

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
La prolifération des grands modèles linguistiques (LLM) et des systèmes agentiques marque un tournant pour la technologie d'entreprise. Le potentiel d'innovation est vaste, mais les pièges le sont tout autant. Dans de nombreuses organisations, l'adoption précoce a été chaotique : fragmentée, non gérée et peu sécurisée. Chaque équipe établit ses propres connexions avec différents fournisseurs de modèles, ce qui se traduit par des expériences cloisonnées sans supervision centralisée, sans contrôle des coûts ni normes de sécurité.
Pour passer de cette expérimentation ponctuelle à une stratégie d'IA cohérente à l'échelle de l'entreprise, nous avons besoin d'un paradigme architectural délibéré, qui intègre la sécurité, la gouvernance et l'évolutivité dès le premier jour.
Une pile d'applications agentiques idéale dans l'environnement actuel doit fournir :
Développement rapide d'applications — l'exécution fédérée à faible latence sur des agents et des environnements hétérogènes réduit le délai de rentabilisation (TTV), permettant aux équipes de fournir rapidement des fonctionnalités prêtes pour la production sans centraliser toutes les données ou tous les calculs.
Flexibilité à l'épreuve du temps — une pile modulaire et interopérable capable de s'adapter aux modèles, protocoles et modèles d'agents émergents au fur et à mesure de l'évolution du paysage de l'IA.
Sécurité et conformité par défaut — Masquage des informations personnelles, application des règles et auditabilité complète.
Opérations déterministes sur des systèmes non déterministes — des garde-fous, des cadres d'évaluation et des voies de retour en arrière lorsque les résultats dérivent.
Gouvernance des coûts avec une granularité symbolique — budgets, rétrofacturation/rétrofacturation et limites d'utilisation.
Fiabilité et portabilité — basculement multimodèle, déploiement hybride/sur site et absence de dépendance vis-à-vis d'un fournisseur via des interfaces indépendantes des fournisseurs, des artefacts exportables et des plans de migration replay-to-switch.
Observabilité approfondie — traces, métriques au niveau des jetons (TTFT, TPS), taux d'accès au cache et tendances d'utilisation.
Capacités composables — des modèles, des outils et des agents connectés via des instructions, et non un code de colle fragile.
Vélocité avec contrôle — CI/CD pour les modèles, les agents et les outils ; déploiements par étapes avec Canary ou A/B testing.
Et nous devons concevoir en tenant compte des contraintes du monde réel, telles que :
C'est là que l'architecture fait la différence entre une démonstration inspirante et un système de production. Le plan doit comprendre quatre couches critiques : modèles, serveurs MCP, agents et invites.
1. Les modèles : au service de l'intelligence de base
Au cœur de toute application Gen-AI se trouve le modèle lui-même, le moteur de raisonnement de votre système. Le défi ne consiste pas simplement à choisir le « meilleur » modèle ; il s'agit de concevoir pour un monde où les modèles sont nombreux, en constante évolution et adaptés à des objectifs différents.
Une pile solide traite les modèles comme des actifs logiciels classiques : ils sont versionnés, suivis pour détecter les modifications apportées aux données et au code, et déplacés au cours du développement, de la préparation et de la production. Le routage doit également tenir compte des coûts et des performances. Parfois, un modèle plus petit et moins cher est le meilleur choix pour une tâche spécifique que de tout exécuter sur un modèle volumineux et coûteux.
Le piège dans lequel de nombreuses personnes tombent est l'étalement des modèles : trop de modèles non suivis, des mises à niveau opaques et aucune trajectoire de retour en arrière lorsque les performances diminuent. L'architecture est ici synonyme de discipline, c'est-à-dire de traiter les modèles avec la même rigueur que le code d'application de base.
2. Serveurs MCP : fonctionnalités de standardisation
Si les modèles sont le cerveau, les serveurs MCP (Model Context Protocol) sont la boîte à outils. Ils donnent à vos agents un accès standardisé et adapté aux besoins de l'entreprise à des systèmes tels que Jira, GitHub, Postgres ou à des API propriétaires.
Plutôt que des intégrations personnalisées par équipe, chacune présentant ses propres particularités, failles de sécurité et logique dupliquée, un seul serveur MCP certifié par système peut être réutilisé dans toute l'entreprise. Les E/S typées, l'authentification et les quotas deviennent cohérents, prévisibles et sécurisés.
Lorsque les équipes sautent cette étape, le chaos s'ensuit : politiques de sécurité incohérentes, travail redondant et intégrations fragiles qui ne peuvent être partagées ou gérées. Les serveurs MCP rendent les fonctionnalités composables et non accidentelles.
3. Agents — La main-d'œuvre numérique
Les agents sont l'endroit où les modèles deviennent opérationnels. Il ne s'agit pas simplement de pipelines : ce sont les contreparties numériques des employés humains, capables de prendre des mesures, de coordonner des tâches et d'utiliser des outils.
Une bonne conception des agents implique de donner à chacun une identité, des autorisations basées sur le moindre privilège et un cycle de vie clair entre le bac à sable et la production. Ils doivent être orchestrés, capables de collaborer entre plusieurs agents et portables dans tous les environnements.
Le risque opérationnel le plus important est l'accès non contrôlé : informations d'identification intégrées dans les couches de l'interface utilisateur, outils accessibles sans limites, absence de propriété ni de SLA. Les agents bien conçus emportent leurs informations d'identification et leurs champs d'application sur eux, sans être liés à l'endroit où ils sont invoqués.
4. Prompts — L'interface opérationnelle
Les instructions sont la façon dont nous indiquons aux modèles et aux agents ce qu'ils doivent faire. Il ne s'agit pas simplement de texte brut, il peut s'agir de modèles structurés, inclure des étapes d'évaluation et intégrer des contrôles de politique.
Dans une configuration solide, les instructions sont traitées comme du code : elles sont contrôlées par version, testées et protégées contre les injections rapides ou les modifications involontaires. En utilisant mise en cache sémantique peut économiser du temps et de l'argent en réutilisant les réponses pour des requêtes similaires au lieu de recommencer l'ensemble du processus.
Si vous ne gérez pas correctement les invites, vous risquez de rencontrer des problèmes de sécurité, de divulguer des données sensibles ou de voir vos invites évoluer lentement au fil du temps comme vous ne l'aviez pas prévu. Une bonne gestion garantit un comportement cohérent, sûr et fiable.
Lorsque les couches principales (modèles, serveurs MCP, agents et invites) sont conçues et gérées avec soin, le système devient plus fiable, plus évolutif et plus facile à entretenir. Mais dans les grandes organisations, des problèmes se posent souvent dans la manière dont toutes ces parties sont coordonnées, et pas seulement dans les parties elles-mêmes.
Les registres centralisés constituent le tissu conjonctif de la pile Gen-AI : le mémoire institutionnelle qui permet de détecter tous les composants, de les rendre conformes et de les rendre interopérables. Sans elles, vous risquez de retomber dans le chaos que cette architecture était censée éviter : travail en double, failles de sécurité et dérive invisible par rapport aux normes.
Une couche de registre robuste fournit :
En pratique, cette couche couvre plusieurs registres spécialisés :
Le système d'enregistrement de vos modèles : suivi versions, lignée (données, code, métriques), état du déploiement (dev/shadow/prod) et qui peut promouvoir ou utiliser un modèle. Il est connecté aux pipelines CI/CD afin que les nouvelles versions soient enregistrées automatiquement et puissent être déployées en toute sécurité via Canary ou des tests A/B. Au-delà de la découvrabilité, elle impose de la discipline : pas de « modèles mystères » en production, pas de modifications non suivies.
Le catalogue de outils certifiés à la disposition des agents, documentant leurs fonctions, leurs arguments et leurs schémas. Il code également autorisations d'utilisation—tous les agents ne devraient pas avoir accès à vos systèmes financiers ou à vos bases de données sensibles. Construit une fois, un serveur MCP peut être réutilisé par les équipes, la passerelle imposant un contrôle d'accès basé sur les rôles au niveau de l'outil.
Un répertoire de vos main-d'œuvre numérique—suivi de l'identité (UUID), du propriétaire, de l'objectif, des compétences, des modèles/outils autorisés et des informations d'identification de chaque agent. Il enregistre le cycle de vie complet, de la création à la suppression, et garantit que l'accès au moindre privilège est appliqué en temps réel à la passerelle. Cela permet d'éviter le mode de défaillance courant des agents qui conservent des privilèges excessifs ou obsolètes.
Un référentiel versionné des politiques de sécurité des entrées/sorties, couvrant Masquage des informations d'identification personnelle, détection rapide des injections, limites topiques, filtres de toxicité, et vérification des faits règles. Les politiques sont gérées sous forme de code, ce qui signifie qu'elles peuvent être déployées de manière incrémentielle via des outils canaris ou des tests A/B. Les politiques groupées (par exemple, « Chatbot conforme à la norme HIPAA ») peuvent être appliquées de manière cohérente entre les modèles, les agents et les outils.
Les registres nous fournissent l'échafaudage de la mémoire et de la gouvernance. Mais sur le papier, la gouvernance ne signifie rien si elle n'est pas appliquée au moment de l'exécution—où les invites sont envoyées, les jetons sont consommés et les réponses sont délivrées.
Même avec les bons composants et des registres bien gérés, un système d'IA moderne ne fonctionne pas en vase clos. En production, le véritable test n'est pas de savoir si votre architecture est bonne sur le papier, mais de savoir si elle continue à fonctionner malgré des conditions de défaillance, une demande variable et des coûts imprévisibles.
C'est là que les « nuances opérationnelles » entrent en jeu. Il ne s'agit pas de composants autonomes, mais plutôt de modèles transversaux qui ajoutent durabilité, efficacité et réactivité à l'ensemble de la pile.
Modèles de haute disponibilité
Dans un système d'IA en direct, l'échec n'est pas une possibilité, c'est une certitude. Les modèles tomberont en panne, les terminaux changeront et les réseaux se comporteront mal. Le travail d'un architecte consiste à s'assurer que ces événements ne se traduisent pas par des pannes pour l'utilisateur.
Verrouillage est évité par la pratique et non par la promesse. Traitez la sortie comme une discipline d'exécution, et non comme un projet du dernier kilomètre.
Passerelle indépendante du fournisseur — normalisez les schémas de demande/réponse et les balises de capacité afin que les applications ne soient jamais liées au SDK d'un fournisseur.
Replay-to-Switch — reportez régulièrement une tranche représentative des traces de production à un autre fournisseur ou à un modèle auto-hébergé ; suivez les deltas en termes de latence, de coût et de qualité pour garder la porte d'évacuation au chaud.
Artefacts ouverts — stockez les invites, les traces, les évaluations, les intégrations et le réglage des ensembles de données dans des formats exportables ; maintenez les index vectoriels reconstructibles à partir de la source.
Matrice de compatibilité — tenez à jour un tableau de bord fournisseur/modèle (latence/coût/qualité/fonctionnalités) afin que les politiques de routage restent axées sur les données.
Contrats et droits relatifs aux données — préférez les termes qui autorisent le remplacement du poids et le réentraînement ; suivez la lignée des ensembles de données dans le registre des modèles afin que la sortie ne soit pas bloquée en fonction de la provenance.
Liste de contrôle de sortie — clés/configurations découplées du code, points de terminaison secondaires pré-vérifiés, ensemble de données de replay minimal défini, lacunes connues documentées.
Les charges de travail liées à l'IA sont intrinsèquement variables et, sans gestion active, les coûts peuvent monter en flèche. Le défi consiste à appliquer la discipline en matière de coûts sans créer de goulots d'étranglement qui frustrent les développeurs ou les utilisateurs.
Ces nuances garantissent le bon fonctionnement du système en cas de problème. Ils contribuent également à maîtriser les coûts. Combiner les nuances de repli, de redondance et de coût nécessite un plan de contrôle unifié ; c'est ce que fait l'AI Gateway : elle réunit tous ces éléments en un seul élément central de l'architecture GenAI moderne.
Les passerelles AI régissent modèles, agents, outils, instructions et jetons. C'est un spécialiste plan de contrôle du middleware pour le trafic d'IA : proxy de sorte/inverse qui comprend les jetons, la sémantique et les outils.
Ce qu'il fait
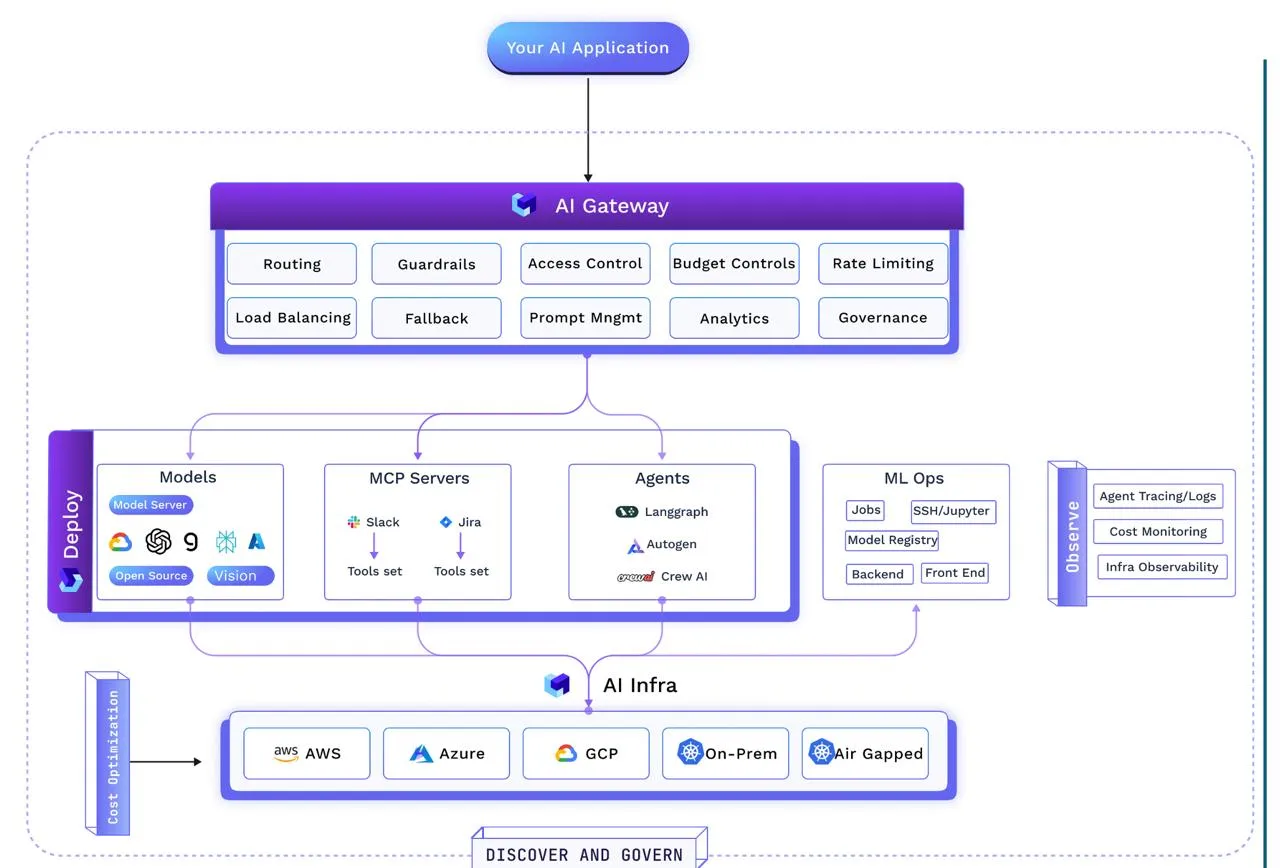
Une fois que le plan directeur est défini, que les registres sont en place, que les garanties opérationnelles sont intégrées et que l'AI Gateway les applique en temps réel, la question qui se pose est la suivante : comment gérons-nous réellement ce truc ?
C'est là que la conversation passe de l'architecture et de la gouvernance à l'exécution : couche de déploiement qui peut transférer du code et des modèles en production jeûne, gardez-les fiable, et exécutez-les de manière rentable—le tout sans enfreindre la discipline opérationnelle.
Ici, vitesse ne veut pas dire prendre des raccourcis. Un pipeline moderne passe de la validation au cluster en quelques minutes : des tests automatisés valident les modifications, contiennent les modèles de packages, les agents et les serveurs MCP dans des images immuables, et les manifestes les déploient vers le développement, le staging ou la production avec des stratégies configurables. Les mises à jour du registre permettent à la passerelle de découvrir et de gérer immédiatement les nouvelles versions. Des applications complètes (modèle, backend, frontend et outils) peuvent être déployées sous forme de piles préconfigurées, ou même créées par des agents de déploiement conversationnels.
La fiabilité est intégrée à Meilleures pratiques en matière de SRE: dimensionnement automatique et basculement instantanés, surveillance proactive, restauration/gestion des versions à la demande, journaux d'audit immuables et arrêt automatique des environnements inactifs ou des IDE.
Ici, les politiques s'appliquent également règles opérationnelles comme « aucun déploiement de production sans au moins deux répliques » ou « Les charges de travail GPU doivent s'arrêter automatiquement lorsqu'elles sont inactives ».
La rentabilité doit également être prise en compte : la couche utilise de manière fluide des instances ponctuelles avec solution de repli à la demande pour réduire les coûts, fait évoluer les charges de travail avec HPA/VPA et la mise à l'échelle automatique des clusters, et tire parti de la mise à l'échelle pilotée par les événements (par exemple, KEDA) pour permettre aux employés de se connecter instantanément en cas de besoin et de revenir à zéro en cas d'inactivité. Une fonction de type pilote automatique appliquerait des modifications de mise à l'échelle ou de placement en temps réel, équilibrant ainsi les économies de coûts et la protection SLA.
Le pipeline de déploiement standard pour une pile d'IA agentic se présente comme suit :
Les artefacts sont des images OCI et les manifestes sont de simples IAc ; les points de terminaison et les régions sont paramétrés. Cela permet de rendre les charges de travail indépendantes du cloud et de permettre une relocalisation rapide et guidée par des règles, sans toucher au code de l'application.
Avec le système en ligne (modèles déployés sur Kubernetes, agents enregistrés et passerelle appliquant les règles d'exécution), l'architecture est opérationnelle. Mais assurer la sécurité, l'efficacité et l'alignement sur les priorités de l'organisation n'est pas un exercice ponctuel. Les charges de travail seront déplacées entre les environnements, augmenteront et diminueront et évolueront avec de nouveaux outils et modèles.
Si la gouvernance n'évolue pas avec eux, vous vous retrouvez avec un comportement parallèle : des agents s'exécutant sans garde-corps, des charges de travail déployées sans redondance ou des GPU laissés au ralenti et entraînant des coûts élevés. La réponse est simple en principe, mais puissante en pratique :des politiques qui s'accompagnent de la charge de travail.
De plus, les garde-corps ne peuvent pas être considérés comme des scripts ad hoc enfouis dans la base de code d'une équipe. Ils devraient être politique en tant que code—versionné, révisé et déployé comme tout autre artefact de base :
Les politiques ne concernent pas uniquement la sécurité de l'IA. Ils peuvent encoder normes opérationnelles à l'échelle de l'organisation:
Ces règles garantissent que vos systèmes répondent aux normes de base en matière de fiabilité et d'efficacité par défaut, sans compter sur des vérifications manuelles ou sur la mémoire de l'équipe.
Dans de nombreux secteurs réglementés ou à haute sécurité, l'exploitation de grands modèles propriétaires en production devient un défi. La mise au point d'un modèle auto-hébergé plus petit permet de contourner cet obstacle tout en préservant la qualité. Et comme la passerelle est déjà intégrée au flux de trafic, elle peut gérer la migration en comparant le nouveau modèle à l'ancien, en testant les résultats des tests A/B et en acheminant le trafic en conséquence une fois les performances convergées. L'utilisation de LLM open source affinés pour les cas d'utilisation de l'IA de génération en génération à grande échelle est également rentable pour les entreprises.
Le Gateway ne se limite pas à l'application de la loi, il s'agit également d'un moteur d'évolution de modèles. En enregistrant des interactions de haute qualité à partir d'un modèle volumineux et coûteux tel que GPT-4o, il crée un ensemble de données de réglage précis pour un modèle plus petit et efficace comme LLama.
Cette approche vous permet de :
Du point de vue de l'architecte, cela fait de l'AI Gateway bien plus qu'une simple couche d'application : elle devient une moteur d'évolution de modèles, transformant discrètement les données d'exécution en base de votre IA de nouvelle génération, optimisée en termes de coûts et prête à la production.
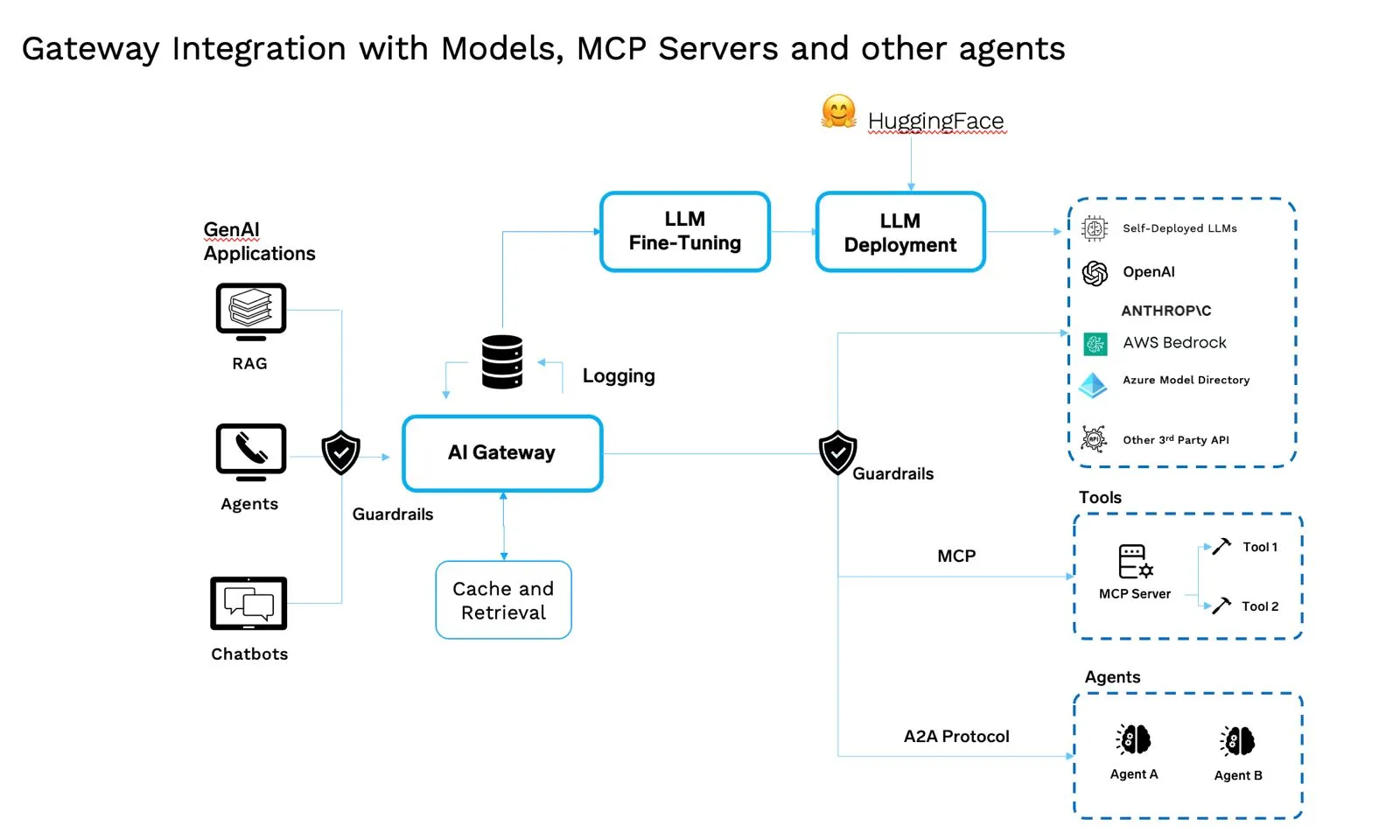
Lorsque vous considérez la pile dans son ensemble, la valeur ne réside pas dans les éléments individuels mais dans la façon dont ils fonctionnent ensemble. Les modèles doivent être suivis et versionnés. Les serveurs MCP les exposent de manière cohérente. Les agents apportent le raisonnement et la prise de décisions. Les instructions leur donnent des instructions claires. Les registres vous permettent de savoir ce qui se passe et où. Les politiques opérationnelles garantissent la sécurité et la rentabilité. Kubernetes vous offre l'évolutivité et la fiabilité nécessaires pour tout gérer.
L'AI Gateway se trouve au sommet pour coordonner ces éléments mobiles, mais la véritable force réside dans l'intégration : chaque couche est connectée, gérée et observable. C'est ce qui permet de transformer un ensemble d'outils en un système auquel les entreprises peuvent réellement faire confiance et sur lequel elles peuvent s'appuyer.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


