

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: May 29, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
L'adoption de l'IA par les entreprises a modifié la répartition des risques. Les décisions critiques ne se limitent plus à la sélection ou à la mise au point du modèle. Dans les systèmes de production, le risque est introduit et contrôlé ou amplifié au couche AI Gateway. C'est là que l'inférence est acheminée, les modèles sont sélectionnés, les agents exécutent les flux de travail, les outils sont invoqués et les données d'observabilité sont émises.
En conséquence, des concepts de longue date tels que résidence des données et souveraineté des données ne peuvent plus être considérés comme des problèmes d'infrastructure statiques. Dans les systèmes d'IA, ils sont propriétés d'exécution, imposée (ou violée) par la passerelle.
De nombreuses entreprises pensent avoir abordé la question de la gouvernance des données en déployant des modèles dans une région cloud spécifique. Cette hypothèse s'effondre une fois qu'AI Gateways introduit :
Compréhension souveraineté des données ou résidence des données dans le contexte de Passerelles IA est donc fondamental pour exécuter une IA conforme et de niveau production.
Les applications traditionnelles disposaient de chemins de données relativement prévisibles. Les demandes provenaient d'utilisateurs, de services ou de bases de données, souvent au sein d'une même région. Les passerelles IA modifient fondamentalement ce modèle.
Une passerelle IA peut, pour une seule demande :
Chacune de ces actions peut introduire déplacement ou accès implicite à des données entre régions, même lorsque l'application elle-même apparaît en local.
C'est pourquoi les passerelles AI deviennent plan de contrôle des données de facto.
Si les contraintes de résidence et de souveraineté ne sont pas appliquées à la porte d'entrée :
En d'autres termes, les défaillances de gouvernance des données dans les systèmes d'IA sont généralement des défaillances de passerelle, et non des échecs de modèles.
C'est aussi pourquoi des assurances génériques comme « nous déployons des modèles dans la région » sont insuffisants. Sans mise en œuvre au niveau de la passerelle, les entreprises ne peuvent garantir que :
Le reste de ce blog examine comment la résidence des données et la souveraineté des données diffèrent, pourquoi les passerelles IA doivent appliquer les deux, et comment des plateformes comme TrueFoundry conçoivent leurs passerelles pour rendre ces garanties applicables plutôt que ambitieuses.
Résidence des données définit où les données sont physiquement traitées et stockées.
Dans les systèmes d'IA, cette question trouve une réponse non pas uniquement par le modèle, mais par le Passerelle IA qui orchestre l'exécution.
Du point de vue d'AI Gateway, la résidence des données s'applique à :
Surtout, la résidence est imposée ou violée au moment de l'exécution.
Dans les systèmes d'IA, la résidence des données n'est pas imposée par un seul paramètre. Il est appliqué par le biais d'un ensemble de primitives d'exécution dans AI Gateway qui limitent collectivement les endroits où l'exécution peut avoir lieu.
Sur des plateformes comme TrueFoundry, ces primitives fonctionnent avant et pendant l'exécution de la requête, garantissant le maintien des garanties de résidence même en cas de tentatives, d'échecs et de routage dynamique.
Les principales primitives d'application sont les suivantes :
Points finaux du modèle à l'échelle de la région
Les modèles sont enregistrés et exposés à l'AI Gateway avec une affinité régionale explicite. La passerelle peut uniquement acheminer les demandes vers les points de terminaison du modèle qui appartiennent à la région autorisée. Cela empêche l'utilisation accidentelle de modèles hébergés globalement ou interrégionaux, même lorsque plusieurs modèles sont configurés pour la même charge de travail.
Pools de nouvelles tentatives et de basculements verrouillés par région
Les nouvelles tentatives et le repli sont l'une des sources les plus courantes de violations du droit de résidence silencieuse. Une passerelle IA tenant compte de la résidence limite la logique des nouvelles tentatives de telle sorte que :
Cela garantit que le comportement en matière de haute disponibilité ne l'emporte jamais sur l'intention de conformité.
Tables de routage tenant compte de la résidence
Les décisions de routage prises dans la passerelle sont évaluées par rapport aux contraintes régionales lors de l'exécution. Même lorsque le routage est régi par des règles (pour les coûts, les performances ou la sélection du modèle), la passerelle applique la résidence en tant que contrainte stricte, ce n'est pas une préférence.
Cela est particulièrement important dans les configurations multimodèles où différents modèles peuvent être disponibles dans différentes zones géographiques.
Exportateurs d'observabilité soumis à des contraintes de résidence
Les journaux d'inférence, les invites, les réponses et les traces contiennent souvent des données réglementées. Une passerelle IA tenant compte de la résidence garantit que :
Cela comble une lacune de conformité courante où l'inférence est locale mais pas les métadonnées.
Alors que la résidence des données répond où les données sont traitées, souveraineté des données réponses qui contrôle en dernier ressort les données et en vertu de quelle juridiction légale.
Pour AI Gateways, la souveraineté est déterminée par :
Une réalité cruciale mais souvent négligée est la suivante : les données peuvent résider dans un pays tout en étant souveraines d'un autre.
Les passerelles IA interagissent souvent avec :
Même si l'inférence se produit localement, la souveraineté peut être compromise si :
Pour les entreprises réglementées, la souveraineté est donc une question de contrôle architectural, pas de géographie.
Une passerelle d'intelligence artificielle que les entreprises ne contrôlent pas totalement ne peut garantir la souveraineté, quel que soit l'endroit où elle fonctionne.
Au niveau de la couche AI Gateway, la différence entre résidence des données et souveraineté des données devient visible sur le plan opérationnel. Les deux doivent être appliqués au moment de l'exécution, mais ils résolvent des risques différents.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Il s'agit de modèles de défaillance récurrents observés lorsque les passerelles IA sont évaluées sans tenir compte de la souveraineté.
Les entreprises déploient des modèles dans une région cloud locale et supposent que la conformité est gérée. En réalité, l'AI Gateway peut toujours :
Les passerelles réessayent souvent ou échouent automatiquement. Sans contraintes explicites :
Même si l'inférence est locale, les agents peuvent invoquer des outils via la passerelle qui :
Les invites, les réponses et les traces contiennent souvent des données réglementées.
Si l'AI Gateway exporte des données télémétriques en dehors des frontières approuvées, la souveraineté est compromise discrètement.
La plupart des plateformes d'IA considèrent la gouvernance des données comme problème de déploiement. TrueFoundry le considère comme un problème d'application de l'exécution.
À l'échelle de l'entreprise, la résidence et la souveraineté des données ne sont pas garanties par l'endroit où l'infrastructure est déployée, mais par comment l'exécution est contrôlée. Dans les systèmes d'IA modernes, où les demandes sont acheminées dynamiquement entre les modèles, les agents invoquent des outils et les pipelines d'observabilité exportent des métadonnées, la seule couche présentant un contexte suffisant pour appliquer correctement la gouvernance est la Passerelle IA.
TrueFoundry est conçu selon ce principe.
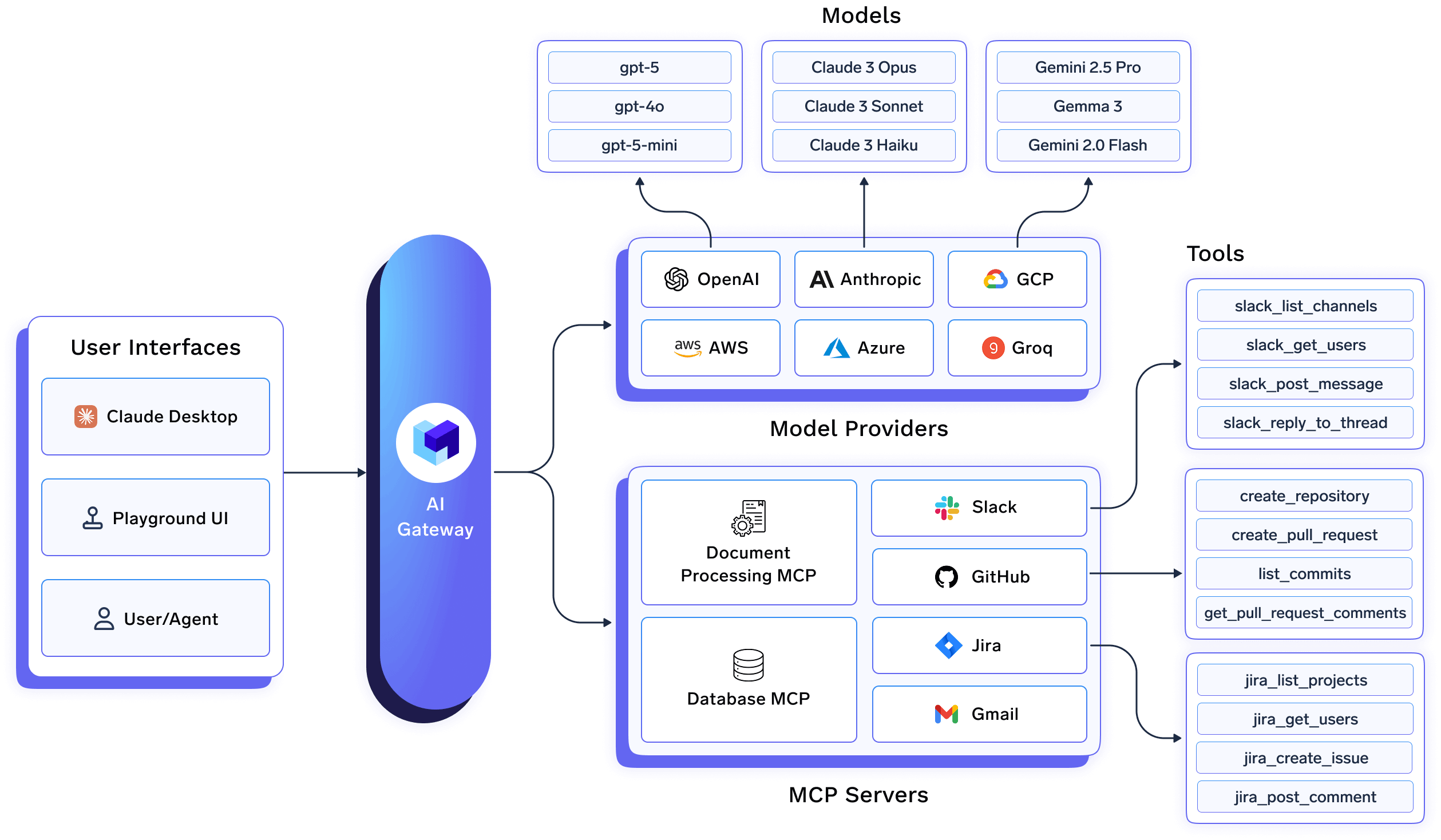
Dans True Foundry, l'AI Gateway n'est pas un proxy léger devant les modèles. Il s'agit d'un plan de contrôle qui se trouve au point de convergence de :
Comme chaque demande passe par cette couche, TrueFoundry peut appliquer à la fois la résidence et la souveraineté en tant que politiques d'exécution de premier ordre, et non des garanties de meilleur effort.
Cette distinction est importante.
TrueFoundry Passerelle IA impose la résidence en chemins d'exécution contraignants, sans recourir à une sélection statique de régions.
Concrètement, cela signifie :
Si une demande ne peut pas être satisfaite dans les limites de résidence, elle échoue à être clôturée au lieu d'être acheminée silencieusement ailleurs.
Cela permet d'éliminer l'un des problèmes de conformité les plus courants dans les systèmes d'IA : exécution entre régions pendant les chemins d'exception.
La souveraineté des données est fondamentalement une question qui contrôle l'accès, not where compute runs.
TrueFoundry enables sovereignty by ensuring enterprises retain control over:
Because the gateway is under the enterprise’s control, sovereignty does not depend on:
This is a critical difference from hosted AI services where inference may be local, but control is not.
A key advantage of TrueFoundry’s approach is consistency.Residency and sovereignty policies are enforced uniformly across:
This prevents a common failure mode where:
By treating the AI Gateway as a shared enforcement point, TrueFoundry ensures that governance is system-wide, not piecemeal.
In modern AI systems, data governance is no longer defined by where infrastructure is deployed, it is defined by how execution is controlled at runtime. As models, agents, and tools interact dynamically, both data residency and data sovereignty must be enforced centrally to remain meaningful.
Residency determines where data is processed. Sovereignty determines who controls it. Solving for one without the other leaves gaps especially in AI Gateways that handle routing, failover, agent workflows, and observability.
Because every inference request and tool invocation passes through them, AI Gateways are the only place where these guarantees can be enforced consistently. TrueFoundry treats the AI Gateway as a governance control plane, making residency and sovereignty enforceable system properties, not assumptions.
That distinction is what turns AI from an experimental capability into a production-grade, compliant system.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


