

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Los grandes modelos lingüísticos (LLM) están transformando la forma en que las empresas automatizan las tareas, generan contenido e interactúan con los datos. Sin embargo, la mayoría de los servicios de LLM actuales se centran en la nube, lo que genera dudas sobre la seguridad, el cumplimiento y el control de los datos.
Para las organizaciones que manejan información confidencial o regulada, a menudo no es viable confiar en API externas o modelos de nube pública. Esto ha llevado a un cambio cada vez mayor hacia las implementaciones de LLM locales, en las que las empresas ejecutan modelos de forma segura dentro de su propia infraestructura.
En este artículo, analizamos qué son las LLM locales, por qué son importantes, cómo funcionan y cómo plataformas como TrueFoundry permiten despliegues escalables y seguros en entornos empresariales.

Los locales de LLM hacen referencia a modelos lingüísticos grandes que se implementan y operan dentro de la propia infraestructura de la organización y no a través de servicios en la nube externos o API de terceros. Estos modelos pueden ser de código abierto o propietarios y, por lo general, se ejecutan en servidores GPU internos, centros de datos privados o entornos de nube aislados configurados para cumplir con los estándares internos de seguridad y cumplimiento.
A diferencia de las LLM alojadas en la nube que se basan en puntos finales públicos y en una infraestructura gestionada por el proveedor, las LLM locales están totalmente controladas por la organización. Esto permite una mayor personalización, ajuste e integración con los sistemas y flujos de trabajo internos. Las empresas pueden elegir qué modelos utilizar, como LLama 2, Mistral o Mixtral, y optimizarlos en función de las necesidades empresariales o de dominio específicas.
La implementación local permite a los equipos adaptar el comportamiento del modelo, aplicar políticas de residencia de datos y garantizar que la información confidencial nunca abandone su red de confianza. También brinda oportunidades para ajustar mejor el rendimiento y controlar los costos, especialmente para las aplicaciones de gran volumen o sensibles a la latencia. Para las organizaciones que priorizan la autonomía, la seguridad y el cumplimiento normativo, los LLM locales ofrecen una alternativa práctica y escalable a las API comerciales de IA.
La implementación de LLM local le brinda un control total sobre la infraestructura, los datos y el comportamiento del modelo. Sin embargo, también requiere una planificación, una inversión y una administración continua cuidadosas. A continuación se detallan los aspectos clave que debe tener en cuenta:
Necesita hardware de alto rendimiento para ejecutar modelos lingüísticos de gran tamaño de manera eficiente. Esto incluye potentes GPU, como las NVIDIA A100 o H100, una gran cantidad de RAM, una red de alta velocidad y un almacenamiento SSD rápido para gestionar conjuntos de datos y modelos de gran tamaño.
Usted conserva la propiedad total de sus datos, lo que permite configuraciones aisladas, políticas de firewall estrictas y el cumplimiento de las normas de residencia de datos, como el RGPD y la HIPAA. Esto hace que la implementación local sea ideal para las industrias que manejan información confidencial o regulada.
Debe implementar canalizaciones de aprendizaje automático para el control de versiones, la contenedorización, la implementación y la supervisión. El seguimiento continuo del rendimiento ayuda a garantizar la precisión, la fiabilidad y la estabilidad operativa del modelo a lo largo del tiempo.
Si bien evitas las tarifas recurrentes de API basadas en tokens, la implementación de LLM en las instalaciones requiere una importante inversión de capital inicial en hardware. También debes tener en cuenta los costos operativos continuos, como la energía, la refrigeración, el mantenimiento y el personal cualificado.
Obtiene acceso total a los pesos del modelo, lo que permite realizar ajustes avanzados con datos patentados. Esto permite un rendimiento altamente personalizado y alineado con los flujos de trabajo de su organización, a diferencia de los modelos genéricos alojados en la nube.
La escalabilidad depende de la capacidad de hardware disponible. A diferencia del escalado automático en la nube, debe planificar los picos de carga de trabajo, implementar el equilibrio de cargas y optimizar los sistemas para mantener una baja latencia y un alto rendimiento.
Su equipo interno de TI o DevOps es responsable de la aplicación de parches de seguridad, el mantenimiento de la infraestructura y las actualizaciones de los modelos. El mantenimiento periódico garantiza la confiabilidad, la seguridad y la compatibilidad del sistema con los cambiantes requisitos de inteligencia artificial.
Los servicios de IA basados en la nube han facilitado a los equipos la experimentación, la creación de prototipos y la implementación de modelos de aprendizaje automático a escala. Sin embargo, cuando se trata de cargas de trabajo de producción en entornos empresariales, confiar únicamente en los LLM centrados en la nube presenta varias limitaciones que no se pueden ignorar.
Privacy and data control son las preocupaciones más importantes. Cuando se utilizan las API de nube pública, los datos de entrada confidenciales deben transmitirse a través de Internet y procesarse en una infraestructura externa. Esto presenta riesgos relacionados con la filtración de datos, el acceso no autorizado y las infracciones de la conformidad, especialmente en sectores como los de la salud, las finanzas, la defensa y los servicios legales, donde se aplican normas reglamentarias estrictas.
Bloqueo de proveedor es otro inconveniente importante. Las plataformas de IA en la nube suelen agrupar las API de inferencia, el almacenamiento y el ajuste en ecosistemas propietarios. Una vez que un flujo de trabajo se basa en un proveedor específico, migrar a otro servicio o incorporar las cargas de trabajo a la empresa lleva mucho tiempo y es costoso. Esta dependencia limita la flexibilidad a largo plazo y el control sobre las actualizaciones de los modelos o los términos de uso.
Escalamiento impredecible de costos también se convierte en un desafío a medida que aumenta el uso. Los LLM requieren un uso intensivo de la computación, y los modelos de precios en la nube basados en el número de tokens o el volumen de solicitudes pueden provocar un aumento vertiginoso de los costos operativos, especialmente en el caso de las aplicaciones con un alto rendimiento o una interacción constante.
Además, los entornos de nube ofrecen opciones limitadas para despliegues periféricos y de baja latencia. Las aplicaciones que requieren respuestas casi instantáneas o funcionalidad sin conexión pueden tener dificultades para cumplir los objetivos de rendimiento cuando dependen de API externas.
Por último, los proveedores de nube reducen gran parte de la infraestructura, lo que deja a los equipos con una visibilidad mínima de los cuellos de botella del rendimiento, las oportunidades de optimización o los parámetros de ajuste.
Para las empresas que exigen control, transparencia y sostenibilidad a largo plazo, estas limitaciones son un argumento sólido para adoptar soluciones de LLM locales.
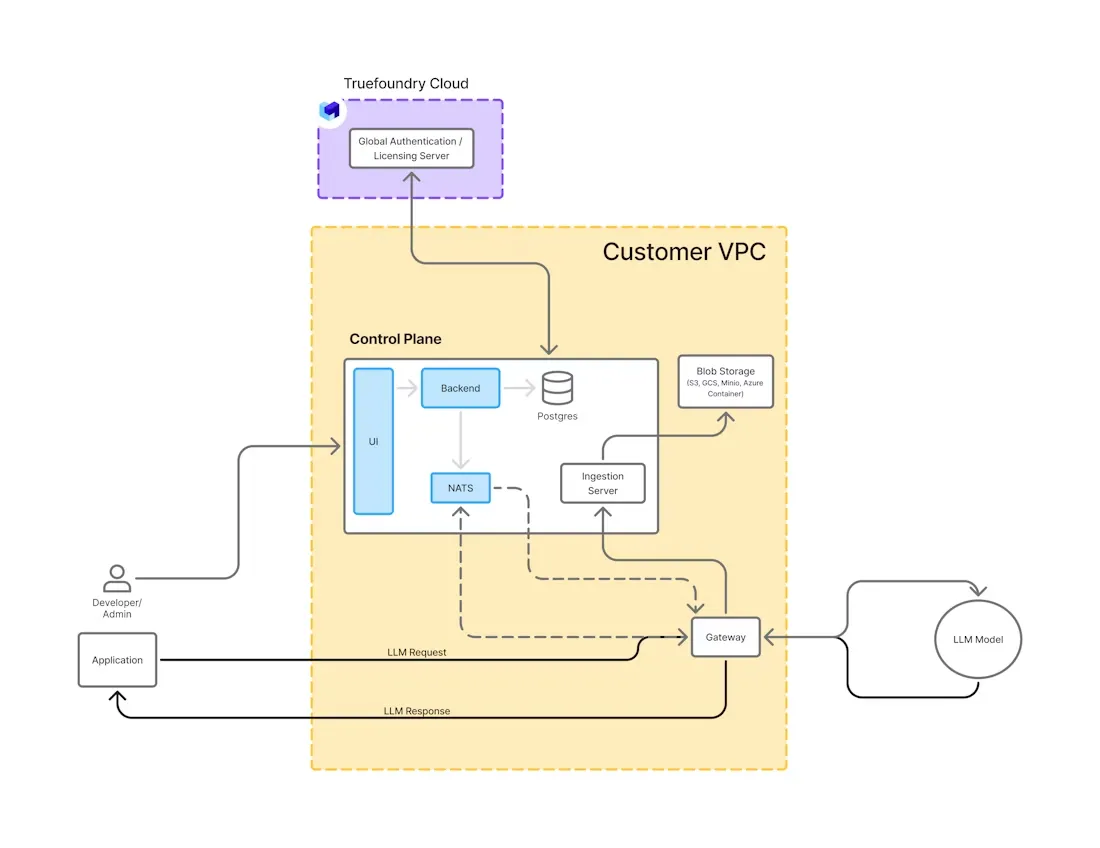
La implementación de LLM en las instalaciones requiere una arquitectura cuidadosamente estructurada que equilibre el rendimiento, la seguridad y la capacidad de mantenimiento. A continuación se muestran los componentes clave que normalmente se encuentran en una configuración de nivel de producción.
Infraestructura de cómputos: Las GPU de alto rendimiento son la base de los LLM locales. Las empresas suelen utilizar las GPU NVIDIA A100, H100 o L40, según el tamaño del modelo y los requisitos de rendimiento. Se alojan en centros de datos locales o clústeres de nube privada con la refrigeración, la red y el almacenamiento adecuados.
Motor de inferencia: Los marcos de inferencia como vLLM, TGI o DeepSpeed-Inference gestionan la ejecución real del modelo. Optimizan el uso de la memoria, admiten la transmisión de tokens y permiten la agrupación por lotes de varias solicitudes para maximizar el rendimiento.
Administración y almacenamiento de modelos: Los modelos se almacenan localmente en repositorios de artefactos seguros o en montajes de volumen. Los mecanismos de control de versiones, reversión y acceso son esenciales para gestionar los ciclos de vida de los modelos y auditar los cambios.
Contenerización y orquestación: Herramientas como Docker y Kubernetes se utilizan para implementar, escalar y administrar las cargas de trabajo de LLM. Kubernetes gestiona el escalado automático, la programación de GPU, el equilibrio de carga y la recuperación ante fallos, lo que garantiza un rendimiento uniforme en todos los servicios.
API and enrutamiento: Una capa de API compatible con REST o OpenAI expone la funcionalidad de LLM a las aplicaciones internas. Puede incluir el enrutamiento multimodelo, la autenticación de usuarios y el filtrado rápido para garantizar la seguridad y el control.
Observabilidad y monitoreo: Las métricas como la latencia, la utilización de la GPU, el rendimiento de las solicitudes y la velocidad de generación de tokens se rastrean mediante herramientas como Prometheus, Grafana y OpenTelemetry. El registro y las alertas son fundamentales para mantener el tiempo de actividad y solucionar los problemas.
Esta arquitectura modular permite a las empresas crear sistemas LLM escalables y seguros adaptados a sus políticas internas, objetivos de rendimiento y requisitos de cumplimiento.
Los LLM locales se están adoptando cada vez más en los sectores que requieren soberanía de datos, un rendimiento de baja latencia y un control total sobre las canalizaciones de IA. Estos son algunos casos de uso comunes e impactantes.
Los hospitales y los laboratorios de investigación utilizan los LLM para resumir las notas de los pacientes, generar informes de alta calidad y ayudar con la documentación clínica. Las implementaciones in situ garantizan que la información de salud de los pacientes permanezca dentro de la infraestructura segura del hospital, lo que contribuye al cumplimiento de la HIPAA y a las políticas de datos institucionales.
Las instituciones financieras utilizan los LLM para tareas como resumir las llamadas de ganancias, automatizar los informes de cumplimiento y analizar los estados financieros. Las configuraciones locales evitan que los datos financieros confidenciales queden expuestos a las API de terceros y, al mismo tiempo, mantienen el cumplimiento de los marcos de riesgo internos y las auditorías reglamentarias.
Las agencias utilizan los LLM para responder preguntas, resumir informes clasificados y recuperar conocimientos internos. Dado que los datos de seguridad nacional deben permanecer estrictamente contenidos, los LLM locales permiten aplicar aplicaciones de IA generativas sin infringir los protocolos de clasificación de datos.
Los bufetes de abogados y los departamentos legales utilizan los LLM para analizar contratos, generar resúmenes y ayudar con la investigación legal. La implementación local garantiza que la información privilegiada entre abogado y cliente nunca salga de los servidores internos, lo que mantiene la confidencialidad y cumple con los requisitos de los colegios de abogados.
Las empresas de fabricación utilizan los LLM para generar guías de solución de problemas, interpretar los registros de los sensores y ayudar a los técnicos de campo. La implementación de los LLM en servidores locales ayuda a evitar el envío de datos de máquinas de propiedad exclusiva a servicios externos y reduce la latencia en entornos remotos o desconectados.
Las empresas de telecomunicaciones utilizan los LLM para impulsar los chatbots, clasificar los tickets y ofrecer recomendaciones de servicio automatizadas. La implementación local permite un rendimiento en tiempo real y, al mismo tiempo, mantiene los datos de los clientes dentro de la infraestructura interna para cumplir con las leyes de privacidad regionales.
Estos casos de uso destacan cómo las LLM locales descontrolan una potente automatización e inteligencia sin comprometer la seguridad, el cumplimiento o el control.
La implementación del LLM en las instalaciones implica una serie de pasos coordinados, desde la selección del modelo hasta el monitoreo de la producción. Un flujo de trabajo bien definido garantiza que el sistema sea escalable, seguro y optimizado para las necesidades de su organización.
El proceso comienza con la elección de un modelo apropiado en función de su caso de uso. Los modelos populares de código abierto como Llama 2, Mistral o Mixtral suelen preferirse para las implementaciones locales. Una vez seleccionado, el modelo se descarga, se cuantifica si es necesario y se valida para comprobar su compatibilidad con su infraestructura.
A continuación, se preparan los servidores GPU o los recursos de nube privada. Esto incluye configurar los tiempos de ejecución de los contenedores (por ejemplo, Docker), los orquestadores (por ejemplo, Kubernetes) y las capas de almacenamiento para alojar los pesos y los registros de los modelos. Los controles de acceso y las políticas de seguridad están configurados para cumplir con los requisitos de cumplimiento.
El modelo se carga en un motor de inferencia como vLLm o TGI. Estos motores proporcionan el entorno de ejecución para la generación de texto en tiempo real, el procesamiento por lotes, la transmisión y la optimización de la memoria. Los archivos de configuración definen el tamaño del lote, los tokens máximos y los límites de simultaneidad.
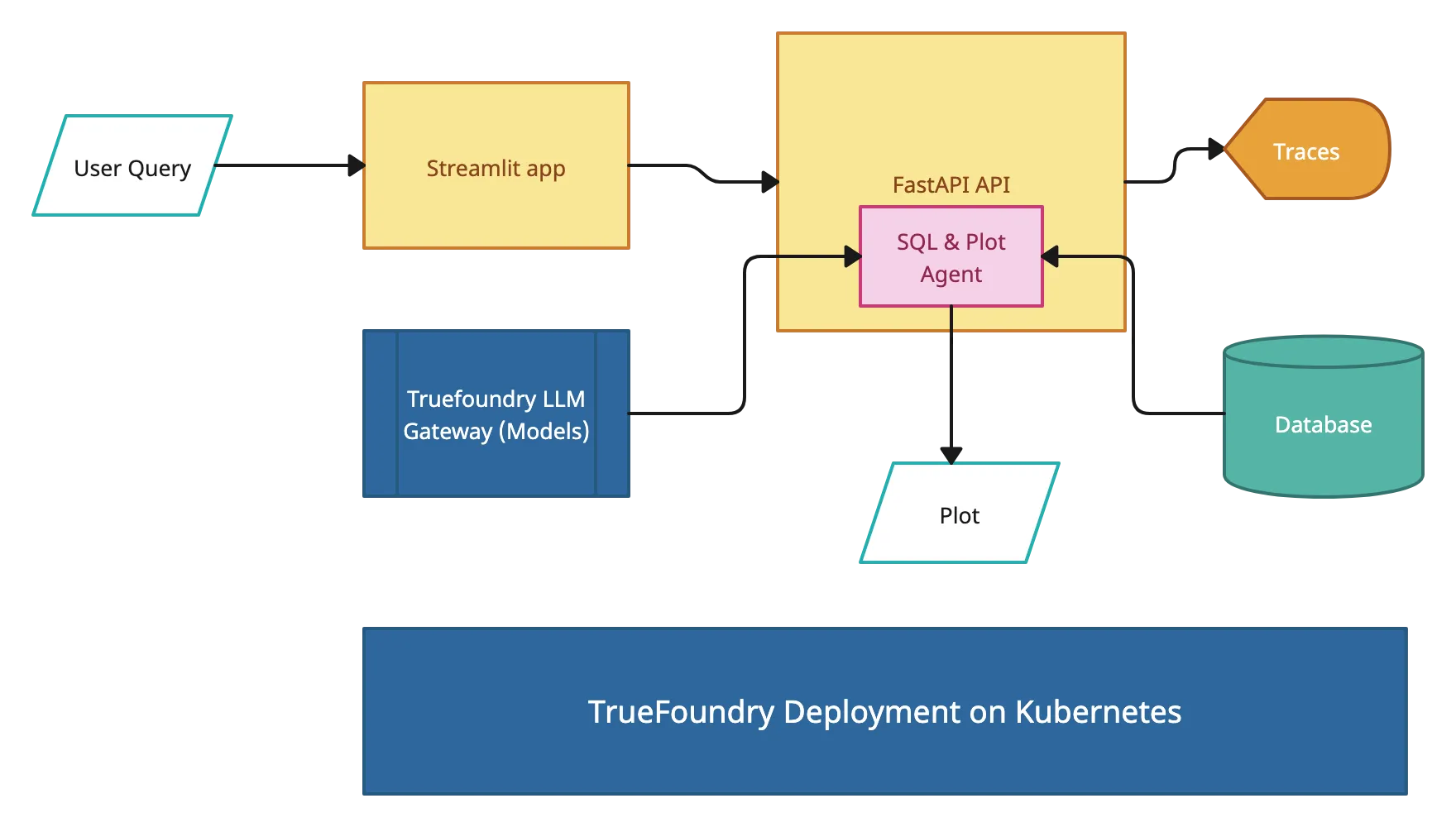
Una vez que el motor está en funcionamiento, se expone a través de una API compatible con REST u OpenAI. Esto permite que las aplicaciones, herramientas o interfaces de usuario internas consulten el modelo. Es posible agregar enrutamiento, autenticación y limitación de velocidad multimodelo en esta capa para un mejor control.
Las herramientas de observabilidad están conectadas para rastrear el uso de la GPU, la latencia, el rendimiento de los tokens y los errores de solicitud. En función de los patrones de tráfico, las políticas de escalado automático o los procedimientos de escalado manual se configuran para gestionar la demanda sin tiempo de inactividad.
Seguir este flujo de trabajo ayuda a las organizaciones a lanzar y administrar los LLM de manera eficiente dentro de su infraestructura sin depender de plataformas externas ni exponer datos confidenciales.
Estas herramientas y técnicas lo ayudan a implementar LLM locales con un rendimiento, una seguridad y un control total de los datos sólidos, a la vez que mantiene una confiabilidad de nivel empresarial.
La implementación de LLM en las instalaciones brinda a las organizaciones un control total sobre su infraestructura de IA, pero también conlleva ventajas y desventajas. Comprender tanto los beneficios como los desafíos es esencial para una adopción exitosa.
TrueFoundry simplifica la implementación y la administración de modelos lingüísticos de gran tamaño dentro de una infraestructura privada, lo que hace que GenAI local sea accesible para las empresas sin necesidad de una profunda experiencia en DevOps o MLOps. Basado en Kubernetes, TrueFoundry permite una administración de LLM rápida, segura y escalable mediante el soporte preintegrado para motores de inferencia de alto rendimiento, como VLLM y TGI.
La plataforma resume la complejidad de administrar contenedores, GPU y políticas de escalado, lo que permite a los equipos centrarse en crear aplicaciones en lugar de mantener la infraestructura. ¿Con La puerta de enlace de IA de TrueFoundry, las organizaciones pueden exponer los LLM mediante API compatibles con OpenAI y, al mismo tiempo, aplicar la limitación de tarifas, la facturación basada en tokens y el enrutamiento multimodelo, todo ello dentro de su entorno seguro.
TrueFoundry también ofrece una observabilidad integrada, incluida la supervisión en tiempo real del uso de los tokens, la latencia y el rendimiento del modelo. Esto ayuda a los equipos a optimizar el rendimiento, solucionar problemas y hacer cumplir la gobernanza.
Ya sea que implementen Llama 2, Mistral o modelos internos ajustados, TrueFoundry ofrece a las empresas una solución lista para la producción para GenAI local, totalmente personalizable, compatible y diseñada para escalar.
A medida que las empresas adoptan cada vez más modelos lingüísticos de gran tamaño, la implementación local ofrece una vía segura y flexible para aprovechar Gen I sin comprometer la privacidad de los datos, el cumplimiento o el control de la infraestructura. Si bien las soluciones basadas en la nube brindan comodidad, a menudo son insuficientes en entornos regulados o delicados. Los LLM locales brindan a las organizaciones la propiedad total del paquete, una mayor personalización y costos predecibles, lo que los hace ideales para las estrategias de IA a largo plazo. Con plataformas como TrueFoundry, la implementación y el escalado interno de los LLM son más rápidos, eficientes y fáciles de administrar. Para las organizaciones que se centran en el control, la transparencia y la innovación, el GenAI local no es solo una alternativa, sino una ventaja estratégica.
Los LLM se implementan localmente mediante la contenedorización de los modelos con Docker, la organización a través de Kubernetes y la entrega a través de motores de inferencia optimizados, como vLLM o TGI. Usted configura las GPU, las redes y el almacenamiento, integra herramientas de supervisión e implementa canalizaciones de MLOps para gestionar el control de versiones, el escalado, la seguridad y el rendimiento dentro de su infraestructura privada.
La implementación en la nube ofrece escalabilidad bajo demanda, infraestructura gestionada y precios de pago por uso, mientras que la implementación local proporciona un control total de los datos, personalización y cumplimiento. Usted cambia la flexibilidad de la nube por una mayor seguridad y soberanía local, pero debe gestionar internamente los costes de hardware, el mantenimiento, los límites de escalado y la complejidad operativa.
Puede utilizar servicios de LLM de nube pública, entornos de nube privada, despliegues híbridos o plataformas de IA gestionadas. Los modelos basados en API, como OpenAI o los puntos finales alojados de Hugging Face, reducen la sobrecarga de infraestructura. Las configuraciones híbridas permiten mantener los datos confidenciales en las instalaciones y, al mismo tiempo, aprovechar la escalabilidad de la nube para los picos de trabajo y la experimentación.
Los LLM locales requieren altos costos iniciales de hardware, mantenimiento continuo, personal calificado y planificación de la capacidad. Se enfrenta a limitaciones de escalamiento, gastos de alimentación y refrigeración y actualizaciones más lentas. La gestión de los parches de seguridad, las actualizaciones de los modelos y la fiabilidad de la infraestructura añade complejidad operativa en comparación con los servicios de IA basados en la nube totalmente gestionados.
TrueFoundry simplifica la implementación local de LLM al integrar la orquestación de Kubernetes, la programación de GPU, el servicio de modelos, la supervisión y los controles de seguridad. Obtiene una administración centralizada, un RBAC, una capacidad de observación y una escalabilidad fluida en todos los entornos. Sus motores de inferencia preintegrados y sus funciones listas para el cumplimiento le ayudan a implementar la IA de nivel de producción de forma segura y eficiente.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


