





October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: May 19, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
In this blog, we will introduce you to training machine learning models on the TrueFoundry Platform. We will discuss how we can run training jobs on TrueFoundry. We will also see how you can perform hyperparameter tuning easily for your machine-learning models, and run your jobs on GPUs.
Let's first start with a problem statement, say we want to see how the diabetes disease will progress in a patient based on various features like age, BMI, blood pressure, etc. In this blog, we will train the Diabetes Dataset machine-learning model in scikit-learn.
Speaking of training machine-learning models, there are several ways to do so like training locally on your machine, training in Jupyter Notebooks, etc. However, the training process might require more resources than what is available on a local machine.
This is where TrueFoundry's Jobs enables you to deploy the training code to run on a remote machine and you can track the logs and metrics.
Note: While we are using this diabetes dataset, the instructions mentioned in this blog apply to other machine-learning / deep-learning models as well.
Jobs provide a way to run short-lived, parallel, or sequential batch tasks within the cluster. Jobs are designed to run to completion, rather than being long-running services or continuously running applications. Once a job is completed, compute and memory resources are released, hence we don't incur any extra cost.
As said before, we will use the Diabetes Dataset in scikit-learn. The dataset contains 442 samples (patients) and 10 features, which are all numeric. The features represent various factors that can affect the progression of diabetes in patients. The target variable is also numeric and represents a quantitative measure of disease progression one year after baseline for each patient.
Before we proceed to train machine-learning models, let's go through the setup instructions:
Go to the TrueFoundry Dashboard and create an account. As soon as you log in, you will be prompted to create a workspace. You would be deploying your jobs in this workspace.

Once you have created your workspace, go ahead and create an ML Repository from the dashboard.
An ML Repository is a collection of runs, models, and artifacts which represents a Machine Learning project. You can think of it like a git repository except that it houses artifacts, models and metadata. All the access controls can be configured on the level of ml-repo.
Once the ML Repo is created, go to workspaces and edit your workspace and enable 'ML Repo Access'. Click on 'Add ML Repo Access' to add your ML Repo to this workspace. This will grant the job running in the workspace to write and read from the ML repo.
pip install servicefoundry
--host: Pass your TrueFoundry Dashboard URL here
sfy login --host <YOUR-HOST-URL-HERE>
Once we have completed the above setup instructions, we can move forward with the implementation section.
Directory Structure
In this blog, we will adhere to the following directory structure where:
❯ tree
.
├── deploy.py
├── requirements.txt
└── train.py
Now let's go over the diabetes model training code:
Model Training Steps
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.compose import TransformedTargetRegressor
from sklearn.preprocessing import QuantileTransformer
from sklearn.svm import SVR
X, y = load_diabetes(as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
regressor = SVR(kernel=kernel)
model = TransformedTargetRegressor(
regressor=regressor,
transformer=QuantileTransformer(n_quantiles=n_quantiles, output_distribution="normal"),
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
Model Training Complete Code
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.compose import TransformedTargetRegressor
from sklearn.preprocessing import QuantileTransformer
from sklearn.svm import SVR
def train(kernel: str, n_quantiles: int):
# load the dataset and create train and test sets
X, y = load_diabetes(as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# initialize the model
regressor = SVR(kernel=kernel)
model = TransformedTargetRegressor(
regressor=regressor,
transformer=QuantileTransformer(n_quantiles=n_quantiles, output_distribution="normal"),
)
# train and test model
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}"
return regressor, model, X_test, y_test
Ahora que hemos visto el código para entrenar un modelo de aprendizaje automático, podemos seguir adelante y aprender cómo guardar (o registrar) dichos modelos para usarlos en el futuro.
Un modelo se compone de un archivo modelo y algunos metadatos. Cada modelo puede tener varias versiones. Podemos serializar, guardar y versionar automáticamente los objetos del modelo mediante el guardar metadatos de modelos y los siguientes son los pasos para hacerlo:
Pasos de registro de modelos
importar mlfoundry
run = mlfoundry.get_client () .create_run (ml_repo=ml_repo, run_name="SVR-with-QT»)
Una ejecución representa un único experimento que, en el contexto del aprendizaje automático, es un modelo específico (por ejemplo, regresión logística), con un conjunto fijo de hiperparámetros. Las métricas y los parámetros (se detallan a continuación) se registran todos en una ejecución específica.
ejecutar.log_params (regressor.get_params ())
run.log_metrics ({"puntuación»: model.score (x_test, y_test)})
model_version = run.log_model (name="diabetes-regression», model=model, framework="sklearn»)
print («model_version =», model_version.version, «model_fqn =», model_version.model_fqn)
Cada modelo registrado genera una nueva versión asociada al nombre y vinculado a la ejecución actual. Se pueden registrar varias versiones del modelo como versiones independientes en el mismo nombre.
Código completo de registro de modelos
importar mlfoundry
def save_model_metadata (regresor, modelo, X_test, y_test, ml_repo):
# crear una ejecución en ml_repo de truefoundry
run = mlfoundry.get_client () .create_run (ml_repo=ml_repo, run_name="SVR-with-QT»)
# registrar los hiperparámetros del modelo
ejecutar.log_params (regressor.get_params ())
# registrar las métricas del modelo
run.log_metrics ({"puntuación»: model.score (x_test, y_test)})
# registrar el modelo
model_version = run.log_model (name="diabetes-regression», model=model, framework="sklearn»)
print («model_version =», model_version.version, «model_fqn =», model_version.model_fqn)
Ahora que hemos visto el proceso de entrenamiento y registro de modelos, podemos compilarlo en un solo train.py archivo. El contenido final del train.py el archivo debería tener este aspecto:
train.py
# declaraciones de importación necesarias para ambas funciones
tren def (kernel, n_quantiles):
...
def save_model_metadata (regresor, modelo, X_test, y_test, ml_repo):
...
regresor, modelo, x_test, y_test = train (kernel="linear», n_quantiles=100)
save_model_metadata (regressor, model, x_test, y_test, ML_REPO="EL NOMBRE DE SU REPOSITORIO DE ML»)
Esto completa nuestro código para el entrenamiento y el registro de modelos. Ahora tenemos que implementar el código de entrenamiento modelo como un trabajo. El deploy.py contiene el código para implementar el código de entrenamiento modelo anterior, como se muestra a continuación:
deploy.py
de servicefoundry import Build, Job, PythonBuild, LocalSource
# definir las especificaciones del trabajo
trabajo = Trabajo (
name="diabetes-train-job»,
image=construir (
build_spec=PythonBuild (command="python train.py «, requirements_path=» requirements.txt «),
BUILD_SOURCE=LocalSource (LOCAL_BUILD=false)
),
)
deployment = job.deploy (WORKSPACE_FQN="SU FQN DE WORKSPACE AQUÍ»)
El requirements.txt debe contener los siguientes paquetes:
requirements.txt
pandas == 1.3.5
scikit-learn==1.2.1
mlfoundry>=0.7.2, <0.8.0
En lo anterior deploy.py código, se implementa un trabajo que muestra la puntuación de precisión del modelo entrenado en los registros cuando se invoca. También registra el modelo de aprendizaje automático entrenado. Para ello, se crea un objeto de trabajo mediante el ServiceFoundry.Job clase. El nombre del trabajo se mantiene como trabajo de entrenamiento para diabéticos aquí.
NOTA: Asegúrese de reemplazar «EL NOMBRE DE SU REPOSITORIO DE ML» por el nombre de su repositorio de ML en train.py y «TU FQN DE ESPACIO DE TRABAJO AQUÍ» con el FQN de tu espacio de trabajo en deploy.py archivo.
En el train.py archivo, necesitas pasar el Nombre del repositorio ML creaste para guardar metadatos de modelos () función. En el deploy.py archivo, necesitas pasar FAN del espacio de trabajo que creaste para job.deploy () función. Ahora ejecute el siguiente comando para implementar el trabajo:
python deploy.py
Después de implementar el trabajo de capacitación, vaya a la subsección «Trabajos» de la sección «Implementaciones», que debería tener un aspecto similar al siguiente:
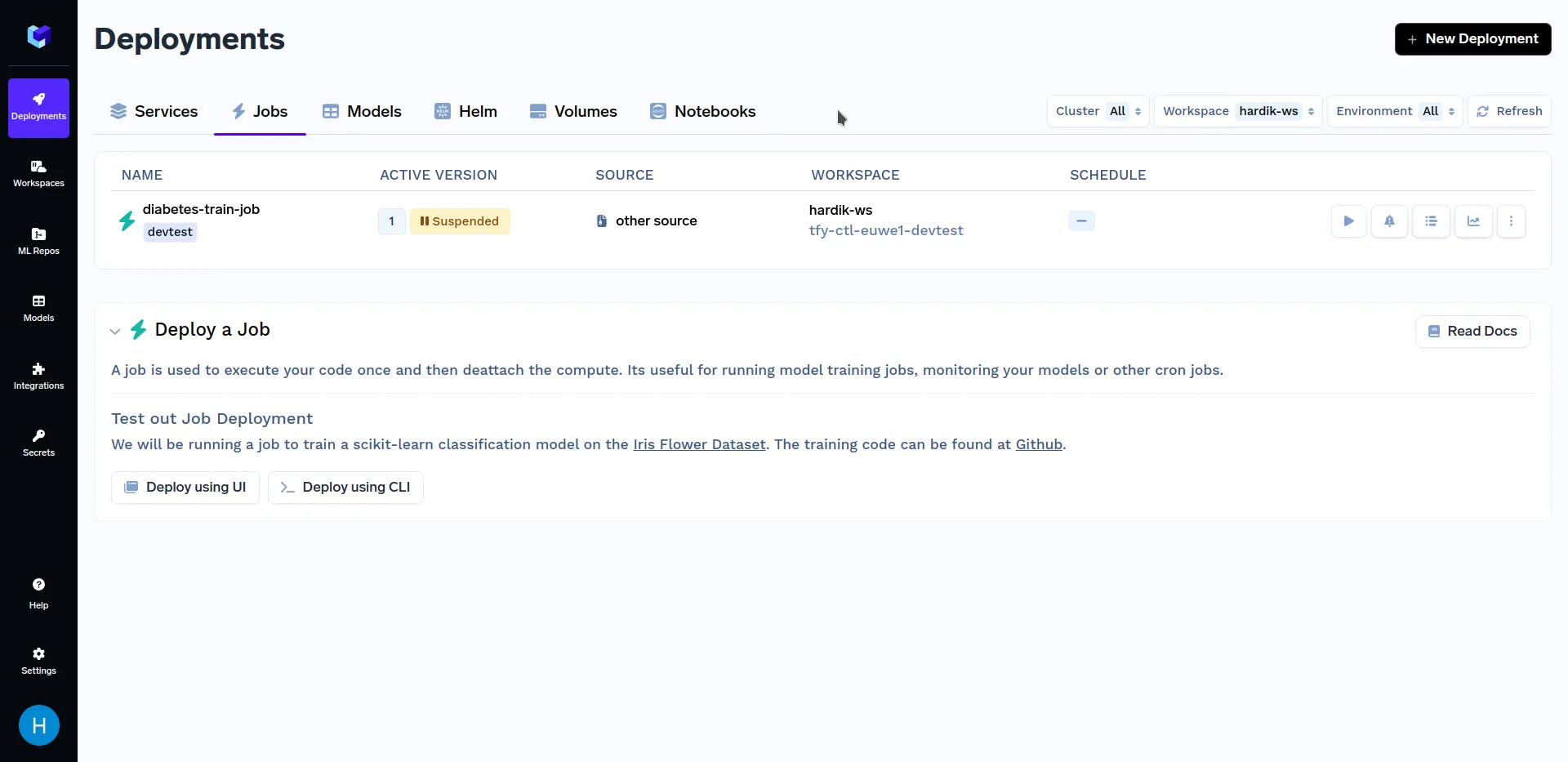
Ahora que hemos terminado de implementar nuestro trabajo, queremos activarlo. Puede hacerlo utilizando cualquiera de nuestros SDK de Python o el Panel de control de TrueFoundry. En primer lugar, hablaremos sobre la creación de puestos de trabajo desde Panel de control de TrueFoundry. Para obtener más información sobre otros métodos para activar trabajos, consulte el Activación de trabajos desde el SDK de Python sección.
Después de la capacitación anterior, el trabajo tiene terminó de implementarse, vaya a la subsección «Trabajos» de la sección «Implementaciones» y haga clic en «trabajo de entrenamiento para diabéticos»y haga clic en «Ejecutar tarea» para configurar la tarea antes de activarla. Debería tener un aspecto similar al siguiente:
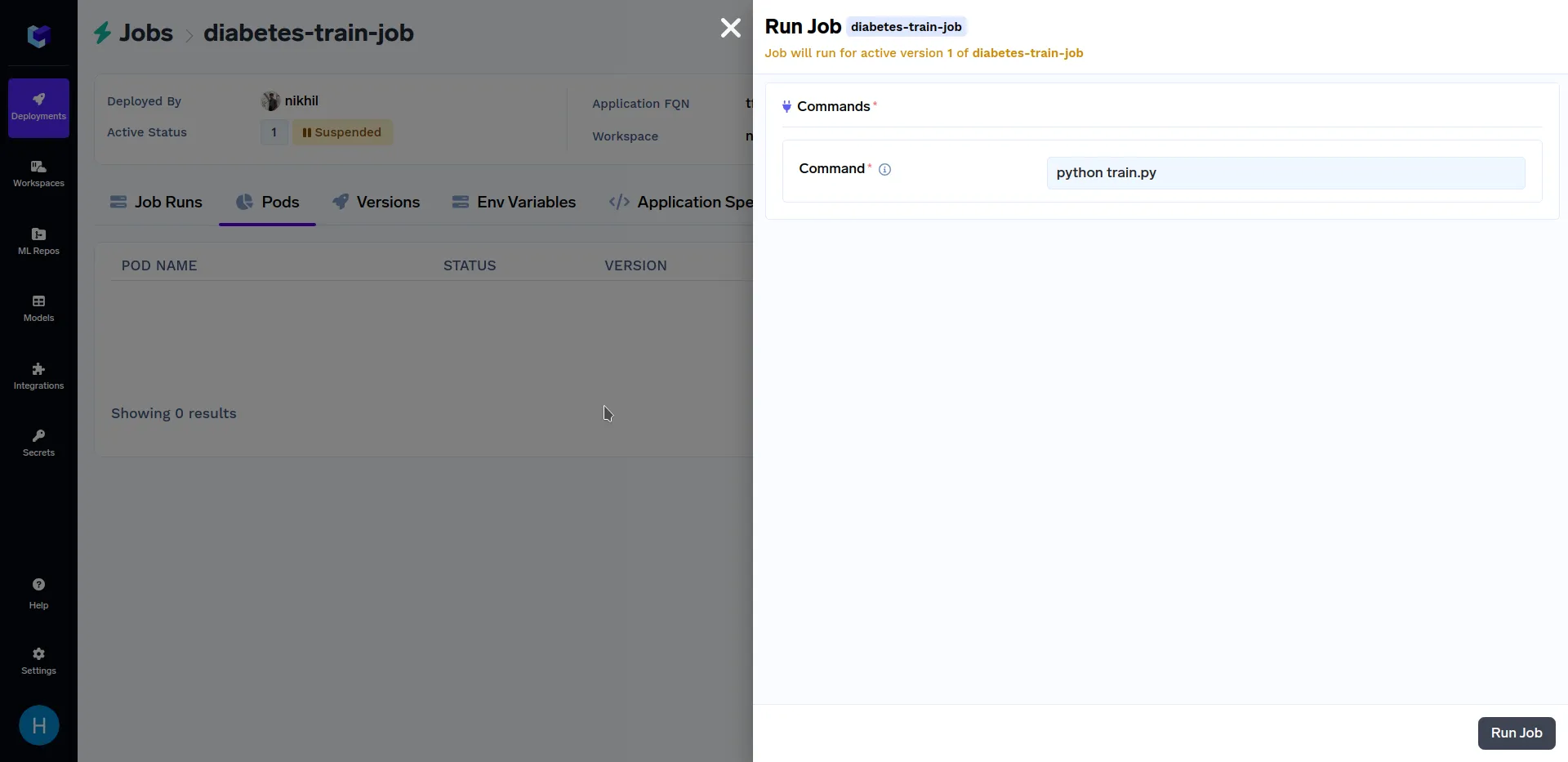
Cuando estés en la pantalla de arriba, haz clic en «Ejecutar trabajo» en la esquina inferior derecha para activar este trabajo. Después de la formación, el trabajo ha terminó de correr, vaya a la subsección «Trabajos» de la sección «Implementaciones» y haga clic en «trabajo de entrenamiento para diabéticos», debería tener un aspecto similar al siguiente:
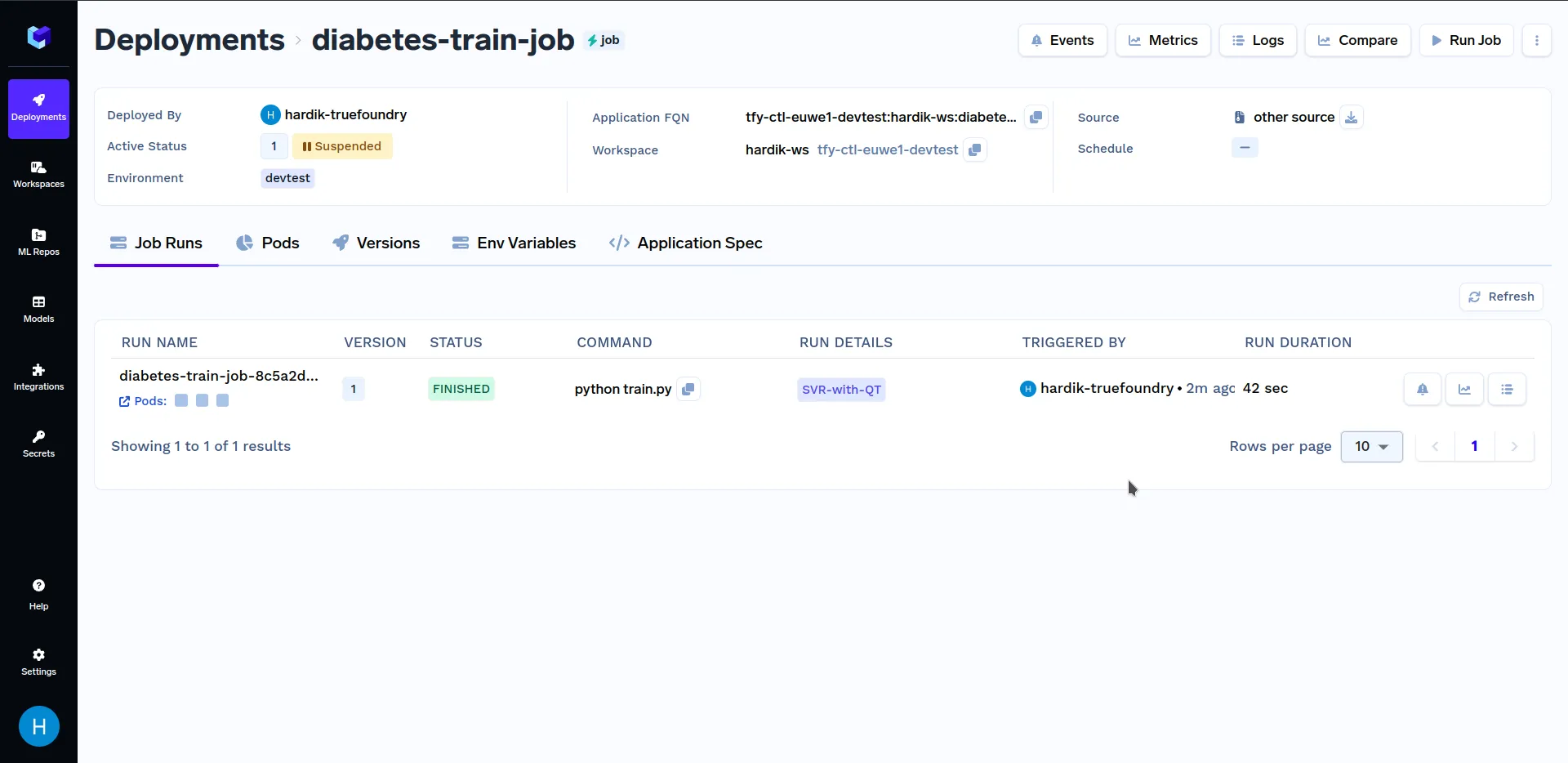
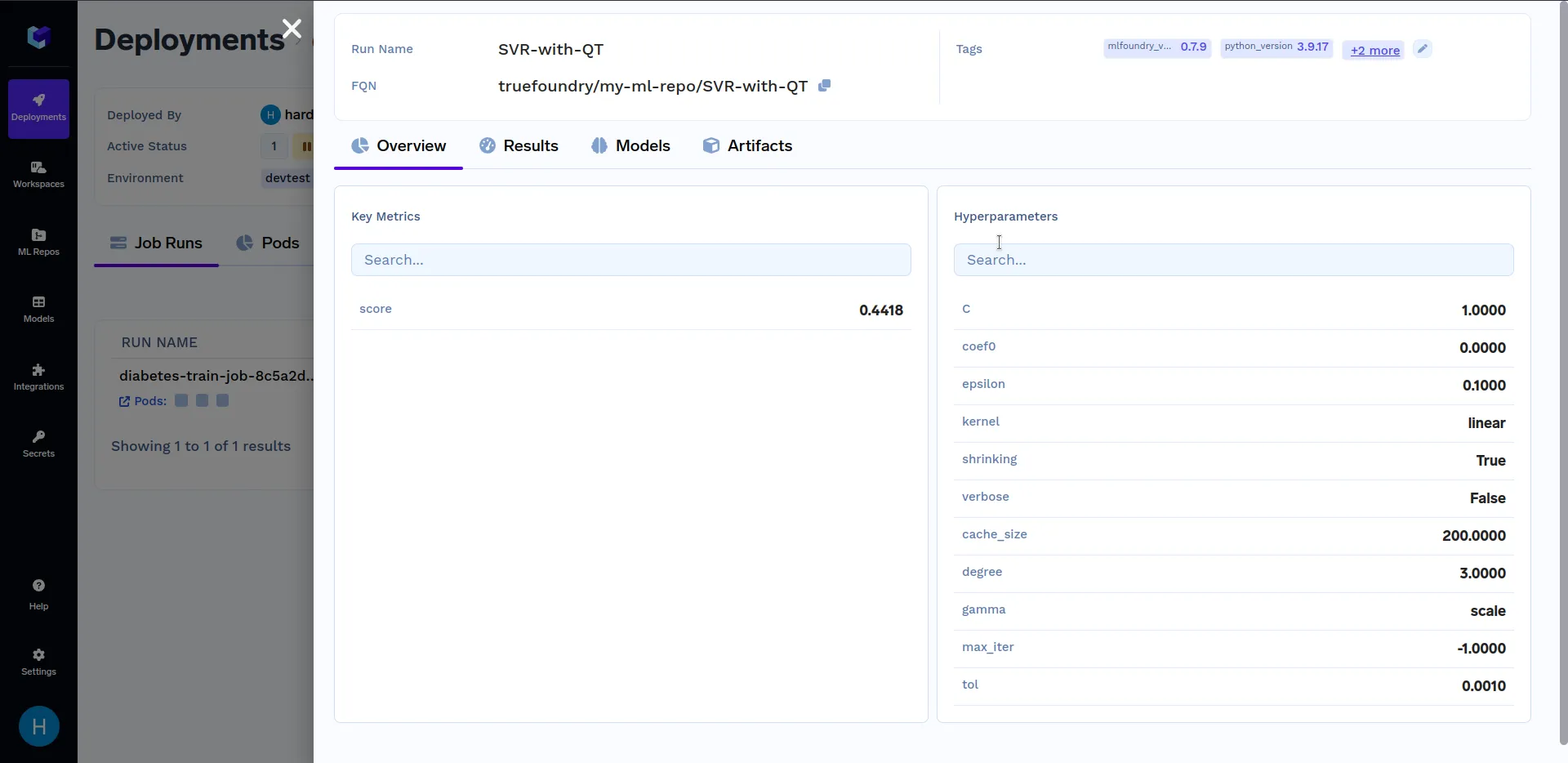
En «Detalles de ejecución», haz clic en «SVR con QT» para ver las métricas e hiperparámetros clave que se registraron en el train.py archivo. Debería tener un aspecto similar al siguiente:
Imagine que tiene tareas de procesamiento de datos o procesamiento por lotes a gran escala en las que ejecutar un solo trabajo con diferentes configuraciones es esencial no solo para agilizar el flujo de trabajo, sino también para garantizar la coherencia en la ejecución del trabajo. En estos casos, un trabajo parametrizado será útil.
Un trabajo parametrizado es un tipo de trabajo que permite crear varias instancias (pods) con diferentes parámetros o entradas. El objetivo principal de un trabajo parametrizado es proporcionar flexibilidad en la ejecución del trabajo mediante la personalización de su comportamiento para diferentes escenarios.
Por ejemplo, un trabajo con el comando como python main.py --n_cuantiles {{n_cuantiles}} es un trabajo parametrizado según sea necesario n_cuantiles como entrada antes de ejecutar. Podemos simplificar el trabajo desplegado anteriormente utilizando parámetros.
Para analizar los argumentos de la línea de comandos, utilizaremos el argparse módulo. El siguiente código muestra el código actualizado para train.py y deploy.py archivos, donde los valores predeterminados de núcleo y n_cuantiles somos lineal y 100 respectivamente:
train.py
importar sistema operativo, argparse
tren def (kernel, n_quantiles):
...
def log_model (regresor, modelo, X_test, y_test, ml_repo):
...
analizador = argParse.ArgumentParser ()
parser.add_argument («--kernel», predeterminado = «lineal», tipo=str)
parser.add_argument («--n_quantiles», predeterminado = 100, tipo = int)
args = parser.parse_args ()
regresor, modelo, x_test, y_test = train (kernel=args.kernel, n_quantiles=args.n_quantiles)
log_model (regresor, modelo, X_test, y_test, ml_repo=os.environ.get («ML_REPO_NAME»))
deploy.py
importar argparse
de servicefoundry import Build, Job, PythonBuild, Param, LocalSource
analizador = argParse.ArgumentParser ()
parser.add_argument («--workspace_fqn», type=str, required=true)
parser.add_argument («--ml_repo», tipo=str, requerido=True)
args = parser.parse_args ()
cmd = «python train.py --kernel {{kernel}} --n_cuantiles {{n_quantiles}}»
# Definir las especificaciones del trabajo
# Solo el comando cambia en el atributo 'image'
trabajo = Trabajo (
...
image=build (build_spec=PythonBuild (comando=cmd,...), ... ),
parámetros = [
Parámetro (name="n_quantiles», predeterminado='100'),
Param (name="kernel», default='linear', description="kernel svm»),
],
env= {«ML_REPO_NAME»: args.ml_repo}
)
despliegue = job.deploy (workspace_fqn=args.workspace_fqn)
NOTA: Asegúrese de reemplazar «EL NOMBRE DE SU REPOSITORIO DE ML» por el nombre de su repositorio de ML y «EL FQN DE SU ESPACIO DE TRABAJO AQUÍ» por el FQN de su espacio de trabajo en el siguiente comando.
Ahora ejecute el siguiente comando para implementar el trabajo parametrizado:
python deploy.py --workspace_fqn «EL VENTILADOR DE TU ESPACIO DE TRABAJO ESTÁ AQUÍ» --ml_repo «EL NOMBRE DE TU REPOSITORIO DE ML»
Alternativamente, se puede ejecutar directamente desde nuestro repositorio de Github.
clon de git https://github.com/truefoundry/truefoundry-examples.git
Ejemplo de trabajo de capacitación en CD
python deploy.py --workspace_fqn «EL VENTILADOR DE TU ESPACIO DE TRABAJO ESTÁ AQUÍ» --ml_repo «EL NOMBRE DE TU REPOSITORIO DE ML»
La versión 2 del trabajo se creará una vez finalizada la implementación. Una vez que el trabajo de formación haya terminó de implementar, el siguiente paso es activar este trabajo.
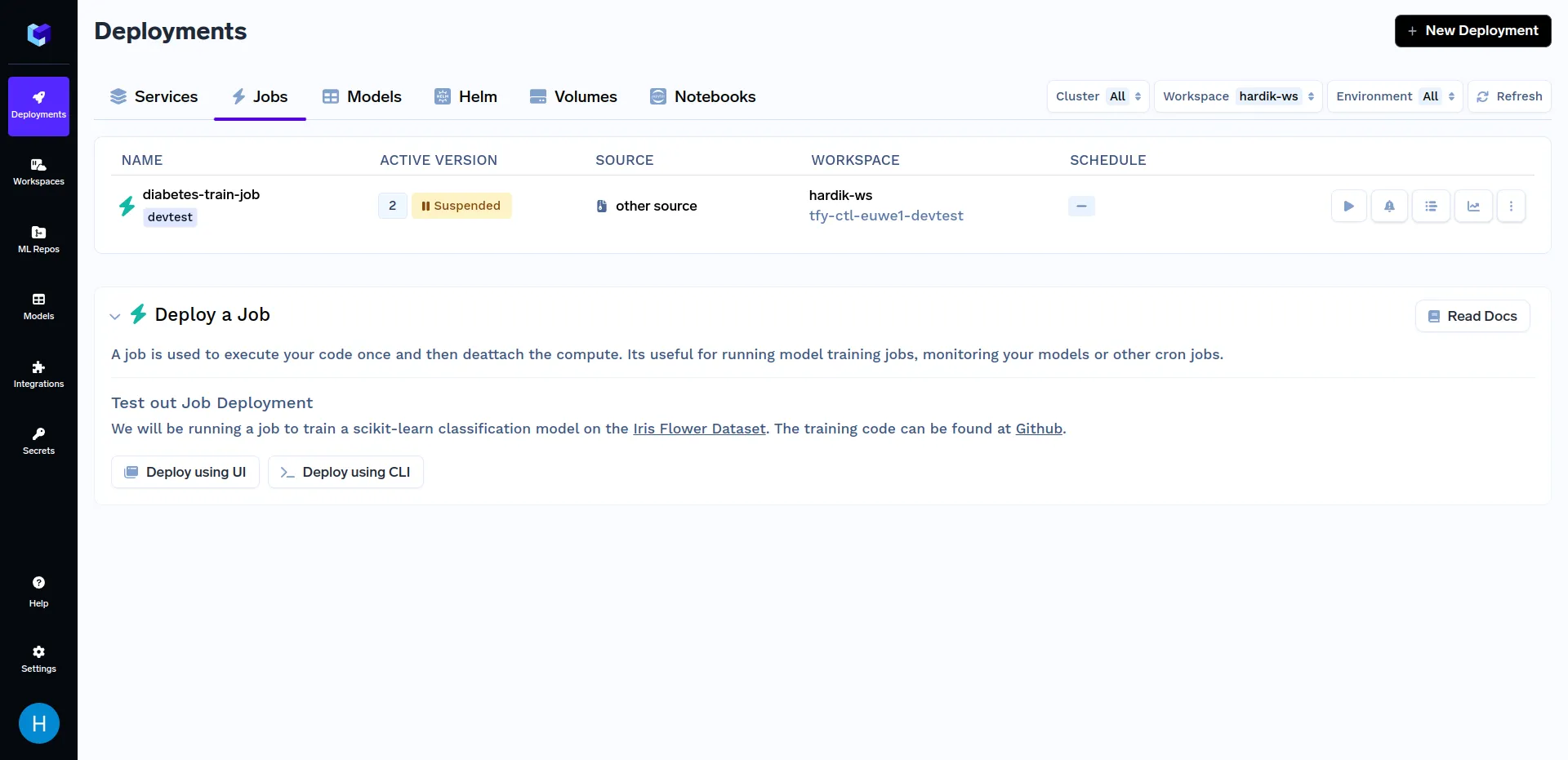
Haga clic en el «trabajo de entrenamiento para diabéticos»y haga clic en «Ejecutar tarea» para configurar la tarea antes de activarla. Ahora puede cambiar el n_cuantiles y núcleo parámetros. Debería tener un aspecto similar al siguiente:
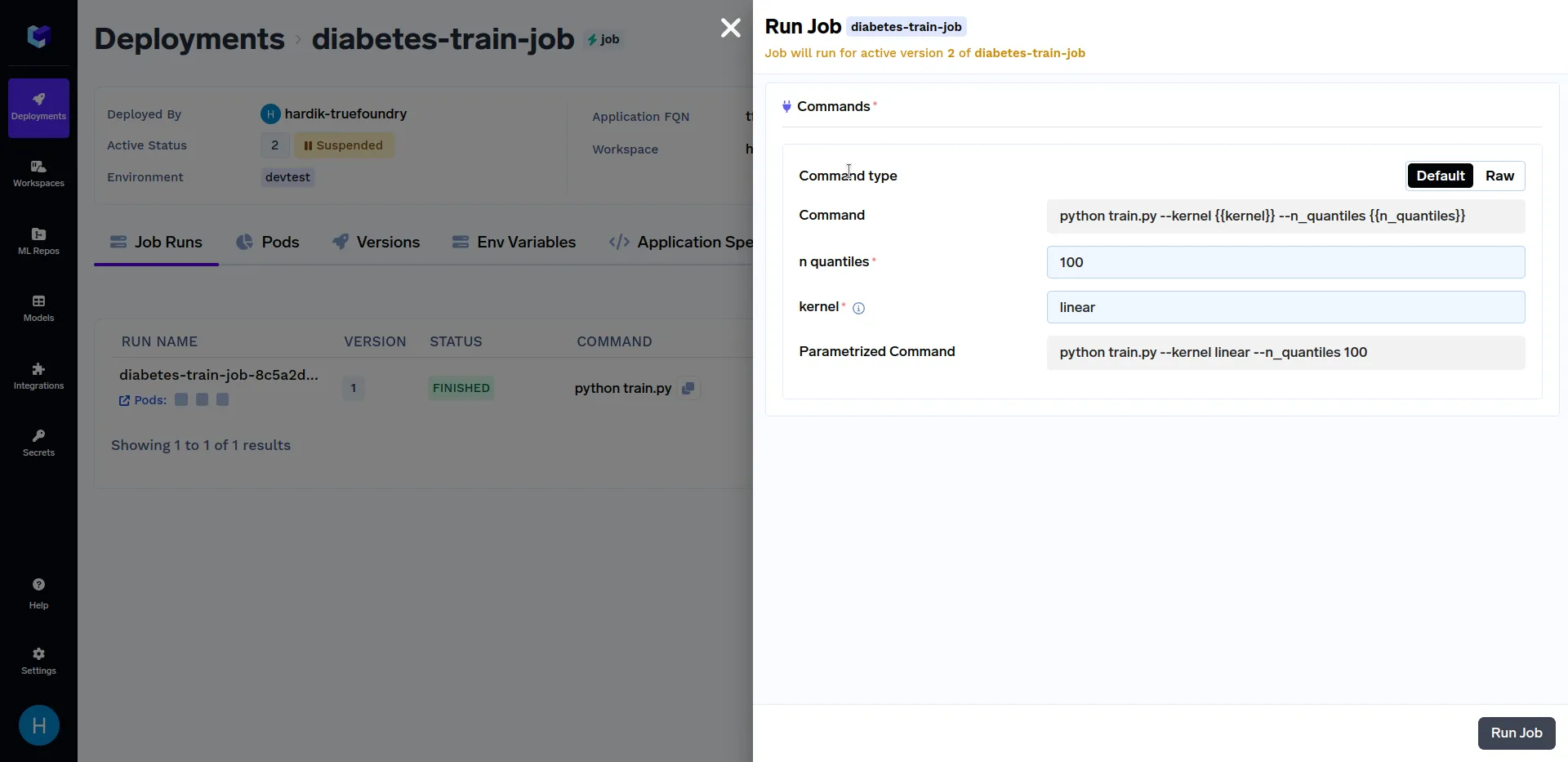
Intente activar las ejecuciones de trabajos con valores diferentes del núcleo parámetro como lineal, sigmoide, polivinílico y rbf. Del mismo modo, puede usar diferentes valores de n_cuantiles parámetros como 50, 80, 100, etc. Varias ejecuciones de trabajo deberían tener un aspecto similar al siguiente:
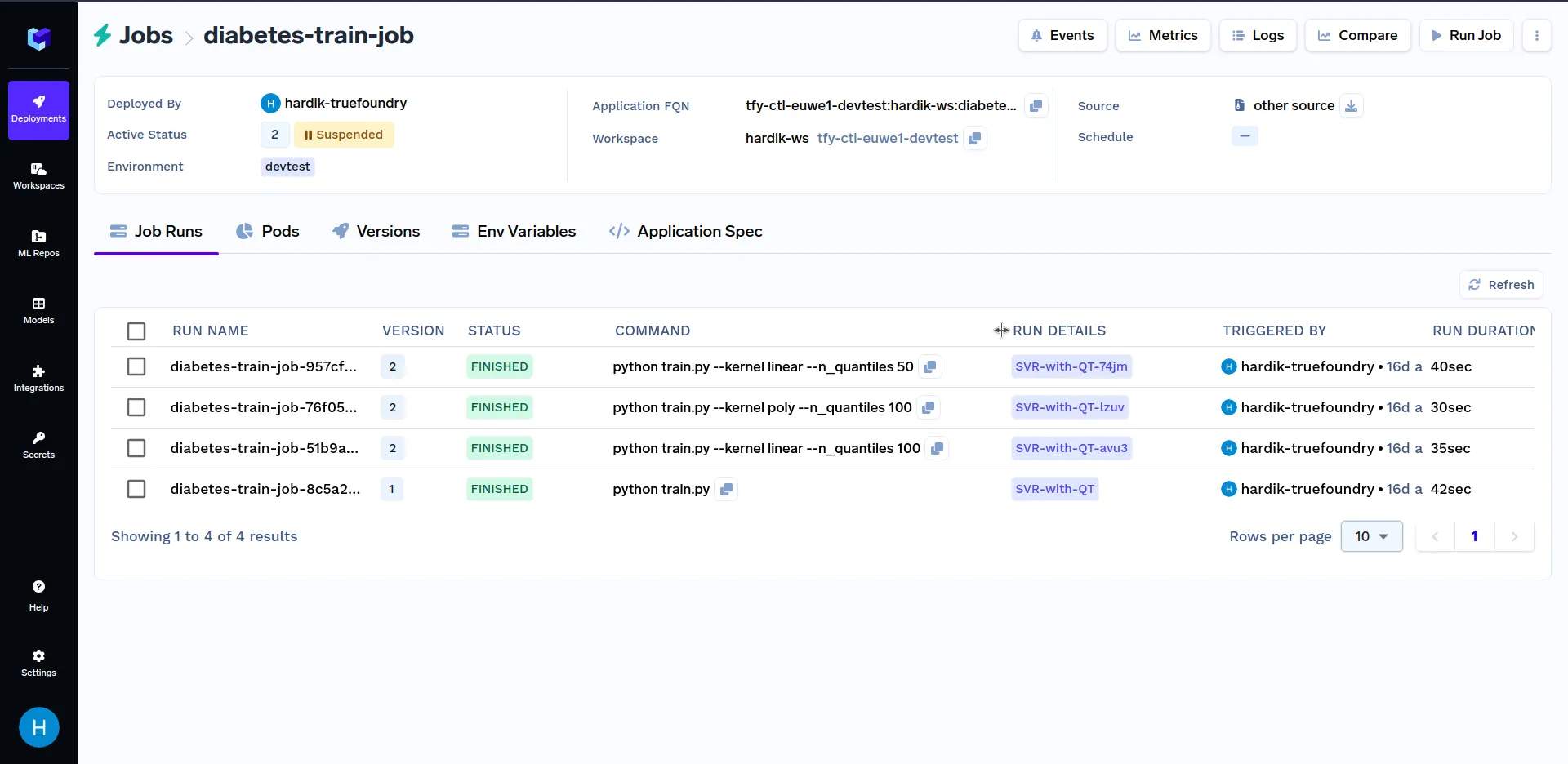
Puede comparar las métricas de diferentes ejecuciones de trabajos en el panel haciendo clic en el botón de comparación en la sección superior derecha del panel, como se muestra a continuación:
Puede obtener más información sobre la implementación de trabajos parametrizados aquí:
Hasta ahora, solo hemos visto la activación de ejecuciones de trabajos desde Panel de control de TrueFoundry. Ahora es posible que activando un trabajo no es siempre deseable mediante la interfaz de usuario, por lo que ahora veremos cómo activar un trabajo mediante programación mediante SDK de Python.
Puede activar su trabajo mediante programación mediante el trigger job funciona como se muestra a continuación:
de servicefoundry import Job, trigger_job
# Configurar una implementación de tareas
trabajo = Trabajo (...)
# Despliegue un trabajo
job_deployment = job.deploy (WORKSPACE_FQN="SU FQN DE WORKSPACE»)
# Activar/ejecutar un trabajo
trigger_job (
application_fqn=job_deployment.application_fqn,
params= {"n_cuantiles» :"80"}
)
También es posible obtener el aplicación_fqn fácilmente desde el panel de control, yendo a Implementaciones -> Trabajos -> Busque el nombre de su trabajo en su espacio de trabajo (aquí diabetes-entrenar-trabajar).
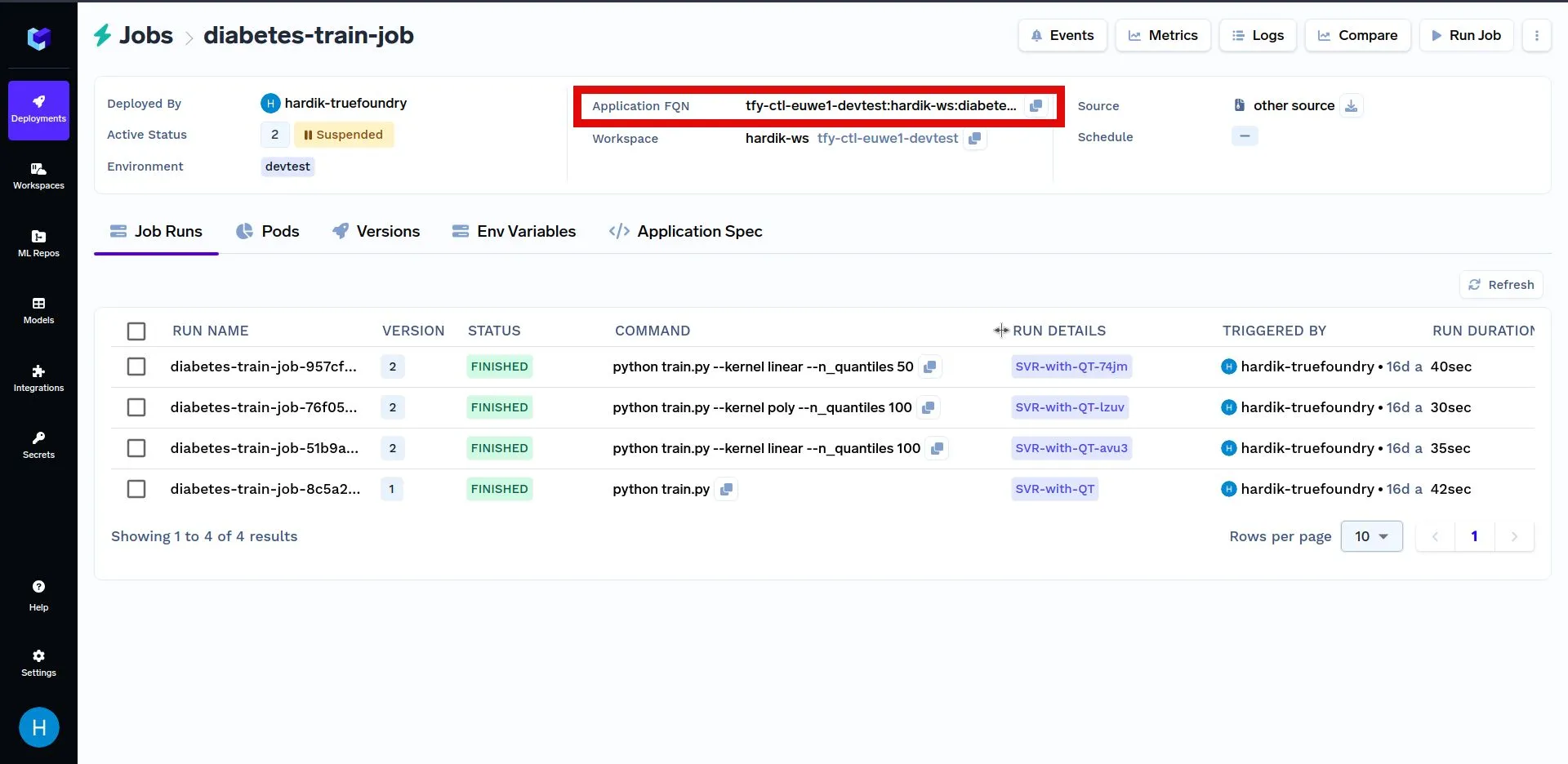
A continuación se muestra otro ejemplo de cómo activar un trabajo mediante programación. En primer lugar, sustituya SU_APLICACIÓN_FAN con el Aplicación FQN de la trabajo desplegado arriba en el código que se muestra a continuación. El Aplicación FQN para una solicitud se destaca a continuación:
En el código que se muestra a continuación, elegimos aleatoriamente un valor para los parámetros del modelo y activamos una ejecución de trabajo con esos parámetros. Después de eso, buscamos entre las ejecuciones de trabajos para encontrar la ejecución con el máximo puntuación. El trabajo realizado con la puntuación máxima indica una elección más óptima de los parámetros del modelo.
importar al azar
importar mlfoundry como mlf
de servicefoundry import trigger_job
# Encuentre el trabajo desplegado, sustitúyalo por el fqn de la aplicación de su trabajo
application_fqn = «SU_APPLICATION_FQN»
# Generar parámetros aleatoriamente
n_quantiles = random.randint (50, 100)
kernel_values = ['lineal', 'sigmoide', 'poli', 'rbf']
kernel = kernel_values [random.randrange (0, len (kernel_values))]
# Activar/ejecutar un trabajo
activado_trabajo = activador_trabajo (
application_fqn=application_fqn,
parámetros = {
«n_cuantiles»: str (n_cuantiles),
«núcleo»: núcleo
}
)
print (F'Triggered job run with n_quantiles= {n_quantiles} and kernel= {kernel} and name as, triggered_job.jobRunname)
cliente = mlf.get_client ()
ml_repo_name = «AQUÍ TIENES EL NOMBRE DE TU REPOSITORIO DE ML»
runs = client.search_runs (ml_repo=ml_repo_name)
puntuación_máxima = 0
para correr en carreras:
métricas = run.get_metrics ()
print (Todas las métricas de la ejecución con el nombre {run.run_name}» :', métricas)
si se «puntúa» en las métricas:
max_score = max (max_score, metrics ['score'] [0] .value)
print («Puntuación máxima del modelo: «, max_score)
NOTA: Asegúrese de reemplazar «SU NOMBRE DE REPOSITORIO DE ML AQUÍ» por su nombre de repositorio de ML y «SU ESPACIO DE TRABAJO FQN AQUÍ» por el FQN de su espacio de trabajo en el siguiente comando.
Puedes leer más sobre Triggering Jobs aquí:
Puede comparar las métricas de diferentes ejecuciones de trabajos de forma programática mediante mlfoundry.search_runs funcionan como se describe en el siguiente código:
importar mlfoundry como mlf
cliente = mlf.get_client ()
ml_repo_name = «TU NOMBRE DE REPO-ML»
# Devuelve todas las ejecuciones
runs = client.search_runs (ml_repo=ml_repo_name)
# Busque el subconjunto de corridas con una métrica de precisión registrada > 0.7
filter_string = «metrics.score > 0.7"
runs = client.search_runs (ml_repo=ml_repo_name, filter_string=filter_string)
Puedes leer más sobre el search_runs funciona aquí:
Imagine tratar con modelos a gran escala que tienen millones o miles de millones de parámetros. Entrenar estos modelos con CPU tradicionales llevaría mucho tiempo e incluso podría resultar inviable debido a limitaciones de memoria.
Por ejemplo, entrenar un modelo de CNN basado en el conjunto de datos CIFAR-10 en un entorno de CPU con 10 épocas lleva 36 minutos y 31 segundos, pero el mismo modelo cuando se entrena en un entorno de GPU (NVIDIA K80) solo lleva 4 minutos y 6 segundos. Esto representa una mejora multiplicada por 9 (consulte aquí)
Las GPU desempeñan un papel vital en el entrenamiento de modelos a gran escala. Proporcionan la memoria, el ancho de banda y las capacidades de procesamiento paralelo necesarias para gestionar modelos de gran tamaño y arquitecturas complejas de manera eficiente. Ahora veremos cómo usar una GPU en un trabajo.
El uso de una GPU en el ejemplo anterior requiere ligeras modificaciones en la forma en que se configura un trabajo en el deploy.py archivo. El siguiente código muestra la actualización Trabajo Configuración para la utilización de la GPU y la asignación personalizada de recursos de CPU y memoria:
deploy.py
de servicefoundry import Job, NodeSelector, GpuType, Resources
trabajo = Trabajo (
resources=Recursos (
# Configurar la GPU
gpu_count=1,
node=nodeSelector (GPU_TYPE=GPUType.t4)
# (Opcional) Configurar los recursos de CPU y memoria
cpu_request=0.2,
cpu_limit=0.5,
memory_request=128,
límite de memoria = 512,
),
...
)
Nota: El resto del código permanece sin cambios
Hasta ahora, hemos visto varias opciones de implementación de trabajos, como imagen, parámetros, y env. Hay varias formas de personalizar tu trabajo con opciones avanzadas. Algunas de ellas son las siguientes:
Ahora que hemos hablado de los trabajos que se pueden activar manualmente a través de TrueFoundry Dashboard o Python SDK. Pero, ¿qué pasa si queremos que un trabajo se ejecute según un cronograma (como un trabajo cron)?
Un trabajo cron ejecuta el trabajo definido en una programación repetida. Esto puede resultar útil para volver a entrenar un modelo periódicamente, generar informes y mucho más. Podemos implementar estos trabajos cambiando sus desencadenar escriba de la siguiente manera:
desde servicefoundry import Job, Schedule
trabajo = Trabajo (
TRIGGER=Programar (
schedule="0 8 1 * *»,
CONCURRENCY_POLICY="Prohibir» # Valores: ["Prohibir», "Permitir», «Reemplazar"]
),
límite de concurrencia = 3,
...
)
En el caso de los trabajos cron, es posible que la ejecución anterior del trabajo no se haya completado cuando ya es hora de que el trabajo se ejecute de nuevo debido a la hora programada. En estos casos, podemos definir política_de_concurrencia de la siguiente manera:
Prohibir: Este es el valor predeterminado. No permita ejecuciones simultáneas.Permitir: Permitir que los trabajos se ejecuten simultáneamente. Opcionalmente, la cantidad máxima de trabajos que se pueden ejecutar simultáneamente se puede cambiar configurando límite de concurrencia al valor deseado. Reemplazar: Sustituya el trabajo actual por el nuevo.La simultaneidad no se aplica a los trabajos activados manualmente. En ese caso, siempre crea una nueva ejecución de trabajo.
El estado del trabajo puede ser de 3 tipos que son TERMINADO, TERMINADO, y FALLÓ. Se puede configurar un trabajo para que se vuelva a intentar varias veces en caso de error.
Un trabajo está marcado como FALLÓ si no finaliza correctamente incluso después del número de reintentos configurado. Reintentos se puede configurar para un trabajo como este:
desde servicefoundry import Job
trabajo = Trabajo (
retries=6, # predeterminado = 1
...
)
En algunos casos de uso, es posible que deba especificar la cantidad máxima de tiempo que desea que un trabajo continúe ejecutándose.
Uso tiempo de espera, puede especificar (en segundos) el tiempo máximo de ejecución de un trabajo, independientemente de si ha fallado o no. Esto tendrá prioridad sobre el reintentos Límite. De forma predeterminada, está establecido en 1000 segundos.
Por ejemplo, si configuras elreintentos a 6 y un tiempo de espera de 480 segundos, el trabajo finalizará después de 480 segundos, independientemente del número de veces que haya intentado ejecutarse.
desde servicefoundry import Job
trabajo = Trabajo (
tiempo de espera = 480,
...
)
Además de las opciones de despliegue de tareas que se analizan en este blog, todavía hay algunas que no analizaremos en este blog, como:
... y algunos más. Puede consultar nuestro Documentación que figuran a continuación para conocer las respuestas a las preguntas anteriores:)
Nuestro repositorio público ejemplos de truefoundry contiene el código fuente del trabajo de este blog y también incluye varios ejemplos, entre ellos LLM Finetuning, Primeros pasos con los cuadernos, Ejemplos de extremo a extremo dando una exposición más amplia a las funciones que ofrece TrueFoundry Platform.
En resumen, TrueFoundry's Job proporciona un marco poderoso para administrar y ejecutar las tareas de capacitación de manera escalable, tolerante a errores y eficiente en el uso de los recursos.
Le permiten distribuir y controlar la ejecución de las cargas de trabajo de aprendizaje automático, supervisar su progreso y garantizar que sus modelos de entrenamiento se entrenen de manera eficaz y confiable, lo que los hace ideales para ejecutar tareas únicas o bajo demanda.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


