Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.
9,9
Reduzca sus costos de infraestructura para los modelos ML/LLM
Las cargas de trabajo de aprendizaje automático (ML) y modelos de grandes lenguajes (LLM) son notoriamente caras de ejecutar en la nube. Esto se debe a que requieren cantidades significativas de potencia informática, memoria y almacenamiento. Sin embargo, hay maneras de reducir los costos de nube para las cargas de trabajo de ML/LLM sin sacrificar la escalabilidad o la confiabilidad.
Principios clave sobre cómo reducir los costos
Mejor visibilidad para los ingenieros y desarrolladores de DevOps: Obtener visibilidad de los costos de la nube es difícil, especialmente cuando tiene varios componentes implementados en varias nubes. TrueFoundry proporciona visibilidad de los costos de la nube a nivel de clúster, espacio de trabajo e implementación, lo que permite a los equipos y desarrolladores de DevOps identificar y optimizar las oportunidades de ahorro de costos a lo largo del ciclo de vida de la ML/LLM.
Facilidad de ajuste de recursos: TrueFoundry permite a los equipos y desarrolladores de DevOps tomar medidas en relación con la visibilidad de los costos que han obtenido.
Equipos de DevOps puede establecer restricciones de recursos a nivel de proyecto, garantizando que las cargas de trabajo de cada equipo tengan acceso a los recursos que necesitan sin exceder el presupuesto.
Desarrolladores también pueden ajustar fácilmente los recursos sobre la marcha, en función de la información que obtienen. Además, TrueFoundry facilita la escalabilidad de las aplicaciones y los IDE a cero en entornos que no son de producción, lo que elimina el costo de los recursos inactivos y hace que los ciclos de iteración para reducir los costos sean más eficientes.
Optimización de la infraestructura para reducir los costos: Las optimizaciones de arquitectura e infraestructura basadas en Kubernetes de TrueFoundry están diseñadas para reducir los costos de la nube.
En general, las funciones de ahorro de costos de TrueFoundry brindan a los equipos y desarrolladores de DevOps las capacidades de visibilidad, control y optimización que necesitan para reducir los costos de la nube durante todo el ciclo de vida de ML/LLM.
Transición de AMI a Docker: Nuestra plataforma ha ayudado a muchas empresas a migrar de AMI a Docker, donde las empresas ya han experimentado ahorros de costos del 30 al 40 por ciento.
TrueFoundry: su plataforma que prioriza los costos
Truefoundry es un «el costo es lo primero» plataforma, construida en torno a Kubernetes, diseñada con una arquitectura que prioriza la eficiencia, la escalabilidad y la reducción de costos.
Exploremos cómo la arquitectura única de TrueFoundry le permite ahorrar costos y, al mismo tiempo, optimizar la confiabilidad y la escalabilidad. Esta es la estructura jerárquica de la plataforma:
Clústeres: Conecte todos sus clústeres, ya sean AWS EKS, Azure AKS, GCP GKE o un clúster local, a la plataforma. Esto le permite integrar sin problemas todos sus clústeres en un solo lugar. Estos clústeres son la base para implementar una amplia gama de servicios, modelos y trabajos.
Espacios de trabajo: Dentro de los clústeres, introducimos los espacios de trabajo, que proporcionan un enfoque simplificado para agregar control de acceso y aislamiento a fin de garantizar que cada proyecto o entorno tenga sus propios recursos dedicados y esté protegido contra el acceso no autorizado. Considérelos como grupos de implementaciones.
Despliegues: Dentro de estos espacios de trabajo, tenemos implementaciones y le ayudamos a implementar diferentes tipos de cosas. Con TrueFoundry, puede cubrir sin esfuerzo todos los aspectos de su ciclo de vida de desarrollo de aprendizaje automático.
Entornos de desarrollo interactivos: Implemente Jupyter Notebook y VS Code para la experimentación colaborativa.
Trabajos de capacitación y ajuste: Entrene de manera eficiente los modelos de aprendizaje automático o ajuste los modelos de LLM mediante la implementación como un trabajo.
LLM previamente entrenados: Implemente rápidamente modelos de lenguaje grande previamente entrenados para casos de uso específicos mediante nuestro catálogo de modelos.
Servicios y aplicaciones: Implemente una variedad de servicios y aplicaciones, incluidos modelos, aplicaciones web, etc.
Catálogo de aplicaciones: Implemente software popular como Label Studio, Redis, Qdrant, etc. con facilidad.
Ahorro de costos a nivel de clúster
Infraestructura basada en Kuberenetes
Kubernetes contribuye a la reducción de costos al emplear el embalaje en contenedores para optimizar la utilización de los recursos, colocar los contenedores de manera eficiente y, en última instancia, reducir los costos de infraestructura.
Para obtener más información sobre cómo TrueFoundry aprovecha Kuberenetes, lea aquí.
💡
Migración de EC2 a Kubernetes: Muchas empresas han pasado con éxito de las máquinas EC2 a Kubernetes después de incorporarlas a nuestra plataforma, lo que ha supuesto un ahorro de costes debido a la mejora de la asignación de recursos
Soporte multinube
La arquitectura multinube de TrueFoundry facilita la conexión a diferentes proveedores de nube.
Flexibilidad para cambiar entre nubes: Al poder cambiar fácilmente entre diferentes proveedores de nube, puede aprovechar los mejores precios y funciones de los diferentes proveedores.
Distribuya las cargas de trabajo entre nubes y regiones: Distribuyendo las cargas de trabajo entre varios proveedores de nube y regiones. Esto puede ayudar a reducir los costos al distribuir las cargas de trabajo en diferentes niveles de precios y regiones. También ayuda a mejorar el rendimiento y la fiabilidad al reducir la dependencia de un único proveedor de nube.
Alta disponibilidad de cuotas de instancias: Al usar varios proveedores de nube, puede obtener acceso a más recursos. Esto puede ayudarle a ahorrar dinero y a evitar cualquier limitación en los recursos que necesita.
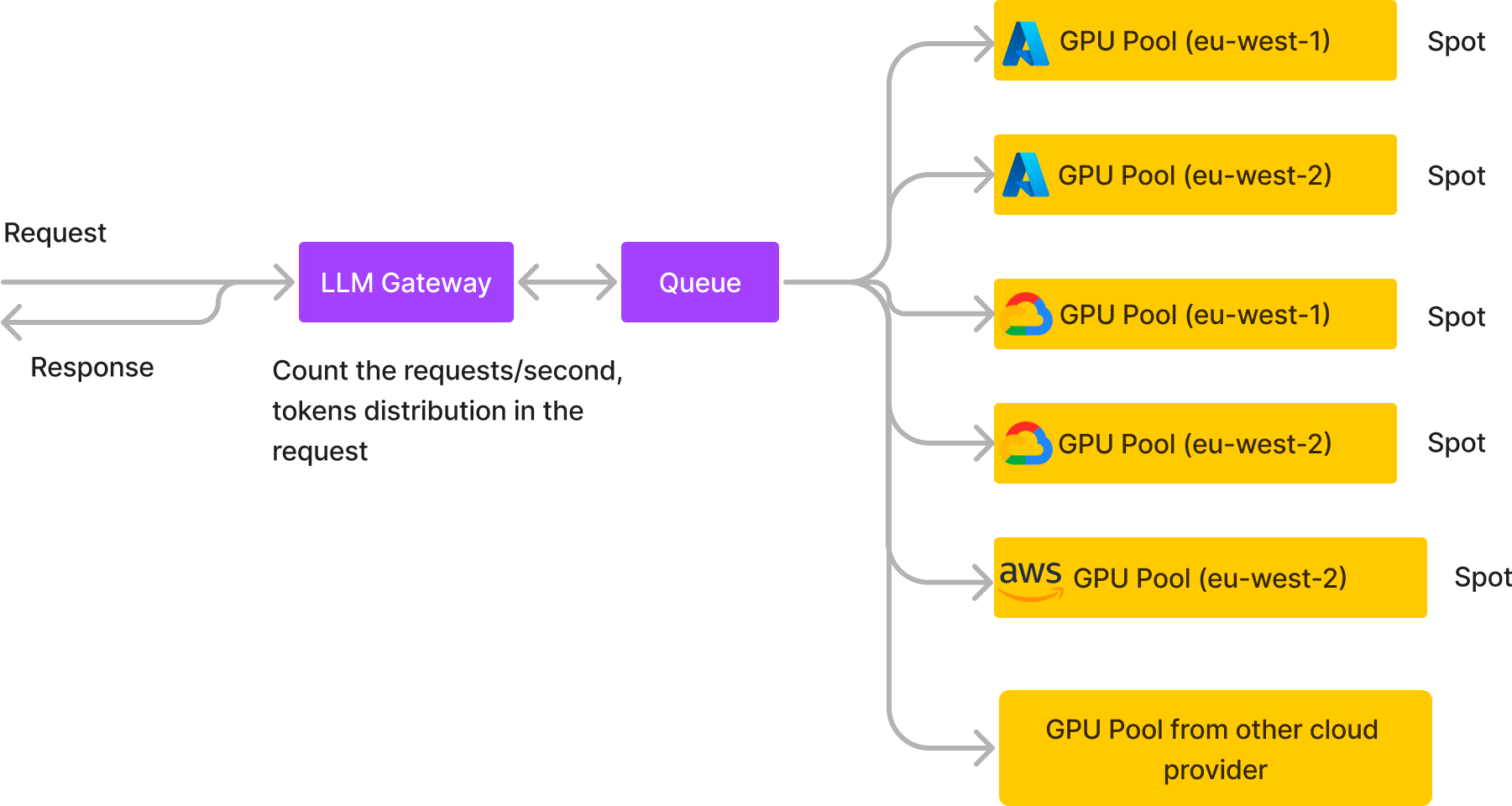
Escalar los LLM en múltiples nubes y regiones
💡
Un proveedor de chatbots de IA conversacional de nivel medio con un tráfico elevado de usuarios (más de 20 RPS y más de 2 millones de solicitudes al día) se ejecuta completamente en instancias de GPU puntuales distribuidas en cinco clústeres en diferentes nubes y regiones mediante nuestro servicio asincrónico. Esto reduce sus costos de infraestructura en un 60% y, al mismo tiempo, mejora la confiabilidad y el rendimiento.
Visibilidad mejorada
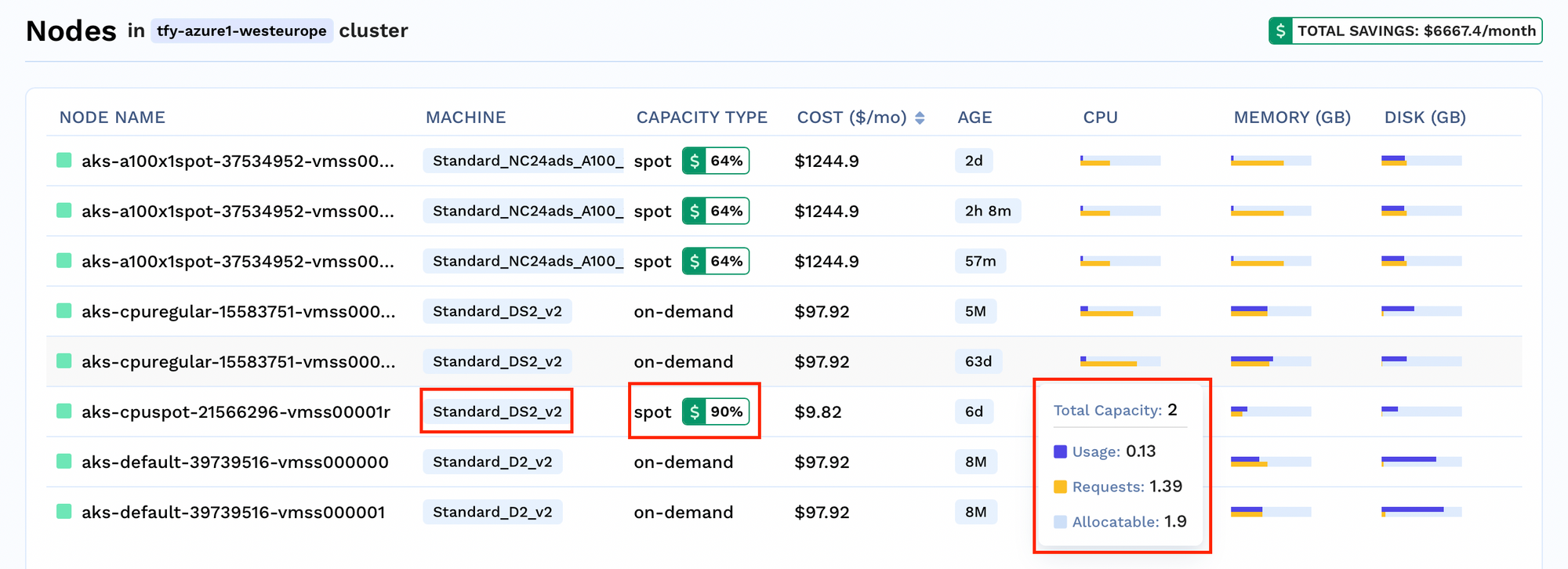
Para cada clúster, puede ver la cantidad de nodos que se ejecutan en el clúster. También puedes obtener información sobre detalles específicos de los nodos, como
Análisis de ahorros: Vea el porcentaje de costo que se ahorra para cada nodo
Perspectivas sobre la asignación de recursos: Consulta el uso actual, la solicitud de recursos y el límite para tomar decisiones informadas.
Información sobre el tipo de capacidad: Consulta qué tipo de nodos se están ejecutando en tu clúster, ya sean nodos puntuales o bajo demanda.
Ahorro de costos a nivel de espacio de trabajo
Límites de recursos
TrueFoundry le permite crear varios espacios de trabajo dentro de un clúster. Esta segmentación le ayuda a organizar sus despliegues para diferentes equipos o entornos.
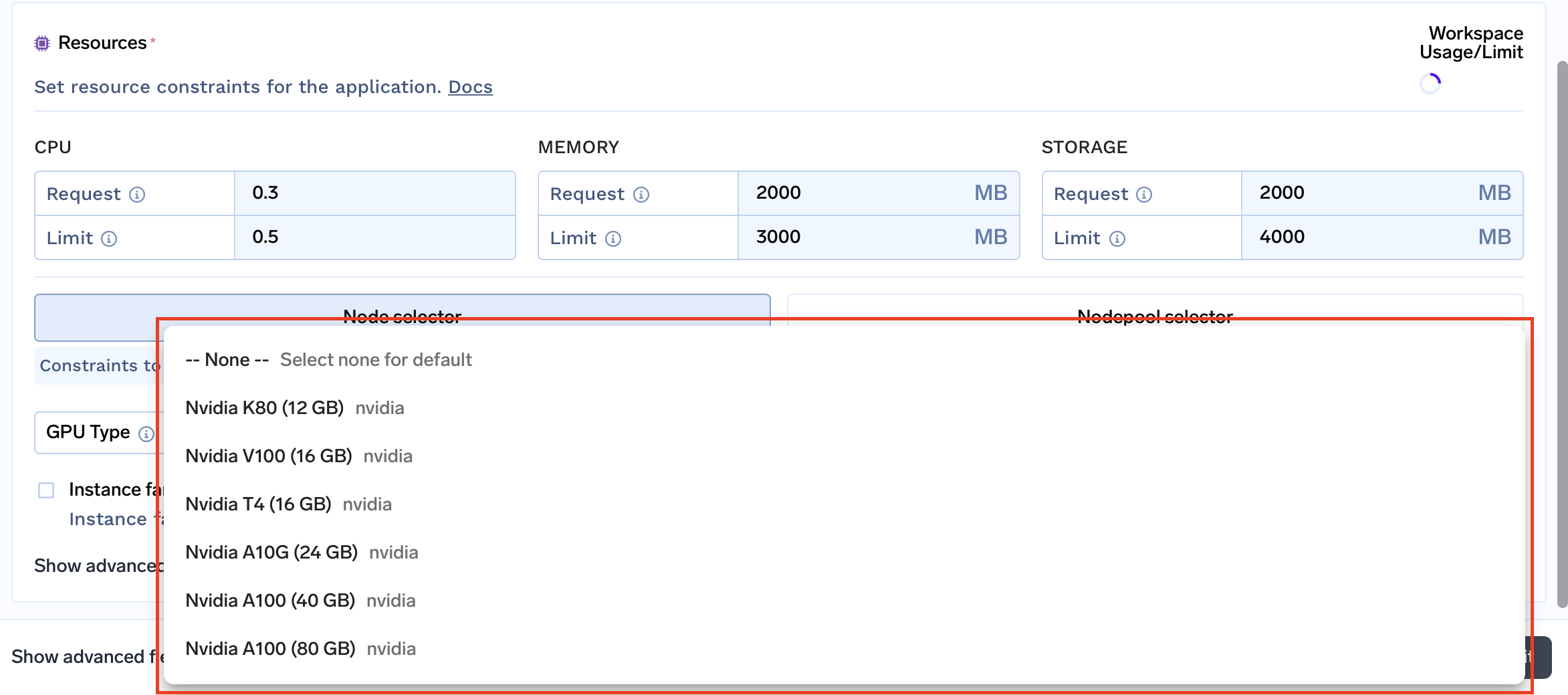
Limitaciones de recursos: Personalice las restricciones de recursos para cada espacio de trabajo, incluidas la CPU, la memoria, el almacenamiento e incluso las familias de instancias. Esto le permite asignar los recursos para cumplir con los requisitos específicos de su proyecto o entorno.
Familias de instancias compatibles: Personalice su espacio de trabajo según los requisitos de rendimiento y el presupuesto específicos seleccionando las familias de instancias que admitirá.
Por ejemplo, si un proyecto no requiere computación de alto rendimiento, puedes deshabilitar las instancias más grandes en su espacio de trabajo. Esto ayudará a evitar que los desarrolladores aprovisionen en exceso los recursos, lo que puede ahorrar dinero.
Grupos de nodos compatibles: Los grupos de nodos son grupos de nodos que proporcionan los recursos computacionales para sus cargas de trabajo. Puede elegir los grupos de nodos que mejor se adapten a sus cargas de trabajo y presupuesto.
Por ejemplo, puedes crear un grupo de nodos con GPU A100. Entonces, solo puedes habilitar ese grupo de nodos específico para los espacios de trabajo del proyecto que requieren acceso a ese tipo de GPU.
Realice un seguimiento del costo a nivel de espacio
También le brindamos visibilidad para realizar un seguimiento del costo de su espacio de trabajo en función del uso anterior. Esto le permitirá identificar qué proyectos o entornos utilizan la mayor cantidad de recursos y dónde puede ahorrar.
Ahorro de costos a nivel de implementación
Ofrecemos funciones avanzadas a nivel de aplicación para ayudarlo a lograr importantes ahorros de costos:
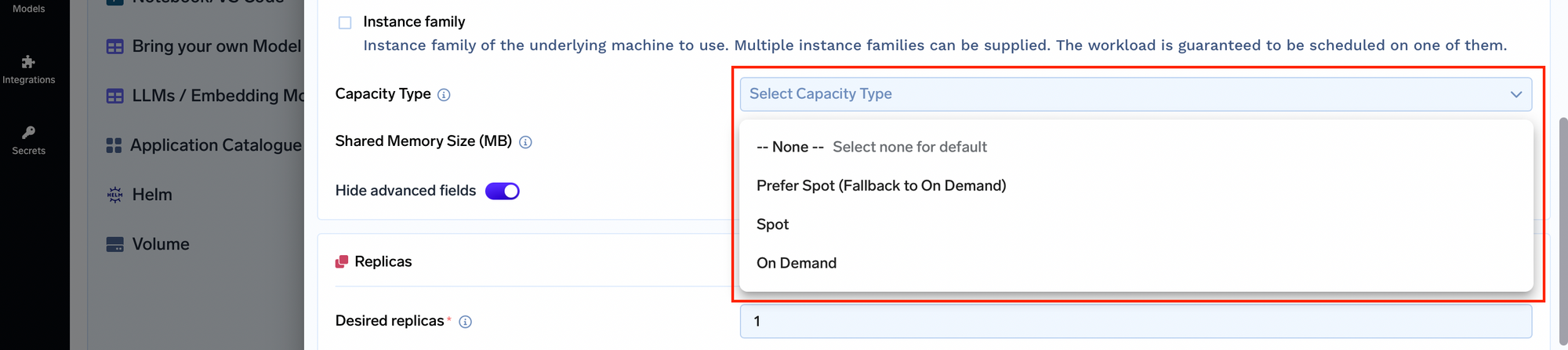
Instancias puntuales con respaldo a la tecnología bajo demanda: Por lo general, las aplicaciones tienen dificultades para equilibrar el costo y la confiabilidad. TrueFoundry le permite seleccionar el tipo de capacidad para sus nodos, incluidas las instancias puntuales que recurren a los recursos bajo demanda. Esto garantiza que sus aplicaciones permanezcan disponibles incluso si se desaloja una instancia puntual, lo que ofrece el equilibrio óptimo entre costo y disponibilidad.
Pausar los servicios: Detenga los servicios cuando no estén en uso para ahorrar costos. Pausa o reanuda los servicios fácilmente desde la página de implementaciones.
Optimización de recursos: Asegúrese de que sus recursos estén asignados de manera óptima y de que sus servicios funcionen con la capacidad adecuada.
Monitorización de recursos: Realice un seguimiento del uso de los recursos de su servicio en tiempo real, incluida la asignación de CPU y GPU. Reciba alertas sobre el sobreaprovisionamiento o el subaprovisionamiento y reciba recomendaciones de recursos.
Ajuste dinámico de recursos: Ajuste los niveles de recursos sobre la marcha para reducirlos a un recurso de CPU más bajo y volver a implementar el servicio en consecuencia.
Escalado automático basado en el tiempo: Programe los ajustes de recursos en función del tiempo para reducir los costos en entornos que no son de producción durante los períodos de bajo uso.
💡
Muchos de nuestros clientes ahorran más del 60% en los costos de su entorno de desarrollo en la nube al programar paradas fuera del horario laboral, lo que reduce el uso de cómputos en 128 horas por semana.
Ahorro de costes a nivel de editores de código
Ofrecemos ciertas funciones para los editores de código, por lo que puede lograr importantes ahorros de costos a nivel de Notebook y VSCode:
Volúmenes compartidos: Utilice volúmenes en función de los requisitos para compartir datos de gran tamaño entre notebooks e instancias de VSCode y facilitar la colaboración. Los volúmenes compartidos reducen la redundancia y mejoran la eficiencia, especialmente cuando varios usuarios necesitan acceder a una cantidad importante de datos en todos los portátiles y las instancias de VSCode.
Uso adaptativo de los recursos: Cambie fácilmente entre la CPU y la GPU en la misma máquina para optimizar la asignación de recursos. No es necesario mantener un recurso de GPU de forma constante, solo cuando sea necesario.
💡
Una empresa de IA generativa que opera en el segmento de generación de vídeo, que ejecuta cientos de Jupyter Notebooks en instancias puntuales para cargas de trabajo no relacionadas con la producción, ahorró entre un 50 y un 60% en costes de nube al utilizar las GPU solo cuando era necesario.
Pausa manual: Pausa fácilmente las instancias de Notebooks/VSCode cuando no estén en uso. El código y los datos se conservan, lo que garantiza un reinicio sin problemas cuando sea necesario.
Pausa automática: Configure sus instancias de Notebooks/VSCode para que se detengan automáticamente después de un cierto período de inactividad a fin de ahorrar valiosos recursos.
💡
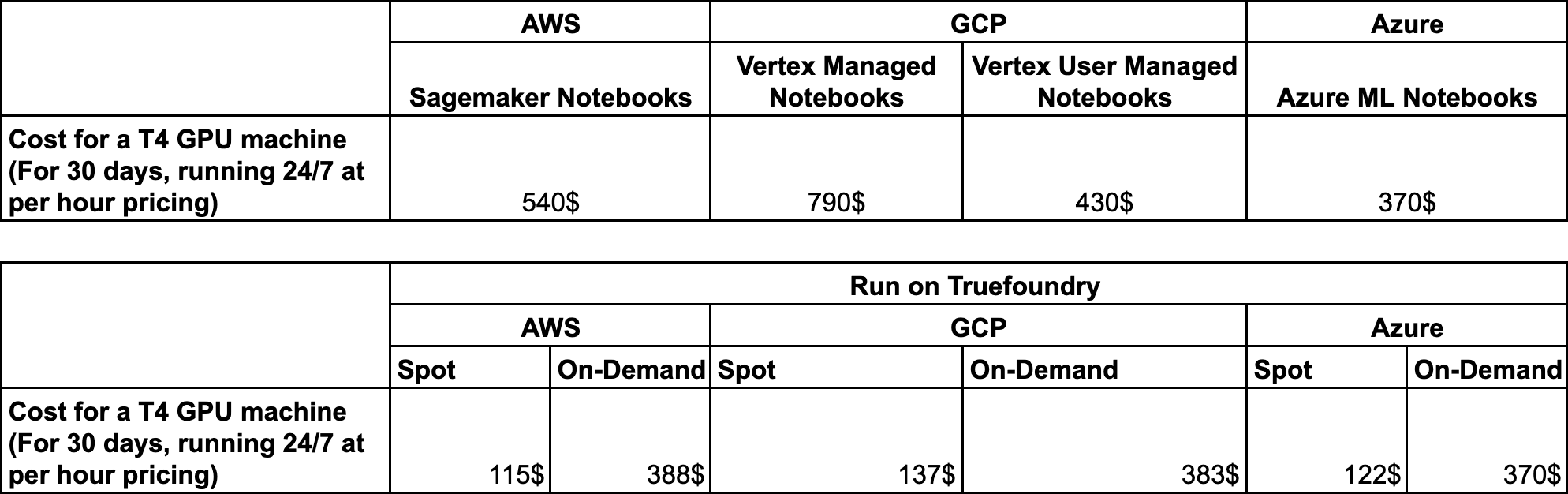
Evaluación comparativa de costos Hemos realizado evaluaciones comparativas en AWS, GCP y Azure para comparar el ahorro de costes que supone ejecutar Notebooks y VSCode bajo demanda o utilizar la nube correspondiente.
Ahorros de costos en la implementación y el ajuste de modelos de lenguaje grande (LLM):
Nuestro catálogo de modelos ofrece una cómoda ventanilla única para implementar y ajustar los conocidos LLM previamente capacitados. Hemos tomado las siguientes medidas para garantizar que la implementación y el ajuste de estos LLM sean lo más rentables posible:
Configuración optimizada de servicio de modelos: Basándonos en la evaluación comparativa de varios modelos de servidores y asignaciones de recursos, le proporcionamos configuraciones preconfiguradas que ofrecen la mejor latencia y rendimiento. Esto simplifica el proceso de implementación de los LLM y le ayuda a hacer que sus implementaciones sean rentables y eficientes desde el punto de vista de los recursos.
Configuración de ajuste preciso eficiente: Ofrecemos métodos eficientes de ajuste, como LoRa y Q-LoRa, que ayudan a reducir el uso de recursos y le permiten alcanzar sus objetivos a un costo menor.
Implementaciones escalables con soporte asíncrono: Implemente los LLM a escala con soporte asíncrono para utilizar sus cuotas de GPU en las tres nubes y obtener de manera confiable las GPU que necesita para el ajuste y la implementación. Esta confiabilidad adicional te permite usar instancias puntuales, lo que te permite ahorrar dinero.
Evaluación comparativa Hemos realizado una evaluación comparativa de costos para comparar los gastos de implementación de LLM en AWS EKS con los de SageMaker. Puede obtener más información en el blog que aparece a continuación.
Varias empresas de la lista Fortune 100 y empresas del mercado intermedio han ahorrado significativamente al usar nuestra plataforma. Algunas incluso han reemplazado sus plataformas internas de SageMaker o en la nube por nuestro sistema, lo que les ha permitido ahorrar entre un 30 y un 40%.
También hemos comparado el rendimiento de muchos LLM de código abierto comunes en esta serie de artículos desde la perspectiva de la latencia, el costo y las solicitudes por segundo. Puedes consultarlos en Blogs de TrueFoundry
También puedes ver este vídeo para obtener una demostración en directo de todas las funciones que hemos tratado en este blog:
True Foundry es un PaaS de implementación de aprendizaje automático sobre Kubernetes para acelerar los flujos de trabajo de los desarrolladores y, al mismo tiempo, permitirles una flexibilidad total a la hora de probar e implementar modelos, al tiempo que garantiza una seguridad y un control totales para el equipo de Infra. A través de nuestra plataforma, permitimos a los equipos de aprendizaje automático implementar y supervisar modela en 15 minutos con un 100% de confiabilidad, escalabilidad y la capacidad de revertirse en segundos, lo que les permite ahorrar costos y lanzar los modelos a la producción más rápido, lo que permite obtener un verdadero valor empresarial.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga



















































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


