

July 20, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les GPU fractionnés nous permettent d'allouer plusieurs charges de travail à un seul GPU, ce qui peut être utile dans les scénarios suivants :
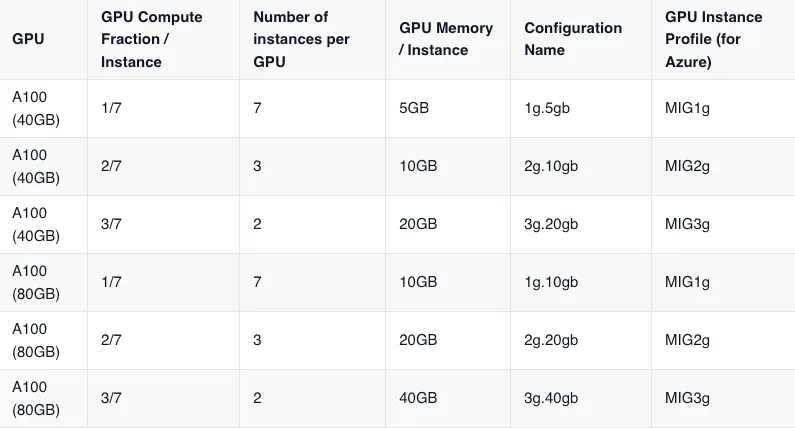
Pour activer les GPU fractionnaires, nous devrons créer un pool de nœuds distinct des GPU et il ne fonctionnera pas via le provisionnement dynamique de nœuds standard dans AWS/GCP. Pour que Truefoundry puisse lire ces pools de nœuds, nous devons nous assurer que l'intégration cloud avec Truefoundry est déjà effectuée.
Si ce n'est pas encore activé, veuillez suivez ce guide pour activer l'intégration au cloud.
Une fois l'intégration cloud ajoutée, vous devez « créer des pools de nœuds » pour les GPU compatibles MIG ou TimeSlicing. Cette configuration est différente selon les fournisseurs de cloud. Veuillez suivre le guide ci-dessous pour activer les GPU fractionnaires sur votre cluster.
Déploiements -> Helm -> tfy-gpu-operator.1. Créez un Nodepool avec MIG activé à l'aide de l'argument --gpu-instance-profile d'Azure CLI. Voici un exemple de commande permettant de faire de même :
az aks nodepool add \
<your cluster name>--nom-cluster \
<your resource group>--groupe-ressources \
--sans attendre \
--enable-cluster-autoscaler \
--eviction-policy Supprimer \
--nombre de nœuds 0 \
--compte maximum 20 \
--compte minimum 1 \
--node-osdisk-size 200 \
--scale-down-mode Supprimer \
--os-type Linux \
--node-taints « nvidia.com/GPU=present:NoSchedule » \
--name a100mig7 \
--node-vm-size standard_NC24ADS_A100_V4 \
--Emplacement prioritaire \
--os-sku Ubuntu \
--gpu-instance-profile MiG1G
2. Actualisez les pools de nœuds du cluster Truefoundry.
3. Déployez votre charge de travail en sélectionnant le GPU (avec le nombre 1) et en sélectionnant le pool de nœuds approprié.
Créez un pool de nœuds et transmettez le mig_profile dans accélérateur en passant gpu_partition_size=1G,5 Go[OU l'une des valeurs autorisées pour le profil MIG que vous trouverez en haut de cette page]
Les pools de nœuds de conteneurs gcloud créent un 100-40-mig-1g5gb \ INT ✘
<enter your project name>--projet= \
<enter your region>--région= \
<enter your cluster name here>--cluster= \
--machine-type=a2-high gpu-1g \
--accelerator type=nvidia-tesla-a100, compte=1, taille de la partition GPU=1g.5 Go \
--activer-la mise à l'échelle automatique \
--nombre total de nœuds minimum 0 \
--total-max-nodes 4 \
--min-provision-nodes 0 \
--num-nodes 0
Il n'est pas anodin de prendre actuellement en charge les GPU MIG sur AWS de manière gérée, mais si vous souhaitez essayer cette fonctionnalité -> Veuillez vous y référer médecins
plug-in pour appareil NVIDIA la configuration est correctement définie dans opérateur tfy-gpugraphique.Casque -> tfy-gpu-operator, cliquez sur Modifier et assurez-vous que les lignes suivantes sont présentes dans le valeursopérateur azure-AKS-GPU :
Plug-in de l'appareil :
configuration :
données :
tous : « »
tranche dans le temps : |-
version : v1
partage :
Découpage temporel :
RenameByDefault : true
ressources :
- nom : nvidia.com/gpu
répliques : 10
nom : time-slicing-config
créer : vrai
par défaut : tous
plugin-appareil.config pointant vers la configuration de découpage temporel correcte avec Azure CLI. Voici un exemple de commande pour faire de même.az aks nodepool add \
<your cluster name>--nom-cluster \
<your resource group>--groupe-ressources \
--sans attendre \
--enable-cluster-autoscaler \
--eviction-policy Supprimer \
--nombre de nœuds 0 \
--compte maximum 20 \
--compte minimum 0 \
--node-osdisk-size 200 \
--scale-down-mode Supprimer \
--os-type Linux \
--node-taints « nvidia.com/GPU=present:NoSchedule » \
--name a100mig7 \
--node-vm-size standard_NC24ADS_A100_V4 \
--Emplacement prioritaire \
--os-sku Ubuntu \
--labels nvidia.com/device-plugin.config=time-sliced-10
Les pools de nœuds de conteneurs gcloud créent un 100-40-frac-10 \ ✔
--project=tfy-devtest \
--region=us-central1 \
--cluster=tfy-gtl-b-us-central-1 \
--machine-type=a2-high gpu-1g \
--accelerator type=nvidia-tesla-a100, count=1, gpu-sharing-strategy=temps partagé, max-shared-clients-per-gpu=10 \
--activer-la mise à l'échelle automatique \
--nombre total de nœuds minimum 0 \
--total-max-nodes 4 \
--min-provision-nodes 0 \
--num-nodes 0
1. Assurez-vous que plug-in pour appareil NVIDIA la configuration est correctement définie dans opérateur tfy-gpugraphique.
Accédez à Casque -> tfy-gpu-operator, cliquez sur Modifier et assurez-vous que les lignes suivantes sont présentes dans le valeurs
Opérateur aws-eks-GPU :
Plug-in de l'appareil :
configuration :
données :
tous : « »
tranche dans le temps : |-
version : v1
partage :
Découpage temporel :
RenameByDefault : true
ressources :
- nom : nvidia.com/gpu
répliques : 10
nom : time-slicing-config
créer : vrai
par défaut : tous
2. Créez un groupe de nœuds sur AWS EKS avec l'étiquette suivante :
étiquettes :
« nvidia.com/device-plugin.config » : « time-sliced-10 »
Pour utiliser des GPU fractionnaires dans votre service :
1. Assurez-vous d'avoir ajouté les pools de nœuds souhaités.
2. Synchronisez les pools de nœuds de cluster depuis votre compte cloud en accédant à Intégrations -> Clusters -> Synchroniser comme indiqué ci-dessous :

3. Vous pouvez déployer à l'aide de l'interface utilisateur de Truefoundry ou du SDK Python.
Remarque : La mise à l'échelle automatique des Nodepools ne fonctionnera que dans GCP clusters. Vous devrez augmenter ou réduire manuellement les pools de nœuds dans Azure/AWS.
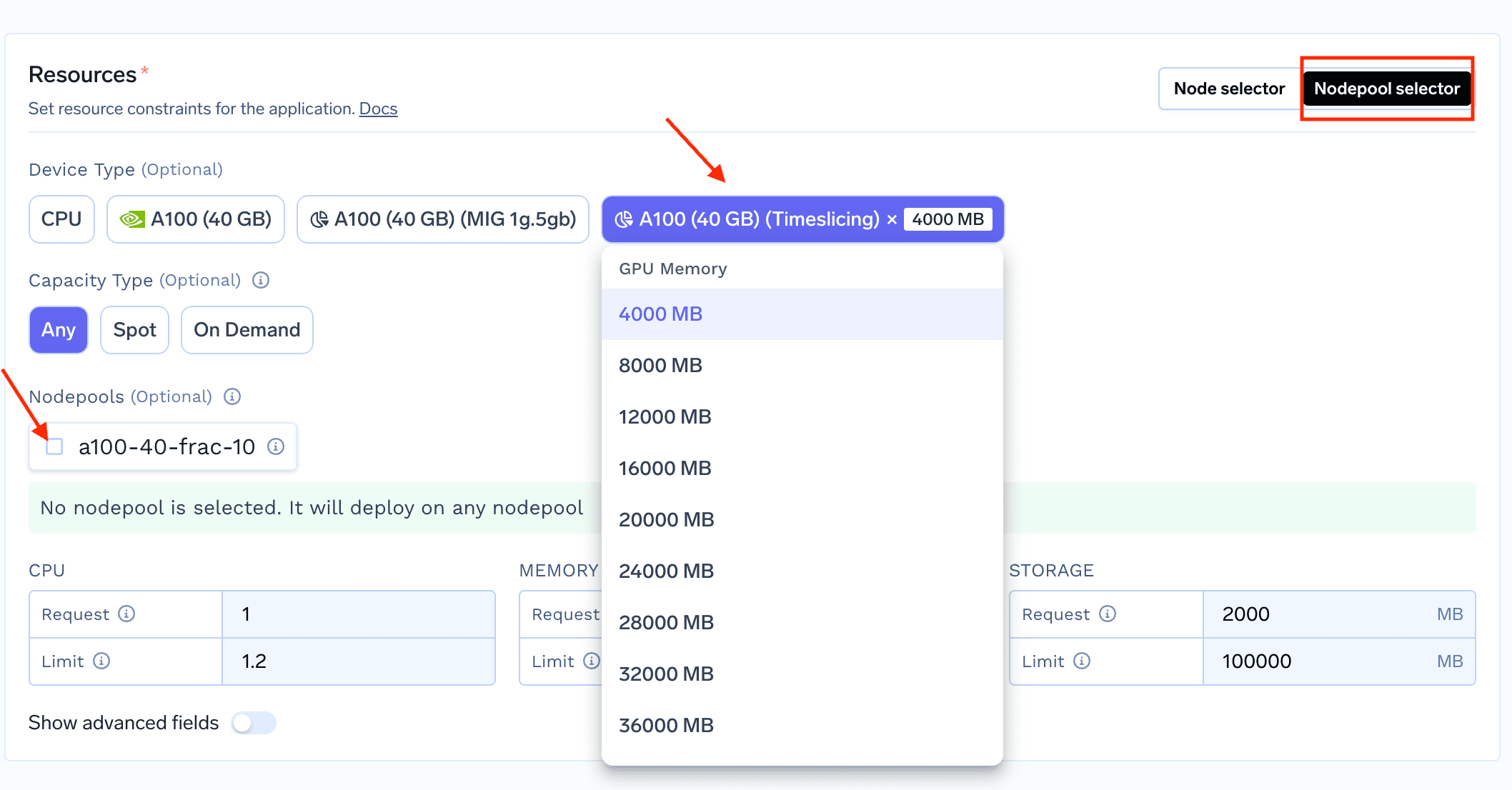
1. Pour déployer une charge de travail utilisant un GPU fractionné, commencez à déployer votre service/job sur Truefoundry et dans la section « Ressources », sélectionnez le sélecteur de pool de nœuds
2. Une fois que vous avez sélectionné le sélecteur de pool de nœuds en haut à droite de la section Ressources, vous pouvez maintenant voir les GPU fractionnés sur l'interface utilisateur que vous pouvez sélectionner (comme indiqué ci-dessous)

Vous pouvez utiliser des GPU fractionnaires à l'aide du SDK python avec les modifications suivantes en termes de ressources :
1. Utilisation de GPU MIG
depuis Servicefoundry import (
...
Un service,
Processeur graphique NVIDIA Mig,
Sélecteur de pool de nœuds,
)
service = Service (
...
Resources=Ressources (
...
Node=NodePoolSelector (
<add your nodepool name>pools de nœuds = [» «],
),
appareils = [
GPU NVIDIA Mig (profil = « 1 g, 5 Go »)
],
),
)
2. Utilisation du GPU Timeslicing
depuis Servicefoundry import (
Un service,
GPU NVIDIA Time Slicing,
Sélecteur de pool de nœuds,
)
service = Service (
...
Resources=Ressources (
...
Node=NodePoolSelector (
<add your nodepool name>pools de nœuds = [» «],
),
appareils = [
GPU Nvidia Timeslicing (gpu_memory = 4000),
],
),
)
Nous mangeons True Foundry prend en charge les GPU fractionnaires de manière extrêmement rationalisée.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


