














June 29, 2026
|
5 min read

Published: June 14, 2026
Blazingly fast way to build, track and deploy your models!
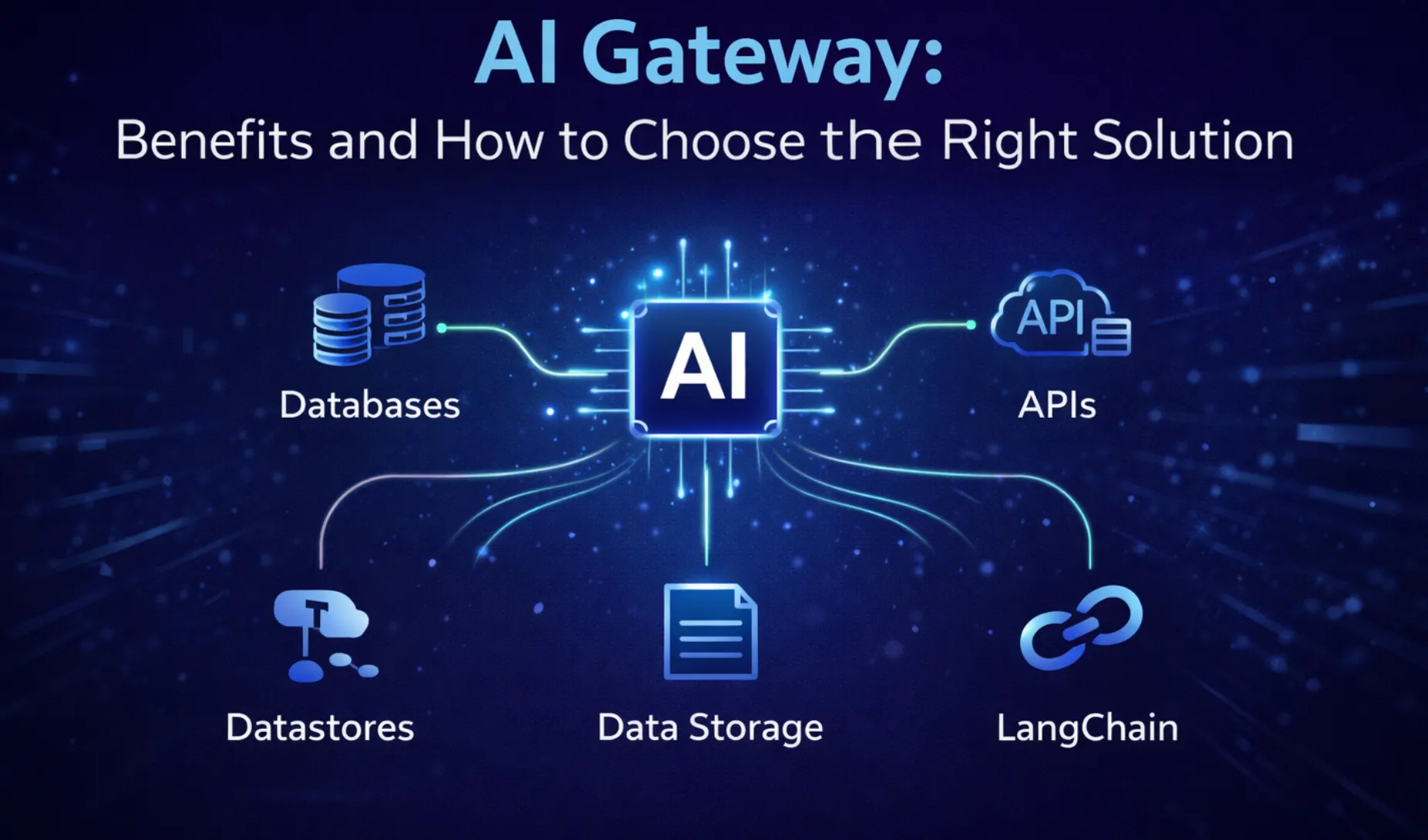
An AI Gateway is an abstraction layer that unifies access to multiple Large Language Models (LLMs) through a single API interface. It provides a consistent, secure, and optimized way to interact with models across providers such as OpenAI, Anthropic, Cohere, Together.ai, or open-source models like Mistral and LLaMA deployed on your own infrastructure.
At its core, an AI Gateway handles the heavy lifting of integrating, routing, authenticating, and monitoring LLM usage across different endpoints. Instead of dealing with multiple SDKs, authentication tokens, rate limits, and pricing models for each provider, teams route all model requests through the Gateway. This streamlines development and enables governance at scale.
TrueFoundry's AI Gateway is built for enterprise-grade performance and observability. It allowsteams to:
In addition, the Gateway supports streaming and non-streaming modes, tool calling (function calling), prompt templating, and tagging for team-level cost breakdowns. With built-in observability, TrueFoundry enables tracking of not just latency and token usage but also user-specific access, traffic trends, and per-endpoint performance.
As LLM usage grows across teams, use cases, and environments, an AI Gateway becomes the foundation for operationalizing generative AI in production. It provides control, visibility, and optimization across the entire lifecycle of LLM interactions.
The increase in AI gateways is mainly in response to growing complexity. Most teams no longer use a single model from one provider. They are testing multiple models, balancing performance with cost, and supporting different use cases across teams. Without an abstraction layer, this situation can quickly become fragile and hard to manage.
Cost pressure has also had a significant impact. As AI usage grows, token consumption and latency shift from being technical issues to business concerns. AI gateways enable teams to route traffic smartly, enforce budgets, and gain insights into actual spending.
Governance is another important factor. As systems handle more sensitive data and regulated workflows, organizations require stronger controls over access, auditing, and compliance. A gateway serves as a natural point for enforcing those policies.
Also Read: OpenRouter vs AI gateway
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

An AI Gateway brings a structured and scalable approach to managing LLM usage across teams and environments. Below are the key features that make it essential for modern GenAI workflows:
Unified Access: AI Gateways offer a single API interface to access multiple LLMs across vendors like OpenAI, Anthropic, or in-house models. This eliminates the need to manage individual APIs, SDKs, or keys for each provider.
Authentication and Authorization: AI Gateways enforce secure access through centralized key management. Developers receive scoped API keys while root keys remain protected, integrated with secret managers like AWS SSM, Google Secret Manager, or Azure Vault.
Role-Based Access Control (RBAC): Ensures that only authorized users can access specific models or actions, aligning with enterprise security standards.
Performance Monitoring: Track latency, error rates, and token throughput for each model endpoint. This helps detect issues early, optimize routing, and maintain SLAs.
Usage Analytics: Detailed logs and dashboards show who used which model, when, and how, offering transparency across projects and enabling cost attribution per user, team, or feature.
Cost Management: Gateways track token-level usage and associate costs with users, teams, or endpoints. This provides clear visibility into spend patterns and helps prevent cost overruns.
API Integrations: Support for external APIs and tools such as evaluation pipelines, prompt guardrails, or vector databases enables seamless integration with broader AI/ML ecosystems.
Custom Model Support: Users can bring their own fine-tuned or proprietary models into the Gateway, routing traffic alongside commercial models.
Caching: Store and reuse identical or similar LLM responses to save tokens and reduce latency.
Routing and Fallbacks: Intelligent request routing based on latency, cost, or reliability. Includes fallback mechanisms and auto-retries to improve resiliency.
Rate Limiting and Load Balancing: Supports user-level quotas, rate limiting, and load balancing across model providers for optimal throughput and stability.
Evaluating the best AI gateway requires a comprehensive assessment of its capabilities across access control, model integration, observability, and cost governance. A robust AI Gateway should simplify model usage while ensuring scalability, performance, and security for production-grade applications.
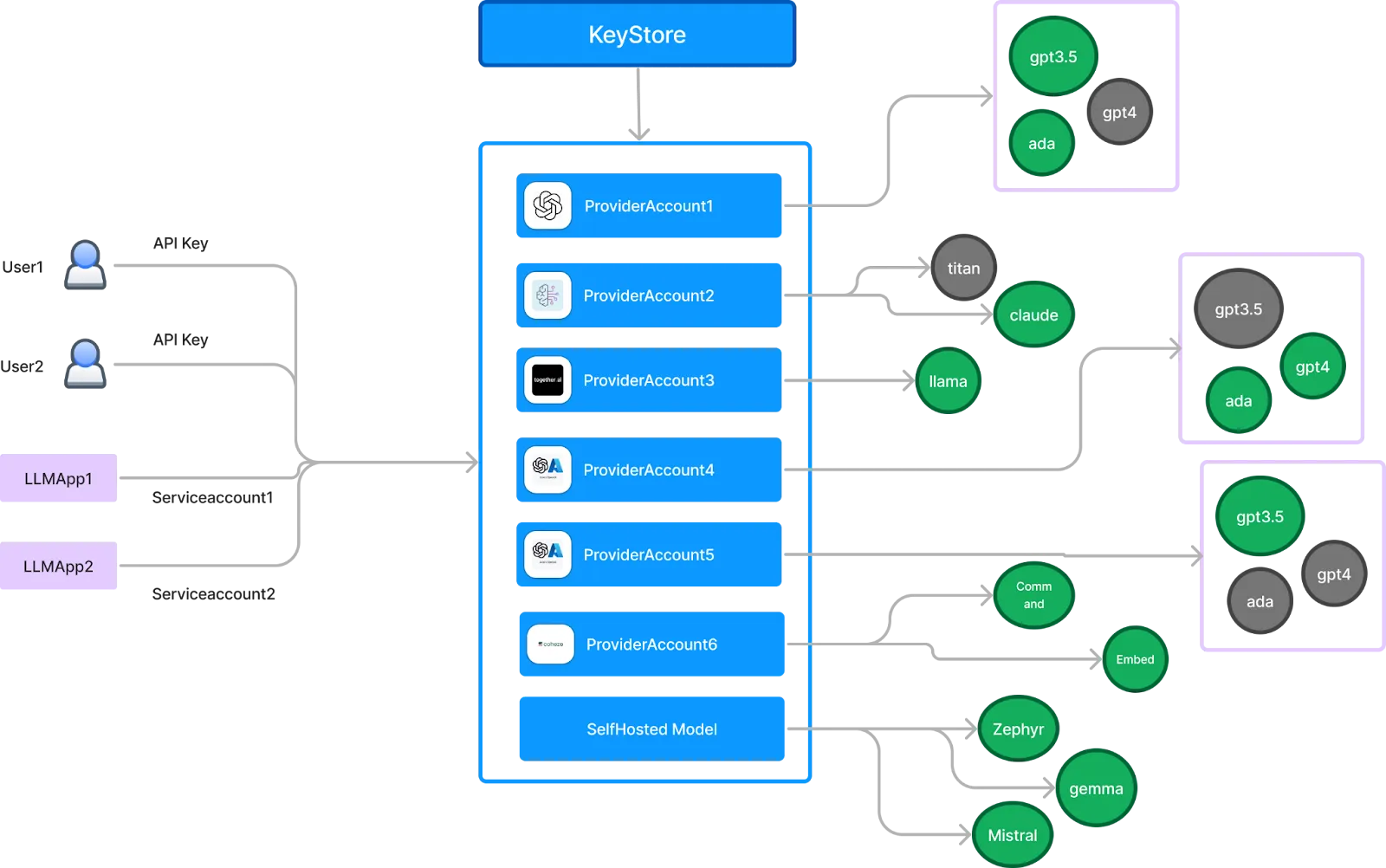
A strong AI Gateway centralizes API key management by issuing individual keys to each user or service while safeguarding root keys using secret managers like AWS SSM, Google Secret Store, or Azure Vault.
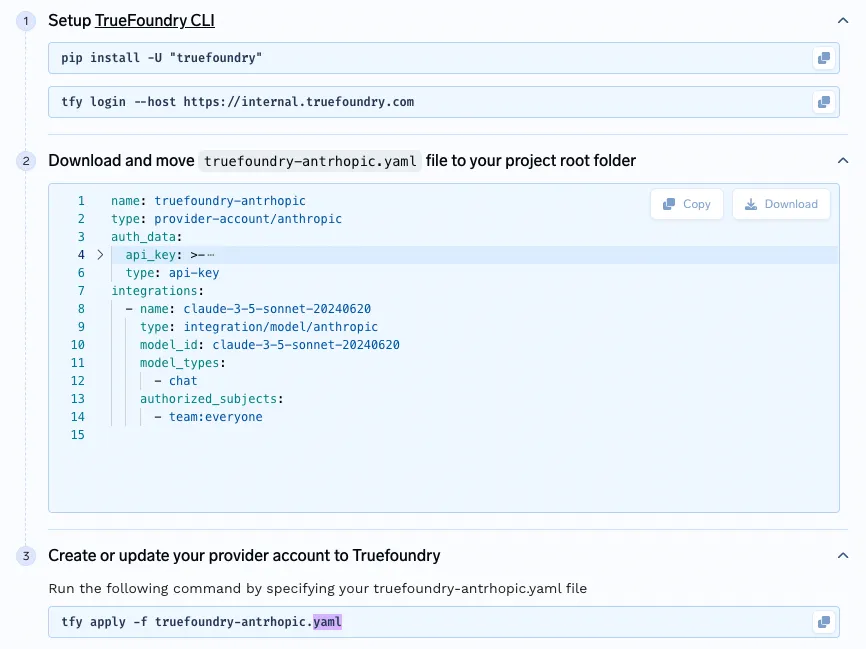
TrueFoundry’s Gateway allows administrators to manage fine-grained access to all integrated models, whether self-hosted or third-party, via a unified admin interface. Access control configurations are tracked in versioned YAML files, ensuring auditability and compliance.
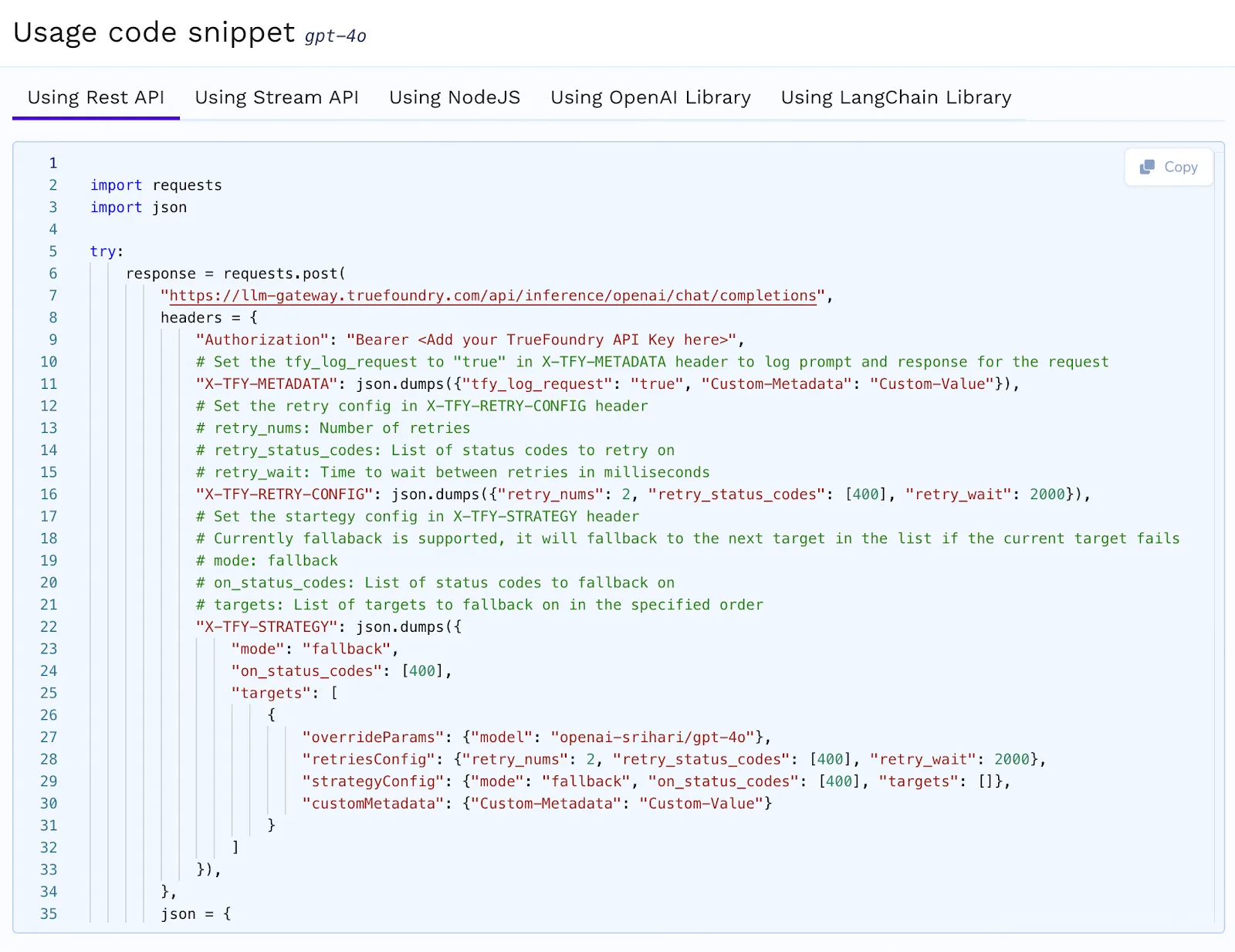
The AI Gateway should offer a standardized interface for interacting with multiple models. TrueFoundry follows the OpenAI request-response format, making it compatible with LangChain and OpenAI SDKs. Developers can switch between models without modifying their code. TrueFoundry also provides auto-generated code snippets for different providers and programming languages, simplifying integration.
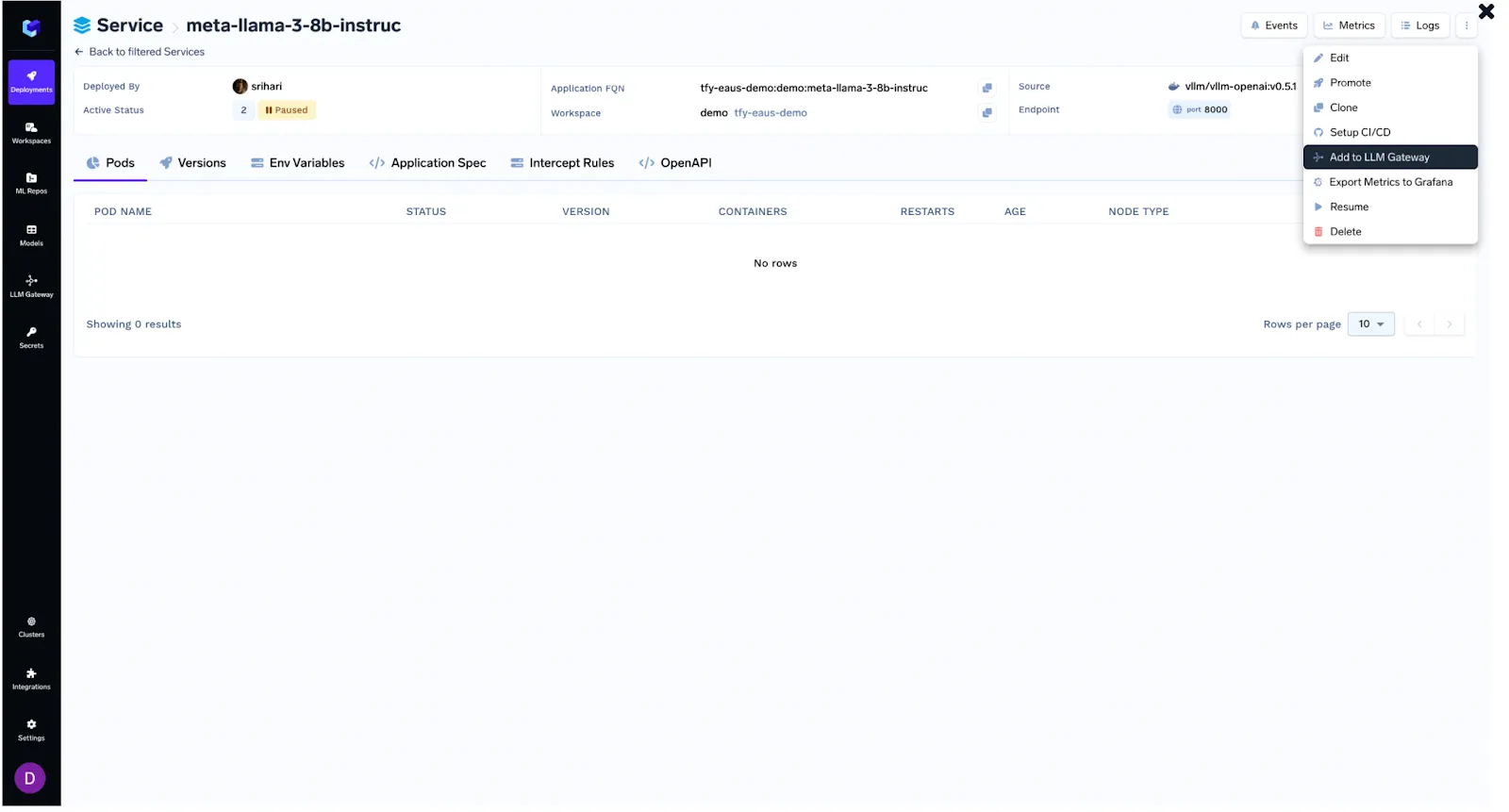
TrueFoundry supports three key routes for model access: third-party providers (like OpenAI, Cohere, AWS Bedrock, and Anthropic), self-hosted open-source models (deployed via HuggingFace or custom infrastructure), and TrueFoundry-hosted models shared across clients. This flexibility enables teams to mix and match models based on use case, budget, or latency requirements.
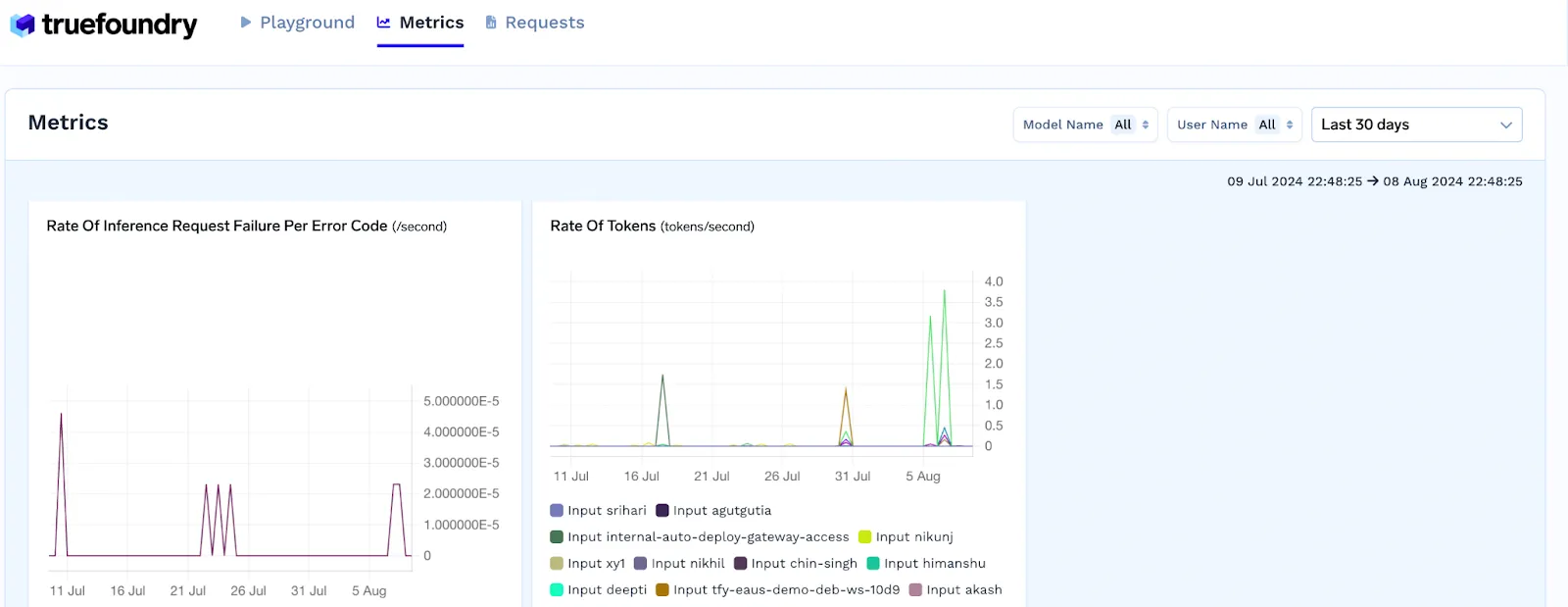
To ensure reliability, the Gateway should monitor latency, error rates, throughput, and inference failures. TrueFoundry captures key metrics like request latency, rate of tokens, and rate of inference failures, making it easy to identify performance bottlenecks through real-time dashboards.
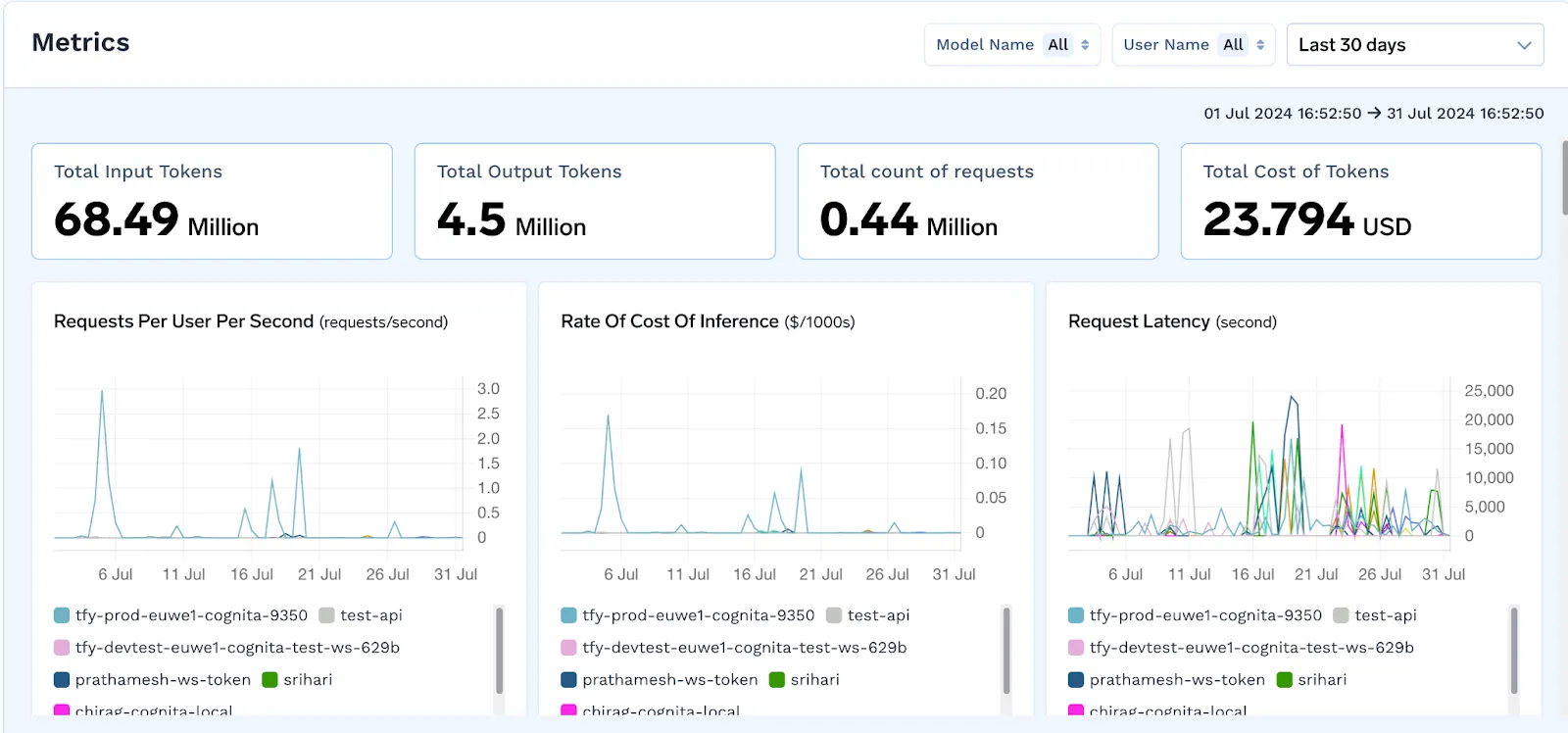
Understanding how, when, and by whom models are used is critical for governance. TrueFoundry logs detailed request and response activity, token consumption, and cost per model. These insights help teams manage workloads and optimize usage patterns.
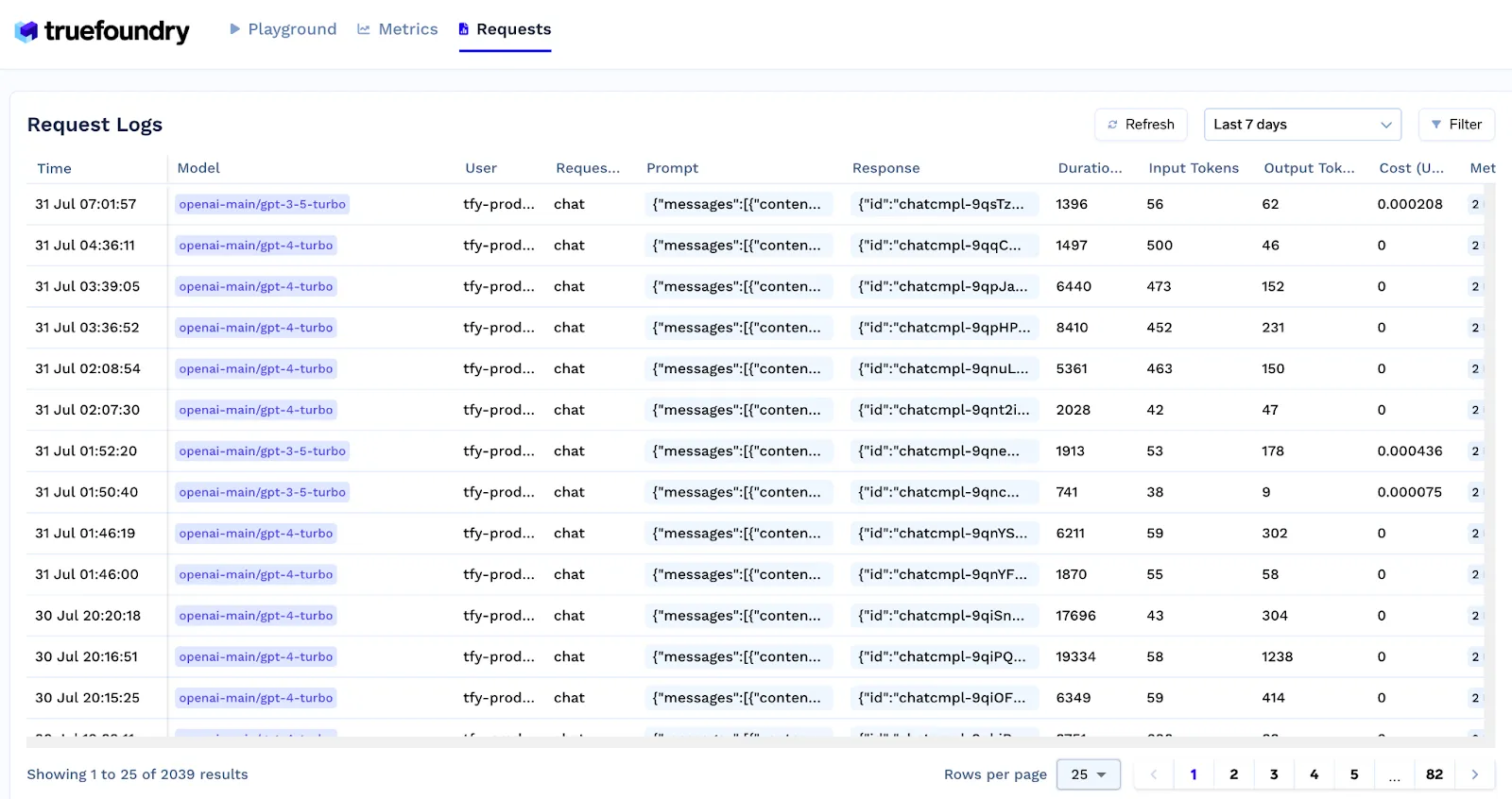
The Gateway should log costs from all model interactions, whether hosted internally or through commercial APIs. TrueFoundry provides full visibility into model usage costs across users, teams, and projects. Integrated dashboards allow organizations to track spend, configure alerts, and apply rate limits or budget caps to control overages.
Advanced features in an AI Gateway determine how effectively it can operate in real-world, production-scale environments. TrueFoundry’s AI Gateway brings a rich set of capabilities that optimize performance, improve reliability, and seamlessly integrate with broader systems, making it enterprise-ready from day one.
Caching helps reduce latency and save costs by avoiding redundant model calls. TrueFoundry supports both exact match caching (for identical prompts) and semantic caching (for similar meaning queries), which enhances speed without compromising on relevance. You can configure cache expiration policies and manually invalidate outdated entries when needed. This ensures that the gateway serves fast, accurate, and up-to-date responses.
For production-critical applications, the gateway automatically routes traffic to alternative models if the primary one fails, ensuring uninterrupted service. Automatic retries help recover from transient errors without user intervention. Built-in rate limiting helps enforce quotas and prevent overuse, while load balancing distributes traffic across multiple models or providers to maintain optimal throughput and minimize latency.
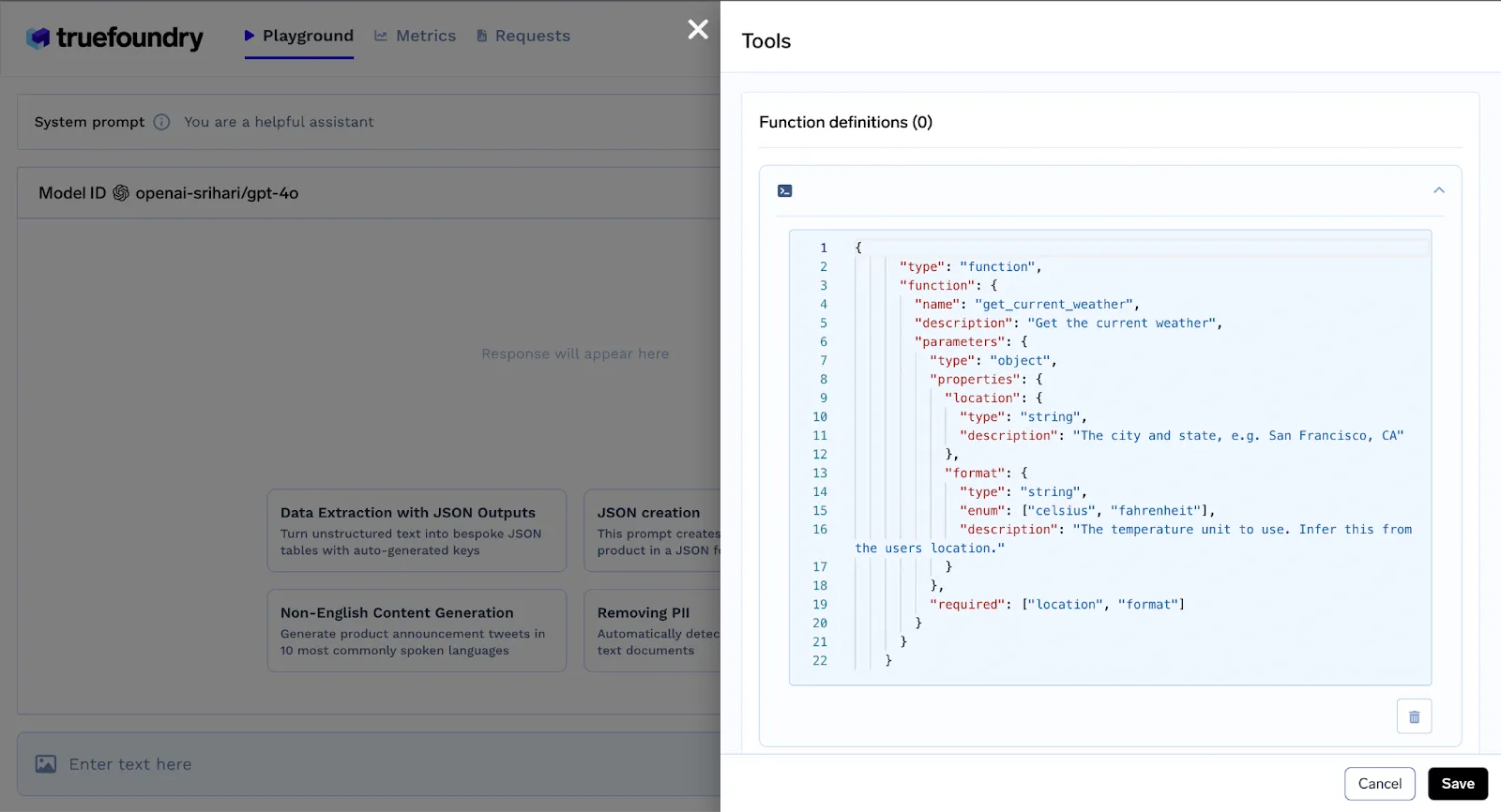
TrueFoundry’s Gateway supports tool calling by simulating interactions with external APIs. While the actual function is not executed by the gateway, the model can return structured outputs representing the intended tool call. This is ideal for building workflows where LLMs need to decide when and how to invoke tools, enabling developers to design and test these behaviors safely.
Modern applications often involve more than just text. The Gateway supports multimodal inputs such as text and images within the same request, which unlocks use cases like document Q&A, visual search, or customer support enriched with screenshots or product photos. This makes the AI Gateway suitable for both traditional NLP and next-gen AI applications that require context from multiple data formats.
TrueFoundry enables deep integration with your existing stack. You can plug in observability tools like Prometheus and Grafana for real-time monitoring, implement safety layers using Guardrails AI or NeMo Guardrails, and evaluate model quality continuously using Arize or MLflow. This connected ecosystem ensures that your AI system is not just performant, but also safe, transparent, and continuously improving.
An AI Gateway delivers significant operational, financial, and engineering advantages for organizations integrating large language models (LLMs) into their products and workflows. It acts as a control plane for AI consumption, providing a consistent interface, enforcing security, and optimizing performance at scale.
Centralized Access and Governance
When multiple teams or applications need to interact with different LLM providers, managing individual keys, tokens, and access rights becomes complex. An AI Gateway centralizes access control, enabling role-based permissions, audit logging, and secure key management.
Example: A global enterprise deploying AI features across marketing, product, and support teams uses an AI Gateway to assign scoped API keys and restrict each team’s access to specific models, reducing the risk of accidental misuse or data leakage.
Cost Transparency and Budget Control
LLMs can become a significant operational cost, especially with growing usage across teams. AI Gateways provide fine-grained cost tracking by user, team, or project. This visibility helps organizations manage budgets, identify inefficiencies, and introduce chargeback models where appropriate.
Example: A SaaS company offering AI-powered features to its customers monitors usage via the gateway and uses the data to implement tiered pricing based on actual token consumption.
Seamless Model Switching and Abstraction
The unified API layer allows organizations to swap LLMs or providers without modifying application code. This makes it easier to test new models, negotiate better pricing, or shift from commercial to open-source deployments.
Example: A startup initially using a commercial LLM transitions to a fine-tuned open-source model for data privacy and cost savings, without changing their codebase, thanks to the gateway abstraction.
Improved Reliability and Resilience
Gateways offer built-in fallbacks, automatic retries, caching, and load balancing to ensure uninterrupted service and consistent performance, even under load or during provider outages.
Example: A high-traffic chatbot system handles sudden traffic spikes by dynamically routing requests across multiple providers while falling back to cached responses when needed.
Compliance and Observability
For regulated industries, the ability to track and audit model usage is critical. AI Gateways integrate with monitoring, logging, and security tooling to meet compliance standards and internal governance policies.
Example: A healthcare company logs every request and response through the gateway, enabling complete traceability for audit purposes while maintaining data access boundaries.
If terms like API gateway and AI gateway feel easy to mix up, you’re not alone. Many teams first encounter gateways when scaling their APIs. With that context in mind, here’s how AI gateways differ and why they exist in the first place.
AI gateways are purpose-built for the complexities of Large Language Models (LLMs). They move beyond simple traffic management to handle the "intelligence" of the data.
Here is a clear comparison between traditional API Gateways and specialized AI Gateways.
In short, a traditional gateway manages how data moves. An AI gateway manages what the data costs and how it behaves. For a modern AI stack, the gateway is your primary defense against spiraling costs and security risks.
As organizations scale their use of large language models, the need for a secure, reliable, and efficient interface becomes critical. An AI Gateway serves as that foundational layer, abstracting away the complexity of managing multiple providers, enforcing access controls, tracking costs, and ensuring performance at scale. It empowers teams to experiment, deploy, and monitor LLM-powered applications with confidence and control.
Whether you're building internal copilots, customer-facing chat interfaces, or multimodal AI workflows, an AI Gateway helps standardize infrastructure while remaining flexible enough to support evolving model ecosystems. Features like caching, routing, cost attribution, and tool calling further extend its value for enterprise-grade deployments.
In a rapidly changing AI landscape, adopting an AI Gateway is not just a convenience; it’s a strategic investment in operational maturity, observability, and long-term scalability.
Ready to see these capabilities in action? Book a demo with TrueFoundry today to learn how we can centralize and secure your enterprise AI infrastructure.
An AI gateway acts as a centralized control plane that unifies multiple LLM providers under a single API. It manages the heavy lifting of request routing, authentication, and performance monitoring across different endpoints. By handling automated retries and defining team-specific rate limits, it ensures your AI infrastructure remains stable and cost-efficient.
The best AI gateway must offer production-grade reliability and vendor flexibility. TrueFoundry is a top contender because it provides unique enterprise features like semantic caching for lower latency and automated model fallbacks to prevent outages. This allows teams to seamlessly switch between commercial and self-hosted models without rewriting application code.
While an AI firewall focuses specifically on security threats like prompt injection, an AI gateway manages the broader "intelligence" of data flow. The gateway handles operational tasks like token-based load balancing, semantic caching, and model failover. Think of the gateway as the complete management layer and the firewall as a specific security guard.
TrueFoundry empowers enterprises to scale AI by providing granular visibility into token usage and costs across departments. It simplifies governance through role-based access control and versioned prompt management, ensuring compliance and reproducibility. This centralized approach allows organizations to move from experimental prototypes to secure, high-performance production environments efficiently.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.



.webp)


.webp)
.webp)
.webp)
.png)






.webp)
.webp)