Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
9,9
Améliorer le support client grâce à une assistance IA en temps réel à l'aide de Cognita
Cognita est un framework RAG open source polyvalent conçu pour permettre aux leaders de la science des données, de l'apprentissage automatique et de l'ingénierie des plateformes de créer et de déployer des applications RAG évolutives. Il présente une architecture entièrement modulaire, conviviale et adaptable, garantissant une sécurité et une conformité complètes. Il est également livré avec une interface utilisateur qui permet d'essayer plus facilement différentes configurations RAG et de voir les résultats en temps réel.
Présentation du cas d'utilisation
À une époque où l'expérience client est la clé de la réussite commerciale, la capacité à fournir une assistance immédiate et précise est cruciale. Le framework Cognita de TrueFoundry permet de développer des applications d'IA sophistiquées en temps réel adaptées au support client. En tirant parti de la nature modulaire et open source de Cognita, les entreprises peuvent améliorer leurs systèmes de support pour fournir un service client de qualité supérieure.
Quel est le problème que nous essayons de résoudre ?
Les systèmes de support client actuels rencontrent des difficultés considérables pour répondre aux attentes élevées des clients en matière de réponses rapides et précises. Les approches de support classiques ne permettent pas de traiter un grand nombre de demandes, de garantir la cohérence des réponses et d'assurer une disponibilité 24 h/24 et 7 j/7. Ces difficultés entraînent une hausse des dépenses d'exploitation, une baisse de la satisfaction des clients et des inefficacités, ce qui peut freiner la croissance de l'entreprise.
Support client manuel ou automatisé
Dans un système de support client manuel traditionnel, les agents humains sont chargés de répondre individuellement à chaque demande du client. Ce processus laborieux implique que les agents parcourent de vastes bases de connaissances, une documentation et des enregistrements de requêtes antérieurs pour trouver des informations précises et pertinentes. La variabilité des performances humaines peut entraîner des incohérences dans les réponses, la qualité de l'assistance dépendant largement de l'expertise et de l'expérience de l'agent. En outre, le maintien d'un système d'assistance 24h/24 et 7j/7 nécessite une main-d'œuvre importante, ce qui nécessite des rotations d'équipes et entraîne une augmentation des coûts opérationnels. Pendant les périodes de pointe, l'approche manuelle entraîne souvent des retards, des temps de réponse prolongés et une insatisfaction des clients.
Ce pipeline automatisé réduit non seulement de manière significative les temps de réponse, mais garantit également que chaque interaction client est traitée avec une précision et une fiabilité constantes. L'évolutivité de Cognita permet au système de traiter un grand nombre de demandes à la fois, ce qui en fait un choix pratique pour les entreprises confrontées à une croissance ou à une évolution des demandes de support. En outre, cette automatisation soulage les agents humains des questions banales, leur permettant de se concentrer sur des problèmes plus complexes, augmentant ainsi l'efficience et l'efficacité globales des opérations de support.
Solution
La transition vers un système automatisé basé sur le framework Cognita de TrueFoundry permet l'intégration de composants d'IA avancés pour automatiser la gestion des requêtes des clients. Plus précisément, l'utilisation de chargeurs de données et analyseurs garantit qu'un ensemble de données complet et structuré est facilement disponible pour que le système puisse en tirer des enseignements. En mettant en œuvre intégrateurs, les données textuelles sont converties en vecteurs de grande dimension, ce qui facilite des recherches de similarité efficaces et précises. Le bases de données vectorielles permettent une récupération rapide de ces informations intégrées, garantissant ainsi des performances en temps réel. Lorsqu'une requête est reçue, le contrôleur de requêtes orchestre le processus en utilisant reclassement pour évaluer et hiérarchiser les réponses les plus pertinentes.
La mise en œuvre de Cognita pour le support client permet de relever ces défis en :
Gestion automatique des requêtes: Utilisation des intégrateurs et des bases de données vectorielles de Cognita pour récupérer rapidement les informations pertinentes et fournir des réponses précises aux demandes des clients.
Assistance en temps réel : Tirer parti des modules de reclassement et de contrôleur de requêtes pour garantir la fourniture des informations les plus pertinentes et les plus concises, améliorant ainsi l'expérience du client.
Évolutivité: La conception modulaire de Cognita permet d'adapter facilement le système pour gérer des volumes croissants de requêtes sans compromettre les performances.
Déploiement de Cognita à l'aide de TrueFoundry
Vous pouvez utiliser Cognita localement ou avec/sans utiliser de composants Truefoundry. Cependant, l'utilisation de composants Truefoundry permet de tester plus facilement différents modèles et de déployer le système de manière évolutive. Cognita vous permet d'héberger plusieurs systèmes RAG à l'aide d'une seule application. Par conséquent, nous utiliserons les composants TrueFoundry pour créer un robot de support à petite échelle uniquement pour le MacBook Pro dans un premier temps, puis nous ajouterons quelques produits supplémentaires et la prise en charge de différentes langues afin de le faire évoluer.
Une fois que vous avez configuré un cluster, ajouté une intégration de stockage et créé un dépôt ML et un espace de travail, vous êtes prêt à commencer à déployer une application RAG basée sur Cognita à l'aide de TrueFoundry. Vous trouverez plus d'informations sur cette configuration unique ici. Une fois terminé :
Naviguez jusqu'au Déploiements onglet.
Cliquez sur le + Nouveau déploiement bouton en haut à droite et sélectionnez Catalogue des applications. Sélectionnez votre espace de travail et l'application RAG.
Remplissez le modèle de déploiement
Donnez un nom à votre déploiement
Ajouter ML Repo
Vous pouvez soit ajouter une base de données Qdrant existante, soit en créer une nouvelle
Par défaut, relâche la branche est utilisée pour le déploiement (vous trouverez cette option dans Afficher les champs avancés). Vous pouvez modifier le nom de la branche et le dépôt git si nécessaire.
Assurez-vous de sélectionner à nouveau la branche principale, car le commit SHA n'est pas mis à jour automatiquement.
Cliquez sur Soumettre, et votre application sera déployée.
Étapes d'implémentation
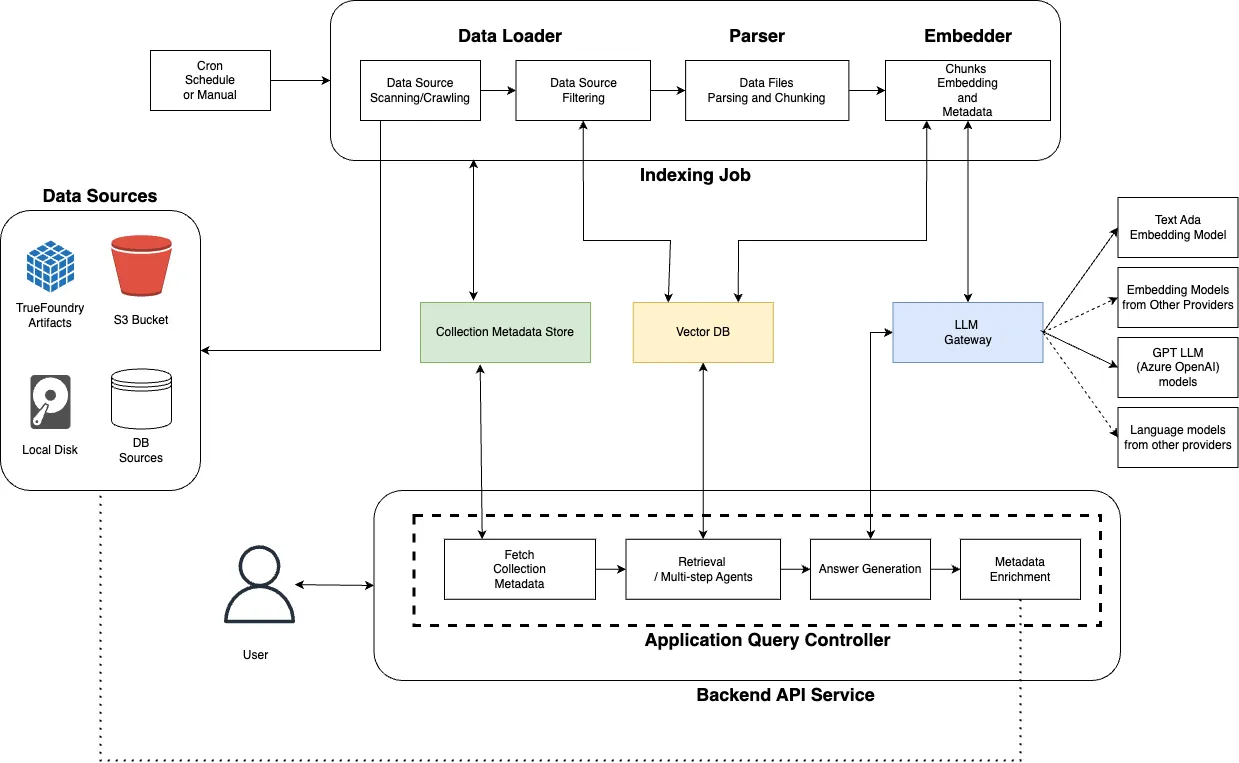
Architecture du projet Cognita
Dans l'ensemble, l'architecture de Cognita est composée de plusieurs entités. Nous aborderons chacun d'entre eux à travers les étapes de mise en œuvre ci-dessous.
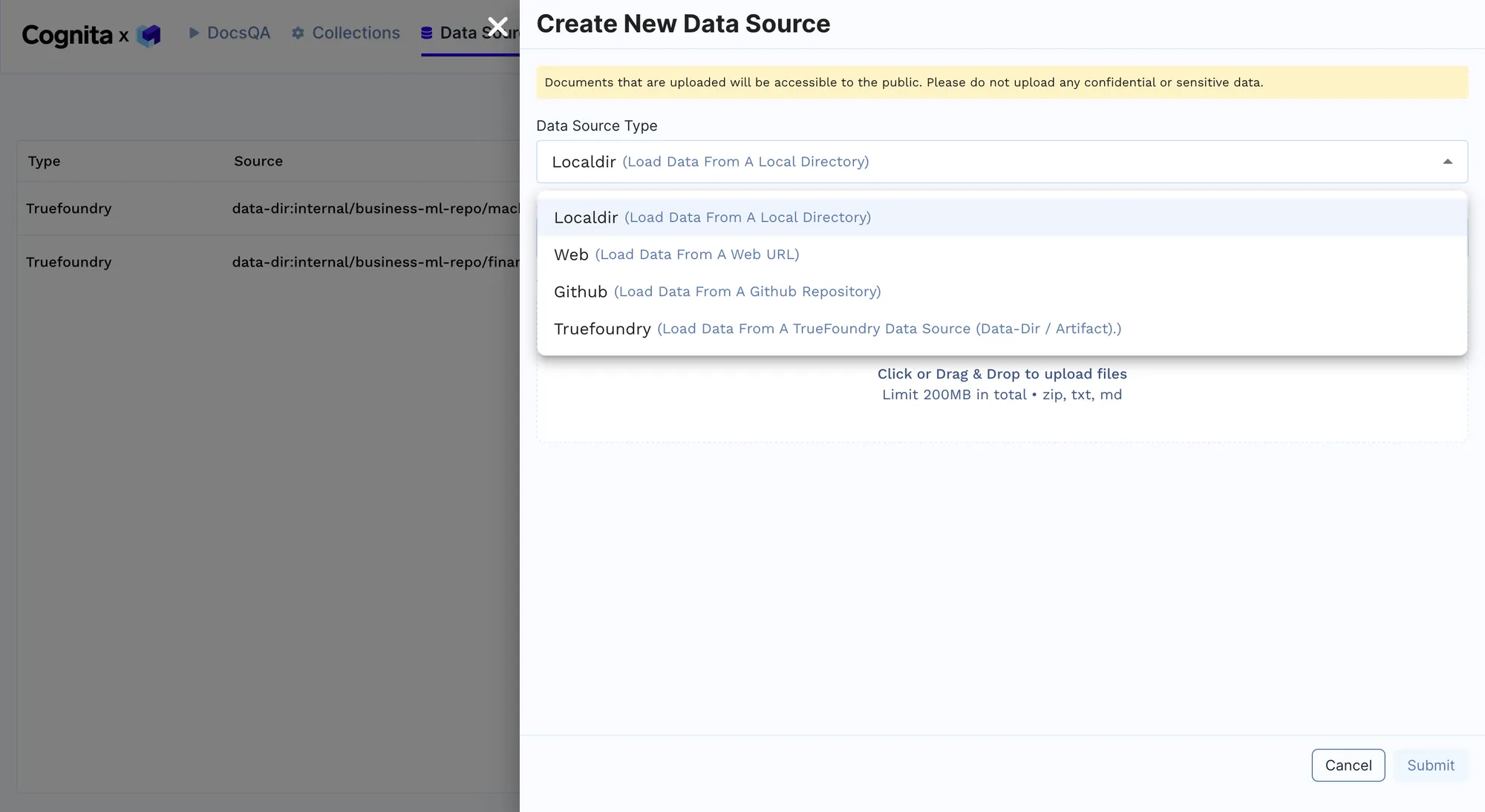
Chargement des données: Les chargeurs de données de Cognita sont utilisés pour importer des documents de support client et des données de requêtes historiques provenant de diverses sources, telles que des annuaires locaux ou un stockage dans le cloud. Cela peut être fait en ajoutant une nouvelle source de données à partir du point de terminaison RAG fourni après le déploiement, comme indiqué ci-dessous. Plusieurs sources de données peuvent être ajoutées ici selon les exigences pour améliorer les performances du modèle. Nous commencerons par ajouter un seul guide MacBook dans un premier temps, puis ajouterons d'autres données ultérieurement. Le lien vers tous les documents téléchargés se trouve ici.
Création d'une nouvelle source de données
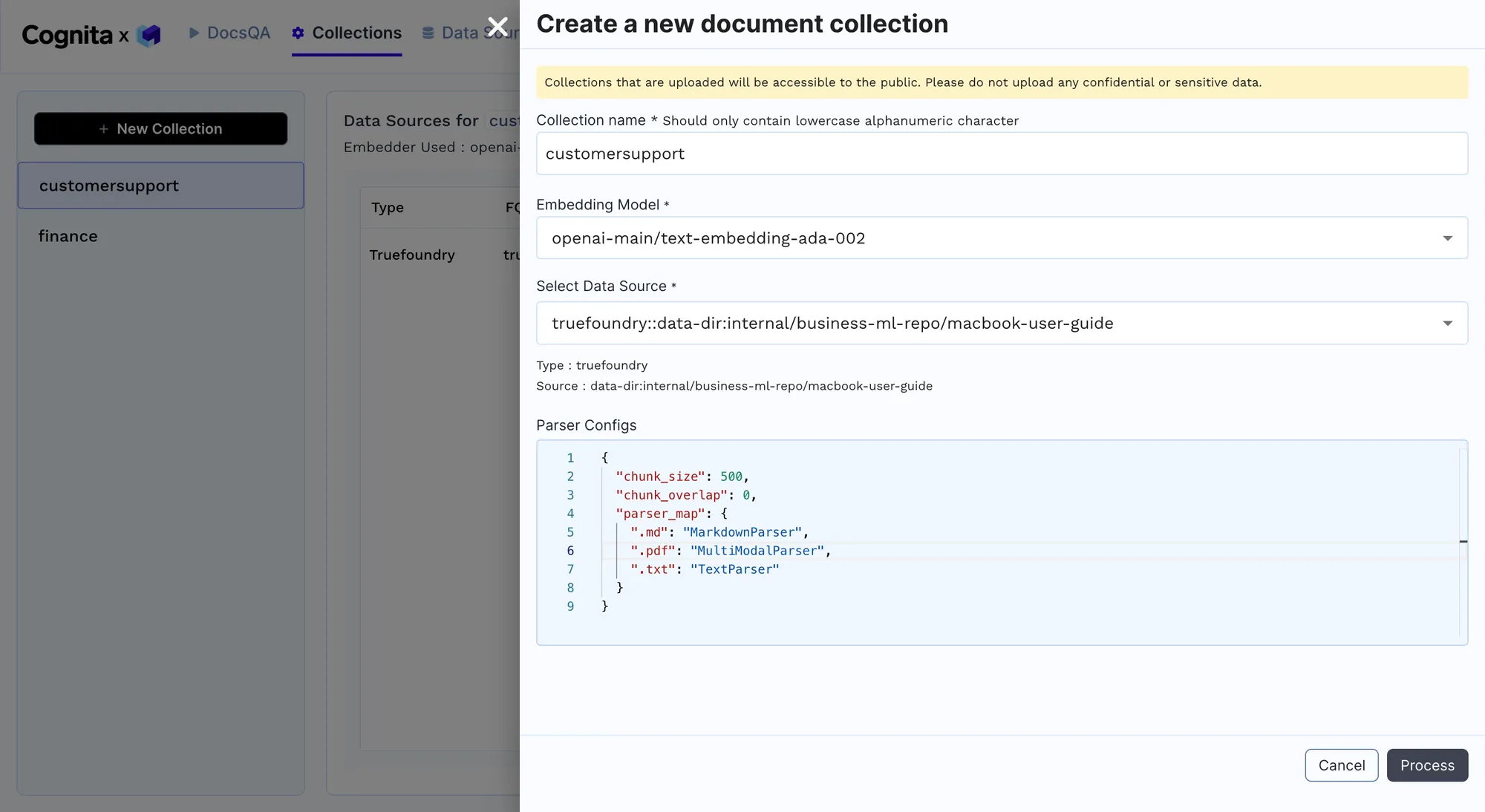
Analyse et intégration: analysez les documents dans un format uniforme et créez des intégrations à l'aide de modèles pré-entraînés pour faciliter la récupération rapide des informations pertinentes. Une nouvelle collection de documents provenant d'une source de données ajoutée à l'étape précédente peut être utilisée pour l'analyse et l'intégration. Nous essayons ici de résoudre un cas d'utilisation multimodal, dans lequel nous prenons un PDF, le convertissons en image et le décomposons en pages, et chaque page est convertie en images. Ensuite, une analyse spécifique est effectuée via des invites, où les informations sont collectées et stockées dans le VectorDB. Lorsqu'une question est posée, la question fait l'objet d'une recherche parmi toutes les informations stockées ; la page est récupérée, qui est ensuite envoyée au modèle de vision pour y répondre. Une fois que Procédé le bouton est cliqué, la collection est créée, un nouveau pod est créé, le travail d'indexation commence et les données sont ingérées dans les différents Qdrants. Remarque : cela peut prendre quelques minutes.
Analyse et intégration des données
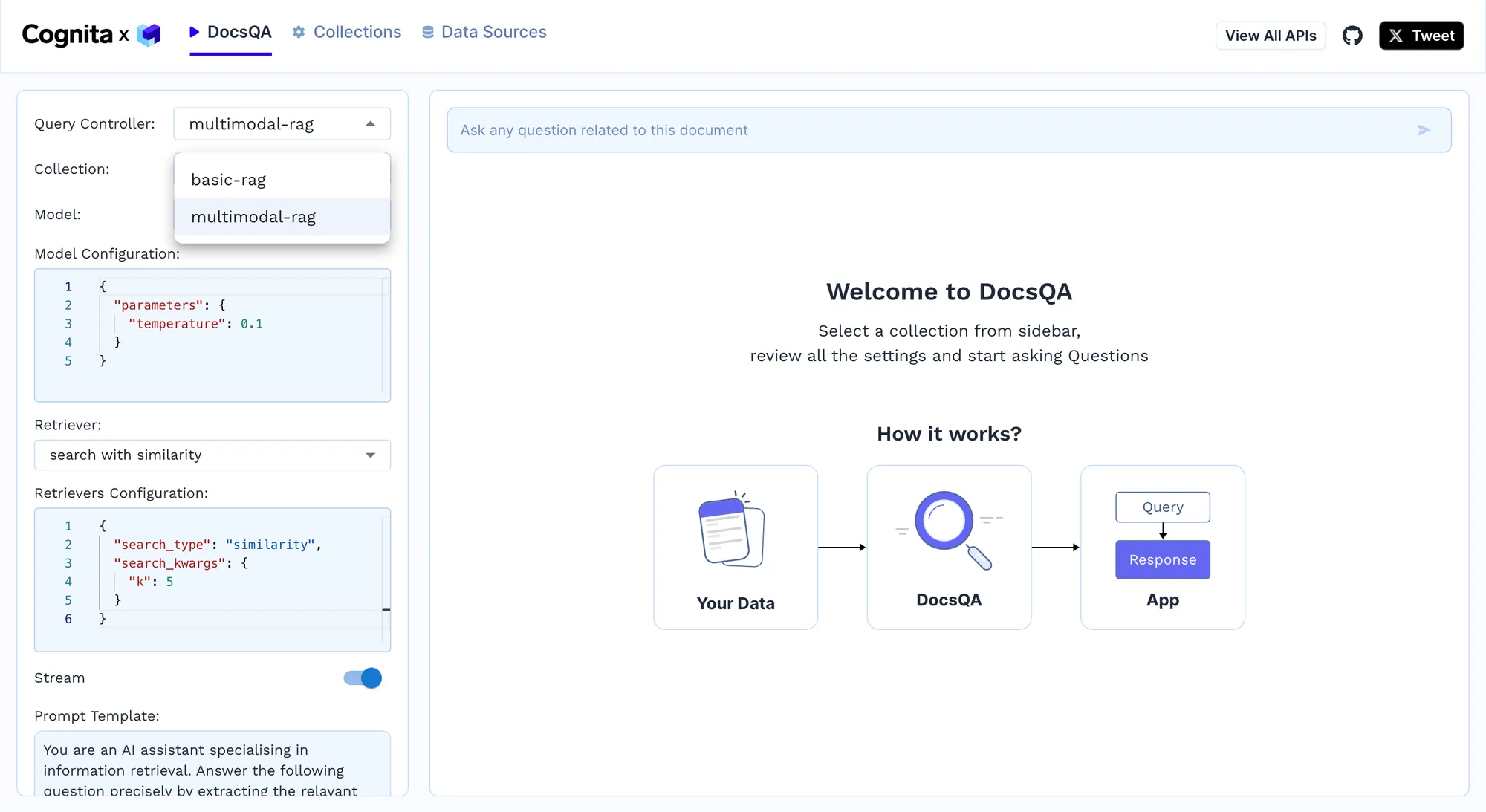
Gestion des requêtes : Implémentez le contrôleur de requêtes pour traiter les requêtes entrantes, rechercher les réponses potentielles et fournir les réponses les plus précises en temps réel. Par exemple, nous pouvons utiliser chiffon de base pour une analyse de texte simple. Toutefois, lorsqu'il s'agit de documents PDF, chiffon multimodal sera une meilleure option car elle utilise le modèle de vision, actuellement GPT-4, pour répondre aux questions sur PDF, qui sont analysées à l'aide de l'analyseur multimodal. Puisque nous utilisons un analyseur multimodal, le chiffon multimodal conduit à de meilleurs résultats.
Implémentation de différents contrôleurs de requêtes
Amélioration continue : Mettez continuellement à jour les modèles d'intégration et de reclassement en fonction des nouvelles données et des interactions avec les clients afin d'améliorer la précision et l'efficacité du système. Différents outils de récupération peuvent être utilisés dans la liste déroulante, comme indiqué ci-dessous. De plus, de nouveaux documents peuvent être ajoutés à la source de données et la tâche d'indexation peut être réexécutée pour améliorer le modèle. Par exemple, pour les requêtes utilisateur plus complexes, un requêtes multiples + reclassement + similarité le modèle peut être utilisé, ce qui nécessite k dans search_kwargs pour recherche de similarité, et le type_de recherche peut être une similitude ou un MMR ou seuil de score de similarité. Cela fonctionne en décomposant les requêtes complexes en requêtes plus simples, en trouvant les documents pertinents pour chacune d'entre elles, en les reclassant et en les envoyant à LLM. Les résultats sont ensuite cumulés et fournis. Nous pouvons jouer avec le modèle d'invite situé sous l'option Retriever pour obtenir des réponses plus riches.
Modifier les récupérateurs pour une amélioration continue
Supposons que vous souhaitiez redimensionner l'application RAG. Dans ce cas, nous pouvons le faire en ajoutant différentes sources de données pour lui permettre de répondre aux différentes demandes des clients et d'être une solution complète. Nous ajoutons d'autres documents, notamment des documents de support pour différents MacBook, iPad, iPhone, AirPods et watchOS, en ajoutant une nouvelle source de données et en la liant à la collection. Le RAG agit désormais en tant qu'agent de support client basé sur l'IA complet pour une large gamme de produits Apple. Certains documents sont également disponibles dans différentes langues afin de les redimensionner davantage en ajoutant un support multilingue.
Exemple de mise en œuvre
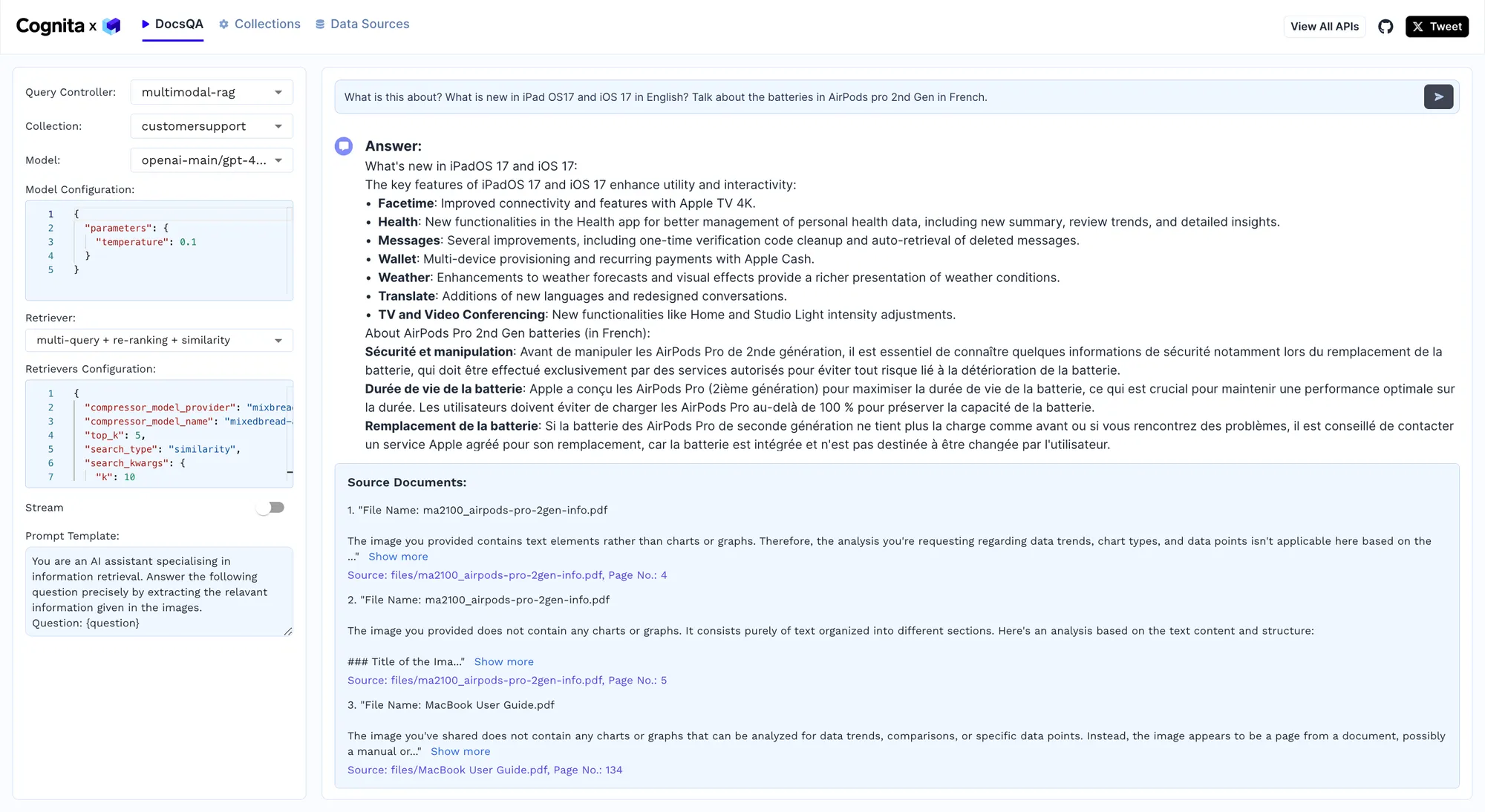
Nous allons maintenant tester le modèle en lui donnant une requête complexe, et les résultats sont présentés ci-dessous.
Cognita en action !
Lors d'un test du framework Cognita, le modèle a répondu avec succès à la question « Quelles sont les nouveautés d'iPadOS 17 et d'iOS 17 en anglais ? Parlez des batteries des AirPods Pro 2e génération en français », ce qui démontre leur capacité à répondre à des questions complexes et multilingues. Le modèle a utilisé la configuration multimodale en chiffon pour traiter et synthétiser les informations provenant de divers documents, fournissant une liste détaillée des nouvelles fonctionnalités d'iPadOS 17 et iOS 17, telles que les fonctionnalités améliorées de FaceTime et les améliorations apportées à l'application Health. De plus, il a fourni des informations précises sur les batteries des AirPods Pro 2e génération en français, concernant la sécurité, la durée de vie des batteries et les procédures de remplacement. Ce test souligne la capacité de Cognita à intégrer des modèles avancés de NLP et de vision, garantissant des réponses précises et contextuelles dans plusieurs langues, améliorant ainsi les opérations de support client grâce à une recherche d'informations de haute qualité en temps réel.
Avantages
Latence réduite et débit amélioré: En tirant parti de techniques d'intégration avancées et de bases de données vectorielles efficaces, Cognita garantit un traitement rapide des requêtes, réduisant les temps de réponse à des millisecondes. Cela est essentiel pour maintenir la satisfaction des clients dans les environnements à haute pression.
Apprentissage adaptatif et amélioration continue: L'intégration de boucles de rétroaction et la mise à jour continue des intégrations des modèles sur la base d'interactions en temps réel permettent au système d'apprendre et de s'améliorer, de réduire les taux d'erreur et d'améliorer la précision des réponses au fil du temps.
Optimisation des ressources et rentabilité: L'automatisation du traitement des requêtes réduit considérablement le besoin d'un personnel d'assistance humain important, ce qui se traduit par des économies de coûts substantielles. En outre, il permet aux agents humains de se concentrer sur des tâches plus complexes et de plus grande valeur, améliorant ainsi la qualité globale de l'assistance.
Évolutivité et flexibilité: L'architecture modulaire de Cognita garantit que le système peut rapidement évoluer horizontalement pour répondre à des volumes de requêtes croissants sans compromettre les performances. Cette polyvalence est essentielle pour les entreprises qui connaissent un développement rapide ou des pics saisonniers des besoins d'assistance.
Fidélisation et fidélisation accrues de la clientèle: En fournissant des réponses cohérentes, précises et rapides, Cognita améliore l'expérience client, ce qui se traduit par des taux de satisfaction plus élevés, une fidélité accrue et une réduction du taux de désabonnement. Cela se traduit directement par une amélioration de la valeur client sur le cycle de vie et des revenus commerciaux.
Améliorations supplémentaires apportées par les entreprises
Personnalisation avancée et profilage des utilisateurs : En intégrant le profilage des utilisateurs et des algorithmes de personnalisation avancés, les entreprises peuvent adapter les réponses en fonction des préférences individuelles des utilisateurs et des interactions passées. Cela peut être réalisé en analysant les données historiques et en intégrant un contexte spécifique à l'utilisateur dans les requêtes, améliorant ainsi la pertinence et la personnalisation des réponses.
Support multilingue : L'intégration de fonctionnalités multilingues permet aux entreprises de fournir une assistance dans plusieurs langues. Cela peut être mis en œuvre en intégrant des modules de détection de langue et de traduction dans Cognita, permettant ainsi une assistance fluide à une clientèle mondiale sans avoir besoin de ressources humaines supplémentaires.
Analyse des sentiments et intelligence émotionnelle : Les entreprises qui intègrent des modules d'analyse des sentiments et d'intelligence émotionnelle peuvent évaluer les sentiments des clients et adapter les réponses en conséquence. Cela implique une analyse en temps réel du ton et de l'attitude des clients, ce qui permet à l'IA de donner des réponses empathiques et appropriées, augmentant ainsi la satisfaction globale des clients.
Support proactif et analyse prédictive : L'analyse prédictive permet aux entreprises d'anticiper les exigences et les défis des clients avant qu'ils ne surviennent. En outre, en évaluant les modèles d'utilisation et les données historiques, Cognita peut lancer des interventions d'assistance proactives, telles que la fourniture de solutions aux problèmes fréquemment rencontrés ou l'information des clients sur des problèmes potentiels, améliorant ainsi l'expérience client et réduisant les demandes entrantes.
Intégration avec les systèmes CRM : L'intégration fluide avec les systèmes CRM peut fournir une vision globale des interactions avec les clients. En extrayant les données des plateformes CRM, Cognita peut proposer des réponses plus informées et contextuelles, garantissant ainsi la cohérence et la personnalisation des interactions avec les clients sur tous les points de contact.
Sécurité et confidentialité renforcées : La mise en œuvre de mesures de sécurité avancées garantit que les données des clients sont traitées en toute sécurité. Les entreprises peuvent intégrer Cognita à des solutions de stockage de données sécurisées et utiliser des protocoles de cryptage pour protéger les informations sensibles, garantir la conformité aux réglementations en matière de protection des données et préserver la confiance des clients.
Mises à jour dynamiques du contenu et de la base de connaissances : L'automatisation du processus de mise à jour des bases de connaissances garantit que le système a toujours accès aux informations les plus récentes. En mettant en place des pipelines automatisés pour ingérer et traiter de nouveaux contenus, Cognita peut apprendre en permanence à partir de données récentes, en tenant le système de support à jour avec les dernières informations et tendances.
Conclusion
L'architecture modulaire et les fonctionnalités avancées d'IA de Cognita constituent une solution robuste pour améliorer le support client. Il gère efficacement les requêtes complexes, traite divers types de données et fournit des réponses précises en temps réel. En intégrant des fonctionnalités telles que le support multilingue et l'analyse prédictive, Cognita améliore considérablement la satisfaction des clients et l'efficacité opérationnelle, ce qui en fait un outil précieux pour les systèmes de support modernes.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge

































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


