


July 20, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Dans cet article, nous comparons les performances de Mistral-7B du point de vue de la latence, du coût et des demandes par seconde. Cela nous aidera à évaluer s'il peut s'agir d'un bon choix en fonction des besoins de l'entreprise. Veuillez noter que nous n'abordons pas les performances qualitatives dans cet article. Il existe différentes méthodes pour comparer les LLM, que vous pouvez trouver ici.
Dans ce blog, nous avons comparé Mistral-7B-Instruct-v0.1 modèle de Mistralai. Le LLM Mistral-7B-Instruct-v0.1 est une version affinée des instructions Mistral-7B-v0.1 modèle de texte génératif (comportant 7 milliards de paramètres) utilisant une variété d'ensembles de données de conversation accessibles au public.
Les principaux facteurs sur lesquels nous avons effectué des analyses comparatives sont les suivants :
Type de processeur graphique :
Longueur du message :
Pour l'analyse comparative, nous avons utilisé Locust, un outil de test de charge open source. Locust fonctionne en créant des utilisateurs/travailleurs pour envoyer des demandes en parallèle. Au début de chaque test, nous pouvons définir Nombre d'utilisateurs et Taux d'apparition. Voici le Nombre d'utilisateurs signifie le nombre maximum d'utilisateurs pouvant être généré/exécuter simultanément, alors que Taux d'apparition indique le nombre d'utilisateurs qui seront générés par seconde.
Lors de chaque test d'analyse comparative d'une configuration de déploiement, nous sommes partis de 1 utilisateur et a continué à augmenter le Nombre d'utilisateurs progressivement jusqu'à ce que nous constations une augmentation constante du RPS. Au cours du test, nous avons également tracé temps de réponse (en ms) et nombre total de demandes par seconde.
Dans chacune des 2 configurations de déploiement, nous avons utilisé le Serveur modèle vLLM ayant version=0.2.0-d849de0.
Latence, RPS et coût
Nous calculons la meilleure latence sur la base de l'envoi d'une seule demande à la fois. Pour augmenter le débit, nous envoyons les demandes en parallèle au LLM. Le débit maximal est le cas lorsque le modèle est capable de traiter les demandes d'entrée sans détérioration significative de la latence.
Jetons par seconde
Les LLM traitent les jetons d'entrée et les génèrent différemment. C'est pourquoi nous avons calculé différemment le taux de traitement des jetons d'entrée et des jetons de sortie.

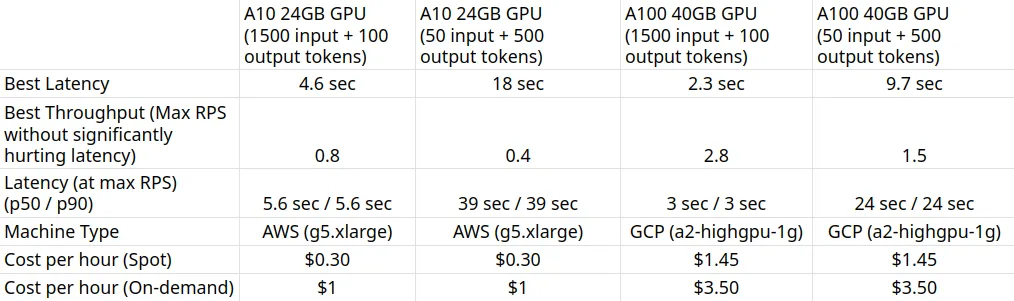
GPU A10 24 Go (1500 jetons d'entrée + 100 jetons de sortie)
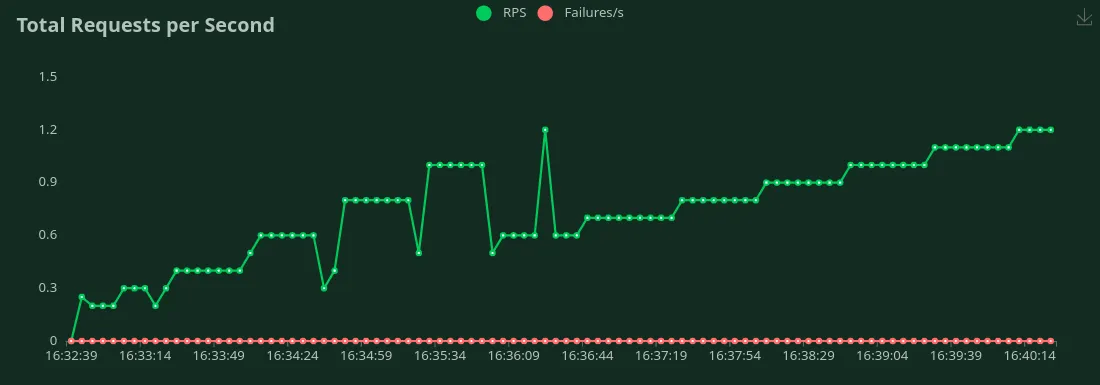
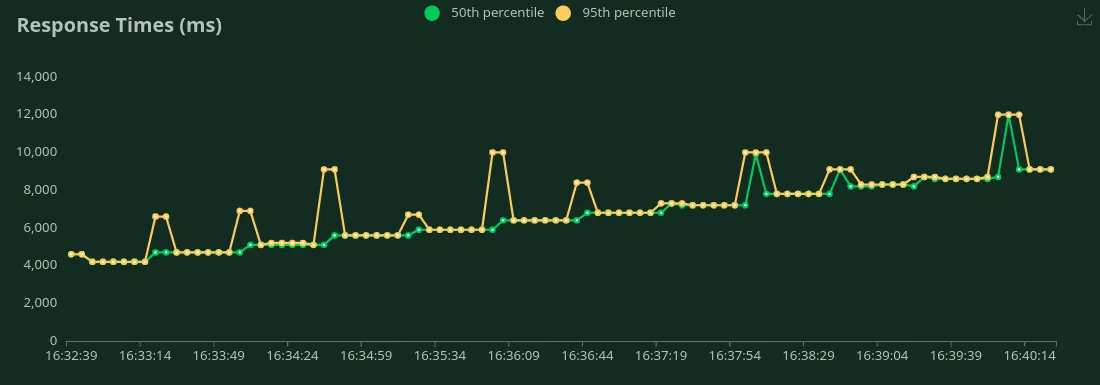
Nous pouvons observer dans les graphiques ci-dessus que Meilleur temps de réponse (pour 1 utilisateur) est 4,6 secondes. Nous pouvons augmenter le nombre d'utilisateurs pour générer plus de trafic vers le modèle. Nous pouvons voir le débit augmenter jusqu'à 0,8 RPS sans baisse significative de la latence. Au-delà 0,8 RPS, la latence augmente considérablement, ce qui signifie que les demandes sont mises en file d'attente.
GPU A10 24 Go (50 jetons d'entrée + 500 jetons de sortie)
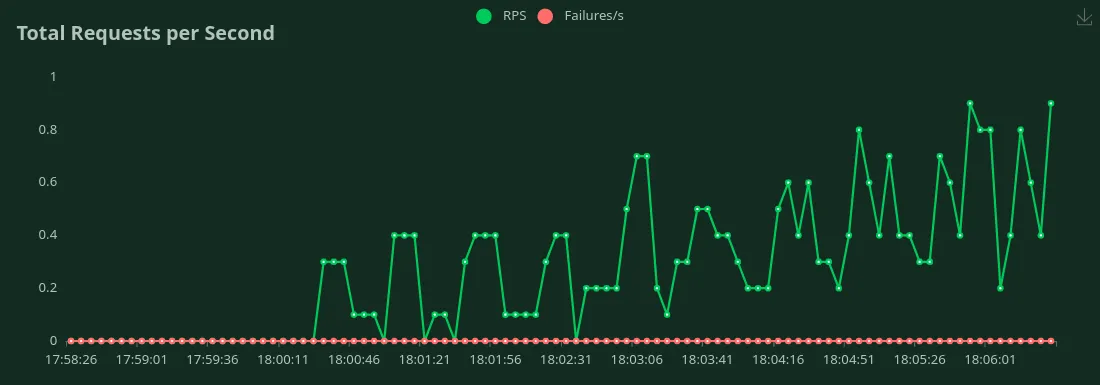
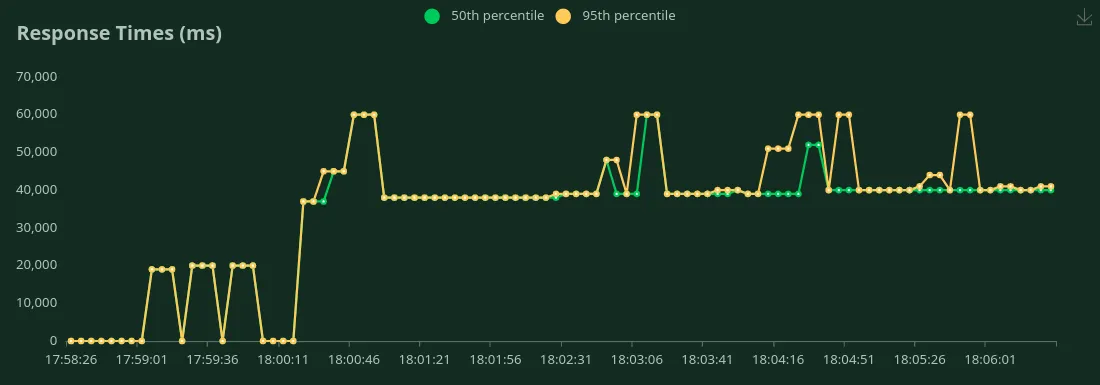
Nous pouvons observer dans les graphiques ci-dessus que Meilleur temps de réponse (pour 1 utilisateur) est 18 secondes. Nous pouvons augmenter le nombre d'utilisateurs pour générer plus de trafic vers le modèle. Nous pouvons voir le débit augmenter jusqu'à 0,4RPS sans baisse significative de la latence. Au-delà 0,4 RPS, la latence augmente considérablement, ce qui signifie que les demandes sont mises en file d'attente.
GPU A100 de 40 Go (1500 jetons d'entrée + 100 jetons de sortie)
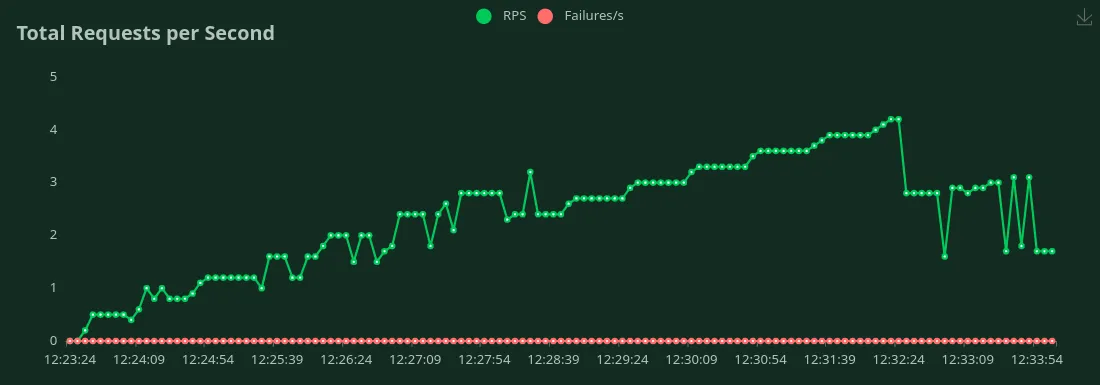
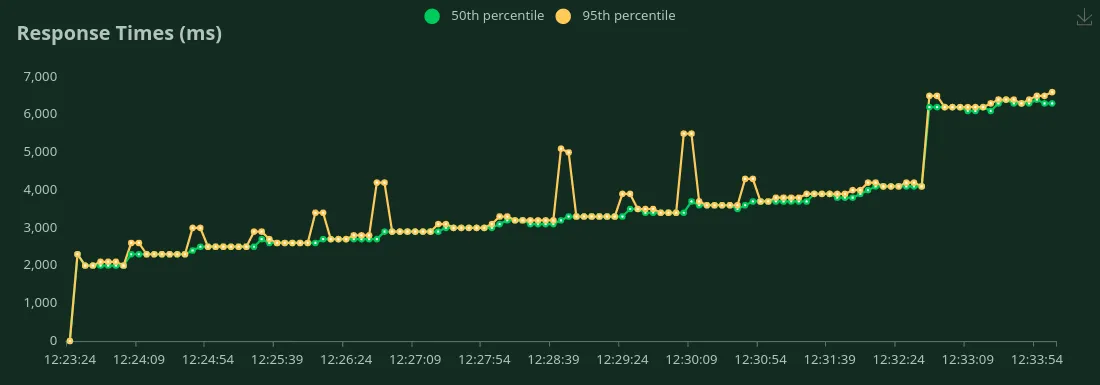
Nous pouvons observer dans les graphiques ci-dessus que Meilleur temps de réponse (pour 1 utilisateur) est 2,3 secondes. Nous pouvons augmenter le nombre d'utilisateurs pour générer plus de trafic vers le modèle. Nous pouvons voir le débit augmenter jusqu'à 2,8 RPS sans baisse significative de la latence. Au-delà 2,8 RPS, la latence augmente considérablement, ce qui signifie que les demandes sont mises en file d'attente.
GPU A100 de 40 Go (50 jetons d'entrée + 500 jetons de sortie)
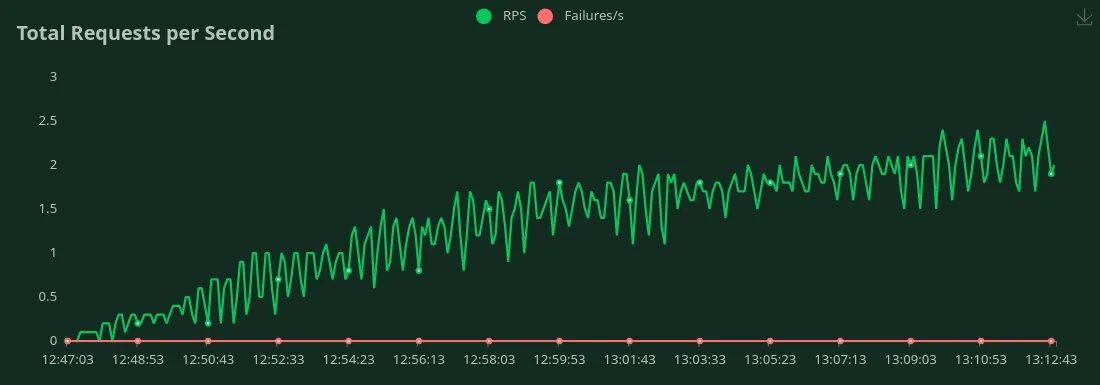
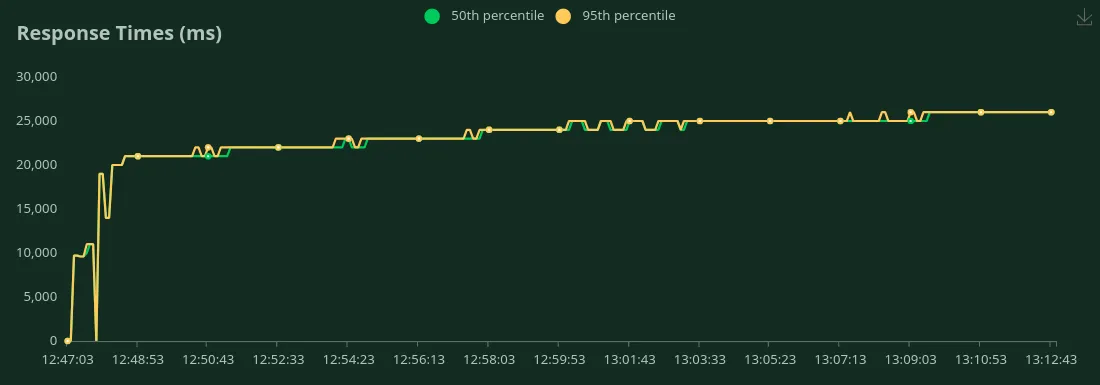
Nous pouvons observer dans les graphiques ci-dessus que Meilleur temps de réponse (pour 1 utilisateur) est 9,7 secondes. Nous pouvons augmenter le nombre d'utilisateurs pour générer plus de trafic vers le modèle. Nous pouvons voir le débit augmenter jusqu'à 1,5 RPS sans baisse significative de la latence. Au-delà 1,5 RPS, la latence augmente considérablement, ce qui signifie que les demandes sont mises en file d'attente.
J'espère que cela vous sera utile pour décider si Mistral-7B-Instruct convient à votre cas d'utilisation et aux coûts que vous pouvez vous attendre à encourir lors de l'hébergement de Mistral-7B-Instrut.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


