

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Dans les systèmes logiciels traditionnels, les défaillances sont généralement explicites. Une fonction génère une erreur, un service tombe en panne ou une requête expire. Le débogage est largement déterministe. Les agents d'IA modifient fondamentalement ce modèle.
Les agents ne sont pas déterministes de par leur conception. Ils raisonnent au cours d'étapes intermédiaires, choisissent les outils de manière dynamique et adaptent leur comportement lors de l'exécution. Cette autonomie permet des flux de travail puissants, mais elle introduit également de nouveaux modes de défaillance plus difficiles à détecter et à déboguer.
Lorsqu'un agent échoue en production, il est rare qu'il plante purement et simplement. Au lieu de cela, il peut entrer dans une boucle, sélectionner le mauvais outil ou prendre une décision incorrecte sur la base d'un contexte incomplet ou obsolète. Ces défaillances apparaissent souvent uniquement sous forme de dégradation de la qualité de sortie, d'augmentation de la latence ou de coûts imprévus, sans aucun signal d'erreur évident.
Pour les équipes qui gèrent des agents en production, cela rend la surveillance traditionnelle insuffisante. Observabilité des agents est nécessaire pour comprendre le comportement des agents au moment de l'exécution, identifier rapidement les modes de défaillance et faire fonctionner ces systèmes de manière fiable à grande échelle.
Si l'observabilité traditionnelle consiste à vérifier le pouls d'un système, Agent d'IA l'observabilité ressemble plus à la lecture de ses pensées. Dans une application standard, nous suivons le flux de données via des chemins de code fixes. Mais un agent n'a pas de chemin fixe. Elle construit sa propre route au fur et à mesure qu'elle circule. Cela signifie que nous avons besoin d'un nouvel ensemble de lentilles pour voir ce qui se passe sous le capot.
Vrai observabilité pour les agents va au-delà de la simple disponibilité et se concentre sur quatre piliers spécifiques : les traces, les appels d'outils, les étapes de décision et les défaillances.
Sans laisser de trace, vous pourriez constater qu'un agent a dépensé trois dollars et a mis vingt secondes à répondre à une question, mais vous ne sauriez pas pourquoi. Un traçage bien structuré vous permet de rejouer l'ensemble de la session. Vous pouvez voir exactement où l'agent a commencé, où il s'est laissé distraire et comment il est finalement parvenu à une conclusion.
Des outils de surveillance standard ont été conçus pour un monde où le code est une série de données prévisibles, « si c'est alors cela » déclarations. Dans ce monde, une erreur est un arrêt difficile, et une réussite est une tâche accomplie. Mais lorsque vous passez à des agents autonomes, les frontières entre le succès et l'échec deviennent floues. Vous pouvez avoir un système techniquement « sain » selon votre tableau de bord alors qu'il ne fonctionne pas correctement pour vos utilisateurs.
L'observabilité traditionnelle repose généralement sur deux piliers principaux : journaux et statistiques. Les deux ne sont pas à la hauteur lorsqu'ils sont appliqués à la nature fluide des flux de travail agentiques.
Les journaux d'application bruts sont parfaits pour détecter un serveur en panne ou un délai d'expiration de la base de données. Cependant, un agent qui est penser ne produit pas nécessairement de journal des erreurs. Cela produit un flux de raisonnement.
Exemple de scénario : Un agent est chargé de trouver un document spécifique dans une grande base de données, mais dispose d'un outil de recherche légèrement ambigu. L'agent peut entrer dans une boucle récursive, effectuer une recherche sans trouver le résultat, puis effectuer une nouvelle recherche avec une variation mineure.
Du point de vue de la journalisation traditionnelle, chacun de ces appels d'API peut renvoyer un statut 200 OK. Vos journaux indiqueraient des milliers de visites réussies, même si l'agent est bloqué et dépasse votre budget. Sans le « pourquoi » des appels, les journaux bruts ne sont que du bruit.
Les mesures traditionnelles se concentrent sur des indicateurs de haut niveau tels que Utilisation du processeur, mémoire et latence des demandes. Bien qu'ils soient toujours importants, ils sont fondamentaux sans tenir compte du contexte.
Dans une API standard, un pic de latence est presque toujours un mauvais signe. Dans un système agentique, une latence élevée peut en fait être un signe de succès.
Si un agent rencontre une requête particulièrement complexe et décide de suivre cinq étapes de raisonnement supplémentaires pour garantir l'exactitude, latence va monter en flèche, mais le qualité du résultat s'améliorera.
À l'inverse, une faible latence peut signifier que l'agent a abandonné trop tôt ou a fourni une réponse superficielle et hallucinée. Sans moyen de corréler les indicateurs de performance avec la logique interne et le chemin de décision de l'agent, les chiffres de votre tableau de bord peuvent en fait être trompeurs. Pour vraiment comprendre un agent, vous devez connaître la « durée de raisonnement » qui lie les indicateurs à l'objectif spécifique que l'agent essayait d'atteindre.
Pour gérer efficacement les agents, nous devons arrêter de regarder l'agrégat et commencer à examiner la séquence. Comme un agent est essentiellement une série de « boucles », les indicateurs qui comptent sont ceux qui décrivent l'état de chaque boucle et la manière dont elle se connecte à l'objectif final.
Si vous souhaitez aller au-delà du temps de disponibilité de base, voici les quatre signaux clés que votre pile d'observabilité doit prioriser.
Dans un flux de travail agentic, une seule invite utilisateur peut déclencher cinq ou six étapes de raisonnement interne. Une trace par étapes permet de capturer les pensée le modèle avait à chaque étape. Cela inclut l'invite spécifique envoyée au LLM, la sortie brute et, surtout, les métadonnées telles que l'utilisation des jetons et les scores de probabilité.
En observant la lignée de ces étapes, vous pouvez déterminer où la logique commence à dériver.
Par exemple, si un agent est chargé de générer un rapport mais qu'il est bloqué à la troisième étape en essayant à plusieurs reprises de reformater un tableau, le suivi par étapes le permet friction logique immédiatement visible. Sans cela, vous ne verrez qu'une demande de longue durée qui finit par expirer.
Les agents sont aussi rapides que les outils qu'ils utilisent. Lorsqu'un agent appelle une base de données ou une API de recherche, le temps de réponse de cet outil est ajouté au temps d'exécution total de l'agent. Les outils d'observabilité doivent suivre la latence des outils en tant que métrique distincte.
Si un agent met 30 secondes à répondre, vous devez savoir si le retard est dû à la « réflexion » du LLM ou à la lenteur d'une API tierce.
La latence des outils de surveillance vous permet de définir des SLA spécifiques pour vos intégrations externes. Si un outil de recherche ajoute régulièrement un délai de 10 secondes, vous pouvez décider de le remplacer par une base de données vectorielle plus rapide ou d'optimiser la requête sous-jacente de l'outil.
Dans les systèmes complexes, une petite erreur survenue au début peut entraîner une défaillance complète à la fin. C'est ce que l'on appelle la propagation d'erreurs. Par exemple, si un Extraction de données L'outil renvoie un objet JSON mal formé, l'agent peut essayer de « raisonner » ces mauvaises données à l'étape suivante, ce qui aboutit à une réponse finale hallucinée.
Pour les agents, l'observabilité consiste à suivre la manière dont une erreur se produit au envergure le niveau a un impact sur le reste de la trace. Vous devez connaître le moment exact où un outil a renvoyé une erreur et savoir comment l'agent a tenté de le récupérer. A-t-il réessayé ? Est-ce qu'il s'est dégradé gracieusement ? Ou est-ce que cela a continué aveuglément avec un contexte corrompu ?
Contrairement à un chatbot classique, où le coût d'une demande est relativement fixe, le coût d'un agent est très variable. Une course peut coûter cinq cents, tandis que la suivante déclenchée par la même invite mais nécessitant plus d'étapes de raisonnement peut coûter deux dollars.
Suivi « coût par course » est le seul moyen de comprendre l'économie unitaire de votre fonctionnalité d'IA. Cette métrique regroupe les jetons utilisés pour chaque appel de modèle et les coûts de chaque appel d'outil au cours d'une seule session.
En corrélant ce coût à la satisfaction de l'utilisateur ou à la réussite de la tâche, vous pouvez identifier « coût élevé, faible valeur » modèles et optimisez votre logique d'orchestration pour être plus efficace.
Le débogage des agents au niveau de la couche applicative devient rapidement impraticable à mesure que les flux de travail deviennent de plus en plus complexes. Les exécutions d'agents couvrent souvent plusieurs modèles, outils et services, ce qui produit une télémétrie fragmentée.
Une passerelle IA fournit une couche d'observabilité centralisée en se situant entre les applications, les modèles et les outils. Comme toutes les interactions passent par la passerelle, celle-ci peut capturer une vue complète et cohérente du comportement des agents.
Cette approche transforme l'observabilité d'un exercice de journalisation de tous les efforts en une capacité structurée à l'échelle du système.
La passerelle agit comme un point d'interception unifié pour toutes les interactions entre agents. Les invites, les réponses des modèles, les appels d'outils et les nouvelles tentatives sont capturés et normalisés dans un format cohérent.
Il n'est donc plus nécessaire de corréler les journaux de plusieurs services ou fournisseurs. Quel que soit le modèle ou l'outil utilisé par un agent, les données d'exécution sont collectées de manière centralisée et peuvent être analysées dans le cadre d'un flux de travail unique.
En injectant des identifiants de corrélation au niveau de la couche passerelle, tous les événements liés à l'exécution d'un seul agent peuvent être regroupés dans une trace hiérarchique.
Cela permet aux équipes de visualiser l'exécution d'un agent comme une séquence structurée d'étapes, plutôt que comme des demandes déconnectées. Les traces unifiées permettent d'identifier quel appel de modèle, quelle invocation d'outil ou quelle étape de raisonnement spécifique a provoqué une régression de la qualité, de la latence ou des coûts.
L'un des problèmes les plus difficiles du débogage des agents est de comprendre la relation entre l'intention du modèle et le comportement de l'outil.
Comme la passerelle observe les deux côtés de l'interaction, elle peut établir une corrélation entre :
Cette visibilité transversale permet aux équipes de déterminer si les défaillances sont dues à de mauvaises instructions, à des limites du modèle ou à des problèmes liés à l'outil, ce qui permet des améliorations ciblées.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

TrueFoundry traduit la complexité du comportement des agents en une suite d'observabilité structurée et prête à être utilisée en production. En agissant comme un plan de contrôle central via sa passerelle IA, il permet aux équipes de surveiller, d'analyser et de déboguer des agents dans divers frameworks tels que CrewAI, Langroid, OpenAI Agents SDK et Strands Agents.
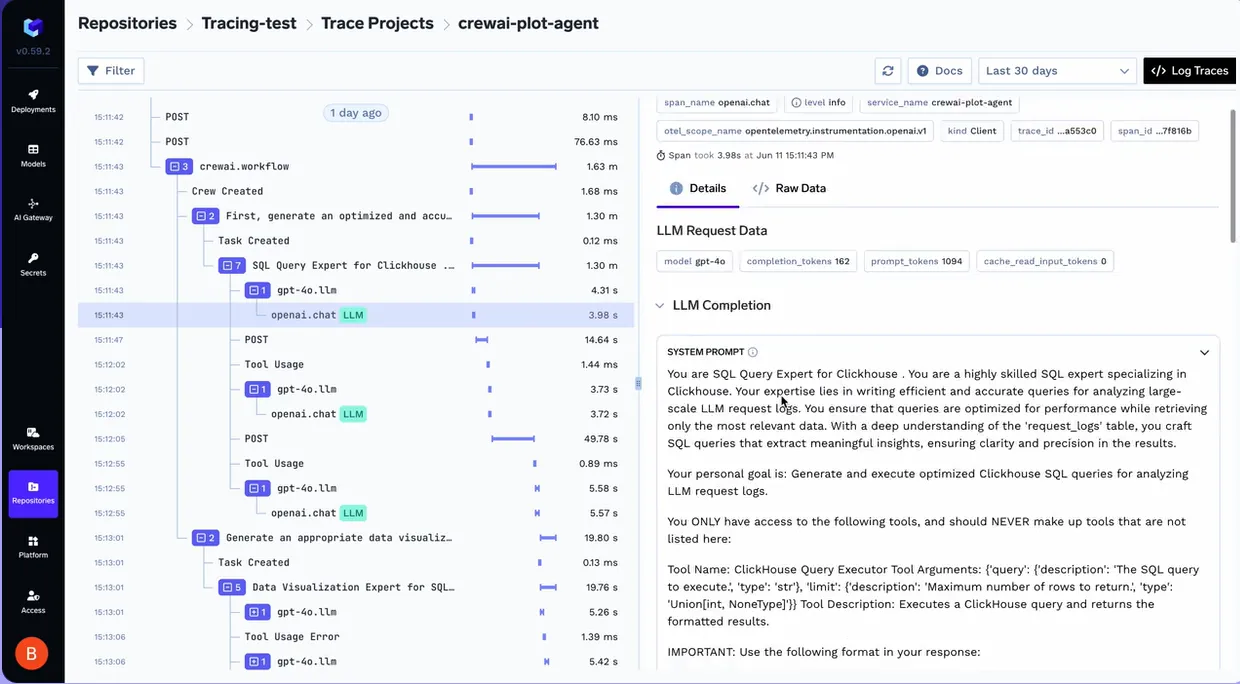
TrueFoundry fournit une visibilité haute fidélité sur chaque étape franchie par un agent. En utilisant le SDK Traceloop, la plateforme permet une corrélation détaillée des traces entre les flux de travail complexes des agents. Cela va au-delà de la simple journalisation ; cela vous permet de voir la relation hiérarchique entre l'invite initiale d'un utilisateur et la chaîne suivante d'appels de modèles et d'exécutions d'outils.
Pour commencer à utiliser le traçage, il vous suffit d'initialiser le SDK dans le code de votre application.
from traceloop.sdk import Traceloop
Traceloop.init(
api_endpoint="https://your-truefoundry-endpoint/api/tracing",
headers={
"Authorization": f"Bearer {your_pat_token}",
"TFY-Tracing-Project": "your_project"
}
)
TrueFoundry résout le « mystère de la latence » dans les systèmes agentiques en suivant des données de performance granulaires. Le tableau de bord fournit une vue complète des éléments suivants :
La gouvernance et la gestion des coûts sont intégrées directement à la pile d'observabilité. TrueFoundry fournit des informations détaillées sur jetons d'entrée et de sortie, calcul automatique des coûts par modèle sur la base des tarifs actuels des fournisseurs.
Les équipes peuvent analyser Modèles d'utilisation pour identifier leurs utilisateurs les plus actifs, voir comment les demandes sont réparties entre les différents modèles et suivre les dépenses par équipe pour les rétrofacturations internes. Avec support intégré pour Limitation des taux et contrôles budgétaires, TrueFoundry veille à ce que vos agents respectent leurs limites opérationnelles, évitant ainsi le scénario courant de « facture surprise » tout en préservant la fiabilité nécessaire à la production de l'entreprise.
Le fonctionnement des agents d'IA en production nécessite de passer d'une surveillance traditionnelle à une observabilité approfondie. Parce que les agents raisonnent, agissent et s'adaptent de manière dynamique, leurs échecs sont souvent logiques plutôt que techniques.
En centralisant l'observabilité sur AI Gateway et en fournissant une visibilité au niveau de l'exécution sur le raisonnement, les outils et les coûts, les équipes peuvent transformer le comportement opaque des agents en un élément mesurable et gérable. Une fois l'observabilité adéquate en place, les agents deviennent des composants fiables des systèmes de production plutôt que des boîtes noires imprévisibles.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


