

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 27, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Au fur et à mesure que les équipes mettent en production des applications LLM et des agents d'IA, les coûts deviennent rapidement l'un des problèmes les plus difficiles à résoudre. Contrairement aux charges de travail cloud traditionnelles, les coûts de l'IA sont déterminés par des modèles d'utilisation dynamiques, non déterministes et souvent cachés derrière de multiples couches d'abstraction.
Une seule demande utilisateur peut déclencher plusieurs appels de modèles, de nouvelles tentatives, des appels d'outils et des boucles d'agents. De petits changements dans les instructions, la logique de routage ou le comportement des agents peuvent augmenter considérablement l'utilisation et le coût des jetons, souvent sans signaux évidents avant l'arrivée des rapports de facturation.
C'est pourquoi Observabilité des coûts liés à l'IA est essentiel dans les systèmes de production. Cela va au-delà du suivi du nombre de jetons ou des factures des fournisseurs. L'observabilité des coûts de l'IA se concentre sur l'attribution des coûts aux unités réelles des systèmes d'IA, telles que les demandes, les invites, les agents, les outils et les utilisateurs, tout en permettant aux équipes de détecter et de contrôler les problèmes de coûts à un stade précoce.
Dans ce blog, nous expliquerons ce que signifie l'observabilité des coûts de l'IA dans la pratique, pourquoi les coûts de l'IA sont difficiles à suivre et comment les équipes utilisent des architectures basées sur des passerelles pour surveiller et contrôler les dépenses LLM en production.
L'observabilité des coûts de l'IA est la capacité à mesurer, attribuer et analyser le coût des charges de travail liées à l'IA entre les modèles, les agents et les flux de travail en temps réel.
Dans les systèmes de production, cela inclut généralement :
Dans la pratique, cela va au-delà des simples tableaux de bord de facturation pour inclure des Solution de suivi des coûts LLM, où l'utilisation des jetons, les nouvelles tentatives, les décisions de routage et le comportement des agents sont directement liés aux flux de travail applicatifs réels.
Contrairement à la surveillance traditionnelle des coûts d'infrastructure, l'observabilité des coûts de l'IA doit fonctionner au niveau de l'application et de la couche d'inférence. Les outils de facturation dans le cloud peuvent indiquer aux équipes combien elles ont dépensé globalement, mais ils n'expliquent pas pourquoi les coûts ont augmenté ou quelle partie du système en a été la cause.
L'observabilité efficace des coûts de l'IA fournit aux équipes le contexte nécessaire pour répondre à des questions telles que :
En rendant les coûts visibles à ce niveau, les équipes peuvent traiter les dépenses liées à l'IA comme une mesure opérationnelle plutôt que comme une dépense surprise.
Les coûts de l'IA sont difficiles à suivre, non pas parce que les prix sont opaques, mais parce que le coût est une propriété émergente du comportement du système. Dans les environnements de production, l'utilisation du LLM est façonnée par la logique de routage, les nouvelles tentatives, les agents et les appels d'outils, qui interagissent tous de manière non évidente.
Plusieurs facteurs compliquent l'observabilité des coûts de l'IA pour les équipes.
La plupart des fournisseurs LLM facturent en fonction des jetons, mais l'utilisation des jetons est très sensible au comportement d'exécution. De petites modifications des invites, de la taille du contexte ou des contraintes de sortie peuvent augmenter considérablement le nombre de jetons. Comme ces changements se produisent souvent au niveau de l'application ou de l'invite, ils sont difficiles à détecter en utilisant uniquement la facturation au niveau du fournisseur.
Les systèmes de production reposent rarement sur un seul modèle. Les équipes acheminent les demandes vers plusieurs modèles et fournisseurs afin d'équilibrer les coûts, la latence et la qualité. Sans une vue centralisée, les données sur les coûts sont fragmentées entre les fournisseurs, ce qui rend difficile la comparaison ou l'optimisation des dépenses de manière globale.
Les défaillances sont coûteuses dans les systèmes d'IA. Les nouvelles tentatives et la logique de repli peuvent augmenter les coûts de manière silencieuse, en particulier lorsque les demandes se répercutent sur les modèles. Sans observabilité au niveau de la demande, les équipes oublient souvent ces multiplicateurs de coûts cachés avant qu'ils n'apparaissent dans les factures agrégées.
Les systèmes basés sur des agents amplifient la complexité des coûts. L'exécution d'un seul agent peut impliquer plusieurs appels de modèles, étapes de planification et appels d'outils. Si un agent entre dans une boucle ou abuse des outils, les coûts peuvent augmenter rapidement. Le suivi de ce comportement nécessite une visibilité sur la manière dont les agents s'exécutent étape par étape.
Les outils de gestion des coûts du cloud et les tableaux de bord des fournisseurs indiquent l'utilisation au niveau d'un compte ou d'un projet. Ils n'attribuent aucun coût aux invites, aux agents, aux utilisateurs ou aux flux de travail. Il est donc difficile pour les équipes chargées de la plateforme de faire respecter les budgets ou pour les équipes chargées des applications d'optimiser leur propre utilisation.
Dans la pratique, ces défis signifient que les problèmes de coûts liés à l'IA sont souvent détectés tardivement et traités de manière réactive. C'est pourquoi les équipes qui gèrent des charges de travail d'IA de production ont besoin d'une observabilité des coûts intégrée au Passerelle IA et chemin d'exécution, où transitent toutes les demandes.
Pour contrôler les dépenses liées à l'IA en production, les équipes ont besoin de plus qu'une facture mensuelle totale. Ils ont besoin de comprendre d'où viennent les coûts et pourquoi. L'observabilité des coûts repose sur Observabilité LLM en liant l'utilisation des jetons et les dépenses aux invites, aux agents et aux flux de travail. L'observabilité efficace des coûts de l'IA répartit les dépenses selon des dimensions qui correspondent à la manière dont les systèmes d'IA sont réellement conçus et exploités.
Les dimensions de coûts les plus utiles sont les suivantes.
C'est la base. Le suivi du coût par demande aide les équipes à comprendre le coût des interactions individuelles avec les utilisateurs et l'évolution de ce coût au fil du temps. Les pics indiqués ici indiquent souvent une croissance rapide, de nouvelles tentatives ou des modifications de routage.
Dans les systèmes multimodèles, les différents modèles ont des profils de coûts très différents. Les équipes ont besoin de visibilité sur le montant des dépenses consacrées à chaque modèle et fournisseur, et sur la manière dont les décisions de routage influent sur les coûts globaux. Cela est essentiel pour faire des compromis éclairés entre la qualité, la latence et les dépenses.
Les invites influencent directement l'utilisation des jetons. Le suivi des coûts par version rapide et rapide permet aux équipes de voir quelles instructions sont coûteuses et si les modifications récentes ont augmenté ou réduit les dépenses. Cela devient particulièrement important lorsque les invites sont partagées entre plusieurs applications ou agents.
Dans les systèmes basés sur des agents, l'attribution des coûts doit aller au-delà des appels de modèles individuels. Les équipes doivent comprendre le coût total de l'exécution d'un agent ou d'un flux de travail de bout en bout, y compris les étapes de planification, les appels d'outils et les nouvelles tentatives. Cela permet de mettre rapidement en évidence le comportement inefficace des agents.
Pour les plateformes internes et les déploiements en entreprise, l'attribution des coûts aux utilisateurs ou aux équipes permet de rendre compte et de budgétiser. Cette dimension est souvent requise pour appliquer des limites d'utilisation ou pour vérifier les coûts en interne.
L'observation conjointe de ces dimensions permet aux équipes de passer d'une analyse réactive des coûts à un contrôle proactif des coûts.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

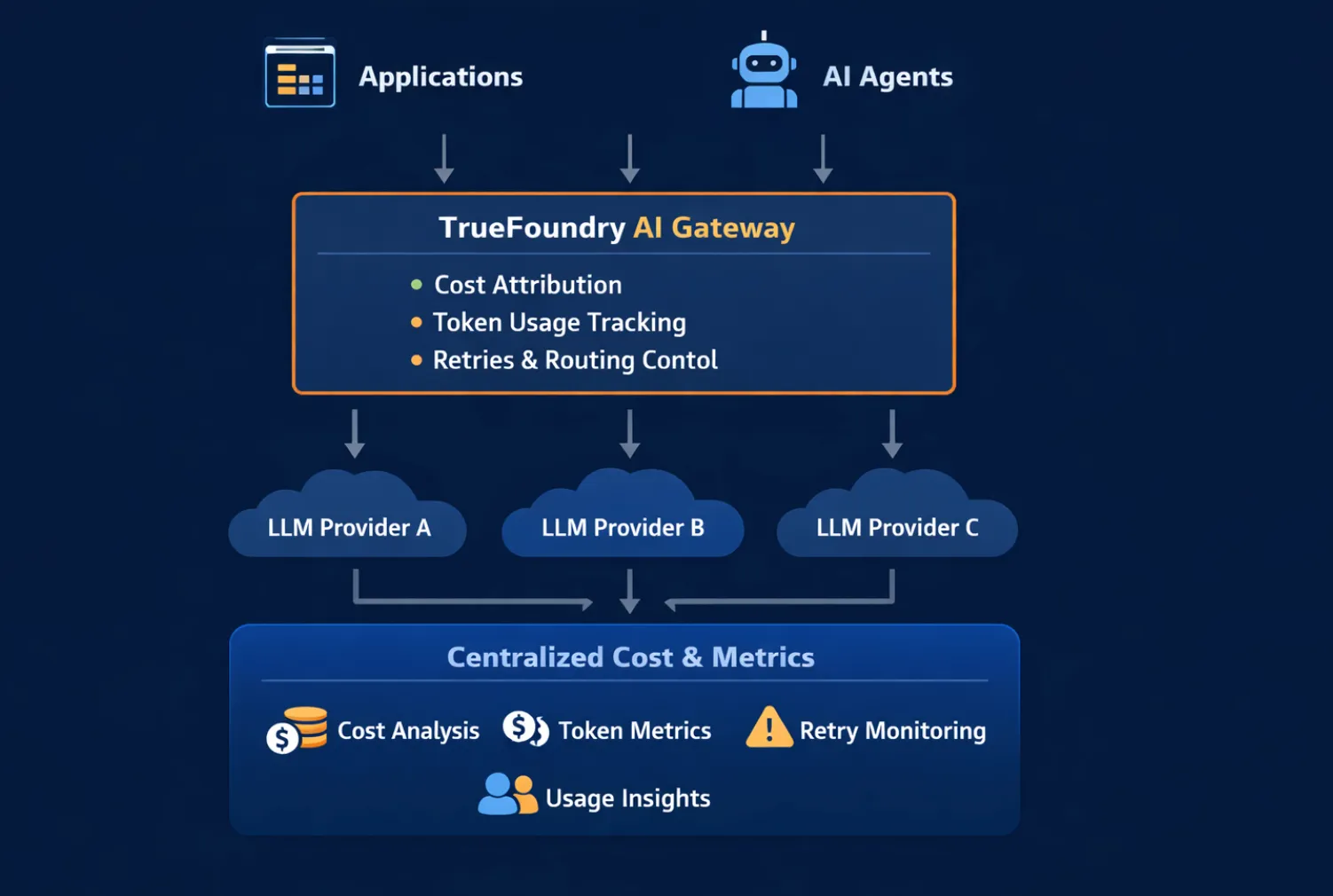
L'observabilité des coûts de l'IA donne de meilleurs résultats lorsqu'elle est mise en œuvre point d'interception central, où toutes les demandes, les décisions de routage et les nouvelles tentatives sont visibles. C'est pourquoi les passerelles IA jouent un rôle essentiel.
Un Passerelle IA se situe entre les applications ou les agents et les fournisseurs de modèles. Comme chaque demande y passe, la passerelle peut :
Sans passerelle, les données sur les coûts sont fragmentées entre les kits de développement logiciel, les services et les tableaux de bord des fournisseurs. Avec une passerelle, le coût devient un signal de premier ordre qui peut être analysé et traité avant que les dépenses n'augmentent.
Dans TrueFoundry, le Passerelle IA fournit ce point de contrôle centralisé, permettant d'observer et de gérer les coûts de l'IA entre les modèles, les agents et les flux de travail de manière unifiée.
Les systèmes basés sur des agents amplifient à la fois la puissance et le coût des charges de travail liées à l'IA. Contrairement aux applications à demande unique, les agents exécutent des flux de travail en plusieurs étapes qui peuvent impliquer la planification, le raisonnement, les nouvelles tentatives et l'utilisation d'outils. Il est donc plus difficile de prévoir le comportement des coûts et il est donc plus important de le suivre de près.
L'exécution d'un seul agent peut inclure :
Sans une observabilité adéquate, ces interactions peuvent augmenter les coûts de manière silencieuse. Les boucles d'agents, les instructions mal limitées ou l'utilisation excessive d'outils passent souvent inaperçues jusqu'à ce que les dépenses globales augmentent de manière significative.
L'observabilité des coûts liés à l'IA pour les agents nécessite une visibilité niveau d'exécution de l'agent, et pas seulement au niveau de l'appel modèle. Les équipes doivent comprendre :
C'est là qu'une architecture basée sur une passerelle devient particulièrement utile. En capturant les demandes des agents sur la passerelle, les équipes peuvent attribuer les coûts sur l'ensemble du cycle de vie d'un agent, au lieu de traiter chaque appel modèle de manière isolée.
Dans TrueFoundry, les déploiements d'agents s'intègrent à AI Gateway, ce qui permet aux équipes d'observer les coûts au fil des étapes et des flux de travail des agents. Cela permet aux équipes chargées des plateformes et des applications de détecter rapidement les comportements inefficaces des agents et d'appliquer des contraintes avant que les coûts ne montent en flèche.
.svg)
Dans True Foundry, L'observabilité des coûts de l'IA est mise en œuvre directement au Passerelle IA et couche d'exécution de l'agent, où toutes les demandes de modèles, les décisions de routage et les nouvelles tentatives sont visibles. Cela fournit une vue unifiée et cohérente des coûts entre les modèles, les invites, les agents et les flux de travail.
Comme chaque demande passe par la passerelle, TrueFoundry peut :
Cette approche centralisée transforme le coût d'une métrique passive en une signal opérationnel. Les équipes peuvent émettre des alertes en cas de dépenses anormales, appliquer les budgets au niveau de la couche de routage et prendre des décisions tenant compte des coûts lorsqu'elles choisissent des modèles ou des stratégies de repli.
Pour les équipes qui gèrent des charges de travail d'IA de production, cela garantit que les coûts restent inchangés prévisible, explicable et contrôlable, alors même que les systèmes gagnent en complexité avec de plus en plus d'agents, de modèles et de flux de travail.
Les coûts liés à l'IA deviennent difficiles à gérer dès que les applications LLM entrent en production. Les coûts ne sont plus déterminés par un seul appel de modèle, mais par une combinaison d'instructions, de décisions de routage, de nouvelles tentatives, d'agents et d'utilisation d'outils. Sans visibilité adéquate, les équipes découvrent souvent les problèmes de coûts uniquement lorsque les dépenses ont déjà augmenté.
L'observabilité des coûts de l'IA répond à ce problème en faisant du coût un signal de première classe. En attribuant les dépenses entre les demandes, les modèles, les invites, les agents et les flux de travail, les équipes peuvent comprendre non seulement combien elles dépensent, mais aussi pourquoi. Ce niveau de compréhension est essentiel pour faire fonctionner les systèmes d'IA de manière fiable à grande échelle.
Les architectures basées sur des passerelles jouent un rôle central dans cette visibilité. En capturant les demandes à un point de contrôle unique, les équipes peuvent observer, analyser et contrôler les dépenses liées à l'IA de manière cohérente, quels que soient les fournisseurs et les voies d'exécution. Dans TrueFoundry, cette approche permet aux équipes chargées des plateformes et des applications de détecter rapidement les inefficacités, de faire respecter les budgets et de trouver un équilibre entre les coûts et les performances à mesure que les charges de travail liées à l'IA augmentent.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


