

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: July 8, 2026
.webp)
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Alors que les entreprises mettent en production l'IA générative et les grands modèles de langage (LLM), la gestion des coûts devient essentielle. La tarification basée sur des jetons, courante chez les fournisseurs de LLM, apporte une complexité unique :
Sans solution de suivi des coûts LLM dédiée, les équipes manquent de visibilité jusqu'à ce que les coûts augmentent de manière inattendue. Cela menace les budgets et entrave les efforts de mise à l'échelle.
Voici comment aborder le suivi, la gouvernance et l'optimisation de bout en bout, ainsi que des liens directs et naturels vers la documentation TrueFoundry pour chaque élément central.
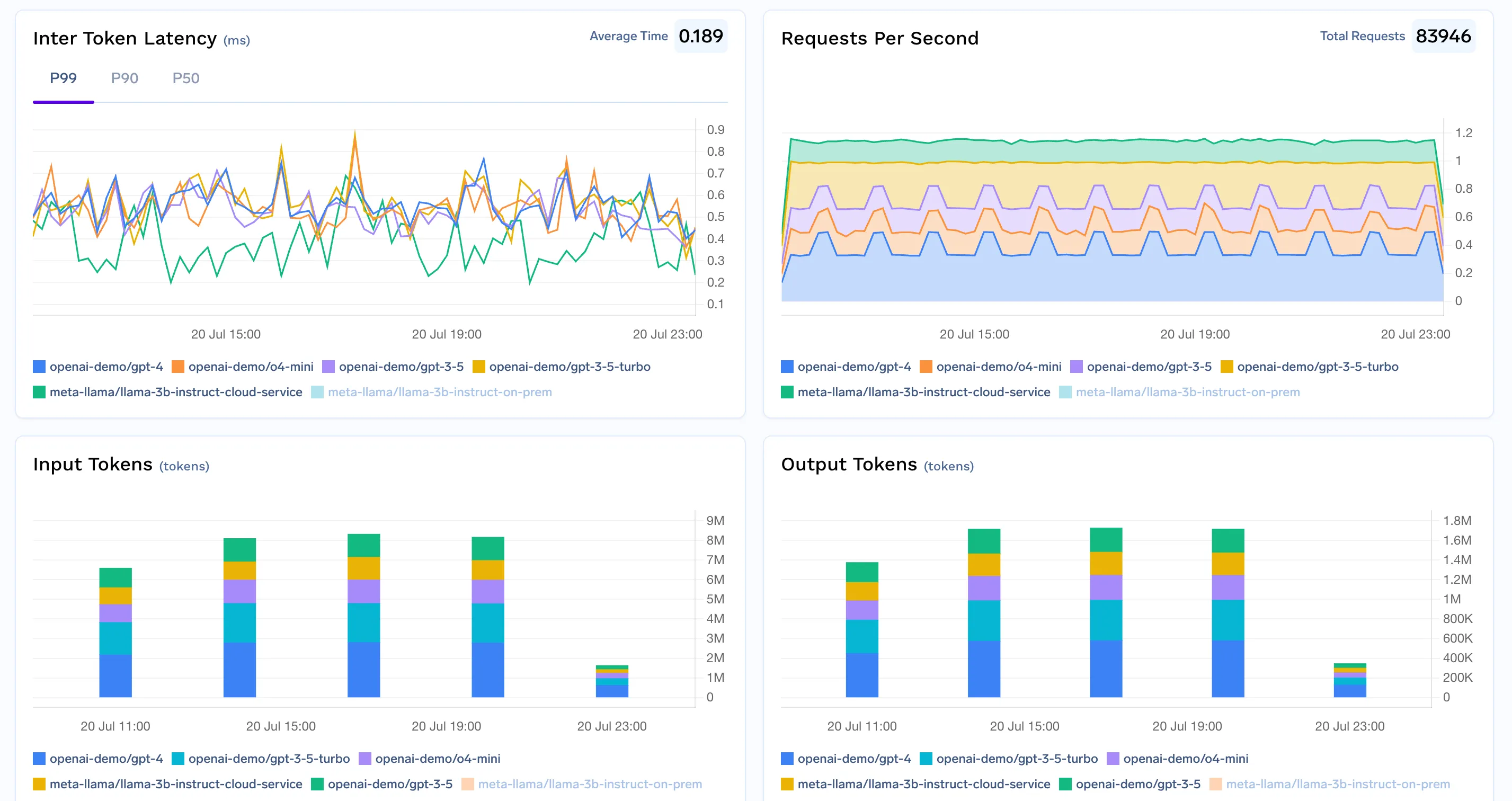
La mise en place d'un suivi des coûts robustes commence par la saisie de données complètes et structurées pour chaque demande LLM. À l'aide du Passerelle TrueFoundry AI, vous pouvez acheminer tout le trafic d'inférence, que ce soit vers un modèle d'API (comme OpenAI, Claude ou Mistral) ou vers un modèle auto-hébergé que vous exploitez. Cette passerelle agit comme votre « guichet unique » pour l'observabilité et l'attribution des coûts.
Pour chaque demande, vous devez :
Une solution complète de suivi des coûts LLM doit vous permettre de faire respecter les limites avant les budgets sont dépassés.
Ensemble, ces fonctionnalités de gouvernance transforment la journalisation en solution de suivi des coûts en temps réel et applicable qui évite les dépassements dès sa conception, et pas seulement grâce à des rapports rétroactifs.
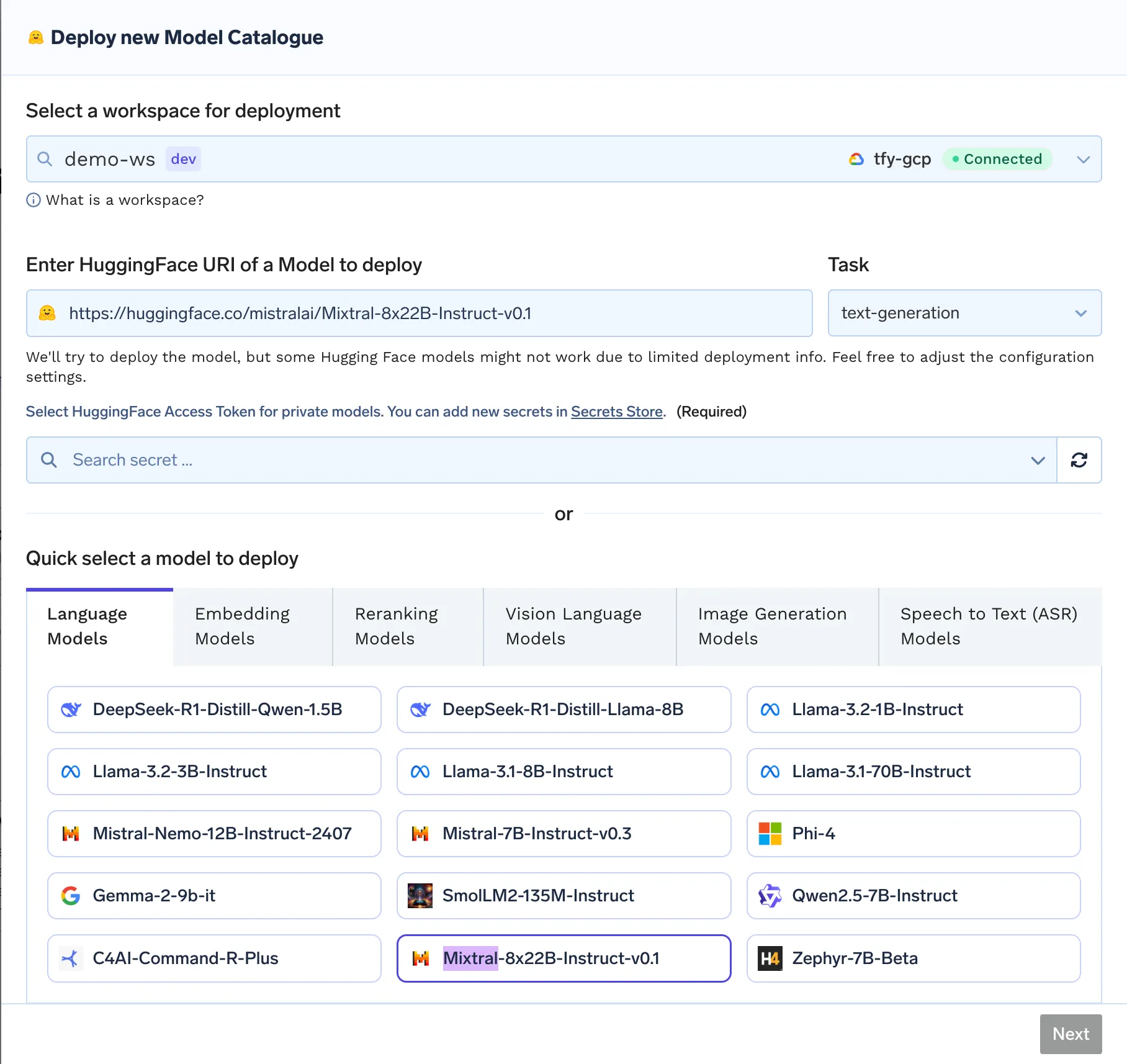
Après l'observabilité et la gouvernance, optimisation est le processus continu de réduction des dépenses sans sacrifier les performances ou la qualité.
Une optimisation des coûts réussie repose sur des mesures vigilantes. Les éléments suivants sont essentiels à suivre sur l'ensemble de votre pile :
Un moderne LLM Coûts Tracking Solution est bien plus qu'un simple reporting après coup, c'est un plan de contrôle stratégique pour chaque phase du déploiement de l'IA, de la gouvernance quotidienne à l'optimisation continue. En tirant parti des fonctionnalités complètes proposées par Passerelle IA de TrueFoundry, les équipes bénéficient d'une visibilité granulaire, d'un contrôle proactif des dépenses et d'un routage rentable pour chaque LLM qu'elles utilisent, que ce soit via une API ou des clusters auto-hébergés.
Pour une analyse technique approfondie étape par étape, voir :
Une solution de suivi des coûts LLM est un plan de contrôle stratégique conçu pour surveiller, gérer et optimiser les dépenses uniques associées aux opérations du modèle linguistique étendu. Contrairement à l'infrastructure cloud traditionnelle, elle convient spécifiquement à la tarification basée sur les jetons, les charges d'inférence variables et les ressources gourmandes en calcul. Ces plateformes offrent une visibilité en temps réel sur les dépenses de plusieurs fournisseurs, modèles et équipes.
Le suivi des coûts d'utilisation du LLM est essentiel car les dépenses liées à l'infrastructure d'Ia peuvent augmenter de façon exponentielle et silencieuse en raison de la tarification des jetons basée sur la consommation. Sans surveillance granulaire, les organisations sont confrontées à des dépassements budgétaires massifs, à une facturation mensuelle imprévisible et à un manque de responsabilité financière. Un suivi efficace garantit une croissance durable en liant chaque dollar dépensé à une valeur commerciale et à un retour sur investissement mesurables.
Il existe plusieurs outils et plateformes spécialisés qui dominent actuellement le marché en matière de gestion et de suivi des coûts du LLM. TrueFoundry propose une passerelle IA unifiée pour la gestion et la gouvernance des dépenses multimodèles. Parmi les autres solutions de premier plan, citons LitellM, qui fournit un proxy léger pour une visibilité des dépenses en temps réel, et Portkey, qui se concentre sur l'attribution détaillée des coûts pour les applications d'IA génératives.
Oui, la plupart des plateformes LLMops avancées intègrent nativement une solution de suivi des coûts LLM pour gérer le cycle de vie complet des modèles. Des plateformes telles que TrueFoundry et Weights & Biases capturent des données télémétriques détaillées dans les environnements de production, affichant les coûts des jetons ainsi que les indicateurs de performance. Cette intégration native permet aux développeurs d'optimiser à la fois la précision et l'efficacité financière au sein d'un flux de travail unique et unifié.
Les solutions de suivi des coûts LLM utilisent la surveillance en temps réel pour déclencher des notifications automatisées par e-mail, Slack ou webhooks lorsque l'utilisation atteint des pourcentages prédéfinis d'un budget. Ces systèmes peuvent être configurés avec des règles d'application automatisées qui limitent le trafic ou bloquent les demandes une fois qu'un plafond est atteint. Ces alertes proactives empêchent les charges de travail « excessives » et garantissent le maintien des garanties financières.
TrueFoundry est une solution idéale de suivi des coûts LLM, car elle combine l'attribution des coûts en temps réel avec un contexte approfondi basé sur des métadonnées. Il permet aux entreprises de définir une tarification personnalisée par modèle et de définir des seuils budgétaires granulaires pour des équipes, des projets ou des environnements spécifiques. Son AI Gateway optimise davantage les dépenses grâce à un routage intelligent, à une mise en cache sémantique et à des modèles de répli automatiques, garantissant ainsi des performances élevées au prix le plus bas possible.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


