

May 8, 2024
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Alors que les grands modèles de langage passent de l'expérimentation à la production, les équipes repensent la manière dont le trafic d'IA doit être géré, sécurisé et observé. Ce qui semblait autrefois être une simple intégration d'API implique désormais des invites, des jetons, le routage des modèles, les nouvelles tentatives, le suivi des coûts et des problèmes de fiabilité que l'infrastructure applicative traditionnelle n'a jamais été conçue pour gérer.
De nombreuses équipes d'ingénierie commencent cette aventure en étendant des passerelles API familières telles que Kong, en tirant parti des modèles de routage, d'authentification et de limitation de débit existants. À mesure que l'utilisation du LLM augmente, les passerelles natives de l'IA telles que Clé de port entrez l'image, en proposant des abstractions adaptées aux invites, aux modèles et à l'observabilité au niveau des jetons.
Les deux approches visent à résoudre des problèmes réels, mais elles partent de points de départ fondamentalement différents. Kong est ancré dans la gestion des API HTTP et des microservices, tandis que Portkey est conçu spécifiquement pour les flux de travail des applications LLM. Les différences entre ces philosophies deviennent de plus en plus importantes à mesure que les systèmes d'IA évoluent en fonction des équipes, des environnements et des cas d'utilisation de production.
Dans cet article, nous comparons Kong et Portkey en termes d'architecture, d'observabilité, de gouvernance et de préparation à l'entreprise. Nous verrons où chaque outil convient le mieux, où les limites commencent à apparaître et ce que les équipes de plateforme devraient prendre en compte à mesure que l'IA devient un élément essentiel de leur infrastructure.
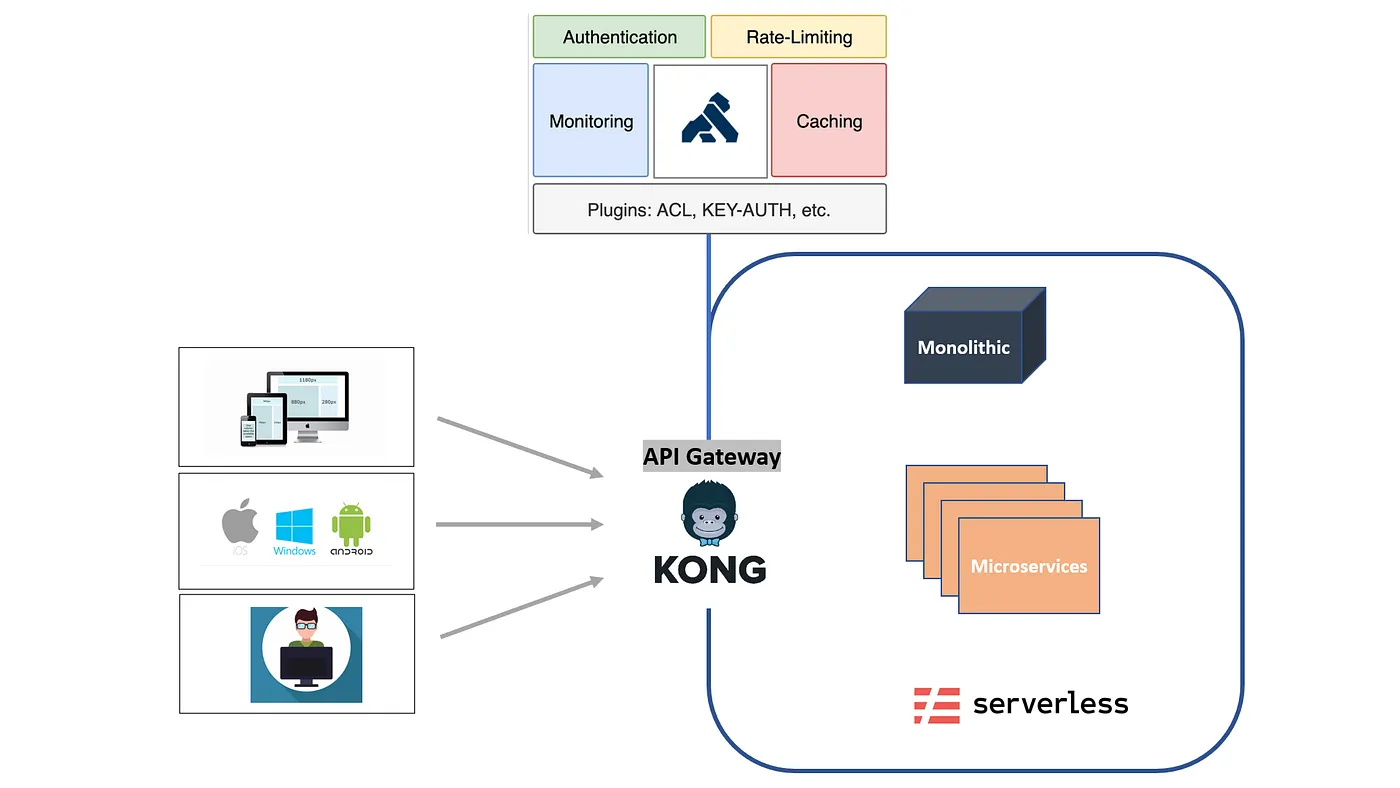
Kong est une passerelle API largement adoptée conçue pour gérer, sécuriser et acheminer le trafic HTTP via des microservices. Il est couramment utilisé comme couche d'entrée dans les architectures basées sur Kubernetes et est bien connu pour gérer des problèmes tels que l'authentification, la limitation du débit, le routage du trafic et l'observabilité au niveau des requêtes.
D'un point de vue architectural, Kong est optimisé pour Systèmes axés sur les API. Ses abstractions principales tournent autour des points de terminaison, des services, des itinéraires et des plugins, ce qui en fait une solution idéale pour les environnements de backend et de microservices traditionnels où les requêtes sont sans état, prévisibles et uniformes.
Lorsque les équipes introduisent des LLM, Kong est souvent le premier outil réutilisé pour gérer le trafic d'IA, en traitant les appels LLM comme un simple point de terminaison d'API. Cela fonctionne initialement pour :
Cependant, le trafic LLM introduit des propriétés qui ne correspondent pas clairement aux API traditionnelles.
À mesure que l'utilisation de l'IA va au-delà de la simple expérimentation, ces lacunes deviennent de plus en plus visibles, en particulier dans les environnements impliquant plusieurs équipes ou sensibles aux coûts.
Clé de port est une passerelle native d'IA conçue spécifiquement pour les applications basées sur de grands modèles de langage. Au lieu de traiter les appels LLM comme des requêtes d'API génériques, Portkey introduit des abstractions qui correspondent au fonctionnement réel des applications d'IA : invites, modèles, jetons et fournisseurs.
Portkey agit essentiellement comme une couche intermédiaire entre les applications d'IA et plusieurs fournisseurs de LLM. Il permet aux développeurs de passer d'un modèle à l'autre, d'acheminer le trafic et d'observer l'utilisation sans associer étroitement le code de l'application à l'API d'un fournisseur spécifique.
Comparé aux passerelles API comme Kong, Portkey est Conçu pour être compatible avec le LLM. Il comprend que :
Cela fait de Portkey un excellent choix pour les équipes qui créent et itèrent sur des applications basées sur LLM, en particulier dans les environnements de production en phase initiale ou intermédiaire.
Au fur et à mesure que l'utilisation de LLM se développe dans les équipes et les environnements, certaines limites apparaissent :
Ces contraintes deviennent importantes lorsque l'IA passe du statut de fonctionnalité d'application à celui de capacité d'entreprise partagée.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Alors que Kong et Clé de port peuvent tous deux faire face à des charges de travail liées à l'IA, ils reposent sur des hypothèses architecturales très différentes. Comprendre cette différence est essentiel pour les équipes chargées de la plateforme qui décident comment étendre l'IA au-delà d'une seule application.
Kong est un bon choix si :
Dans cette configuration, Kong fonctionne comme extension temporaire de l'infrastructure d'API existante.
Portkey convient parfaitement lorsque :
Portkey brille au couche d'application, en particulier pour les équipes de produits d'IA qui évoluent rapidement.
Les deux Kong et Clé de port répondent aux véritables défis de la pile d'IA, mais ils le font à des niveaux différents et, en fin de compte, limités. Ces limites deviennent apparentes à mesure que l'IA évolue d'une fonctionnalité d'application unique à une capacité d'entreprise partagée couvrant de multiples équipes, environnements et limites réglementaires.
Kong est conçu pour régir les demandes d'API, et non le comportement de l'IA. Les invites, les jetons, la sélection du modèle et l'exécution des agents sont opaques pour la passerelle.
Portkey introduit des contrôles compatibles avec le LLM, mais la gouvernance reste largement maintenue limité à l'application.
Les équipes d'IA d'entreprise ont toutefois besoin de réponses à des questions telles que :
Ni Kong ni Portkey ne fournissent gouvernance de l'IA à l'échelle de l'organisation en tant que capacité de première classe.
Les coûts de l'IA sont déterminés par une combinaison de :
Kong n'a aucune visibilité sur ces facteurs de coûts spécifiques à l'IA.
Portkey expose des métriques au niveau des jetons, mais l'attribution des coûts devient de plus en plus difficile car l'utilisation concerne plusieurs équipes, applications et environnements.
Sans attribution au niveau de l'infrastructure, les équipes chargées de la plateforme et des finances ont du mal à répondre à une question fondamentale : qui dépense quoi et pourquoi ?
Les systèmes d'IA de production exigent une séparation stricte entre :
Kong n'a pas été conçu en gardant à l'esprit l'isolation de l'environnement d'IA.
Portkey optimise les flux de travail des applications plutôt que d'imposer des limites d'environnement strictes.
Pour les entreprises des secteurs réglementés, ce manque d'isolement devient rapidement un obstacle au déploiement.
Les déploiements d'IA d'entreprise doivent répondre à des exigences telles que :
Ces contraintes doivent être appliquées au niveau de l'infrastructure, qui n'est pas intégré au code de l'application ni géré manuellement par les équipes.
Kong traite le trafic de l'IA comme des requêtes HTTP génériques.
Portkey suppose une utilisation axée sur le cloud au niveau de l'application.
Aucune des deux approches n'est conçue pour déploiements d'IA axés sur la conformité.
L'IA en production ne se limite plus aux appels synchrones à réponse rapide. Les systèmes du monde réel incluent :
Les passerelles qui se concentrent uniquement sur le trafic API ou le routage rapide ne parviennent pas à régir le cycle de vie complet des charges de travail liées à l'IA.
À mesure que l'adoption de l'IA progresse, les entreprises convergent vers le même constat : Les passerelles seules ne suffisent pas. L'exécution de l'IA en production nécessite une couche d'infrastructure qui unifie accès, déploiement, observabilité, gouvernance et conformité. C'est pourquoi les organisations finissent par aller au-delà des passerelles API et des passerelles d'applications LLM pour Plateformes d'infrastructure natives d'IA conçues pour l'échelle de l'entreprise
Les limites de Kong et Clé de port proviennent de la même cause fondamentale : les deux ont été conçus pour résoudre problèmes au niveau de la passerelle, pas problèmes d'infrastructure d'IA d'entreprise.
Alors que l'IA devient une capacité partagée et essentielle à la production, les entreprises ont besoin de plus que le routage du trafic ou une abstraction rapide. Ils ont besoin d'une plateforme qui traite Gouvernance, déploiement, observabilité et sécurité de l'IA en tant que problèmes d'infrastructure de premier ordre. C'est ici True Foundry se distingue.
TrueFoundry repose sur l'idée que les charges de travail de l'IA doivent être gérées comme tout autre système de production critique, mais avec Primitives natives de l'IA. Au lieu de fonctionner uniquement dans le chemin de la demande, TrueFoundry fonctionne comme un plan de contrôle IA unifié.
À un niveau élevé, TrueFoundry réunit :
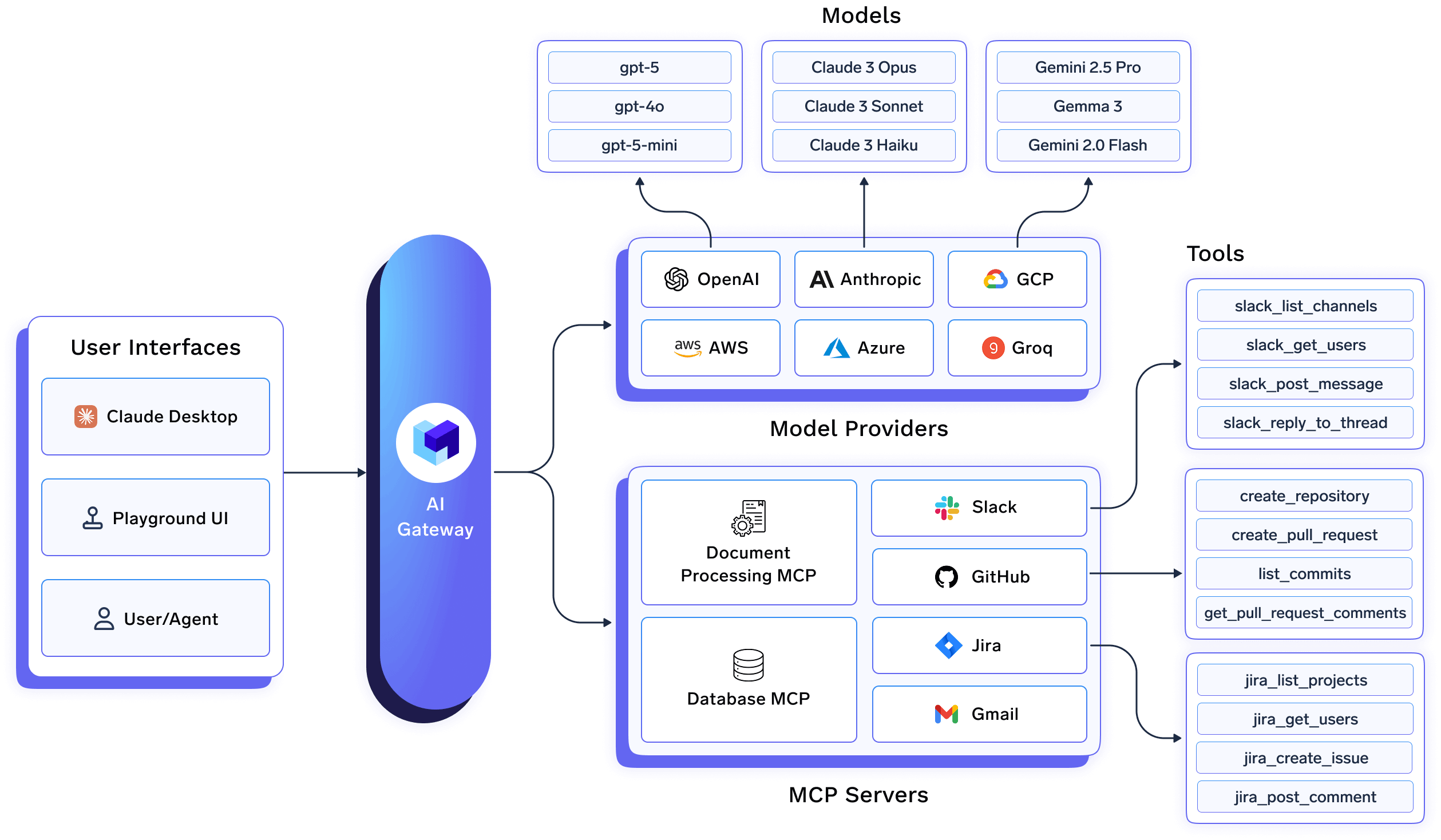
Dans de nombreuses piles d'IA, l'utilisation de LLM est traitée comme un problème d'intégration d'API : les demandes sont acheminées, authentifiées et enregistrées, mais tout ce qui dépasse les limites de la demande est laissé aux applications individuelles. TrueFoundry adopte une approche différente en traitant les charges de travail, les services, les emplois et les agents d'IA comme objets d'infrastructure avec cycle de vie, propriété et limites opérationnelles.
Plutôt que de simplement décider si une demande doit être autorisée, TrueFoundry contrôle où les systèmes d'IA fonctionnent, comment ils s'exécutent et sous quelles contraintes, du déploiement à l'exécution. Ce passage du routage des demandes au contrôle du cycle de vie permet une gouvernance cohérente à mesure que l'utilisation de l'IA évolue.
Concrètement, cela se manifeste sous plusieurs aspects critiques.
Dans les architectures centrées sur les passerelles, politiques d'accès sont généralement intégrés au code de l'application, à la configuration du SDK ou aux règles de passerelle par service. Cela devient rapidement fragile à mesure que les équipes, les services et les environnements se multiplient.
TrueFoundry applique les politiques d'accès et d'utilisation au niveau d'espace de travail et d'environnement. Les modèles, les agents et les outils sont limités à des environnements tels que le développement, le staging et la production, les autorisations et les contrôles étant appliqués de manière cohérente à toutes les charges de travail déployées dans cet environnement.
Parce que les politiques sont liées à des environnements plutôt qu'à des applications individuelles :
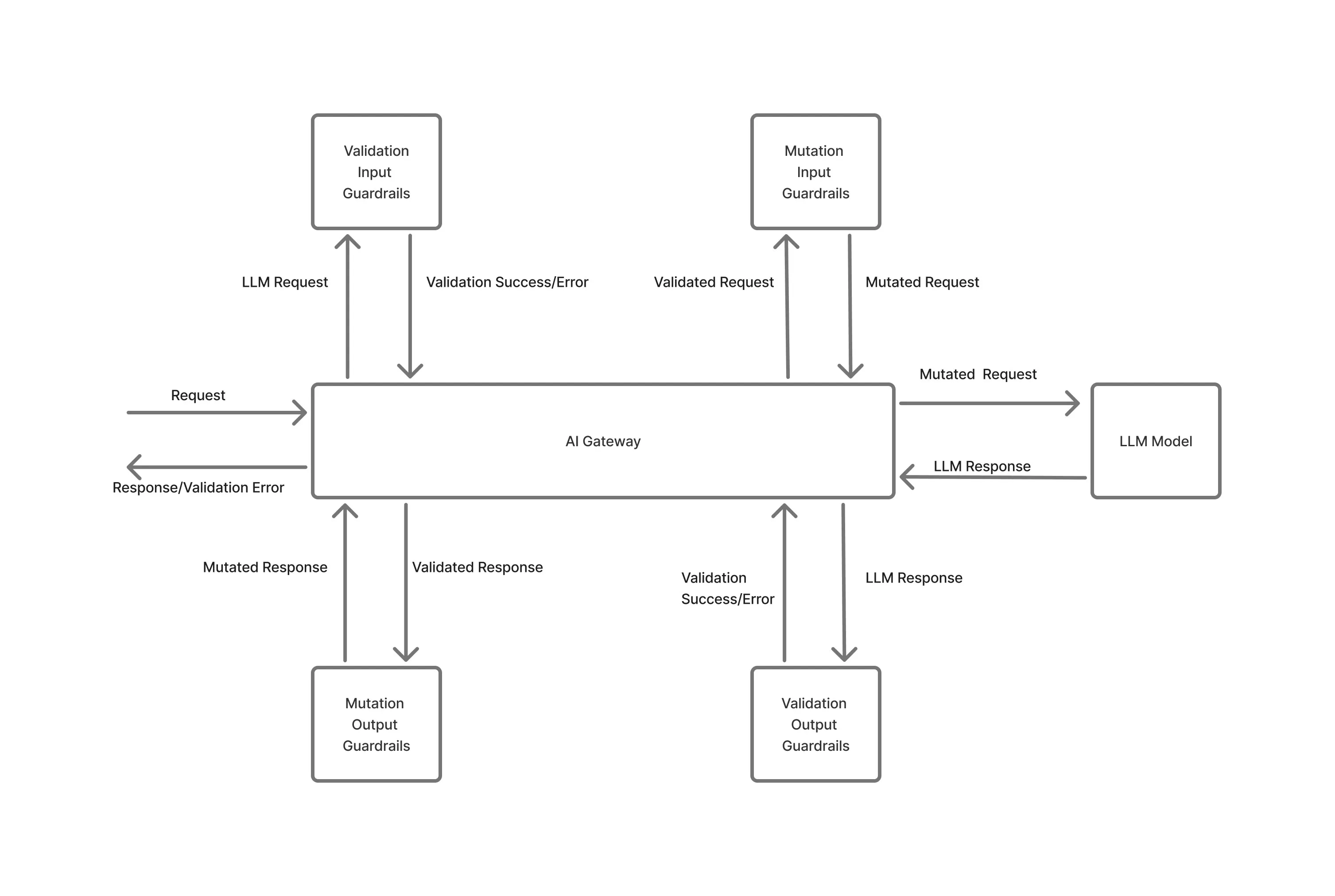
Les systèmes d'IA échouent en production, non pas parce qu'une seule demande n'est pas valide, mais parce que l'utilisation s'accumule de manière inattendue en raison de pics de simultanéité, de tempêtes de nouvelles tentatives ou de charges de travail en arrière-plan exécutées à grande échelle.
TrueFoundry impose l'utilisation garde-corps au moment de l'exécution, avec une visibilité sur le comportement des charges de travail au moment de l'exécution. Les limites de simultanéité, les contraintes de débit et les limites d'utilisation sont appliquées de manière centralisée aux services et aux tâches qui partagent des modèles ou une infrastructure sous-jacents.
Parce que ces limites sont appliquées au niveau de la plate-forme :
Cela est fondamentalement différent des contrôles côté client ou au niveau du SDK, qui supposent que les applications se comportent correctement et indépendamment.
TrueFoundry renforce l'isolation au niveau du couche de déploiement et d'environnement, et pas seulement sur demande d'admission. Les services d'IA, les tâches par lots et les flux de travail des agents sont déployés sous forme de charges de travail isolées dans des environnements définis, avec un accès, des politiques et des ressources délimités par environnement.
Ces charges de travail s'exécutent comme déploiements et tâches séparés avec des processus d'exécution et des domaines de défaillance indépendants, plutôt que de partager un seul contexte d'exécution plat derrière une passerelle. En conséquence :
Les passerelles LLM au niveau de l'application, qui fonctionnent principalement dans le chemin de la demande, ne contrôlent pas l'exécution de l'exécution ni l'état de l'infrastructure. Par conséquent, ils ne peuvent pas fournir ce niveau de déploiement et d'isolation de l'environnement, un problème qui devient de plus en plus visible à mesure que les charges de travail de l'IA évoluent entre les équipes et les environnements de production.

Les métriques au niveau des jetons sont utiles, mais insuffisantes une fois que les charges de travail d'IA couvrent des services de longue durée, des tâches en arrière-plan et des flux de travail des agents. Dans les systèmes de production, les coûts et les performances découlent de l'interaction entre :
TrueFoundry met en corrélation ces signaux au niveau de la plateforme, ce qui permet aux équipes de raisonner sur le comportement de l'IA de la même manière qu'elles raisonnent sur les autres systèmes de production :par environnement, service et propriétaire, et non par des appels d'API individuels.
De nombreux déploiements d'IA d'entreprise sont soumis à des contraintes que les passerelles au niveau des applications suppriment implicitement, notamment :
Le plan de contrôle de TrueFoundry est conçu pour fonctionner sur tous ces modèles de déploiement, garantissant ainsi la cohérence de la gouvernance, de l'isolation et de l'observabilité, quel que soit l'endroit où l'inférence est exécutée. Par conséquent, les propriétés de conformité, telles que les limites des données et l'auditabilité, sont appliquées dans le cadre de l'infrastructure elle-même, au lieu d'être ajoutées ultérieurement par le biais de la logique des applications ou des contrôles de processus.
Kong et Portkey résolvent chacun des problèmes importants à différents stades de l'adoption de l'IA. Kong étend les modèles de passerelle API familiers au trafic d'IA, tandis que Portkey introduit des abstractions natives LLM qui facilitent la création et l'exploitation d'applications basées sur l'IA.
Cependant, à mesure que l'IA devient une capacité partagée critique pour la production, les entreprises sont rapidement confrontées à des défis qui vont au-delà du routage des demandes ou de la gestion rapide. La gouvernance, l'attribution des coûts, l'isolation de l'environnement et la conformité nécessitent tous des contrôles au niveau de l'infrastructure et pas seulement au niveau de la passerelle.
C'est pourquoi de nombreuses organisations vont au-delà des passerelles d'applications API et LLM pour se tourner vers des plateformes d'infrastructure natives d'IA telles que True Foundry, qui sont conçus pour exécuter, gouverner et faire évoluer les systèmes d'IA de manière fiable au sein des équipes et des environnements.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception







.png)

.webp)
.webp)
.webp)



.webp)
.webp)


