

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Nos complace anunciar que TrueFoundry ha desarrollado una solución potente, pero fácil de usar, para la implementación y el ajuste del modelo de lenguaje grande (LLM) a través de nuestro Catálogo de modelos. Nuestro objetivo es ayudar a las empresas a autohospedar sus LLM de código abierto en Kuberenetes, lo que hace que los costos de inferencia sean 10 veces más baratos con un solo clic. En este blog te mostramos cómo puedes implementar un Dolly-V2-3B modelar y afinar un Pitia-70 M modelar con TrueFoundry.Plataforma TrueFoundry se ha diseñado para admitir modelos de aprendizaje automático y aprendizaje profundo de todo tipo, desde los más simples, como la regresión logística, hasta los modelos más avanzados, como Stable Diffusion. Uno podría pensar: ¿por qué es necesario crear algo nuevo cuando se trata de modelos lingüísticos de gran tamaño?
El enorme tamaño y la complejidad de estos modelos plantean importantes desafíos a la hora de implementarlos en aplicaciones del mundo real. Si bien la plataforma TrueFoundry ya permitía implementar modelos de todos los tamaños a escala, nos dimos cuenta de que había más optimizaciones (coste+tiempo) y mejoras en la experiencia del usuario que podíamos hacer con estos modelos.
Es innegable que los grandes modelos lingüísticos (LLM), como ChatGPT, han despertado un gran revuelo en el campo de la inteligencia artificial.
Sin embargo, después de haber hablado con más de 50 empresas que ya están empezando a ponerlo en producción, el valor que ya está creando es inmenso. Creemos que el uso de los LLM solo se expandirá a medida que las personas descubran nuevos casos de uso todos los días.
Crear un caso de uso de prueba de concepto con modelos de lenguaje de gran tamaño y API de OpenAI es fácil, pero cuando se empieza a pensar en la producción 🚀, entran en juego muchas más consideraciones.
Para la mayoría de las empresas, desarrollar la capacidad de ingeniería necesaria para gestionar la compleja infraestructura de GPU a fin de prestar servicios de LLM de forma fiable es difícil y lleva mucho tiempo. Además, la mayoría de las empresas desean modelos específicos que funcionen mejor en su caso de uso, para lo cual necesitan ajustar estos modelos con precisión. Esto puede ser un desafío técnico y costoso.
Nuestra postura sobre el futuro de los LLM es que los modelos de código abierto van a ser el camino a seguir. Lea más sobre nuestros puntos de vista sobre el tema aquí. Hemos decidido aprovechar esta comunidad de innovadores que está innovando rápidamente y ayudar a las empresas a utilizar todo el valor de estos LLM de código abierto en sus organizaciones.
TrueFoundry quiere que nuestros socios puedan aprovechar todas las ventajas que las LLM de código abierto, adaptadas a su caso de uso específico, pueden tener en sus organizaciones:
Sin embargo, administrar e implementar modelos de código abierto en su propia infraestructura no es una tarea fácil. Si bien implementación de LLM local ofrece un control de datos inigualable, una preparación para el cumplimiento y una rentabilidad a largo plazo, y requiere una amplia experiencia en la orquestación de GPU, la administración de Kubernetes y la optimización de modelos.
Pero imagínese si fuera tan fácil como conectar sus datos y hacer unos pocos clics.
Entendemos los desafíos a los que se enfrentan las empresas al hacer la transición de la prueba de concepto de LLM a la producción. Nuestro objetivo es construir la capa que haga que este proceso sea muy fácil para nuestros socios. Así es como lo hacemos:
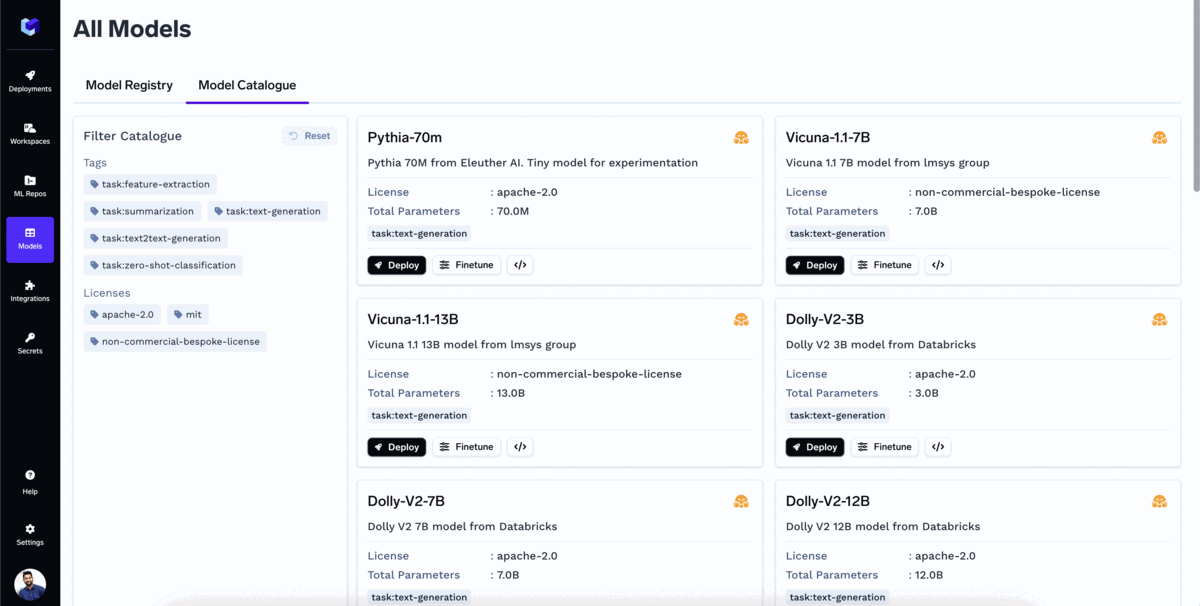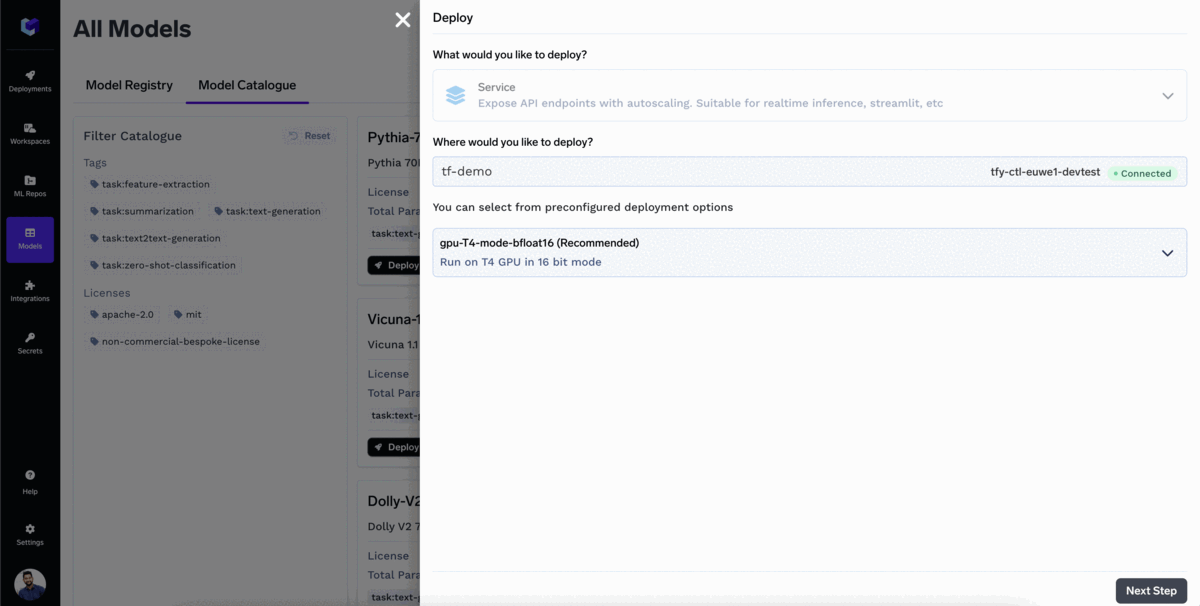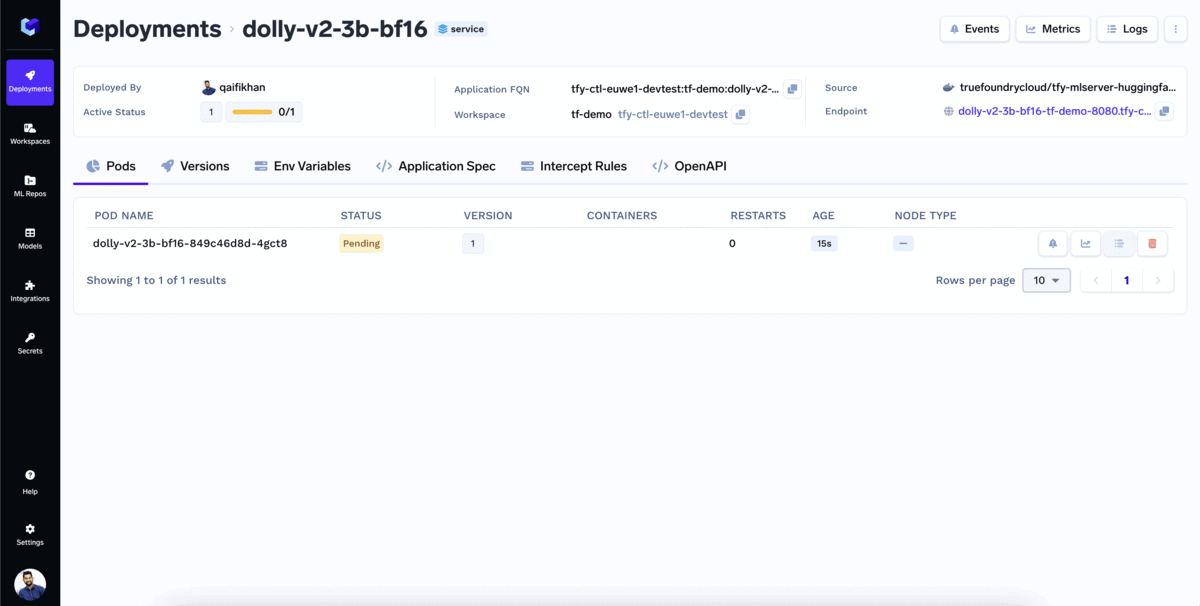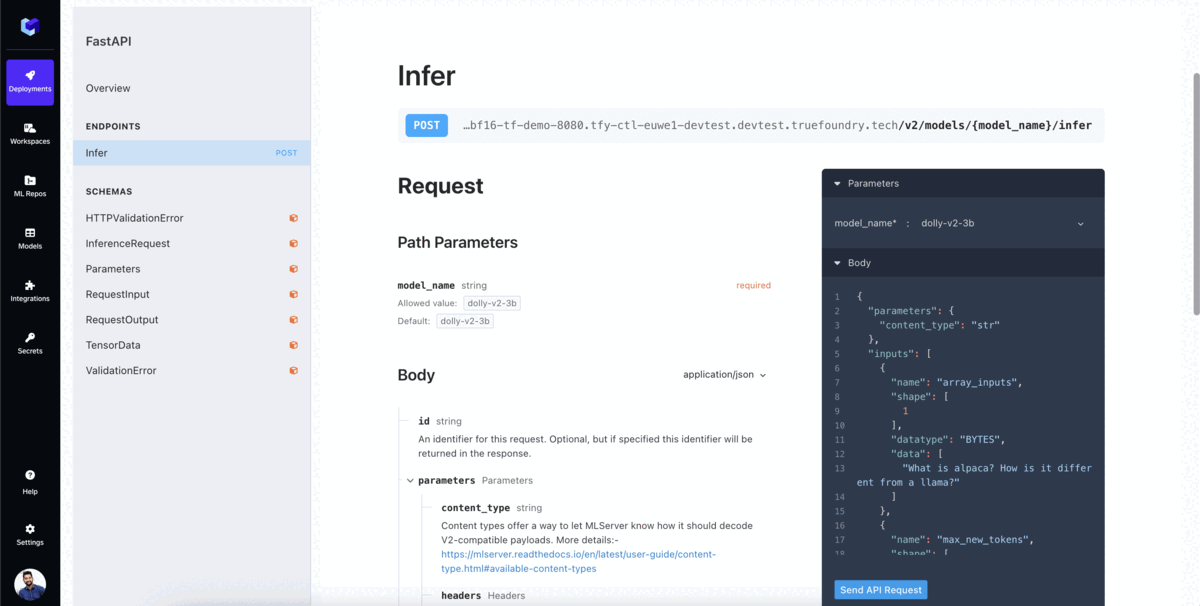
True Foundry Catálogo de modelos es un repositorio de todos los populares modelos de lenguaje grande (LLM) de código abierto que se pueden implementar con un solo clic. El usuario también puede ajustar el modelo directamente desde el catálogo de modelos.
El catálogo ya es compatible con la mayoría de los modelos populares, y cada día añadimos soporte para más. Algunos de los modelos más populares que ya puede implementar en su propia nube son:
Y muchos más...
Estamos obsesionados con que las empresas puedan realizar envíos el primer día. Para que esto sea posible, estos son los principios en los que basamos nuestras capacidades de LLM:
ℹ️
Para obtener un recorrido detallado de los flujos de entrenamiento y ajuste en la interfaz de usuario, consulte este vídeo de YouTube
¡Implementar tus LLM es tan fácil como hacer clic tres veces!
🚀
¡Su modelo ya está desplegado!
Iniciar la inferencia con el punto final de la API modelo. TrueFoundry le proporciona la Interfaz OpenAPI para probar el modelo y el código de muestra para llamar al modelo en las aplicaciones.
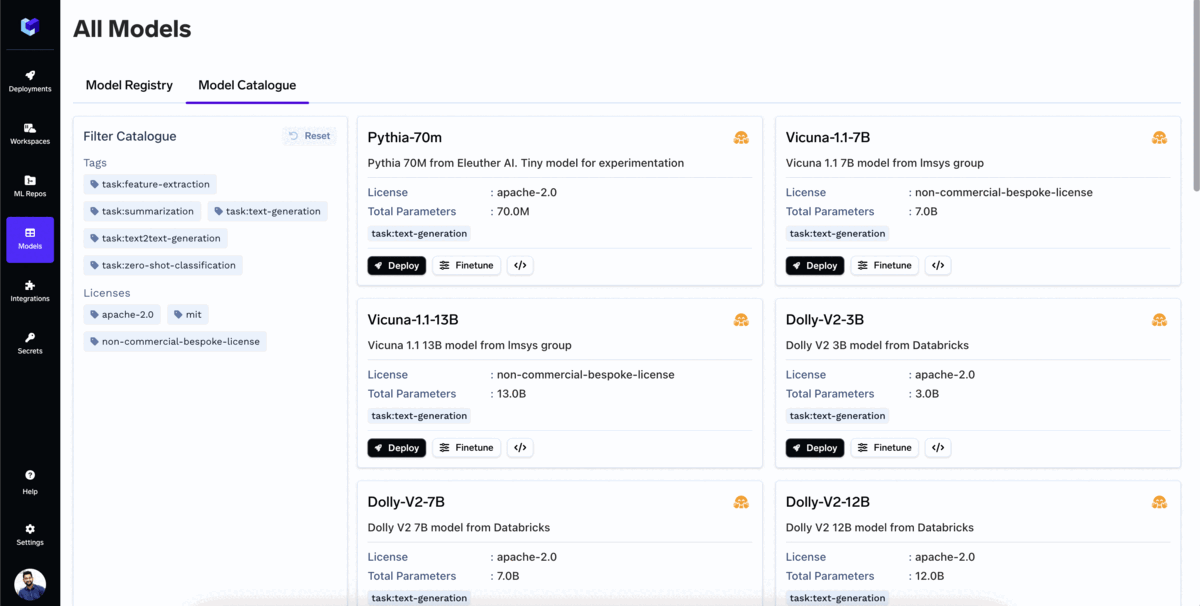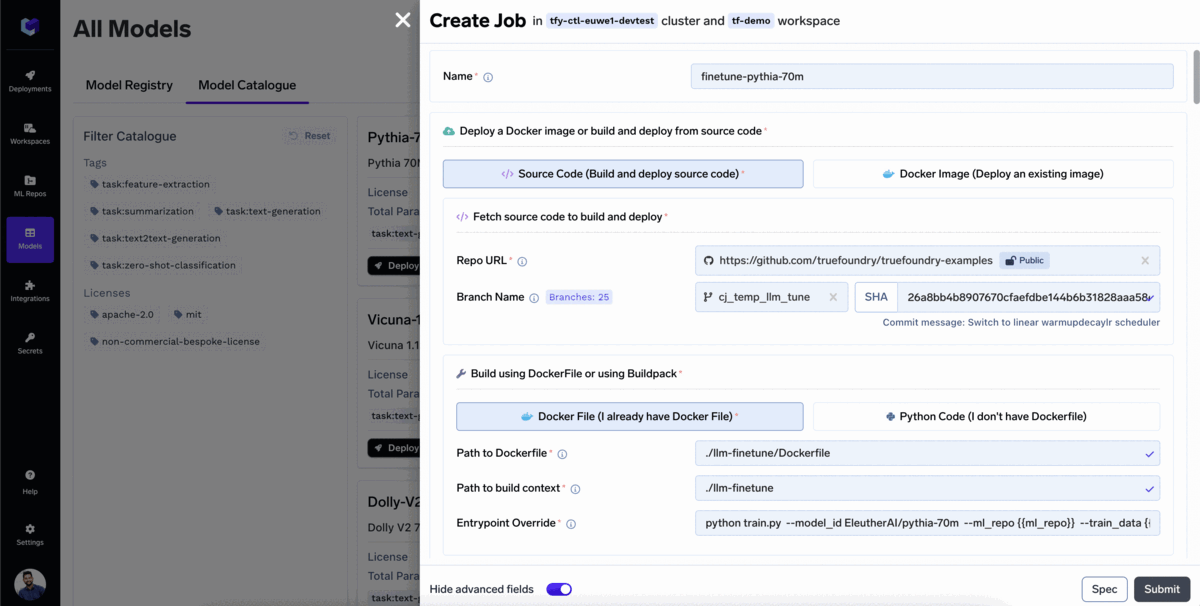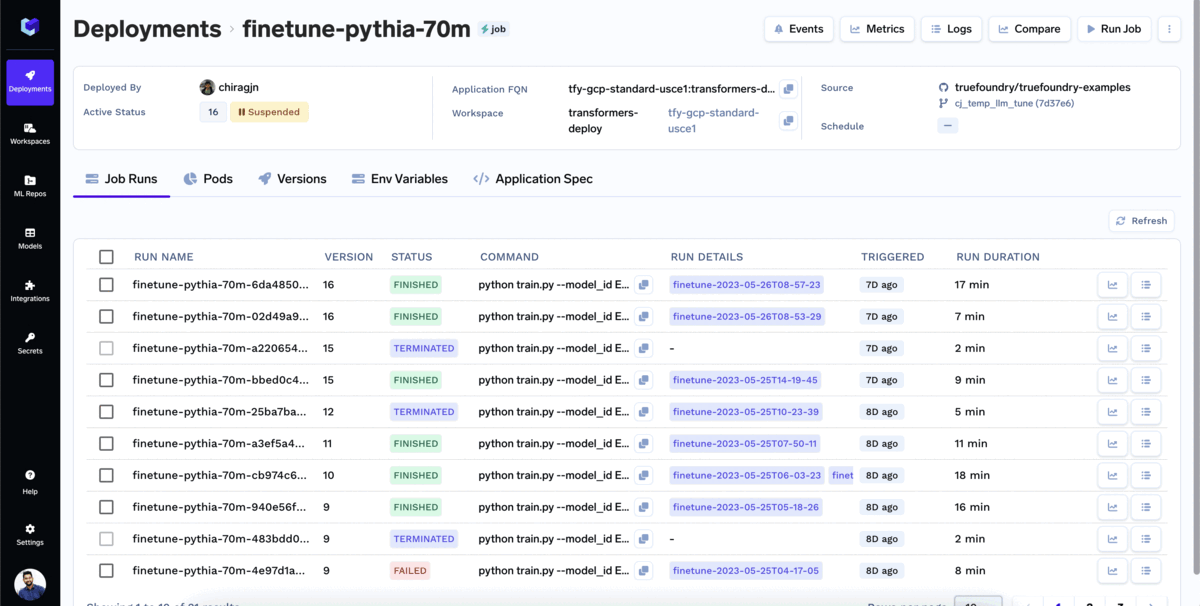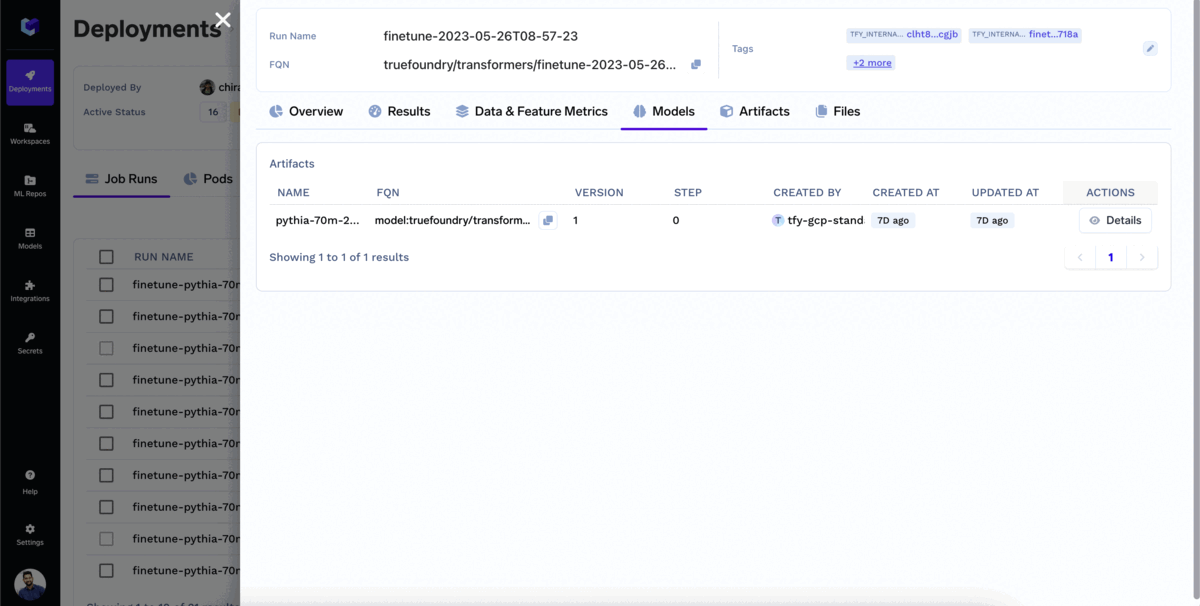
La mayoría de las empresas querrían usar modelos ajustados para su caso de uso específico. Para ajustar un modelo con TrueFoundry:
🚀
¡El modelo ha empezado a afinarse!
Puedes supervisar el ajuste fino a medida que avanza. En la pestaña de ejecución del trabajo, puedes ver toda la información relevante asociada al trabajo de formación, como las métricas de pérdidas, las curvas de entrenamiento y los resultados de las evaluaciones. Esto le permite realizar un seguimiento del proceso de ajuste y tomar decisiones informadas en función del desempeño del trabajo.
Este es solo el comienzo de nuestro viaje con los modelos lingüísticos grandes (LLM) y la IA generativa. Estamos planeando construir mucho más en los próximos días, ¡y os mantendremos informados!
Todavía estamos aprendiendo sobre este tema, como todos los demás. En caso de que esté intentando utilizar modelos lingüísticos extensos en su organización, nos encantaría charlar e intercambiar notas.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


