

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
%20(11).webp)
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
L'incitation, le réglage fin et la génération augmentée par extraction (RAG) sont les techniques d'apprentissage LLM les plus populaires. Le choix de la bonne technique implique une évaluation minutieuse des exigences, des ressources et des résultats souhaités de votre projet.
Dans les sections suivantes, nous approfondirons chaque technique, en discutant de ses subtilités, de ses applications et de la manière de choisir celle qui convient le mieux à vos besoins

La première étape pour choisir entre l'invite, le réglage et le RAG consiste à examiner de près les données dont vous disposez et le problème spécifique que vous souhaitez résoudre. Déterminez si votre tâche implique des connaissances communes, des informations spécialisées ou nécessite des données à jour provenant de sources externes. La complexité du problème, le style et le ton du résultat souhaité, ainsi que le niveau de personnalisation requis sont également des facteurs critiques.
Si vous traitez de sujets hautement spécialisés ou spécialisés, des ajustements ou un RAG peuvent être nécessaires pour atteindre le niveau de précision et de pertinence souhaité. D'un autre côté, si votre projet implique des requêtes plus générales ou la création de contenu, les incitations peuvent être suffisantes et plus rentables.
Le choix entre l'incitation, la mise au point et le RAG dépend également des contraintes budgétaires. L'incitation est généralement la méthode la moins gourmande en ressources, car elle utilise le modèle tel quel. La mise au point nécessite des données et des ressources informatiques supplémentaires pour la formation, ce qui entraîne une augmentation des coûts. Le RAG peut également être gourmand en ressources, en particulier s'il implique la mise en place et la maintenance d'une base de données externe à des fins de récupération.
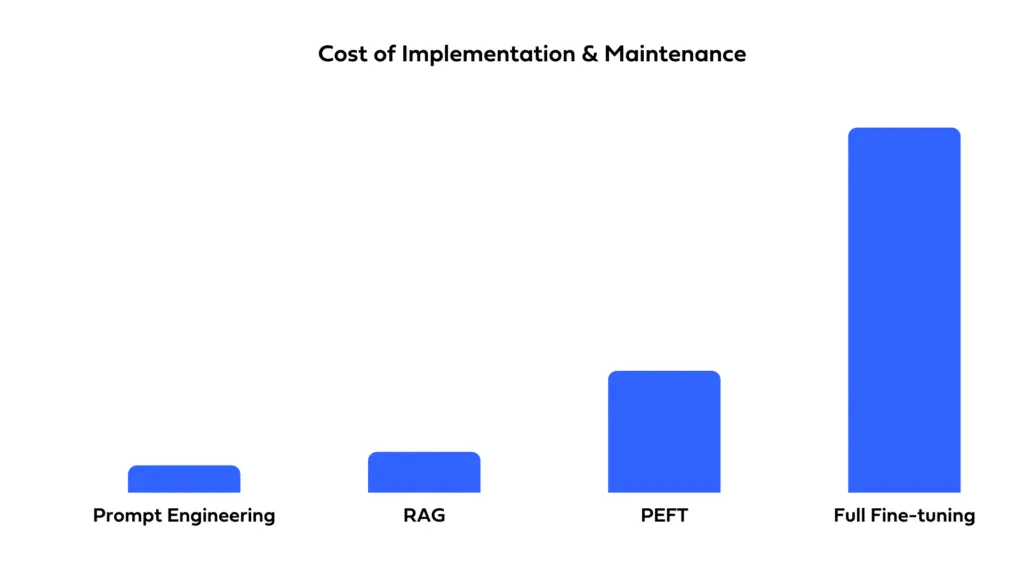
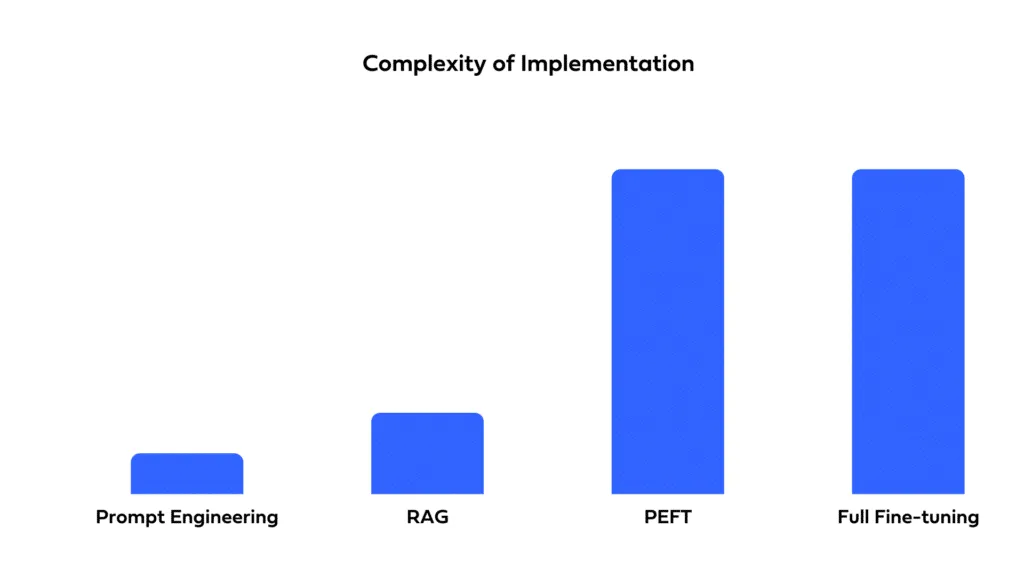
Réfléchissez à la rapidité avec laquelle vous devez déployer votre solution et aux ressources dont vous disposez. Les instructions permettent un déploiement rapide avec un temps de configuration minimal. La mise au point, tout en offrant potentiellement de meilleures performances, nécessite du temps pour la formation et l'optimisation. Le RAG implique la complexité de l'intégration de sources de données externes, ce qui peut prolonger les délais de développement et nécessiter une expertise spécialisée.
RAG facilite l'attribution des sources, permettant aux utilisateurs de discerner l'origine des informations utilisées pour générer la réponse. L'invite et le réglage fin agissent comme une boîte noire, ce qui rend difficile la traçabilité des réponses.

Le prompting est idéal pour les projets qui nécessitent des solutions rapides et rentables et qui peuvent s'appuyer sur la base de connaissances générales de modèles pré-entraînés. Il convient à des applications telles que :
Bien que les instructions soient très accessibles, elles ne fournissent pas toujours la précision ou la personnalisation nécessaires pour des tâches spécialisées. La qualité des sorties peut varier considérablement en fonction de la conception de l'invite, ce qui nécessite une conception et des tests minutieux.
Le réglage fin est la méthode de choix lorsque votre projet exige un haut degré de spécificité ou doit s'aligner étroitement sur des styles, des tons ou des connaissances spécifiques à un domaine. Il est particulièrement efficace pour :
La décision de peaufiner devrait prendre en compte le compromis entre l'amélioration des performances et les coûts et ressources supplémentaires requis. C'est essentiel pour les projets où la valeur de la personnalisation et de la précision l'emporte sur ces considérations.
RAG excelle dans les situations où les réponses doivent être complétées par les dernières informations ou des données détaillées provenant de domaines spécifiques. Il est particulièrement adapté pour :
RAG peut fournir des résultats supérieurs pour des requêtes complexes et des domaines de connaissances spécialisés, mais s'accompagne d'une complexité et de besoins en ressources accrus. C'est le bon choix lorsque l'envergure du projet justifie l'investissement dans la mise en place et la maintenance de l'infrastructure nécessaire à la récupération des données en temps réel
L'invite est activée par notre Passerelle LLM module, qui prend en charge les flux de travail souvent associés au meilleurs outils d'ingénierie rapides utilisé pour les applications LLM de production. LLM Gateway propose une API unifiée qui permet aux utilisateurs d'accéder à différents fournisseurs LLM, y compris à leurs propres modèles auto-hébergés, via une plate-forme unique. Il propose des fonctionnalités centralisées de gestion des clés, d'authentification et d'attribution des coûts. En outre, il prend en charge le repli, les nouvelles tentatives ainsi que l'intégration aux garde-corps.
Nous avons modélisé le flux de travail pour configurer RAG en quelques clics. Lisez notre blog pour savoir comment déployer un Chatbot basé sur RAG à l'aide de TrueFoundry. Il prend en charge le processus de bout en bout consistant à créer une base de données vectorielles, à intégrer un modèle, à des LLM, etc., tout en vous offrant les bons contrôles pour personnaliser le flux de travail en fonction de vos besoins.
TrueFoundry a simplifié le réglage fin processus en éliminant toutes les subtilités et en configurant les bonnes configurations de ressources pour les techniques LoRA/QLoRa. Vous pouvez déployer un bloc-notes Jupyter pour effectuer des essais ou lancer une tâche de réglage dédiée. Veuillez lire le guide détaillé ici.
Nous mangeons True Foundry prend en charge les trois techniques d'apprentissage du LLM : l'incitation, le RAG et le réglage fin de manière extrêmement rationalisée.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


