

August 27, 2025
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 4, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
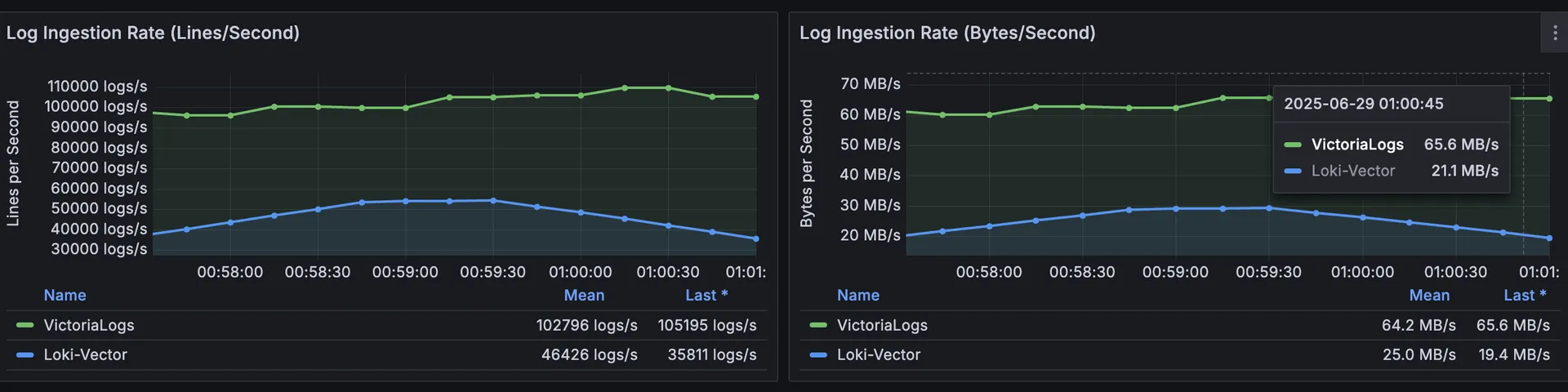
L; SECAR — Tras realizar pruebas paralelas con una carga de trabajo de 500 GB/7 días, VictoriaLogs redujo las latencias de las consultas en 94%, redujo el almacenamiento en ≈ 40%, y usó menos del 50% de la CPU y la RAM que asignamos anteriormente a Loki. En este post se explica por qué cambiamos.
Truefoundry ayuda a los desarrolladores a ejecutar cargas de trabajo de aprendizaje automático multiusuario en Kubernetes.
Los desarrolladores necesitan:
Al principio, Loki nos sirvió bien, pero a medida que el volumen creció, vimos latencias de búsqueda de más de 30 s y una alta amplificación de E/S. Esto provocó una evaluación de VictoriaLogs.
Loki es el sistema de agregación de registros de Grafana‑Labs que almacena los registros en fragmentos comprimidos acompañados de un índice creado a partir de etiquetas (pares clave-valor). Las consultas se expresan en LogQL y dependen en gran medida de los filtros de etiquetas seguidos del filtrado de líneas.
Logos de Victoria es una base de datos de registro del equipo de VictoriaMetrics. Utiliza columnar Estilo LSM almacenamiento con índices por campo, búsqueda acelerada por SIMD y LogSQL similar a SQL sintaxis.

[REGISTRO ESTÁTICO ÚNICO] ID=abc123 XYZ en un espacio de nombres lleno de registros pesados durante 7 días.Propósito: Total de líneas de registro desde app="serviciofoundry-server»
Propósito: Busque una línea de registro estática única en verdadera fundición espacio de nombres
Propósito: Busca un patrón de reinicio conocido :3000 en un pequeño subconjunto de registros (dirigido a un único fragmento)
Se verificó que los conjuntos de resultados eran idénticos.
Propósito: busca un registro inexistente, lo que desencadena una búsqueda de datos completa
Se verificó que los conjuntos de resultados eran idénticos.
Con datos de procesamiento de 500 GB, Loki se comportó de manera extraña. Los recursos se agotaron y la respuesta a la consulta se detuvo.
Nuestra evaluación se centró en tres dimensiones que son importantes para los ingenieros de plataformas en el día a día:
¿Por qué la brecha? VictoriaLogs mantiene un índice por token, por lo que incluso los escaneos similares a los de las expresiones regulares son asistidos por índices. Loki, por el contrario, filtra línea por línea después de una consulta de etiqueta, lo que se convierte en un escaneo de fuerza bruta cuando el conjunto de etiquetas es amplio.
También hicimos pruebas de estrés para la ingestión con 120 réplicas de nuestros azotar generador.
Los resultados fueron reveladores:
Loki:
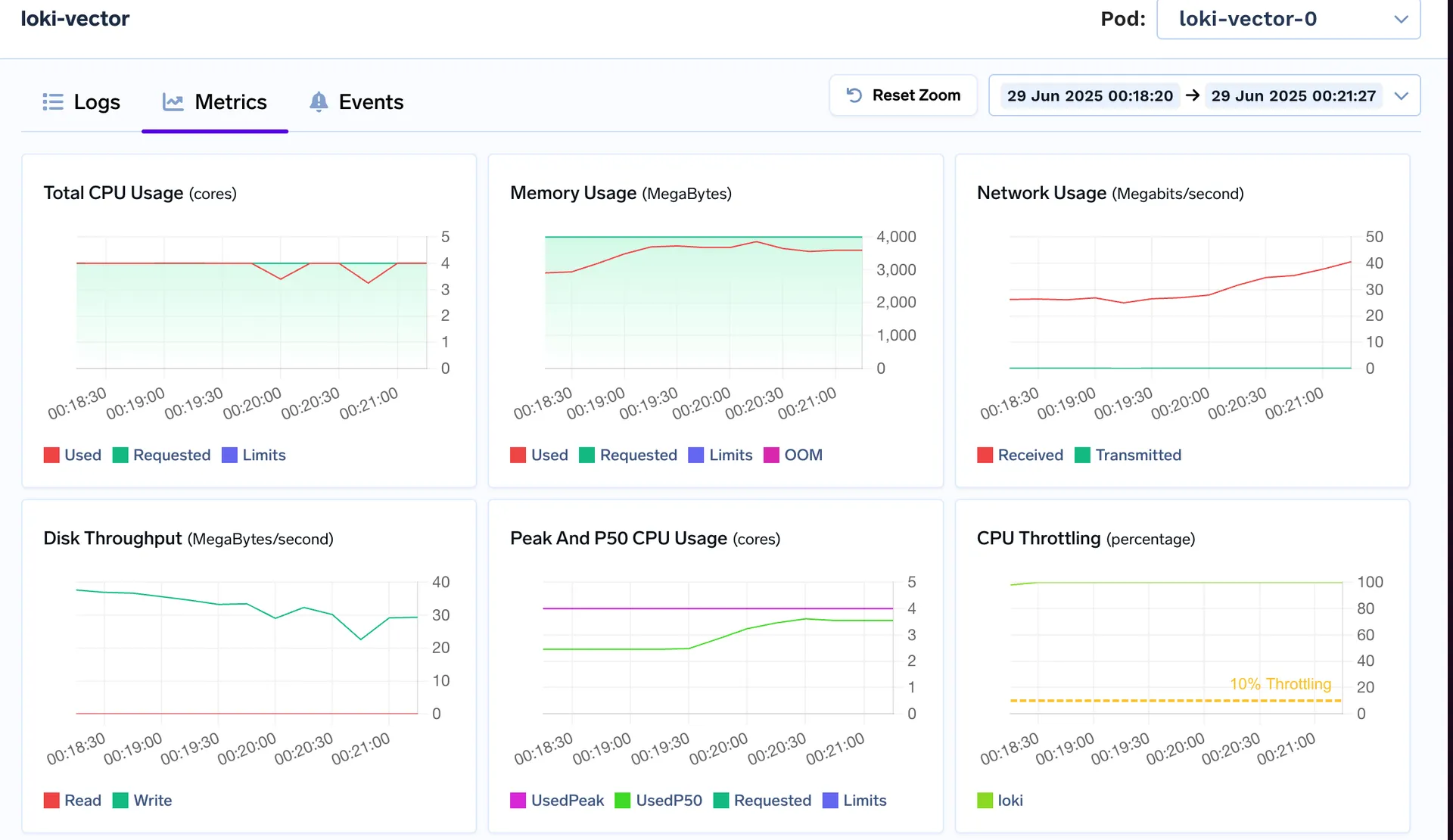
Loki alcanza un máximo de 3 a 4 vCPU, se acerca a su límite de 8 GiB y muestra una aceleración bajo la misma carga de trabajo
Logos de Victoria:
👉 Conclusión clave: VictoriaLogs entregado Velocidad de ingestión 3 veces mayor mientras consume 72% menos de CPU y 87% menos de memoria comparado con Loki.
VictoriaLogs se mantiene cómodamente por debajo de sus límites de 4 vCPU y 8 GiB incluso durante las ráfagas de ingestión
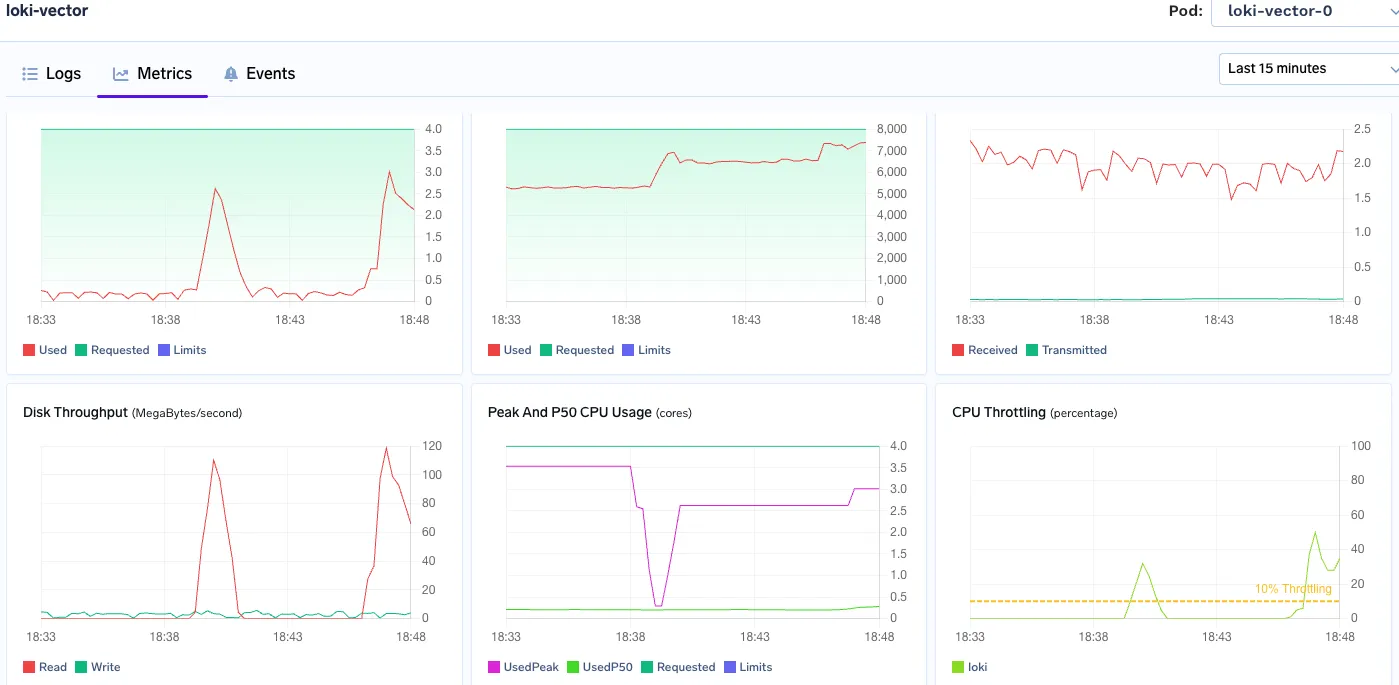
Memoria utilizada: uso constante de 6 a 7 GB de RAM
Pico de CPU: 3 vCPU
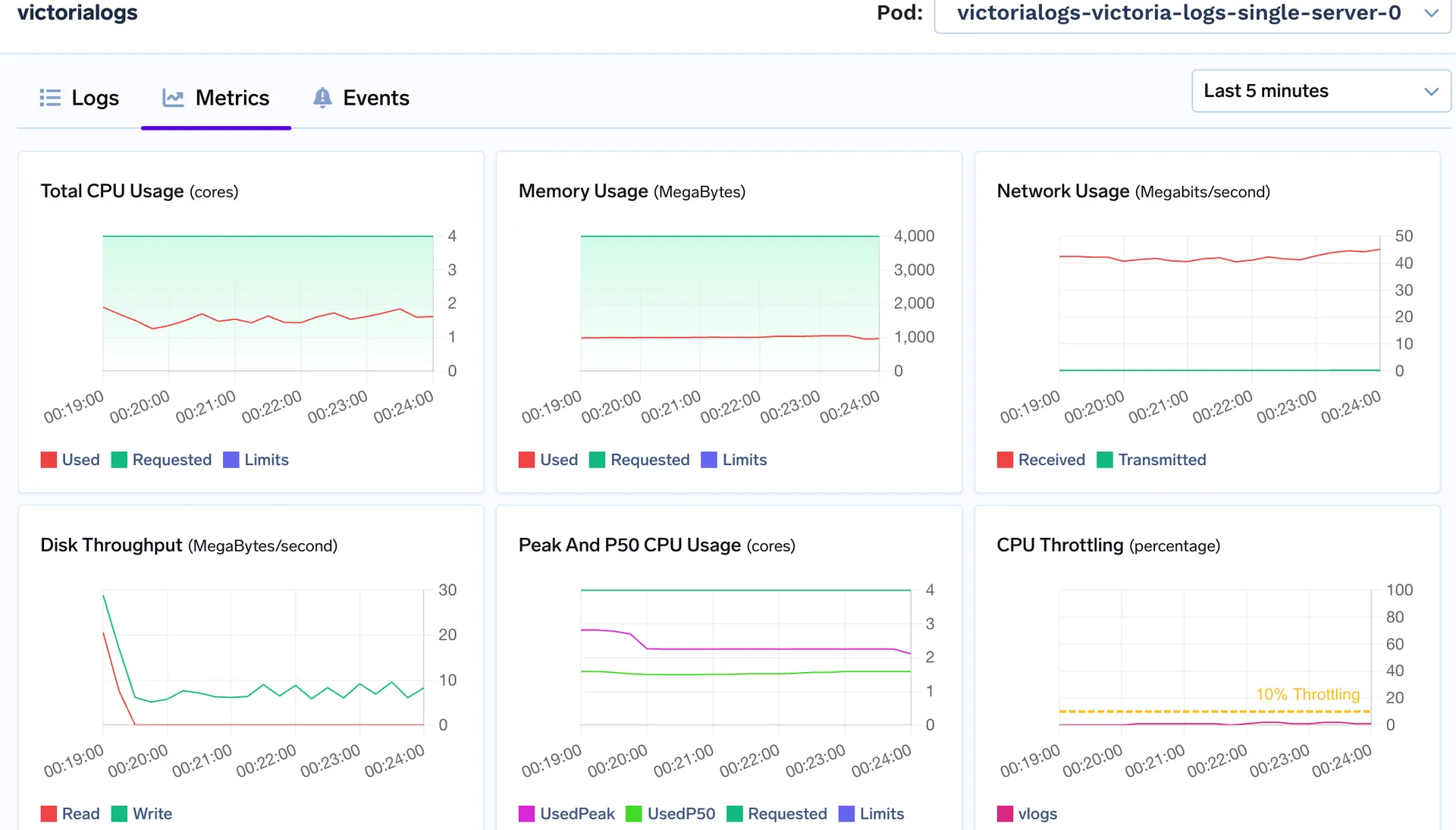
Logos de Victoria
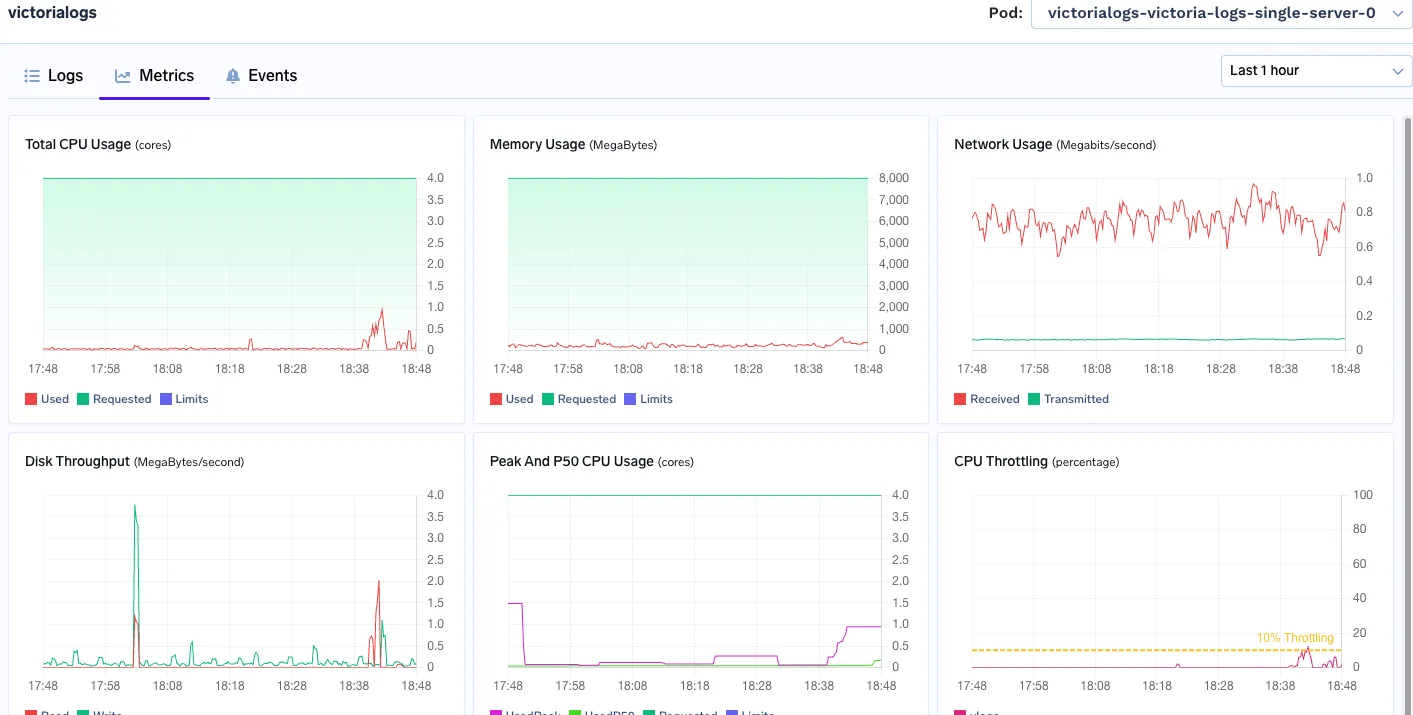
Memoria utilizada: 800 MB - 900 MB
Uso máximo de CPU: 1.1 vCPU
Las consultas eran similares, con límites aleatorios y rangos de tiempo aleatorios, para garantizar ráfagas de caché.
Registros Victoria
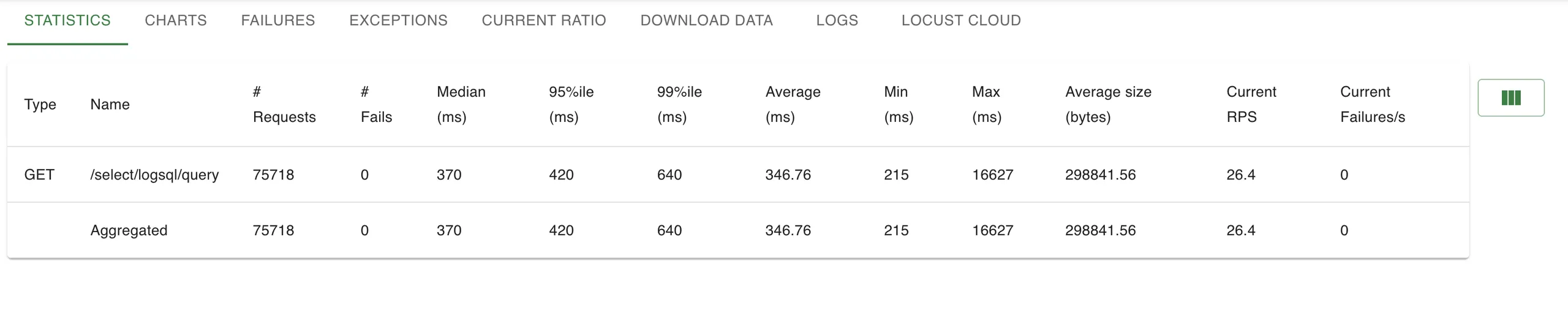
Loki

📌 A pesar del manejo RPS un 36% más alto, VictoriaLogs mostró latencias de p 95% y de cola más bajas, lo que demuestra que su modelo de indexación se mantiene bajo presión con 3,6x Más rápido Hasta 99% de archivo
Esta prueba reforzó nuestra decisión: VictoriaLogs no solo es más rápida en teoría, sino que se adapta mejor bajo presión a cargas de trabajo similares a las de producción.
En resumen: para un caso de uso con mucho registro y centrado en las búsquedas, VictoriaLogs nos permite responder a las preguntas en segundos en lugar de minutos y, al mismo tiempo, reducir los costos de infraestructura.
Para los perfiles de carga de trabajo con una gran cantidad de búsquedas de texto ad hoc, VictoriaLogs proporcionó orden de magnitud consultas más rápidas y ahorro de costes de material. Loki sigue siendo una opción excelente cuando predominan la estrecha integración de Grafana y las consultas que dan prioridad a las etiquetas, pero VictoriaLogs es ahora nuestra opción predeterminada para clústeres centrados en desarrolladores con un alto nivel de consumo.
La diferencia clave entre victorialogs y loki es la indexación avanzada por token y el almacenamiento en columnas de Victorialogs. Esto permite un rendimiento de consultas mucho más rápido y un uso de recursos significativamente menor en comparación con la indexación de solo etiquetas de Loki, que a menudo resulta en búsquedas de escaneo completo más lentas y en una mayor sobrecarga operativa para la administración de registros.
Sí, en nuestra rigurosa evaluación comparativa, VictoriaLogs demostró una velocidad superior en comparación con Loki. En las comparaciones entre Victorialogs y Loki, VictoriaLogs redujo las latencias de las consultas en un 94% y logró tiempos de búsqueda 12 veces más rápidos para consultas complejas. También ofrecía un rendimiento de ingestión 3 veces mayor, lo que lo hacía considerablemente más eficiente.
Al evaluar victorialogs frente a loki, es útil conocer los detalles de configuración. Por lo general, VictoriaLogs usa el puerto 8428 para su API HTTP predeterminada y para raspar los puntos finales. Este puerto permite el acceso a la base de datos de registro y la interacción con ella. Si bien nuestro blog se centra en el rendimiento, comprender los aspectos básicos de la implementación, como el puerto predeterminado, es crucial para la configuración del sistema.
En los puntos de referencia que comparan victorialogs con loki, VictoriaLogs ofreció un rendimiento superior. Logró una reducción del 94% en las latencias de las consultas, redujo el uso del almacenamiento en aproximadamente un 40% y consumió menos del 50% de la CPU y la RAM asignadas. VictoriaLogs también mostró un rendimiento de ingestión 3 veces mayor, lo que la hizo altamente eficiente.
En nuestro punto de referencia de victorialogs contra loki, VictoriaLogs demostró ser superior. Redujo la latencia de las consultas en un 94%, redujo el almacenamiento en un 40% y utilizó más de un 50% menos de CPU/RAM. La empresa estadounidense TrueFoundry eligió VictoriaLogs por su rendimiento y eficiencia mejorados en la gestión de las cargas de trabajo de aprendizaje automático.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada







.png)

.webp)
.webp)
.webp)



.webp)
.webp)


