

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026
%20(11).webp)
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
La incitación, el ajuste fino y la generación aumentada de recuperación (RAG) son las técnicas de aprendizaje de LLM más populares. La elección de la técnica correcta implica una evaluación cuidadosa de los requisitos, los recursos y los resultados deseados del proyecto.
En las siguientes secciones, profundizaremos en cada técnica, analizaremos sus complejidades, aplicaciones y cómo decidir cuál es la más adecuada para sus necesidades

El primer paso para decidir entre solicitar, ajustar y RAG es examinar detenidamente los datos de los que dispone y el problema específico que pretende resolver. Considera si tu tarea implica conocimientos comunes o información especializada o requiere datos actualizados de fuentes externas. La complejidad del problema, el estilo y el tono del resultado deseado y el nivel de personalización necesario también son factores críticos.
Si se trata de temas altamente especializados o de nicho, es posible que sea necesario realizar ajustes o RAG para lograr el nivel deseado de precisión y relevancia. Por otro lado, si tu proyecto implica consultas más generales o la creación de contenido, las indicaciones podrían ser suficientes y más rentables.
La elección entre la incitación, el ajuste y la RAG también depende de las restricciones presupuestarias. La solicitud es, por lo general, la que consume menos recursos, ya que utiliza el modelo tal cual. El ajuste preciso requiere datos y recursos computacionales adicionales para la capacitación, lo que genera costos más altos. El RAG también puede consumir muchos recursos, especialmente si implica configurar y mantener una base de datos externa para su recuperación.
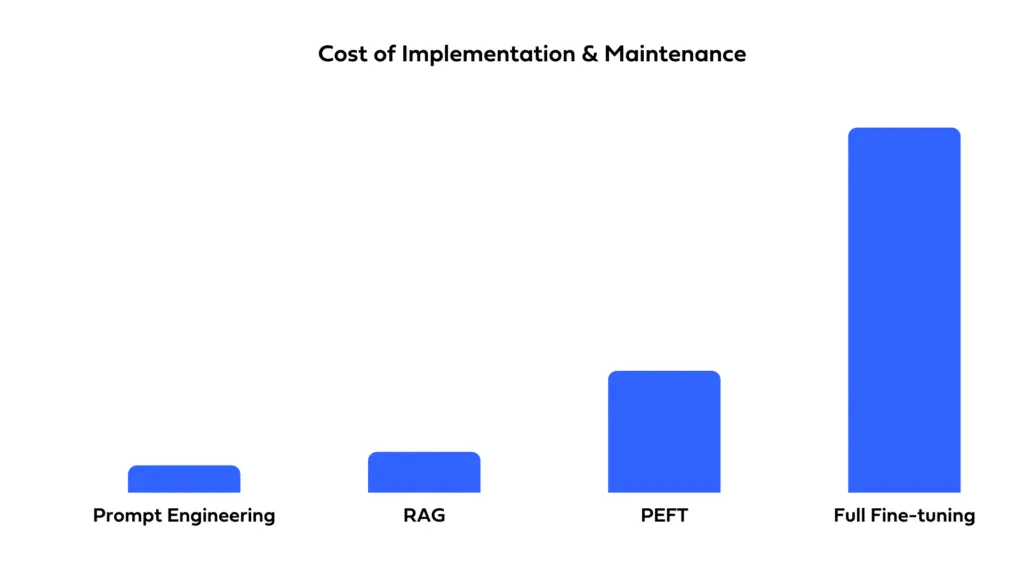
Tenga en cuenta la rapidez con la que necesita implementar la solución y los recursos de los que dispone. Las indicaciones permiten una implementación rápida con un tiempo de configuración mínimo. El ajuste fino, si bien puede ofrecer un mejor rendimiento, requiere tiempo para la capacitación y la optimización. La tecnología RAG implica la complejidad de integrar fuentes de datos externas, lo que puede ampliar los plazos de desarrollo y requerir conocimientos especializados.
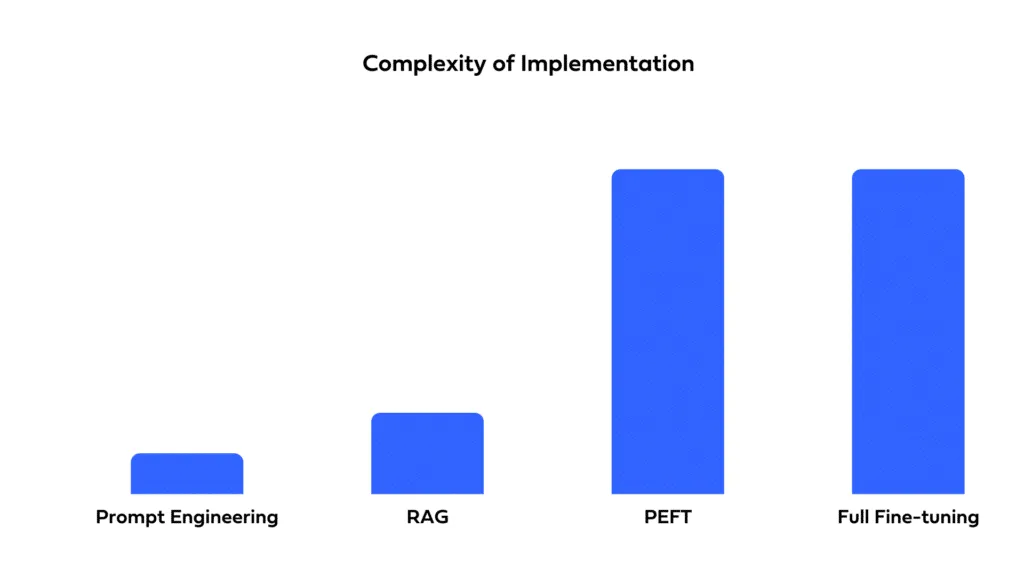
RAG facilita la atribución de la fuente, lo que permite a los usuarios discernir el origen de la información utilizada para generar la respuesta. La indicación y el ajuste fino actúan como una caja negra que dificulta el rastreo de las respuestas.

Prompting es ideal para proyectos que requieren soluciones rápidas y rentables y puede basarse en la base de conocimientos generales de modelos previamente entrenados. Se adapta a aplicaciones como:
Si bien las solicitudes son muy accesibles, es posible que no siempre proporcionen la precisión o la personalización necesarias para tareas especializadas. La calidad de los resultados puede variar considerablemente en función del diseño de la solicitud, lo que requiere una elaboración y unas pruebas cuidadosas.
El ajuste fino es el método preferido cuando su proyecto exige un alto grado de especificidad o necesita alinearse estrechamente con estilos, tonos o conocimientos específicos de un dominio determinado. Es particularmente eficaz para:
La decisión de realizar un ajuste fino debe considerar la compensación entre la mejora del rendimiento y los costos y recursos adicionales necesarios. Es esencial para los proyectos en los que el valor de la personalización y la precisión supera estas consideraciones.
RAG sobresale en situaciones en las que las respuestas deben complementarse con la información más reciente o datos detallados de dominios específicos. Es especialmente adecuado para:
RAG puede ofrecer resultados superiores para consultas complejas y áreas de conocimiento especializadas, pero conlleva una mayor complejidad y necesidades de recursos. Es la elección correcta cuando el alcance del proyecto justifica la inversión en la creación y el mantenimiento de la infraestructura necesaria para la recuperación de datos en tiempo real
La solicitud está habilitada por nuestro Puerta de enlace LLM módulo, que admite los flujos de trabajo que a menudo se asocian a mejores herramientas de ingeniería rápida utilizado para aplicaciones de LLM de producción. LLM Gateway ofrece una API unificada que permite a los usuarios acceder a varios proveedores de LLM, incluidos sus propios modelos autohospedados, a través de una única plataforma. Cuenta con funciones centralizadas de administración de claves, autenticación y atribución de costos. Además, ofrece soporte para el retroceso y los reintentos, así como para la integración con barreras de seguridad.
Hemos creado plantillas para el flujo de trabajo para configurar RAG con solo unos pocos clics. Lea nuestro blog sobre cómo implementar un Chatbot basado en RAG usando TrueFoundry. Se encarga del proceso integral de creación de una base de datos vectorial, incrustación de modelos, LLM, etc., a la vez que le brinda los controles adecuados para personalizar el flujo de trabajo de acuerdo con sus necesidades.
TrueFoundry ha simplificado la ajuste fino procese abstrayendo todas las complejidades y configurando las configuraciones de recursos correctas para las técnicas de LoRa/QLoRa. Puede implementar un portátil Jupyter de ajuste fino para experimentar o iniciar un trabajo de ajuste específico. Lea la guía detallada aquí.
Estamos en True Foundry admiten las tres técnicas de aprendizaje de LLM: instrucciones, RAG y ajuste fino de una manera extremadamente simplificada.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


