



July 20, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Le but de cet article est d'informer le lecteur sur le fonctionnement de la tarification des grands modèles linguistiques (LLM). Ceci est motivé par nos conversations avec de nombreuses entreprises utilisant des LLM à des fins commerciales. Au cours de ces conversations, nous nous sommes rendu compte que l'économie du LLM est souvent mal comprise, ce qui laisse une énorme marge d'optimisation.
Vous rendez-vous compte que le fait de la même tâche peut prendre 3 500$ avec un modèle ou 1 260 000$ avec un autre? Cela se fait au prix de la différence de performance, mais cela laisse une grande marge de manœuvre pour réfléchir au compromis entre les coûts et les performances. La tâche est-elle telle que je puisse utiliser quelque chose de moins cher ?
Nous avons constaté à maintes reprises que des entreprises surestimaient ou sous-estimaient leurs dépenses consacrées aux grands modèles linguistiques. Nous essaierons donc ici de comprendre le coût de fonctionnement de certains des modèles linguistiques les plus populaires et de comprendre comment fonctionne leur tarification.
ℹ️
Le but de ce blog n'est pas d'éduquer le lecteur sur les LLM ou leurs performances. Il s'agit d'un blog à forte intensité mathématique axé sur la compréhension de la tarification du LLM. Par souci de simplicité, nous ne comparerions pas les performances de ces modèles.
Le échantillon pour l'analyse des prixPour comprendre comment fonctionne la tarification des LLM, nous comparerions les coûts engagés pour la même tâche, c'est-à-dire pour résumer Wikipédia à la moitié de sa taille.
Nous utiliserions quelques approximations pour simplifier les calculs et les rendre facilement compréhensibles
❓
Jetons sont des sous-parties de mots qui ne dépendent pas précisément du début ou de la fin des mots. Il s'agit de l'unité dans laquelle les API OpenAI divisent l'entrée en jetons avant qu'elle ne soit traitée. Les jetons peuvent inclure des espaces de fin et même des sous-mots.
Pour cette tâche, nous supposons que chaque article est simplement compressé à la moitié de sa taille pour des raisons de simplicité. Par conséquent, les résultats que nous attendons seront les suivants :

Comparer ce que coûterait l'utilisation de différents modèles pour cette tâche
OpenAI et les autres API tierces facturent généralement en fonction de deux leviers ; si vous souhaitez déduire à l'aide de leurs API
Ce coût dépend du nombre de jetons (expliqué ci-dessus) transmis en tant que contexte/invite/instruction à l'API.
Son coût est basé sur le nombre de jetons que l'API renvoie en réponse.
Pour une tâche telle que la synthèse, étant donné que vous devez transmettre l'intégralité du document ou de l'extrait à résumer au modèle, le nombre de jetons qui font partie de l'invite peut devenir significatif, d'où le coût d'entrée.
Avec les modèles auto-hébergés, l'utilisateur doit gérer/approvisionner la machine nécessaire à l'exécution du modèle. Bien que cela puisse inclure le coût de gestion de ces ressources, la tarification est relativement facile à comprendre puisqu'elle est uniquement basée sur le coût de fonctionnement de la machine (généralement celui facturé par les fournisseurs de cloud, sauf si vous avez votre propre cluster sur site)
Coût du provisionnement de la machine requise pour exécuter/héberger le modèle. Étant donné que la plupart de ces modèles plus grands sont plus grands que ce qui peut être exécuté sur un ordinateur portable ou un seul appareil local, l'utilisation d'un fournisseur de cloud pour ces machines est la plus courante.
Les fournisseurs de cloud proposent ces instances, mais les utilisateurs peuvent être confrontés à des problèmes de disponibilité du GPU car ces modèles nécessitent un GPU.
Coûts des instances Google Cloud
Coûts des instances Microsoft Azure
Les fournisseurs de cloud fournissent leur capacité inutilisée à un coût 40 à 90 % inférieur à celui des instances à la demande
Coût = Non Nombre de jetons (pour 1 000 articles) X Nombre d'articles (en milliers) X Coût unitaire (pour 1 million de jetons)
Coût des intrants
1 000 (jetons/article) X 6 000 000 (articles) X 30$ (/Mn de jetons) = 180 000$
Coût de production
0,5 K (jetons/article) X 6 000 K (articles) X 60$ (/Mn de jetons) = 180 000$
Coût total
Coût d'entrée + coût de sortie
Coût d'entrée (/Mn de jetons) Coût de sortie (/Mn de jetons) 60$ à 120$
Coût = Non Nombre de jetons (pour 1 000 articles) X Nombre d'articles (en milliers) X Coût unitaire (pour 1 million de jetons)
Coût des intrants
1 000 (jetons/article) X 6 000 000 (articles) X 60$ (/Mn de jetons) = 360 000$
Coût de production
0,5 K (jetons/article) X 6 000 K (articles) X 120$ (/Mn de jetons) = 360 000$
Coût total
Coût d'entrée + coût de sortie
Coût = Nombre de jetons (pour 1 000 articles) X Nombre d'articles (en milliers) X Coût unitaire (pour 1 million de jetons)
Coût des intrants
1 000 (jetons/article) X 6 000 000 (articles) X 11$ (/Mn de jetons) = 66 000$
Coût de production
0,5 K (jetons/article) X 6 000 K (articles) X 60$ (/Mn de jetons) = 96 000$
Coût total
Coût d'entrée + coût de sortie
Coût = Non Nombre de jetons (pour 1 000 articles) X Nombre d'articles (en milliers) X Coût unitaire (pour 1 million de jetons)
Coût des intrants
1 000 (jetons/article) X 6 000 000 (articles) X 20$ (/Mn de jetons) = 120 000$
Coût de production
0,5 K (jetons/article) X 6 000 K (articles) X 20$ (/Mn de jetons) = 60 000$
Coût total
Coût d'entrée + coût de sortie
Coût = Non Nombre de jetons (pour 1 000 articles) X Nombre d'articles (en milliers) X Coût unitaire (pour 1 million de jetons)
Coût des intrants
1 000 (jetons/article) X 6 000 000 (articles) X 2$ (/Mn de jetons) = 12 000$
Coût de production
0,5 K (jetons/article) X 6 000 K (articles) X 60$ (/Mn de jetons) = 6 000$
Coût total
Coût d'entrée + coût de sortie
Coût de fonctionnement de la machine (/h pour Spot A100-80 Go) 10$
Coût = Nombre de jetons (pour 1 000 articles) X Nombre d'articles (en milliers) X Coût unitaire (pour 1 million de jetons)
Coût des intrants
1 000 (jetons/article) X 6 000 000 (articles) X 30$ (/Mn de jetons) = 180 000$
Coût de production
0,5 K (jetons/article) X 6 000 K (articles) X 60$ (/Mn de jetons) = 180 000$
Coût total
Coût d'entrée + coût de sortie
Dans la plupart des cas d'utilisation, les entreprises en ont besoin pour affiner des modèles spécifiques à leurs propres données et à des tâches particulières. De nombreuses entreprises ont indiqué que les modèles open source affinés étaient comparables, voire parfois meilleurs, que les API tierces comme OpenAI sur une tâche spécifique.

Coût total
Coût d'entrée + coût de sortie

Coût total
Coût d'entrée + coût de sortie

Coût total
Coût d'entrée + coût de sortie
Points à retenir de la tarification :
Nous utilisons le benchmark suivant pour analyser l'effet du réglage fin des modèles sur les performances des modèles. Il est intéressant de noter que :
Type de tâcheBest 6B/7B OOTB Model Few-ShotMoveLM 7B Zero-ShotGPT-3.5 Turbo Zero-ShotGPT-3.5 Turbo Few-ShotGPT-4 Zero-shotGPT-4 Few-ShotGPT-4 Few-ShotRevance - jeu de données interne0,330,930,840,840,920,95Extraction - sortie structurée pour les requêtes0.380,980,220.720.380.73 Raisonnement - déclenchement personnalisé0,620,930.870.880.90.88Classification - domaine de la requête de l'utilisateur0,210,790.60.730.70.76Extraction - sortie structurée à partir du typage d'entités0,830,870,90,890,890,89
Nous croyons en un état d'applications où les tâches les plus simples sont gérées par des LLM open source légers, tandis que les tâches les plus complexes ou celles qui nécessitent des fonctionnalités distinctes (par exemple, la recherche sur le Web, les appels d'API, etc.), qui ne sont proposées que par des LLM commerciaux à source fermée, peuvent leur être déléguées.
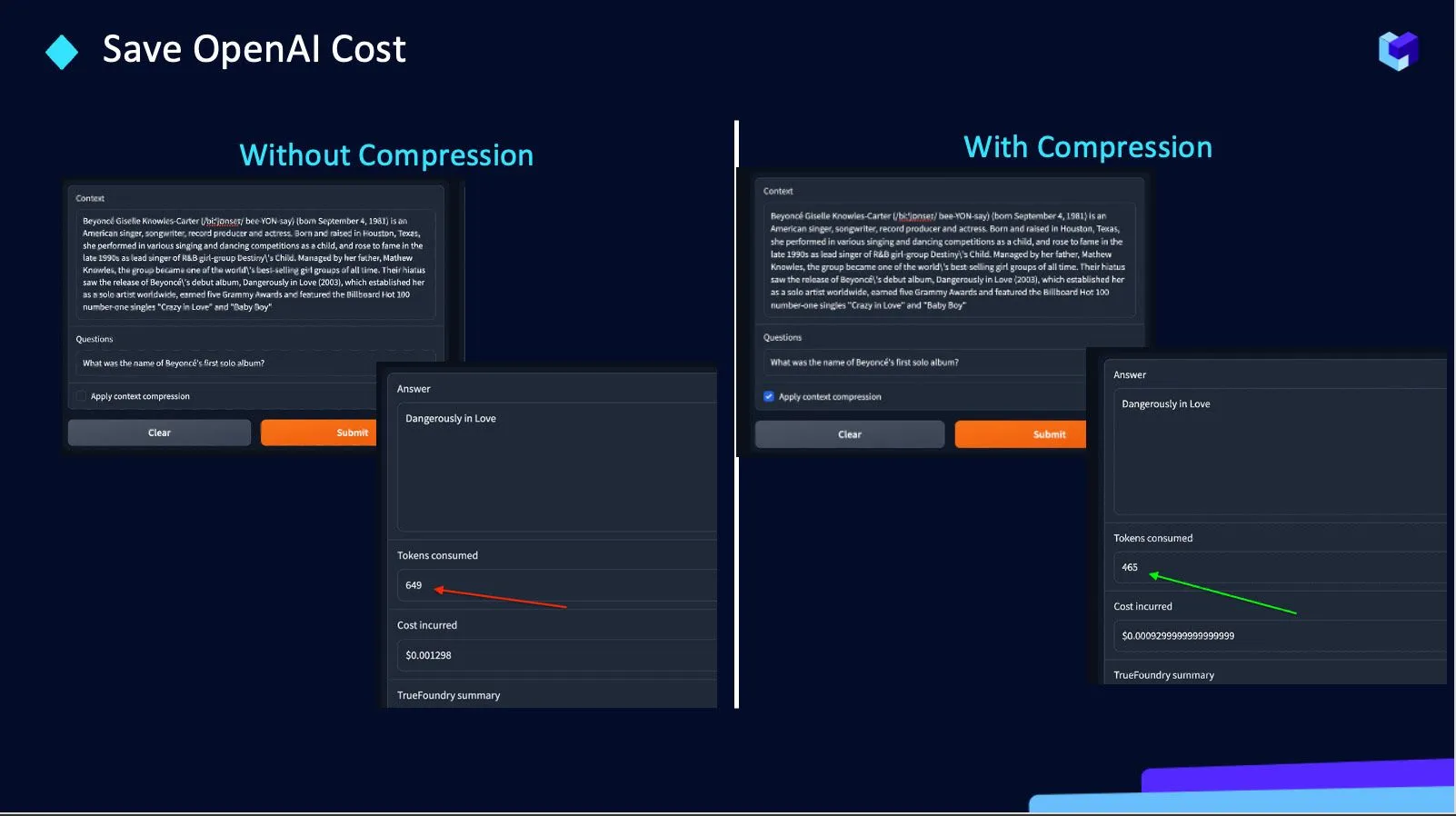
Nous contribuons à réduire le nombre de jetons envoyés aux API OpenAI. Pourquoi nous avons décidé de travailler là-dessus parce que :
D'où True Foundry construit une API de compression pour économisez le coût d'OpenAI d'environ 30 %.
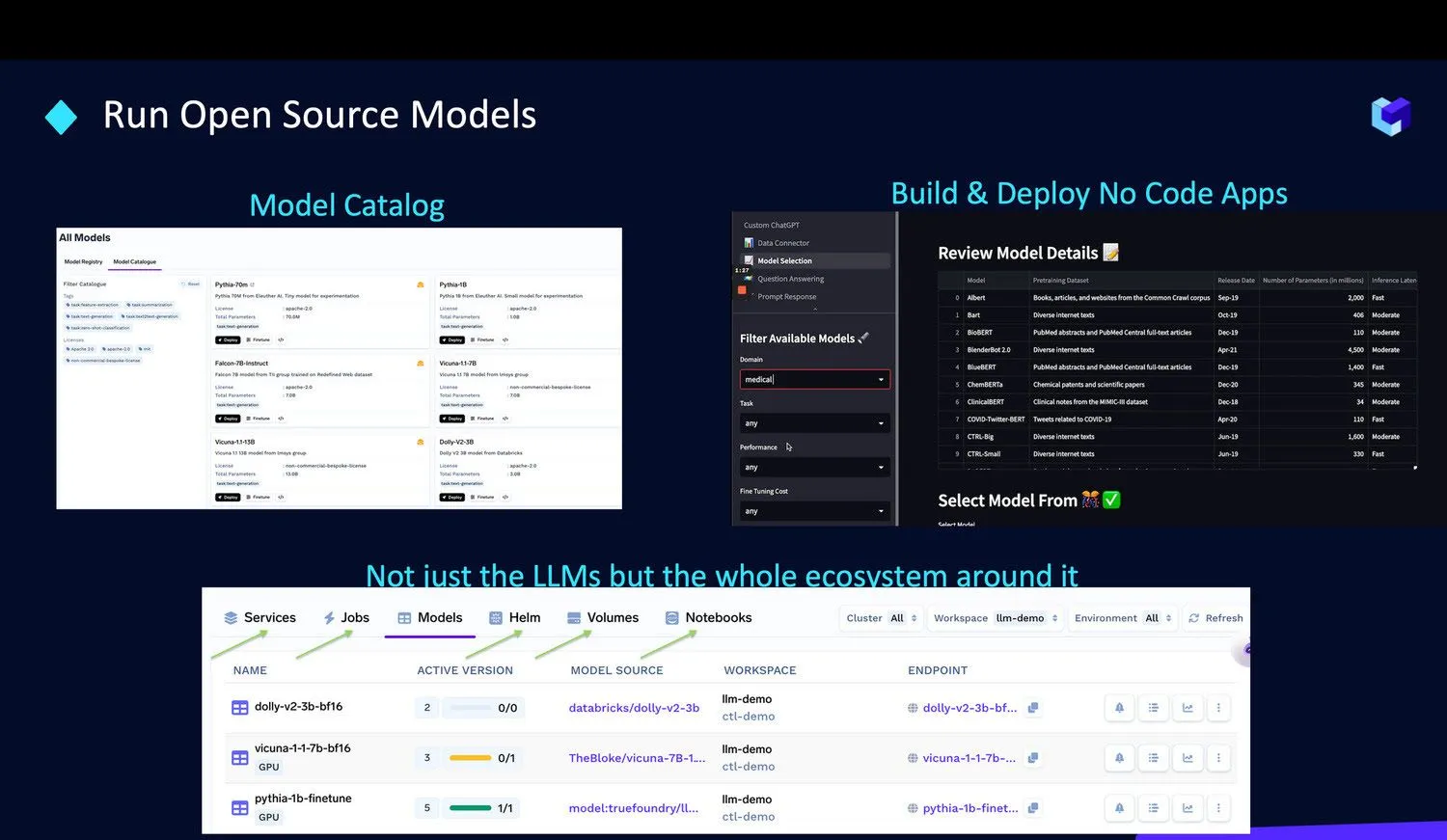
Nous simplifions l'exécution de ces modèles au sein de votre propre infrastructure grâce à nos offres suivantes :
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


