ni de pannes de service.
Oui, TrueFoundry fournit une implémentation de niveau production de la limitation de débit dans la passerelle LLM via une configuration déclarative basée sur des règles. Il permet aux équipes d'appliquer des limites tenant compte des jetons à plusieurs fournisseurs de modèles et locataires à l'aide de simples fichiers YAML. Ce système fournit des commentaires en temps réel et des tableaux de bord détaillés, permettant aux équipes de la plateforme de dimensionner les charges de travail liées à l'IA tout en maintenant une gouvernance stricte des coûts et des ressources.
La limitation du débit de l'IA fonctionne en suivant la fréquence à laquelle un utilisateur envoie des requêtes à une API d'IA. Le système compte les demandes ou les jetons dans une fenêtre temporelle. Si l'utilisateur dépasse la limite autorisée, l'API bloque temporairement les nouvelles demandes ou renvoie une erreur jusqu'à ce que la limite soit réinitialisée. Cela protège les serveurs contre les surcharges.
Absolument. En plafonnant l'utilisation des jetons et les taux de demandes, les passerelles empêchent la surutilisation inattendue du GPU ou les dépenses liées au cloud. Les entreprises peuvent aligner l'utilisation sur les budgets, planifier un accès hiérarchisé et réduire le surprovisionnement coûteux tout en maintenant un service cohérent pour les charges de travail critiques.
Oui Les passerelles d'intelligence artificielle modernes telles que TrueFoundry permettent aux équipes de mettre à jour les règles de limite de débit en temps réel ou via des scripts automatisés, garantissant ainsi que l'infrastructure peut gérer les surtensions inattendues sans interruption ni dégradation des performances. Les ajustements dynamiques permettent de maintenir la réactivité du service tout en maintenant une utilisation équitable entre les locataires.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


