

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: May 20, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les passerelles sont en train de devenir le plan de contrôle opérationnel des systèmes GenAI. Ils unifient le trafic pour les API tierces (OpenAI, Anthropic, Mistral, Bedrock) et les modèles auto-hébergés, appliquent les politiques et présentent une interface unique pour la latence, les erreurs, la consommation de jetons et les dépenses. Ce même point d'étranglement est l'endroit idéal pour capturer des traces, effectuer des analyses au niveau du modèle et au niveau de l'utilisateur, et déclencher des garde-fous et des alertes, sans ajouter de latence au chemin de la demande.
Les véritables organisations l'ont appris à leurs dépens. Prenons l'exemple d'un copilote d'assistance au service de milliers d'agents. Un après-midi, une mise à jour rapide et anodine augmente la longueur de sortie d'environ 40 %. La satisfaction des agents diminue à mesure que les réponses sont en retard ; le ministère des Finances prend note de la facture. Grâce à l'observabilité de la passerelle, vous pourriez voir la latence p95 et les jetons de sortie augmenter pour la route concernée, la corréler au déploiement ou à la version rapide, puis revenir en arrière, idéalement avec une alerte automatique configurée pour la détecter la prochaine fois.
Cet article récapitule ce qu'est une passerelle IA, pourquoi l'observabilité est essentielle et décrit les mesures, les tableaux de bord et les flux de travail concrets que les équipes devraient mettre en place. Nous montrerons également comment la passerelle IA de TrueFoundry fournit la solution d'observabilité prête à l'emploi : analyses unifiées (latence, TTFT/ITL, erreurs), suivi granulaire des coûts, ventilations au niveau du client/utilisateur, visibilité du routage saine ou défaillante, et collecte évolutive et à faible coût intégrée à l'architecture.
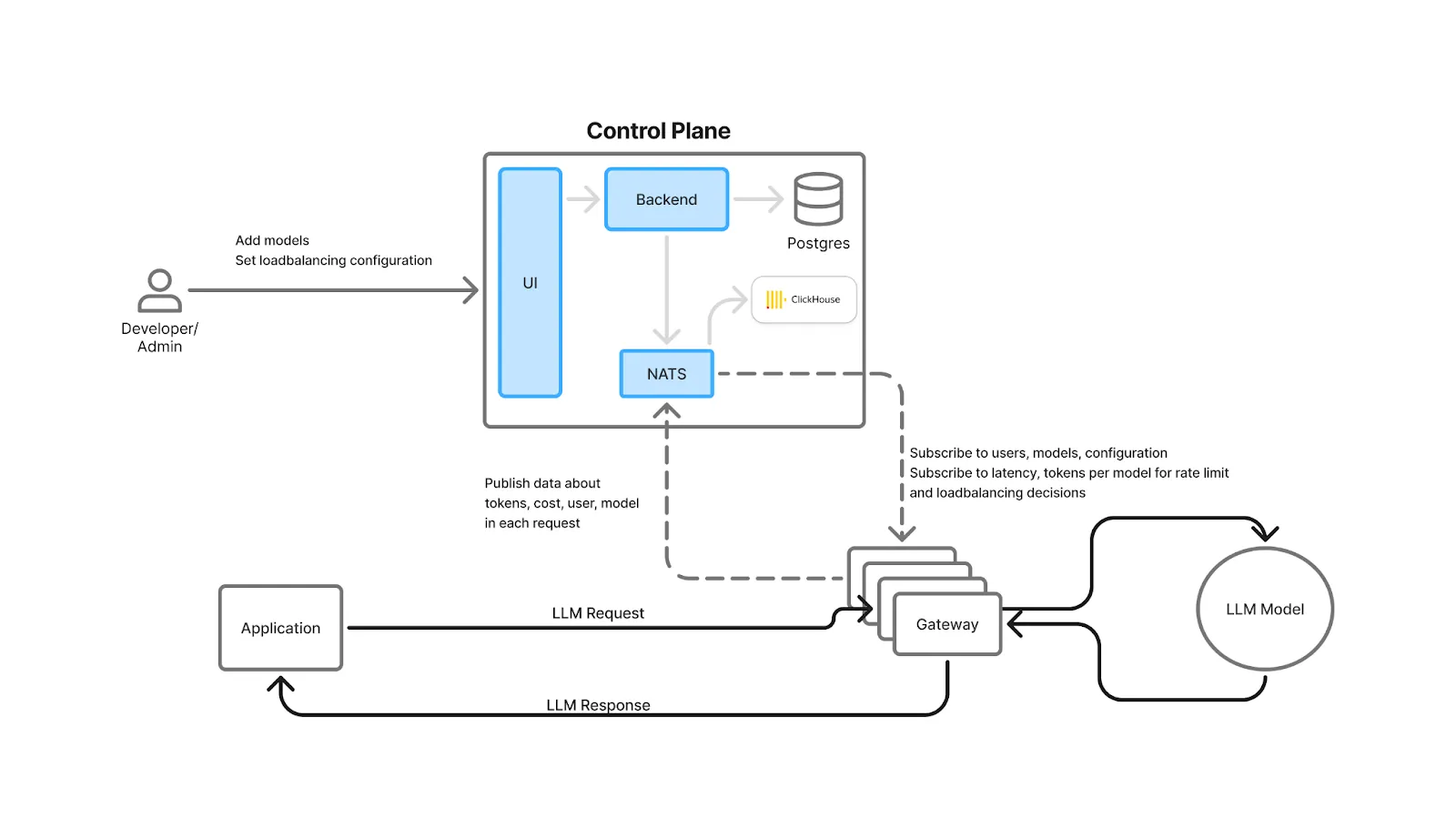
Un Passerelle IA est une couche fine et performante qui transmet les demandes d'applications par proxy à un ou plusieurs fournisseurs LLM ou à des modèles auto-hébergés. Il unifie les API, centralise l'authentification et RBAC (contrôle d'accès basé sur les rôles) , applique des limites tarifaires et garde-corps, exécute équilibrage de charge et le basculement, et capture les données d'observabilité et de coûts pour chaque demande. Considérez-le comme la couche « entrée + politique + télémétrie » pour GenAI.
Sur le plan opérationnel, les passerelles modernes prennent en charge le routage pondéré et basé sur la latence, les contrôles de santé et les solutions de secours automatiques lorsqu'un modèle ou une région ne fonctionne pas correctement, de sorte que les demandes se poursuivent même en cas de problème avec les fournisseurs. Comme chaque demande passe par la passerelle, les équipes peuvent comparer les fournisseurs en termes de latence et de coût, ce qui permet de OpenRouter contre AI Gateway une évaluation pratique pour décider comment gérer le routage, l'observabilité et le contrôle à grande échelle.
TrueFoundry l'architecture est conçue pour que ces contrôles et mesures n'entraînent qu'un minimum de frais : vérifications de l'authentification, limitation de débit, et l'équilibrage de charge est effectué en mémoire ; les logs/métriques sont écrits de manière asynchrone dans une file d'attente ; et le chemin de la requête évite les appels externes (sauf si vous optez pour la mise en cache). La passerelle est extensible horizontalement et dépend du processeur, ce qui permet de maintenir la surcharge de latence de bout en bout à quelques millisecondes.
La latence LLM est multimodale : il y a le délai jusqu'au premier jeton (TTFT), la latence entre jetons (ITL) pour le streaming et la latence totale des demandes. Chacun affecte différemment la perception de l'expérience utilisateur. Les passerelles qui suivent ces trois paramètres vous aident à déterminer si les ralentissements sont dus aux files d'attente des fournisseurs, au calcul du modèle, au réseau ou à la longueur des instructions, et à choisir la meilleure stratégie de routage.
Les jetons sont les nouveaux cycles du processeur. Une seule invite peut être étendue à plusieurs outils ou étapes de récupération, et les coûts s'accumulent entre les fournisseurs. L'observabilité doit attribuer les dépenses par modèle, fournisseur, environnement, application, locataire et utilisateur et se tenir au courant des prix publics des fournisseurs afin d'éviter les feuilles de calcul manuelles.
Les applications de production doivent être protégées contre les pannes des fournisseurs, les restrictions et les régressions de modèles. L'observabilité liée aux bilans de santé, aux ventilations de code 4xx/5xx, aux taux de réessaies/de repli et à l'utilisation des limites de débit vous permet d'appliquer les SLO et de basculer automatiquement lorsque les performances se détériorent.
Les entreprises ont besoin de pistes complètes de demandes et de réponses avec des contrôles d'accès et des politiques de modération des informations personnelles et du contenu. Une passerelle centralise cette application et cette journalisation afin que les équipes puissent prouver qui a appelé quel modèle, avec quelles données et quelles données il a renvoyé, sans partager largement les clés d'API des fournisseurs.
La qualité des modèles, les prix et les quotas changent fréquemment. Les organisations qui instrumentalisent les passerelles peuvent comparer les fournisseurs en tête-à-tête et modifier le trafic en fonction de nouvelles données sur la latence/les coûts/les erreurs, préservant ainsi les performances et les marges au fur et à mesure de l'évolution du marché.
Les directives externes répondent à ces besoins : les leaders du secteur mettent l'accent sur l'observabilité de l'IA pour répondre rapidement aux dérives, aux pannes et aux pics de coûts ; OpenAI et Azure recommandent une journalisation structurée et un retard exponentiel pour les limites de débit, qu'une passerelle peut normaliser entre les applications.
Vous trouverez ci-dessous les fonctionnalités que vous pouvez attendre d'une passerelle IA de production, et que TrueFoundry fournit en mode natif.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Voici comment TrueFoundry intègre l'observabilité au cœur du chemin des requêtes et fournit une solution analytique complète prête à l'emploi, sans ralentir le trafic de production.
.webp)
Le tableau de bord Analytics présente : la latence des demandes (p50/p95/p99), le délai jusqu'au premier jeton (TTFT/TTFS), la latence entre jetons (ITL), le coût par modèle/fournisseur, les jetons d'entrée/sortie, les codes d'erreur et l'activité politique (limite de débit, équilibrage de charge, solutions de repli, garde-corps, budgets). Les vues sont divisées par modèle, utilisateur, équipe, RuleID et métadonnées personnalisées ; vous pouvez également télécharger des fichiers CSV bruts.
Activez Public Cost pour renseigner automatiquement la tarification par jeton à partir des tarifs publiés par les fournisseurs (OpenAI, Anthropic, Bedrock, etc.). Pour les modèles négociés ou affinés, définissez le coût privé avec des prix de jetons d'entrée/sortie personnalisés. Les deux sont intégrés à l'analyse des coûts par demande et à l'analyse des coûts globaux.
Rattachez le contexte commercial (client, fonctionnalité, environnement) et répartissez les jetons, la latence et les dépenses selon tous les critères, ce qui est idéal pour les rétrofacturations, la détection des voisins bruyants et la hiérarchisation des optimisations.
.webp)
Définissez des quotas par jetons ou par demandes par minute/heure/jour, en fonction des utilisateurs, des modèles ou des segments identifiés via des métadonnées. Les tableaux de bord indiquent l'utilisation et les limites afin que vous puissiez ajuster les limites et protéger la capacité partagée.
Utilisez des divisions basées sur le poids pour les expériences ou un routage basé sur la latence pour le régime permanent. Les tests de santé marquent les backends comme défectueux en fonction des seuils d'erreur/de latence et les excluent automatiquement. Les chaînes de secours réessayent en cas d'échec, avec des intervalles et des mesures indiquant le chemin emprunté et son impact sur la latence/les coûts.
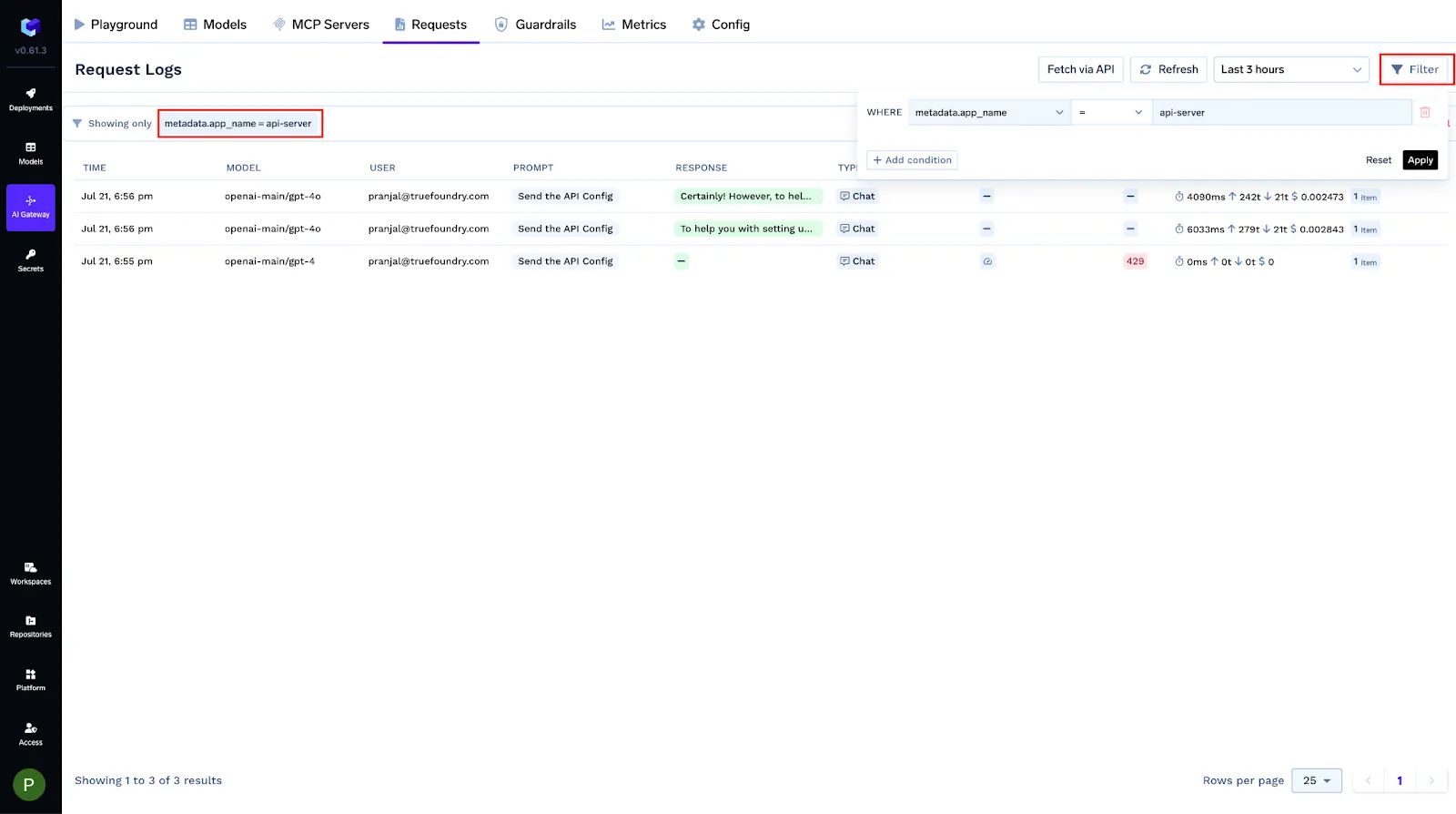
Centralisez les clés des fournisseurs, émettez des jetons d'accès délimités, appliquez le RBAC et conservez des journaux de requêtes/réponses immuables à des fins de conformité, sur les serveurs LLM et MCP
Vous pouvez baliser chaque demande avec des métadonnées structurées via MÉTADONNÉES X-TFY en-tête. Les clés enregistrées deviennent des filtres interrogeables, des étiquettes Grafana et des conditions dans les configurations de passerelle (limites de débit, équilibrage de charge, solutions de secours, garde-corps). Les valeurs sont des chaînes (≤ 128 caractères).
X-TFY-METADATA: {"tfy_log_request":"true","environment":"staging","feature":"countdown-bot","customer_id":"acme-42"}
Use this to isolate logs, group cost/latency by tenant or feature, and roll out policy changes safely to a subset of traffic.
Example — rate‑limit by metadata
name: ratelimiting-config
type: gateway-rate-limiting-config
rules:
- id: openai-gpt4-dev-env
when:
models: ["openai-main/gpt4"]
metadata:
env: dev
limit_to: 1000
unit: requests_per_day
Il en va de même lorsque le modèle de métadonnées s'applique aux règles d'équilibrage de charge et de repli
La passerelle est compatible avec OpenTelemetry. Activez l'exportation OTLP et envoyez des traces vers n'importe quel backend (Tempo, Jaeger, Datadog/New Relic via Collector, TrueFoundry Tracing). Les intervalles incluent des attributs genai (modèle, jetons, TTFT, ITL, paramètres, appels d'outils, erreurs) et des intervalles détaillés pour la limitation du débit, l'équilibrage de charge, les solutions de secours et les appels de serveur/outil MCP, ce qui vous permet de corréler le comportement des fournisseurs avec les intervalles au niveau de l'application.
Activer le traçage
ENABLE_OTEL_TRACING="true"
OTEL_SERVICE_NAME=<your_service>
OTEL_EXPORTER_OTLP_TRACES_ENDPOINT="https://<otel-collector>/v1/traces"
OTEL_EXPORTER_OTLP_TRACES_HEADERS="Authorization=Bearer <token>"Espacements représentatifs
.webp)
Expose /metrics for Prometheus or push OTEL metrics by setting:
ENABLE_OTEL_METRICS="true"
OTEL_EXPORTER_OTLP_METRICS_ENDPOINT="https://<otlp-endpoint>/v1/metrics"
OTEL_EXPORTER_OTLP_METRICS_HEADERS="Authorization=Bearer <token>"
LLM_GATEWAY_METADATA_LOGGING_KEYS='["customer_id","request_type"]'
Metadata keys listed in LLM_GATEWAY_METADATA_LOGGING_KEYS become Prometheus labels llm_gateway_metadata_<key>, enabling per‑customer/per‑feature cost and latency charts. (Truefoundry Docs)<key>Les clés de métadonnées répertoriées dans LLM_GATEWAY_METADATA_LOGGING_KEYS deviennent les étiquettes Prometheus llm_gateway_metadata_, permettant ainsi de créer des graphiques de coûts et de latence par client/par fonctionnalité. (Truefoundry Docs)
Familles de métriques clés (sous-ensemble)
Tokens & cost: llm_gateway_input_tokens, llm_gateway_output_tokens, llm_gateway_request_cost.
Latency: llm_gateway_request_processing_ms, llm_gateway_first_token_latency_ms, llm_gateway_inter_token_latency_ms.
Errors: llm_gateway_request_model_inference_failure, llm_gateway_config_parsing_failures.
Policy activity: llm_gateway_rate_limit_requests_total, llm_gateway_load_balanced_requests_total, llm_gateway_fallback_requests_total, llm_gateway_budget_requests_total, llm_gateway_guardrails_requests_total.
Agent/MCP: llm_gateway_agent_request_duration_ms, llm_gateway_agent_llm_latency_ms, llm_gateway_agent_tool_latency_ms, llm_gateway_agent_tool_calls_total, llm_gateway_agent_mcp_connect_latency_ms, llm_gateway_agent_request_iteration_limit_reached_total. UNE tableau de bord Grafana JSON prédéfini est publié par TrueFoundry, organisé en modèle, Utilisateur, Configuration, et Invocation du MCP vues. Ajoutez des variables pour vos métadonnées personnalisées, par exemple :
label_values(llm_gateway_input_tokens, llm_gateway_metadata_customer_id).webp)
Le Model Context Protocol (MCP) d'Anthropic, annoncé le 25 novembre 2024, normalise la façon dont les assistants se connectent aux outils, aux instructions et aux ressources. L'écosystème s'est accéléré jusqu'en 2025 grâce à de nombreux serveurs préconfigurés (GitHub, Slack, Google Maps, Puppeteer, etc.).
TrueFoundry intègre MCP de manière native :
Cela fait de la passerelle le plan de contrôle opérationnel pour les charges de travail agentiques, en unifiant les politiques, l'authentification, le routage et la visibilité de bout en bout à la fois pour les appels LLM et les exécutions d'outils.
Vous trouverez ci-dessous une liste de contrôle pratique. Chaque métrique inclut ce qu'elle vous indique, comment l'utiliser et comment TrueFoundry la présente.
Un changement rapide augmente la verbosité de la sortie pour les entreprises clientes. Symptômes : augmentation des jetons de sortie, latence p95 plus élevée et dépenses quotidiennes. Action avec TrueFoundry : les analyses montrent une augmentation des jetons de sortie pour l'environnement « support‑prod » et une hausse des coûts pour le modèle principal. Vous comparez un autre fournisseur qui affiche un TTFT inférieur et des jetons de sortie moins chers ; vous transférez 30 % du trafic via un routage basé sur le poids et vous définissez une alerte sur le « coût par conversation ».
À 10 h IST, le taux d'erreur a grimpé à 429 secondes. Action avec TrueFoundry : Les tableaux de bord des limites de débit confirment les manettes depuis l'amont. Les chaînes de secours entrent en jeu et le routage évolue vers un backend plus sain. Vous maintenez la stabilité de l'expérience utilisateur et vous ajustez ultérieurement les quotas de jetons et les paramètres de backoff.
Les utilisateurs signalent que « la réponse commence rapidement, mais elle est ensuite explorée ». Action avec TrueFoundry : Le TTFT convient, mais l'ITL est élevé sur le modèle principal. Le routage basé sur la latence privilégie automatiquement un fournisseur offrant un meilleur débit de streaming ; vous définissez également une alerte sur ITL p95.
Le traitement par lots d'un client monopolise des jetons et ralentit tous les autres. Action avec TrueFoundry : Les limites tarifaires établies par les clients en fonction de jetons garantissent un partage équitable et protègent les SLO ; les analyses vérifient l'utilisation et le nombre de refus afin de vous permettre de vendre des quotas plus élevés.
Les applications LLM sont des systèmes dynamiques. Les modèles évoluent, les fournisseurs modifient les quotas et les prix, les incitent à changer et le comportement des utilisateurs vous surprend. L'AI Gateway est l'endroit où vous pouvez observer, contrôler et optimiser tout cela, à condition de recueillir les bons signaux et de les transformer en actions.
La passerelle IA de TrueFoundry vous offre ce centre de commande opérationnel. Il capture la latence (TTFT/ITL), les jetons, les coûts et les erreurs avec une faible surcharge ; applique les limites de débit, le RBAC et les garde-fous tenant compte des jetons ; et fournit une visibilité sur le routage, l'état et la solution de secours afin que vous puissiez garantir des expériences rapides, fiables et rentables. Grâce à des analyses granulaires des clients/utilisateurs et à une attribution des coûts automatisée et actualisée, les équipes peuvent passer d'une lutte réactive à une optimisation proactive.
Si vous souhaitez centraliser votre pile GenAI, ou démêler une multitude d'intégrations ponctuelles, commencez par acheminer le trafic via la passerelle, activez les tableaux de bord ci-dessus et définissez quelques alertes alignées sur le SLO. Vous bénéficierez de la visibilité nécessaire pour expédier plus rapidement, maîtriser les coûts et satisfaire vos agents et vos utilisateurs.
L'observabilité dans la passerelle AI permet de suivre des raisonnements complexes en plusieurs étapes et des invocations d'outils qui seraient autrement opaques. La surveillance des chemins d'exécution des agents permet de détecter des boucles infinies, des hallucinations et une utilisation inefficace des outils en temps réel. Cette visibilité garantit que les agents autonomes restent fiables, prévisibles et respectent leur budget tout en interagissant avec divers systèmes externes et API.
L'observabilité des passerelles IA optimise les performances du LLM en fournissant un suivi en temps réel de la latence, du débit et des taux d'erreur chez les différents fournisseurs de modèles. En capturant des indicateurs granulaires tels que le délai jusqu'au premier jeton (TTFT) et la latence entre jetons (ITL), les équipes peuvent identifier des goulots d'étranglement spécifiques dans la chaîne d'inférence. Ces informations permettent aux développeurs de comparer objectivement les vitesses des modèles et de mettre en œuvre un routage intelligent pour garantir des performances à haut débit aux utilisateurs finaux.
L'observabilité des passerelles IA réduit les coûts en fournissant une visibilité granulaire sur la consommation de jetons entre les modèles, les équipes et les utilisateurs. Le suivi des dépenses par demande et par espace de travail permet aux équipes d'identifier immédiatement les demandes excessives ou les flux de travail inefficaces. Ces données soutiennent des stratégies automatisées de réduction des coûts telles que la mise en cache sémantique, la limitation du débit tenant compte des jetons et le routage des requêtes vers des modèles plus abordables sans intervention manuelle.
L'observabilité des passerelles IA facilite les audits de conformité en maintenant un journal centralisé et immuable de chaque demande et réponse. Les systèmes modernes enregistrent des pistes d'audit détaillées, y compris les identifiants utilisateur, les horodatages et les événements de masquage des informations personnelles afin de protéger les données sensibles. Ces journaux garantissent que les entreprises respectent les normes réglementaires telles que le RGPD et le SOC 2 en offrant une transparence totale sur les interactions entre les modèles, souvent tout en conservant toutes les données télémétriques dans l'environnement cloud sécurisé de l'organisation.
TrueFoundry simplifie la gestion de l'infrastructure d'IA en unifiant plusieurs fournisseurs de modèles en un seul plan de contrôle grâce à l'observabilité dans les passerelles d'IA. TrueFoundry met en corrélation la télémétrie au niveau des demandes avec l'utilisation du GPU et du processeur afin d'optimiser l'allocation des ressources et de réduire le gaspillage. Cette approche intégrée permet aux équipes de la plateforme de gérer les déploiements, la mise à l'échelle et les politiques de sécurité dans divers environnements de manière native au sein de leurs comptes AWS, GCP ou Azure.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


