

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les grands modèles linguistiques (LLM) sont allés au-delà des chatbots expérimentaux et des démonstrations publiques ; ils alimentent désormais les flux de travail critiques au sein de l'entreprise. Qu'il s'agisse d'automatiser la recherche de connaissances internes, de générer des rapports, d'améliorer le support client et de garantir la conformité, les LLM redéfinissent le mode de fonctionnement des entreprises modernes. Mais déployer des LLM dans des environnements d'entreprise n'est pas aussi simple que de se connecter à une API. Elle exige une gouvernance, une observabilité, des garanties de confidentialité et une infrastructure adaptée. Ce guide explore l'évolution du paysage des LLM d'entreprise, en abordant les principaux défis, les modèles de déploiement, les meilleures pratiques de surveillance et la manière dont des plateformes telles que TrueFoundry permettent une adoption sécurisée et évolutive des LLM dans tous les secteurs.
Le battage médiatique autour des LLM a déclenché une vague d'adoption, mais pour les entreprises, le véritable défi n'est pas de générer des réponses tape-à-l'œil. Il déploie ces modèles de manière intelligente et responsable. Un véritable LLM d'entreprise n'est pas simplement un ChatGPT avec un emballage professionnel. Il s'agit d'un système basé sur vos données propriétaires, optimisé pour vos flux de travail et déployé en tenant compte de vos exigences en matière de conformité, de coûts et de contrôle.
La plupart des LLM publics sont formés aux données ouvertes sur Internet. Ils sont donc puissants dans le raisonnement linguistique général, mais peu fiables lorsqu'ils sont appliqués à des contextes spécifiques à l'entreprise, en particulier lorsque la précision, la traçabilité et la sécurité sont importantes. Par exemple, une société de services financiers ne peut pas se permettre des faits hallucinés, de vagues avertissements ou des réponses imprévisibles. Ce dont ils ont besoin, c'est d'un modèle qui tienne compte du domaine, qui puisse être audité et qui puisse être déployé derrière des pare-feux. Cette méthode est souvent associée à la génération augmentée par extraction (RAG), ce qui lui permet de raisonner sur des documents internes, et pas seulement sur ce sur quoi elle a été préalablement entraînée.
Les LLM d'entreprise sont en train de devenir des copilotes internes. Les équipes juridiques les utilisent pour rédiger des contrats, les équipes RH pour répondre aux questions des employés, les développeurs pour accélérer le code et les équipes de support pour résumer et résoudre les tickets plus rapidement. Mais ces résultats ne sont possibles que si le LLM est bien intégré, surveillé en production et aligné sur les limites des données de l'organisation.
Ce changement est également le signe d'une évolution philosophique. Nous ne traitons plus les LLM comme des boîtes noires magiques mais comme des systèmes d'IA modulaires, où l'orchestration, la mise à la terre, l'observabilité et les boucles de rétroaction sont tout aussi importants que le modèle de base lui-même.
Mise en œuvre réussie LLM en entreprise ne se limite pas à la capacité de l'IA. Ils concernent l'effet de levier commercial. Pour cela, il faut penser bien au-delà du modèle, à l'architecture, à l'infrastructure et à la confiance organisationnelle dont il dépend.
Bien que le potentiel des Enterprise LLM soit vaste, leur déploiement dans un environnement professionnel réel comporte des défis critiques que les organisations doivent relever dès le premier jour.
Confidentialité et sécurité des données : Les LLM d'entreprise fonctionnent souvent sur des données internes sensibles, des contrats, des dossiers clients, du code source et des données financières. Cela soulève de graves préoccupations en matière de fuite de données, d'accès non autorisé et de non-conformité réglementaire. Sans contrôles d'accès stricts, cryptage et nettoyage rapide, les sorties LLM peuvent exposer involontairement des informations confidentielles.
Hallucinations et fiabilité : Les LLM ont tendance à générer des réponses confiantes mais incorrectes, également appelées hallucinations. Dans une entreprise, cela peut entraîner des erreurs opérationnelles, des risques juridiques et une perte de confiance. Il est donc essentiel d'ancrer le modèle dans des documents internes via des pipelines RAG pour garantir l'exactitude des faits.
Injection rapide et entrées contradictoires : Les entreprises doivent se protéger contre les messages malveillants ou manipulateurs qui contournent les filtres ou extraient des données involontaires. Sans une validation des entrées et des garde-fous appropriés, les modèles peuvent devenir des vecteurs d'ingénierie sociale ou de fuites.
Coûts et frais généraux d'infrastructure : L'exécution de grands modèles sur des GPU à grande échelle entraîne des coûts d'inférence élevés. C'est ici Inférence LLM La stratégie devient essentielle, car la taille du modèle, les lots et les choix matériels déterminent directement la latence et la rentabilité de l'entreprise. Les entreprises doivent gérer la latence, le débit et l'évolutivité tout en maîtrisant les dépenses liées au cloud. Il est essentiel de choisir la bonne taille de modèle et d'optimiser le traitement par lots, la mise en cache et la quantification.
Surveillance et contrôle de version : Contrairement aux logiciels traditionnels, le comportement du LLM peut légèrement évoluer au fil du temps. Les entreprises ont besoin d'outils pour suivre les instructions, les résultats, la qualité des réponses et les tendances d'utilisation. Le manque d'observabilité peut entraîner une mauvaise utilisation du modèle, une sous-performance ou un non-respect des SLA.
Complexité de l'évaluation : L'évaluation des LLM n'est pas triviale. Cela nécessite des benchmarks personnalisés, des boucles de feedback et des mesures spécifiques à la tâche, telles que la pertinence, la cohérence et la factualité.
Chacun de ces défis nécessite une approche structurée pour atténuer les risques et permettre une mise à l'échelle. Sans eux, les initiatives LLM restent bloquées en mode prototype et n'atteignent jamais leur véritable maturité d'entreprise.
Les entreprises de tous les secteurs vont au-delà de l'expérimentation et commencent à déployer des LLM dans des environnements de production. Ces déploiements se concentrent sur des cas d'utilisation internes à fort impact qui peuvent générer un retour sur investissement mesurable tout en minimisant les risques.
Extraction de connaissances et recherche interne
L'une des applications les plus courantes est la recherche d'entreprise. En combinant les LLM avec des systèmes de récupération tels que des bases de données vectorielles, les entreprises permettent aux employés d'interroger la documentation interne en langage naturel. Cela améliore l'accès aux connaissances pour les équipes RH, juridiques, de conformité et informatiques.
Automatisation du support client
Les entreprises intègrent les LLM dans les flux de travail du support client. Les modèles facilitent la synthèse des tickets, la génération d'e-mails et le routage des intentions. Associés à des données d'assistance historiques, les LLM peuvent réduire considérablement les temps de réponse et améliorer la satisfaction des clients.
Synthèse et classification des documents
Les LLM sont utilisés pour analyser et résumer de longs rapports, contrats ou transcriptions. Les entreprises des secteurs juridique, financier et de la santé bénéficient du traitement automatisé des documents, qui réduit le temps de révision manuelle et accélère la prise de décision.
Productivité des développeurs
Les équipes techniques déploient des LLM axés sur le code pour accélérer le développement de logiciels. Les copilotes internes suggèrent des extraits de code, identifient les bogues et génèrent de la documentation sur la base de référentiels internes. Cela augmente la rapidité de l'ingénierie sans compromettre la sécurité.
Assistants spécifiques à un domaine
Certaines organisations mettent au point des assistants basés sur le LLM et adaptés à des flux de travail spécifiques. Par exemple, les compagnies d'assurance utilisent des modèles formés à partir des données relatives aux sinistres pour signaler les anomalies ou pré-remplir les formulaires. Les sociétés de conseil utilisent des LLM pour préparer des dossiers de recherche basés sur leurs bases de données propriétaires.
Parmi les exemples concrets, citons l'utilisation interne de StarCoder par VMware pour l'ingénierie, l'espace de travail Enterprise LLM Workspace de l'armée américaine pour l'accès à la documentation et la plateforme de recherche d'entreprise pilotée par l'IA de Glean.
La réussite des déploiements repose non seulement sur le modèle, mais aussi sur l'intégration avec les données, les outils et les pratiques de gouvernance internes. Il ne s'agit pas de solutions prêtes à l'emploi. Il s'agit de systèmes personnalisés conçus spécialement pour avoir un impact sur l'entreprise.
L'une des décisions architecturales les plus importantes pour toute initiative LLM d'entreprise est de savoir où déployer le modèle. Les déploiements sur site et dans le cloud offrent des avantages distincts, en fonction des priorités, des contraintes et de l'environnement réglementaire de l'organisation.
Déploiement sur site
Les entreprises dont la gouvernance des données est stricte, comme les secteurs de la santé, de la finance ou de l'administration, optent souvent pour des déploiements sur site. Ils garantissent un contrôle total des données sensibles, permettant ainsi le respect des politiques internes et des réglementations externes. Les configurations sur site réduisent également la dépendance à l'égard d'une infrastructure tierce et permettent de régler les performances au niveau matériel. Cependant, ils nécessitent des investissements importants dans les GPU, une expertise DevOps et une maintenance continue. Les mises à jour, les correctifs et la mise à l'échelle des modèles deviennent des responsabilités internes, ce qui peut ralentir l'innovation si les ressources ne sont pas suffisantes.
Déploiement du cloud
Les LLM basés sur le cloud sont plus rapides à adopter et plus faciles à faire évoluer. Des fournisseurs tels qu'OpenAI, AWS Bedrock, Google Cloud et Azure proposent des API gérées avec un accès instantané à des modèles de pointe. Ces services réduisent la charge opérationnelle et accélèrent le délai de rentabilisation, en particulier lors des premières expérimentations. Mais ils s'accompagnent de préoccupations concernant la confidentialité des données, la dépendance vis-à-vis des fournisseurs et les coûts récurrents. Pour de nombreuses entreprises, l'envoi de données propriétaires vers des terminaux externes est un échec à moins que des politiques strictes de cryptage, d'anonymisation et d'accès ne soient appliquées.
Solutions hybrides et VPC
Une tendance croissante est le déploiement hybride, où l'inférence s'exécute dans un environnement de cloud privé virtuel (VPC). Cela permet d'équilibrer la flexibilité du cloud avec la sécurité d'une infrastructure isolée. Des plateformes telles que TrueFoundry et Hugging Face prennent en charge l'hébergement privé de modèles open source dans des environnements contrôlés par l'entreprise, offrant ainsi le meilleur des deux mondes.
Le choix du bon modèle de déploiement n'est pas qu'une décision technique. Cela a un impact direct sur la conformité, les performances et les coûts à long terme. Les entreprises doivent évaluer leurs cas d'utilisation, leur tolérance au risque et la maturité de leur infrastructure avant de s'engager dans une voie.
La surveillance des LLM dans les environnements d'entreprise est fondamentalement différente de la surveillance des modèles d'apprentissage automatique traditionnels. Les LLM sont probabilistes, non déterministes et très sensibles au contexte. Sans observabilité adéquate, leur comportement peut dériver silencieusement, générer des sorties incorrectes ou introduire des risques, sans aucun signe de défaillance du système.
Suivi et gestion des versions rapides : Les entreprises doivent suivre chaque interaction entre les utilisateurs et le LLM, y compris la structure exacte des invites, les messages système et la fenêtre contextuelle. L'observabilité commence par une traçabilité complète. L'enregistrement des modèles d'invite, des versions de modèles, des paramètres de température et des paires entrées-sorties permet aux équipes de reproduire et d'analyser les résultats ultérieurement.
Évaluation des résultats et ancrage : Il est crucial de contrôler l'exactitude factuelle et la pertinence des réponses du LLM. Les entreprises devraient mettre en place des contrôles automatiques pour détecter les hallucinations, par exemple en validant les résultats par rapport à des documents internes connus ou en imposant la citation des sources à l'aide de pipelines RAG. L'évaluation des résultats à l'aide de rubriques de notation telles que l'utilité, l'exactitude et l'exhaustivité permet de structurer le suivi.
Latence et utilisation des jetons : Alors que les mesures d'infrastructure sont gérées ailleurs, l'observabilité au niveau de la couche LLM inclut le suivi de la taille d'entrée des jetons, de la longueur de sortie et de la consommation totale des jetons. Ces indicateurs ont une incidence directe sur le temps de réponse et les coûts. Les pics de jetons peuvent indiquer des problèmes techniques rapides ou une mauvaise utilisation.
Détection des sorties dangereuses ou dangereuses : Les LLM peuvent générer un langage biaisé, offensant ou non conforme en cas de défaillance des garde-fous. Les entreprises doivent surveiller les sorties pour détecter les termes sensibles, les violations de tonalité ou les fuites de données à l'aide de modèles ou de classificateurs. Les tests faisant équipe et les tests contradictoires peuvent révéler des angles morts.
Intégration de la boucle de rétroaction : Les commentaires des utilisateurs sont essentiels. Les entreprises doivent saisir les corrections, les signaux d'insatisfaction et les notations. Ces signaux contribuent à l'affinement rapide, aux mises à jour du RAG et à l'ajustement du modèle.
Sans observabilité ciblée, les LLM se comportent comme des boîtes noires. Grâce à un suivi approprié, ils deviennent des systèmes transparents auxquels les entreprises peuvent faire confiance, auditer et améliorer en permanence.
TrueFoundry est spécialement conçu pour aider les entreprises à déployer, gérer et faire évoluer les applications LLM avec le contrôle, la sécurité et les performances qu'exigent les environnements de production. Contrairement aux plateformes d'IA génériques, TrueFoundry se concentre sur une infrastructure d'IA modulaire de niveau production qui s'intègre dans l'environnement cloud, sur site ou hybride d'une entreprise.
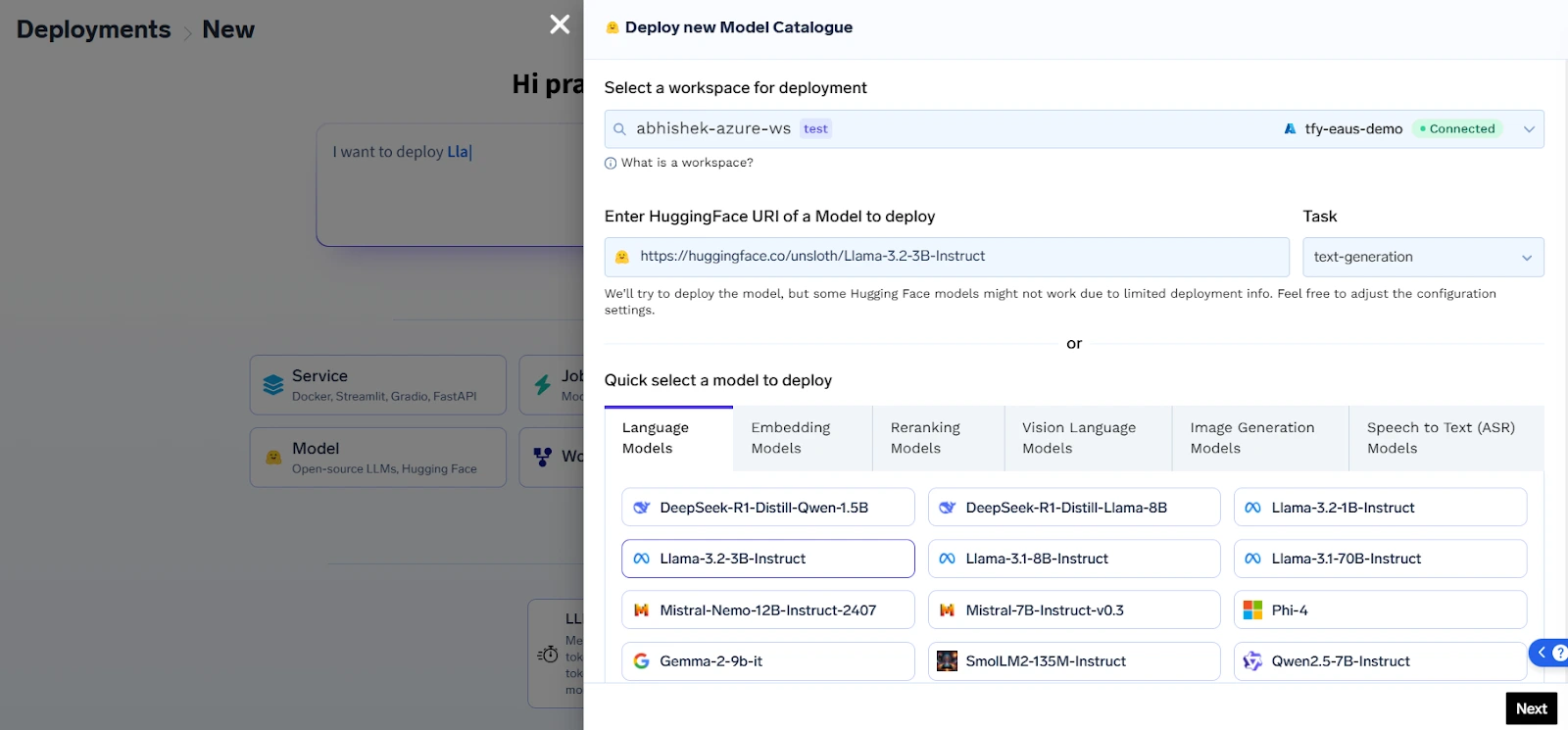
Au cœur de son offre se trouve une couche d'infrastructure d'IA native de Kubernetes qui permet aux équipes de déployer des LLM propriétaires et open source tels que LLama, Mistral, Falçon et GPT-J avec un contrôle total sur l'hébergement, la mise en réseau et la sécurité. Cela garantit que les données sensibles de l'entreprise restent à l'intérieur des limites de l'organisation, qu'elles soient déployées dans un cloud privé ou dans un centre de données sur site.
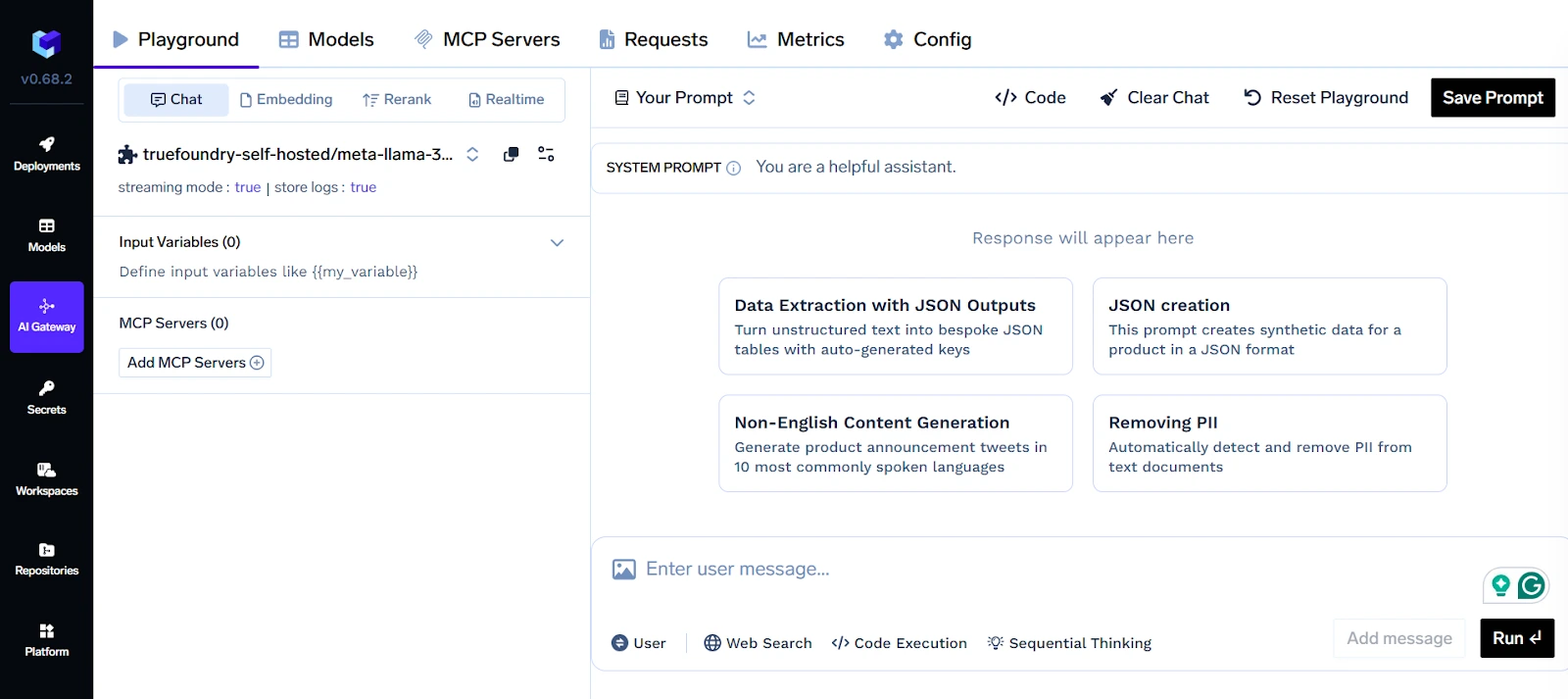
Pour les entreprises utilisant plusieurs fournisseurs LLM (par exemple, OpenAI, Anthropic, Cohere), TrueFoundry propose une passerelle LLM unifiée. Cette couche d'abstraction permet aux équipes de passer d'un fournisseur à l'autre ou d'acheminer le trafic de manière intelligente en fonction des besoins en termes de coût, de latence ou de conformité. Il prend également en charge les stratégies de repli et multimodèles, essentielles à la fiabilité des environnements de production.
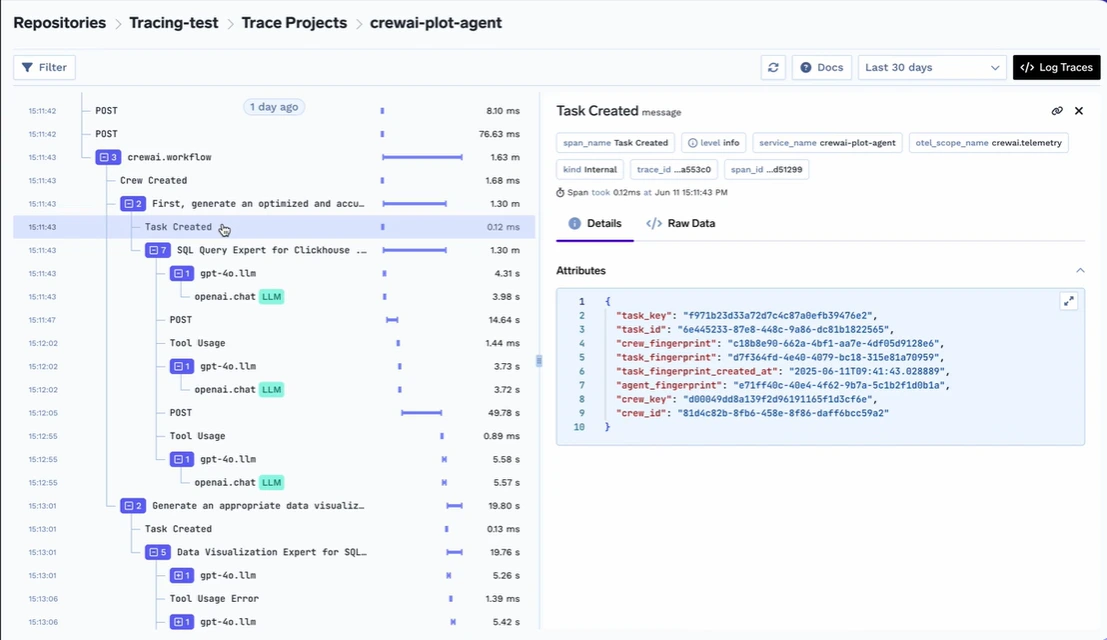
Pour garantir la confiance et l'observabilité, TrueFoundry fournit une surveillance et des analyses approfondies au niveau de la rapidité et de la réponse, fonctionnant comme une couche centrale aux côtés de l'entreprise Outils d'observabilité LLM. Les entreprises peuvent suivre les instructions utilisées, le comportement des modèles au fil du temps et le niveau de latence ou le coût associés à chaque demande. Cela est essentiel pour le débogage, les audits de conformité et l'optimisation des performances.
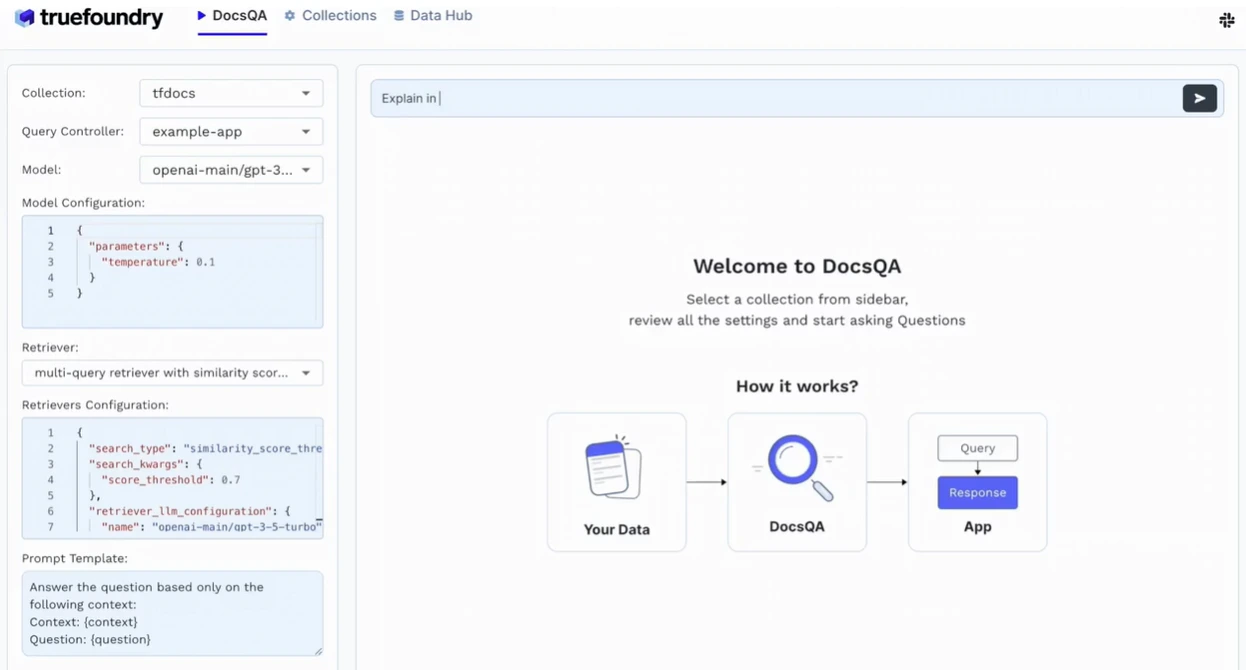
TrueFoundry prend également en charge la technologie RAG (Retrieval-Augmented Generation) prête à l'emploi, permettant aux entreprises d'intégrer les réponses LLM à leurs connaissances internes. Il s'intègre aux magasins vectoriels populaires tels que Weaviate, Pinecone et Qdrant, permettant des réponses précises et contextuelles sans avoir à réentraîner les modèles de base.
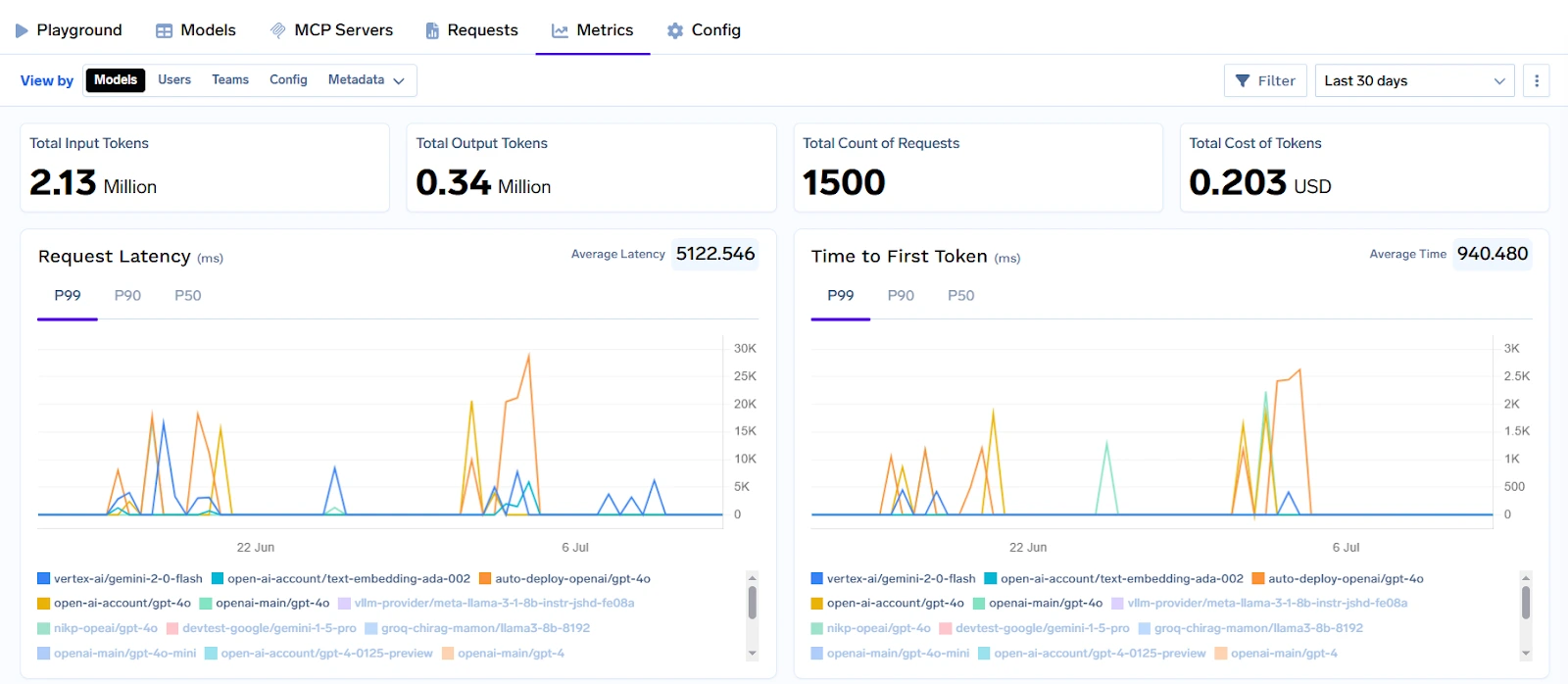
Les entreprises peuvent également tirer parti de la gestion rapide des versions, du suivi de l'utilisation des jetons et de l'optimisation des pipelines grâce à des environnements sandbox sécurisés. Les contrôles d'accès, la gestion des clés d'API et les pistes d'audit garantissent une sécurité et une gouvernance de niveau professionnel. TrueFoundry assure la transparence et le contrôle des coûts grâce à une facturation granulaire, à une limitation des tarifs et à des quotas d'utilisation, offrant aux équipes d'ingénierie et des finances une visibilité totale sur l'utilisation du LLM à grande échelle.
Avec TrueFoundry, les entreprises ne se contentent pas de déployer des LLM, elles les opérationnalisent. La plateforme comble le fossé entre l'expérimentation et la production, permettant de créer des applications fiables, conformes et évolutives alimentées par LLM.
Au fur et à mesure que les entreprises adoptent les LLM, l'accent est mis sur l'optimisation, l'orchestration et l'évolutivité plutôt que sur l'accès. L'une des tendances les plus importantes est la montée en puissance de modèles open source petits et efficaces. Des modèles tels que Mistral, Phi-3 et DBRX montrent que la taille n'est plus le seul indicateur de qualité. Les entreprises peaufinent de plus en plus ces modèles plus petits pour répondre aux besoins spécifiques des tâches tout en réduisant les coûts et la latence.
Une autre tendance émergente est l'évolution vers des systèmes agentiques, dans lesquels les LLM ne se contentent pas de répondre aux demandes, mais agissent comme des agents autonomes qui planifient, raisonnent et exécutent des tâches sur plusieurs systèmes. Cela permet des flux de travail d'entreprise plus complexes tels que l'intégration, le traitement des documents en plusieurs étapes et l'analyse automatisée.
Nous constatons également une intégration approfondie avec les graphes de connaissances et les bases de données d'entreprise. Au lieu de s'appuyer uniquement sur des intégrations et des magasins vectoriels, les organisations connectent les LLM à des sources de connaissances structurées afin de fournir des résultats plus fondés, vérifiables et traçables.
Enfin, les outils de gouvernance et de conformité deviendront non négociables. Alors que de plus en plus de flux de travail critiques passent par des LLM, les entreprises exigeront un contrôle rigoureux des invites, des sorties et des autorisations des utilisateurs.
Ces tendances laissent présager un avenir dans lequel les LLM deviendront une infrastructure fondamentale, sécurisée, composable et profondément intégrée dans les opérations de l'entreprise.
Les LLM d'entreprise ne sont plus des expériences ; ils sont en train de devenir rapidement un élément essentiel de l'infrastructure commerciale moderne. Mais pour réaliser leur plein potentiel, il ne suffit pas d'accéder à des modèles puissants. Cela nécessite une architecture, une stratégie de déploiement, des systèmes de surveillance et des cadres de gouvernance adaptés. Grâce à des plateformes telles que TrueFoundry, les entreprises peuvent aller au-delà des prototypes et créer des applications LLM sécurisées, évolutives et axées sur le retour sur investissement. Au fur et à mesure de l'évolution de l'écosystème, les gagnants seront ceux qui considèrent les LLM non pas comme des outils magiques, mais comme des systèmes gérés profondément intégrés, constamment observés et alignés sur les résultats commerciaux.
Un LLM d'entreprise est un vaste modèle linguistique optimisé pour les environnements d'entreprise, qui donne la priorité à la sécurité des données, à l'évolutivité et à l'intégration aux systèmes internes. Contrairement aux modèles à usage général, un LLM pour entreprise est conçu pour fonctionner au sein du cloud privé ou de l'infrastructure sur site de l'entreprise, garantissant ainsi la protection des données sensibles. Ces modèles sont généralement utilisés pour alimenter des outils spécialisés tels que des bases de connaissances internes et des flux de travail automatisés.
Pour créer un LLM d'entreprise, les organisations doivent aller au-delà des simples appels d'API et établir un pipeline de production. Cela implique la mise en place d'une infrastructure robuste pour l'hébergement des modèles, la mise en œuvre de la génération augmentée par extraction (RAG) pour ancrer le modèle dans des données privées et la création d'une passerelle IA pour une gestion centralisée. TrueFoundry rationalise ce processus en fournissant les outils MLOps nécessaires au déploiement et à la mise à l'échelle de ces modèles tout en maintenant une gouvernance complète.
Les cas d'utilisation courants du LLM en entreprise incluent la création de moteurs de recherche basés sur RAG pour les documents propriétaires, l'automatisation de l'analyse de contrats complexes et le déploiement d'agents d'IA pour le support technique. En tirant parti du LLM en entreprise, les entreprises peuvent réduire considérablement le temps de traitement manuel tout en augmentant la précision de la recherche d'informations internes.
Les benchmarks standard ne parviennent souvent pas à prendre en compte les exigences d'un environnement de production. Pour un LLM d'entreprise, les critères de référence essentiels incluent la latence d'inférence, la rentabilité des jetons et les mesures de « fidélité » dans les pipelines RAG afin de garantir qu'aucune hallucination ne se produise. Le suivi de ces benchmarks permet aux équipes d'évaluer si un modèle spécifique répond aux normes de performance et de fiabilité requises pour les applications destinées aux clients ou critiques.
Pour choisir le LLM d'entreprise adapté à créer, il faut trouver un équilibre entre les performances du modèle et les exigences de souveraineté des données. De nombreuses organisations utilisent une combinaison de modèles propriétaires pour des raisonnements complexes et de modèles open source pour les tâches volumineuses et sensibles à la confidentialité. Une plateforme flexible comme TrueFoundry vous permet d'éviter la dépendance vis-à-vis d'un fournisseur en fournissant une interface unifiée permettant de passer d'un modèle à l'autre en fonction des coûts et des besoins de sécurité spécifiques de chaque projet.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


