



July 20, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les grands modèles linguistiques (LLM) sont de plus en plus puissants et sont utilisés pour diverses tâches, notamment les chatbots, la génération de texte et la réponse à des questions. Cependant, la formation des LLM peut être coûteuse et nécessiter beaucoup de ressources. Dans cet article de blog, nous allons vous montrer comment affiner un LLM plus petit (7B) pour qu'il soit plus performant que ChatGPT.
Le réglage fin est un processus qui consiste à entraîner un LLM sur un ensemble de données spécifique afin d'améliorer ses performances sur une tâche particulière. Dans ce cas, nous allons affiner un LLM 7B pour multiplier deux nombres.
Commençons donc par les performances de différents grands modèles de langage sur une tâche de multiplication simple : 458*987 = 452046.
Dans un premier temps, nous examinerons le modèle Llama-2-7B récemment publié par Meta. Nous avons déployé Lllama-2 sur TrueFoundry et l'avons essayé avec les intégrations Langchain de TrueFoundry. Voici le résultat pour la même chose.
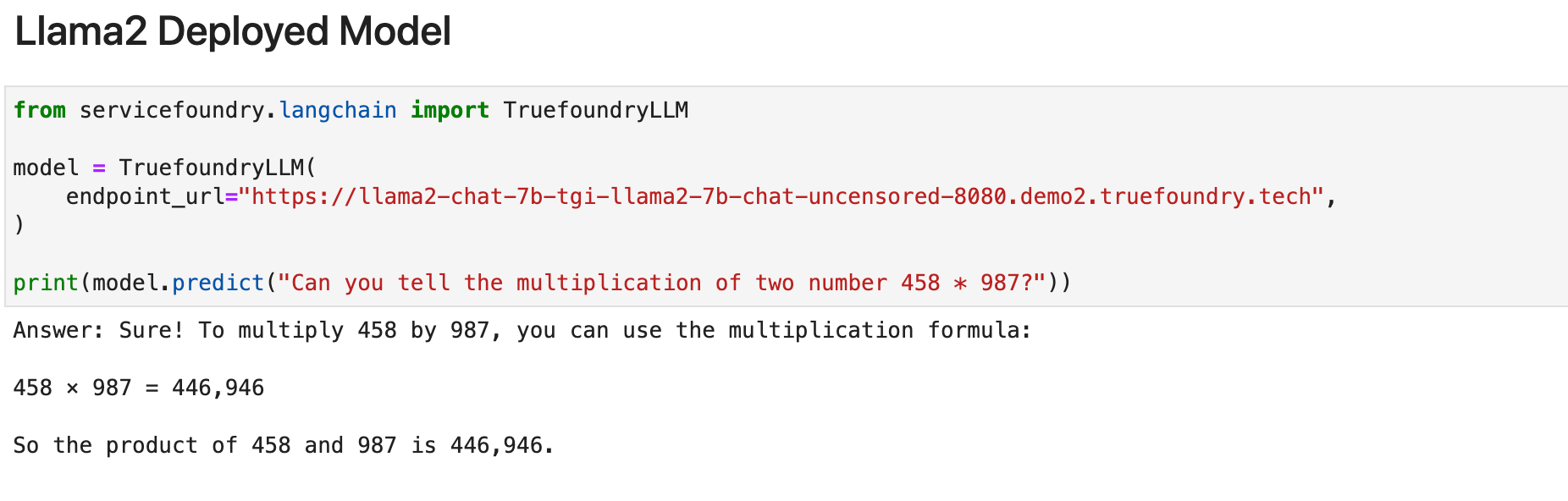
Comme nous pouvons clairement le constater, cela ne fonctionne pas bien dans cette tâche. (ce qui est également attendu compte tenu de la taille du modèle). Voyons comment les modèles de pointe s'acquittent de la même tâche :
Regardons le résultat de ChatGPT (GPT3.5 Turbo) :
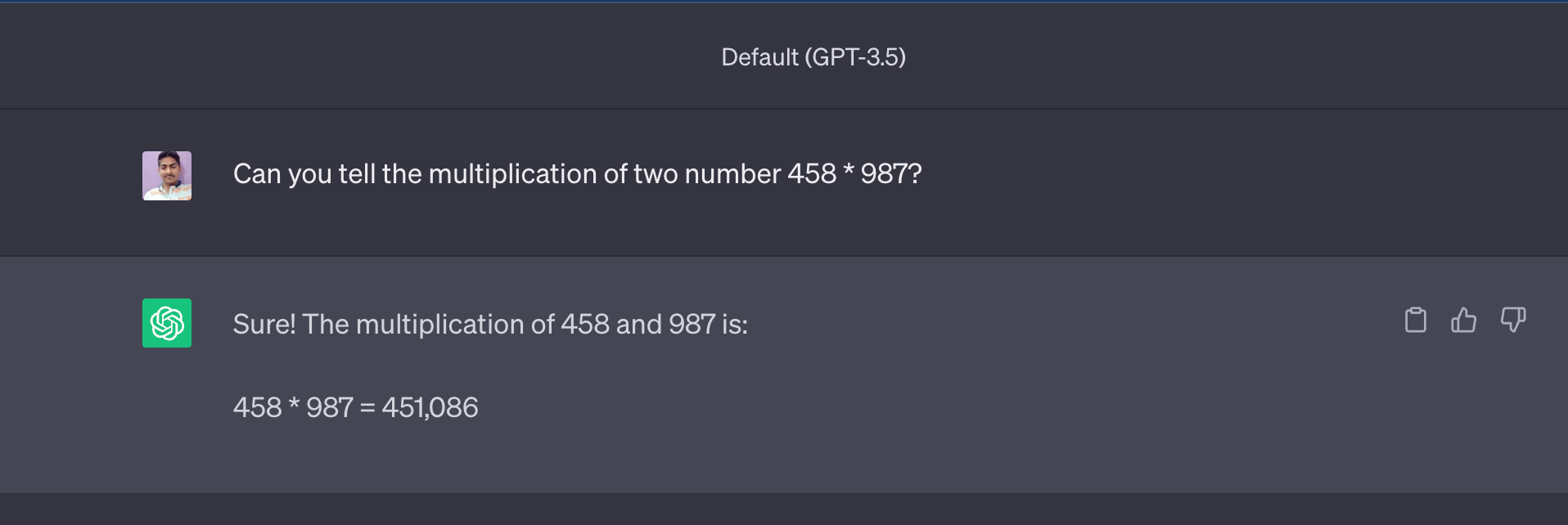
Maintenant, la réponse (451 086) est très proche de la réponse réelle qui est 452 046 mais la réponse n'est pas correcte.
Essayons avec une autre invite (pour faire un calcul étape par étape et voir ce qu'il fait) :
0h00 /1×
ChatGPT avec invite personnalisée pour la multiplication
Mais encore une fois, le résultat est incorrect : 450 606 🤨
Enfin, essayons le State of the Art (GPT-4) et vérifions comment il s'acquitte de la tâche :

Elle est très proche de la bonne réponse (452 046) et peut sembler correcte à tout le monde. Mais il est clair que la réponse est incorrecte.
La réponse à cette question est très simple. Ils ne sont pas « formés » pour cela.
Les LLM sont formés sur des ensembles de données volumineux de texte et de code, mais ces données ne sont pas toujours structurées de manière à faciliter le raisonnement mathématique. Par exemple, les données peuvent ne pas inclure de représentations explicites de concepts mathématiques tels que l'addition, la soustraction, la multiplication et la division. Il peut donc être difficile pour les LLM d'apprendre à effectuer correctement ces opérations.
Nous nous sommes donc demandé s'il était possible de former un LLM à effectuer des opérations mathématiques ? Nous avons fait une expérience et les résultats étaient plutôt prometteurs !
Pour commencer, nous avons organisé un ensemble de données de 40 000 lignes d'instructions et d'instructions. Nous avons essayé de reproduire exactement les étapes suivies dans la méthode de multiplication longue, qui consiste à diviser le multiplicand et le multiplicand en leurs chiffres individuels, puis à multiplier chaque chiffre du multiplicand par chaque chiffre du multiplicand et à placer les résultats dans les positions appropriées en fonction de leurs valeurs de position. Enfin, tous les produits individuels sont additionnés pour obtenir le résultat final.
Voici un exemple d'invite :
Vous êtes un assistant utile fournissant des réponses détaillées aux questions de multiplication. Assurez-vous de fournir une explication complète en utilisant la méthode de multiplication longue pour le problème mathématique ci-dessous.
Si vous ne connaissez pas la réponse à une question, veuillez ne pas partager de fausses informations. Qu'est-ce que 5244 * 1932 ?
Et voici un exemple de réponse :
Voici les étapes pour multiplier 5244 * 1932 en utilisant la méthode de multiplication longue.
Étape 1 : divisez 5244 en ses chiffres individuels : 5 (milliers de places), 2 (centaines de places), 4 (dizaines de places) et 4 (une place).
Étape 2 : De même, divisez 1932 en ses chiffres individuels : 1 (milliers de places), 9 (centaines de places), 3 (dizaines) et 2 (une place).
- 4 (à partir de la première place du premier chiffre) * 2 (à partir de la première place du deuxième numéro) = 8 -> Décalez-le de 0 place vers la gauche (car nous multiplions par la place 1 du deuxième chiffre) pour obtenir 8
- 4 (à partir de la première place du premier chiffre) * 3 (à partir de la 10e place du deuxième numéro) = 12 -> Décalez-le de 1 place vers la gauche (car nous multiplions par les 10 places du deuxième numéro) pour obtenir 120
- 4 (à partir de la première place du premier chiffre) * 9 (à partir de la place 100 du deuxième numéro) = 36 -> Décalez-le de 2 places vers la gauche (car nous multiplions par la place 100 du deuxième numéro) pour obtenir 3600
- 4 (à partir de la première place du premier chiffre) * 1 (à partir de la place 1000 du deuxième numéro) = 4 -> Décalez-le de 3 places vers la gauche (car nous multiplions par les 1000 places du deuxième numéro) pour obtenir 4000
- 4 (à partir de la 10e place du premier chiffre) * 2 (à partir de la place 1 du deuxième numéro) = 8 -> Décalez-le de 1 place vers la gauche (car nous multiplions par la place 1 du deuxième chiffre) pour obtenir 80
- 4 (à partir de la 10e place du premier chiffre) * 3 (à partir de la 10e place du deuxième numéro) = 12 -> Décalez-le de 2 places vers la gauche (car nous multiplions par les 10 places du deuxième numéro) pour obtenir 1200
- 4 (à partir de la 10e place du premier chiffre) * 9 (à partir de la place 100 du deuxième numéro) = 36 -> Décalez-le de 3 places vers la gauche (car nous multiplions par la place 100 du deuxième numéro) pour obtenir 36000
- 4 (à partir de la 10e place du premier chiffre) * 1 (à partir de la place 1000 du deuxième numéro) = 4 -> Décalez-le de 4 places vers la gauche (car nous multiplions par les 1000 places du deuxième numéro) pour obtenir 40000
- 2 (à partir de la place 100 du premier chiffre) * 2 (à partir de la place 1 du deuxième numéro) = 4 -> Décalez-le de 2 places vers la gauche (car nous multiplions par la place 1 du deuxième chiffre) pour obtenir 400
- 2 (à partir de 100 places du premier chiffre) * 3 (à partir de la 10e place du deuxième numéro) = 6 -> Décalez-le de 3 places vers la gauche (car nous multiplions par les 10 places du deuxième numéro) pour obtenir 6000
- 2 (à partir de la place 100 du premier chiffre) * 9 (à partir de la place 100 du deuxième numéro) = 18 -> Décalez-le de 4 places vers la gauche (car nous multiplions par la place 100 du deuxième chiffre) pour obtenir 180000
- 2 (à partir de la place 100 du premier chiffre) * 1 (à partir de la place 1000 du deuxième numéro) = 2 -> Décalez-le de 5 places vers la gauche (car nous multiplions par les 1000 places du deuxième numéro) pour obtenir 200 000
- 5 (à partir de 1000 places du premier chiffre) * 2 (à partir de 1 place du deuxième chiffre) = 10 -> Décalez-le de 3 places vers la gauche (car nous multiplions par la place 1 du deuxième chiffre) pour obtenir 10000
- 5 (à partir de 1000 places du premier chiffre) * 3 (à partir de la 10e place du deuxième chiffre) = 15 -> Décalez-le de 4 places vers la gauche (car nous multiplions par les 10 places du deuxième chiffre) pour obtenir 150000
- 5 (à partir de 1000 places du premier chiffre) * 9 (à partir de la place 100 du deuxième chiffre) = 45 -> Décalez-le de 5 places vers la gauche (car nous multiplions par la place 100 du deuxième chiffre) pour obtenir 4500000
- 5 (à partir de 1000 places du premier chiffre) * 1 (à partir de 1000 places du deuxième numéro) = 5 -> Décalez-le de 6 places vers la gauche (car nous multiplions par les 1000 du deuxième chiffre) pour obtenir 5000000
Maintenant, additionnez tous ces résultats :
La somme de 8 + 120 + 3600 + 4000 + 80 + 1200 + 36000 + 40000 + 400 + 6000 + 180000 + 200000 + 10000 + 150000 + 4500000 + 5000000 = 10131408.
Ensuite, nous avons écrit un script Python qui génère des paires de réponses rapides en sélectionnant au hasard deux chiffres pour la multiplication. Nous avons organisé un ensemble de données de 40 000 lignes.
Maintenant, une fois que l'ensemble de données est prêt, nous devons affiner le modèle.
Nous utilisons la variante de chat affinée de Meta's (7 milliards de paramètres) de Lama-2 comme modèle de base.
Nous avons effectué le réglage fin en utilisant Réglage fin de QLoRa en utilisant la bibliothèque BitsandBytes et Peft. Voici la configuration lora que nous avons utilisée :
Config LoRa (
lora_alpha=16,
lora_drop out=0,1,
r = 64,
bias="aucun »,
task_type="Causal_LM »,
modules_cibles = [
« q_projet »,
« k_projet »,
« v_projet »,
« o_projet »,
],
)
Il a fallu environ 8 heures pour s'entraîner sur une machine GPU A100 de 40 Go pour un ensemble de données de 40 000 lignes.
Enfin, nous avons déployé le modèle affiné sur True Foundry encore une fois et voici les résultats :
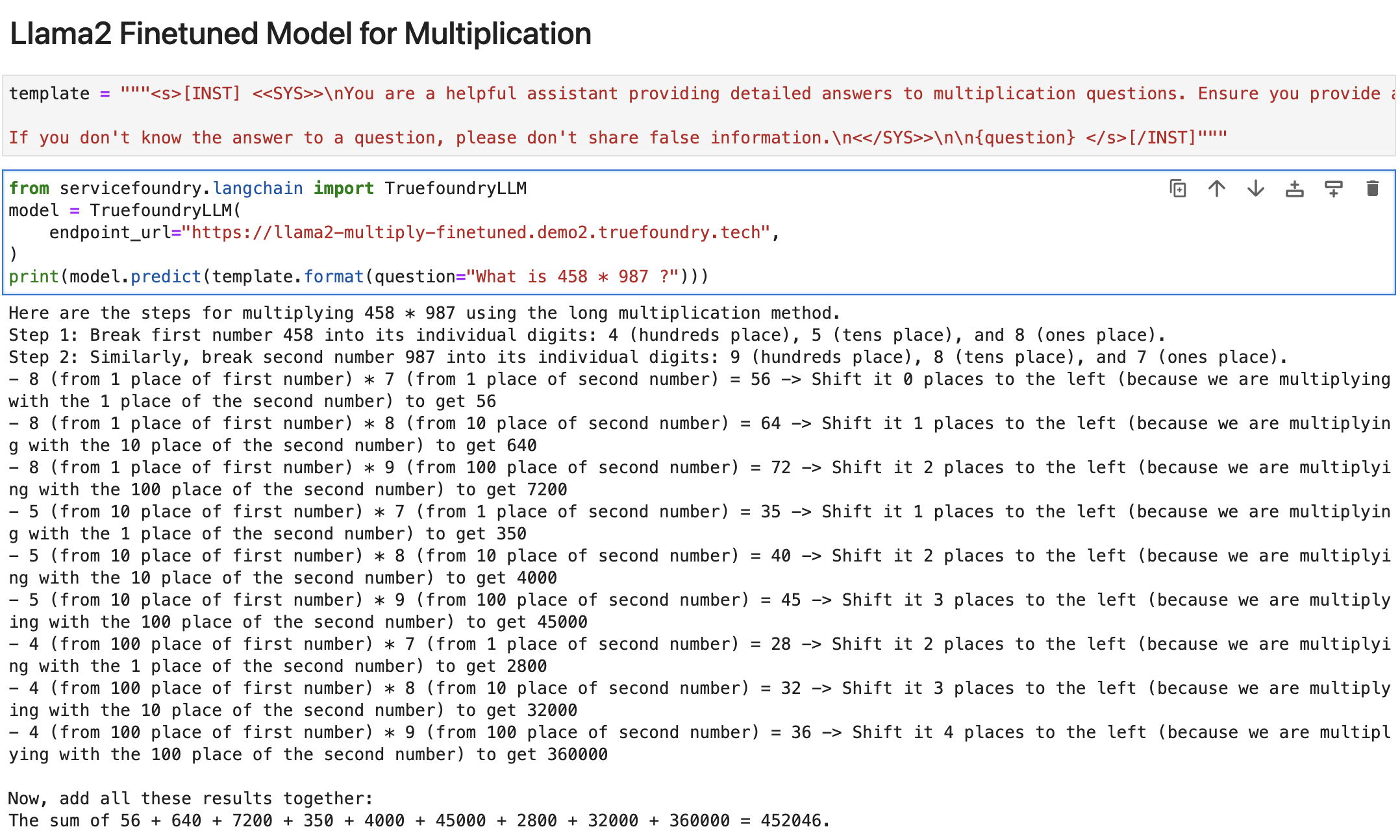
Alors enfin ! Nous pouvons voir que le modèle affiné est capable de calculer correctement le résultat.
Bien que l'arithmétique ne soit pas une tâche pour laquelle nous utiliserons le LLM, cet exemple montre comment un « petit » LLM (paramètres 7B) correctement réglé pour une tâche spécifique peut surpasser les « grands » LLM (comme GPT3.5 turbo - paramètres 175B et GPT-4) sur une tâche spécifique.
Les modèles plus petits (modèles affinés) sont peu coûteux en termes d'inférence, sont meilleurs pour les tâches spécialisées et peuvent être déployés facilement sur votre propre cloud !
Nous avons écrit un blog détaillé sur le réglage de Llama 2
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


