

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Los modelos lingüísticos de gran tamaño se están convirtiendo rápidamente en una capa central del software empresarial. Lo que comenzó como una experimentación basada en la nube con API alojadas ahora está evolucionando hacia sistemas de nivel de producción integrados en herramientas internas, aplicaciones orientadas al cliente y flujos de trabajo automatizados.
A medida que se produce este cambio, muchas organizaciones se enfrentan a una dura realidad: no todas las cargas de trabajo de IA pueden ejecutarse en la nube pública.
Los datos empresariales confidenciales, la propiedad intelectual patentada, las cargas de trabajo reguladas, las aplicaciones de latencia crítica y las obligaciones de cumplimiento impulsan a los equipos a implementar LLM en infraestructura local o privada. Sin embargo, el simple hecho de utilizar modelos de alojamiento automático no resuelve el problema operativo más amplio. A medida que se conectan más equipos, aplicaciones y modelos, las organizaciones necesitan una forma coherente de controlar el acceso, hacer cumplir las políticas, supervisar el uso y gestionar los costos en todo su ecosistema de LLM.
Aquí es donde un Infraestructura local de LLM Gateway se convierte en fundamental.
En lugar de permitir que cada aplicación se integre directamente con los modelos individuales, un LLM Gateway introduce una capa de control centralizada que rige la forma en que se accede a los modelos y se utilizan. En los entornos locales, esta puerta de enlace se convierte en la columna vertebral que permite a las empresas ampliar la adopción de la LLM de forma segura, compatible y eficiente sin sacrificar la visibilidad ni el control.
Un Puerta de enlace LLM es una capa centralizada de acceso y gobierno que se encuentra entre las aplicaciones y los modelos de lenguaje. En lugar de que las aplicaciones llamen directamente a los modelos, todas las solicitudes de LLM pasan por la puerta de enlace, que refuerza los controles de seguridad, enrutamiento, observabilidad y políticas en un solo lugar.
En un configuración local, tanto la puerta de enlace como los modelos se ejecutan completamente dentro de la infraestructura de la organización, como un centro de datos, una nube privada (VPC) o un entorno aislado. Esto garantiza que las indicaciones, las respuestas, las incrustaciones y los metadatos nunca superen los límites controlados.
En un nivel superior, una puerta de enlace de LLM local proporciona:
Al abstraer el acceso al modelo detrás de una API estandarizada, la puerta de enlace desvincula el desarrollo de aplicaciones de la infraestructura del modelo. Los equipos pueden cambiar de modelo, introducir versiones ajustadas o aplicar nuevas reglas de gobierno sin modificar el código de la aplicación.
En entornos locales donde la infraestructura es finita, los requisitos de cumplimiento son estrictos y la complejidad operativa es alta, esta capa de puerta de enlace centralizada es lo que hace viable la adopción de la LLM a gran escala. Transforma los modelos autohospedados de despliegues aislados a una plataforma de IA gobernada y lista para la producción.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Ejecutar un LLM en las instalaciones rara vez es solo una decisión de infraestructura. Por lo general, está impulsado por requisitos empresariales no negociables en torno al control, la seguridad y la gobernanza de los datos. Un Puerta de enlace LLM es lo que hace que estas implementaciones sean prácticas a escala.
Las empresas suelen gestionar entradas confidenciales, como documentos internos, registros de clientes, código fuente o datos clasificados. En entornos regulados, es inaceptable que incluso los datos transitorios y rápidos salgan de una infraestructura controlada.
Una pasarela de LLM local garantiza que:
Esto es especialmente importante para las organizaciones que operan bajo estrictos requisitos de soberanía o localización de datos.
Las integraciones directas entre la aplicación y el modelo crean límites de seguridad fragmentados. Cada servicio termina administrando sus propias credenciales, permisos y lógica de acceso, lo que dificulta la aplicación de estándares de seguridad uniformes.
Un LLM Gateway centraliza:
Al enrutar todo el tráfico a través de una única capa de control, las empresas reducen significativamente su superficie de ataque y ganan confianza en la forma en que se accede a los modelos.
Los marcos regulatorios requieren cada vez más que las organizaciones respondan a preguntas como:
Una pasarela de LLM local proporciona registros de auditoría integrados de forma predeterminada. Cada solicitud se puede registrar, medir y rastrear sin depender de los equipos de aplicaciones individuales para implementar correctamente la lógica de cumplimiento.
Esto es esencial para los entornos sujetos al RGPD, ITAR, HIPAA o a los estándares de gobierno interno.
Los recursos de GPU locales son limitados y costosos. Sin controles centralizados, los equipos pueden consumir fácilmente en exceso la capacidad de inferencia o implementar cargas de trabajo ineficientes.
Una pasarela de LLM permite:
Esto permite a las organizaciones tratar la inferencia de LLM como un recurso administrado en lugar de como un gasto descontrolado.
Un local LLM Gateway no es un servicio único. Es un pila de infraestructura en capas diseñado para controlar cómo se accede, se gobierna y se opera a los modelos en los entornos empresariales.
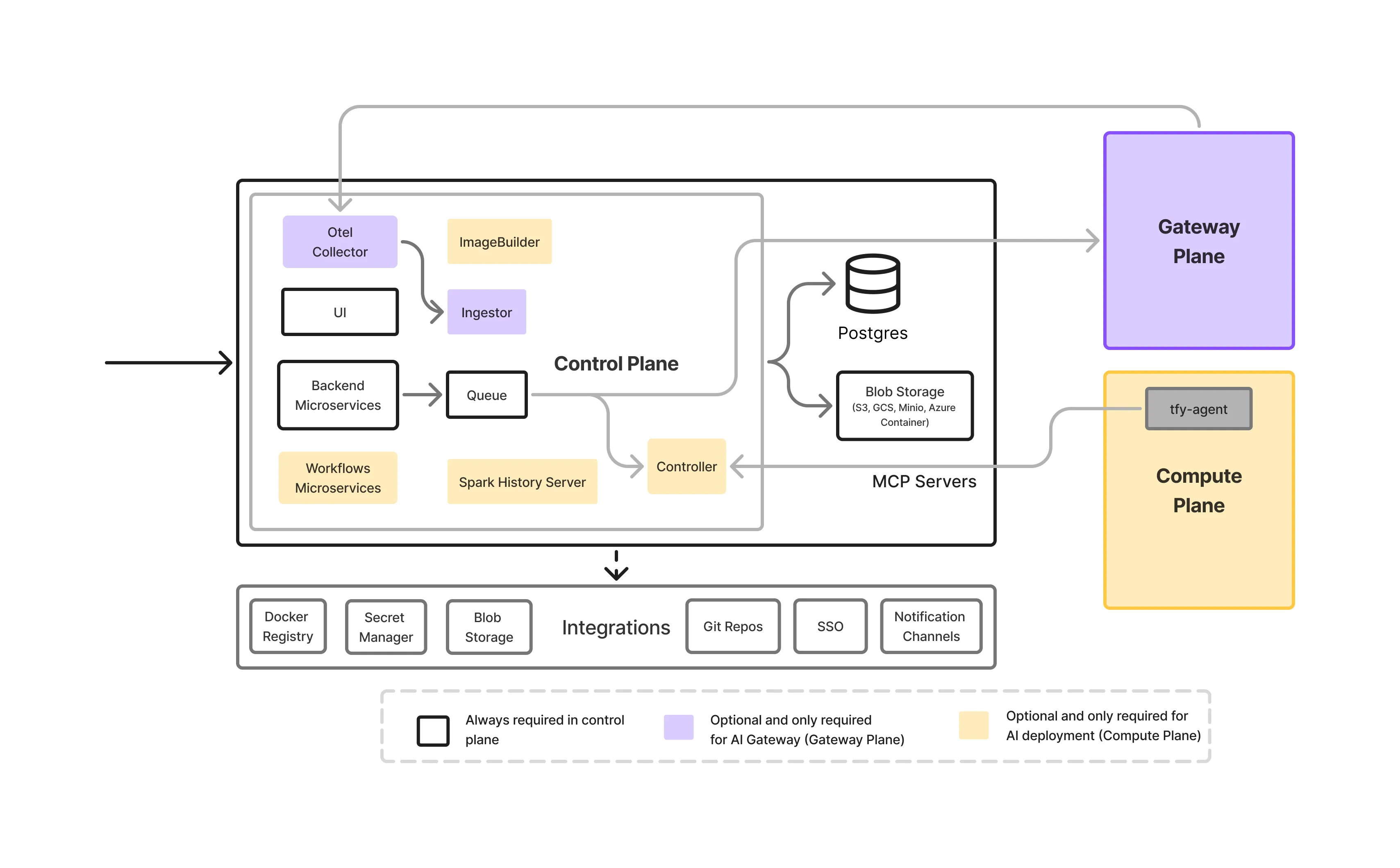
Esta es la puerta principal para todo el tráfico de LLM.
Gestiona la autenticación, la autorización, la validación de solicitudes y las decisiones de enrutamiento. Al aplicar las políticas de forma centralizada, el plano de control elimina la necesidad de que los equipos de aplicaciones integren la lógica de seguridad o gobernanza en su código.
Esta capa es responsable de modelo de servicio, que aloja los LLM reales que se ejecutan en las instalaciones y los expone para una inferencia acelerada por GPU de baja latencia, que incluye:
La pasarela abstrae estos modelos en una API unificada, lo que permite a los equipos cambiar o actualizar los modelos sin afectar a las aplicaciones.
La visibilidad es fundamental en los entornos locales donde los recursos son limitados.
La puerta de enlace proporciona:
Esto permite a los equipos comprender cómo se utilizan los modelos e identificar los problemas de rendimiento o costos de manera temprana.
Las reglas de gobierno se definen una vez y se aplican en todas partes.
Esto incluye:
La gobernanza centralizada evita que las políticas se desvíen entre los equipos y las aplicaciones.
Los servicios de puerta de enlace y modelo suelen ejecutarse en una infraestructura basada en Kubernetes compatible con GPU. Esta capa proporciona:
Garantiza que la puerta de enlace funcione de manera confiable como parte de una pila de IA local más amplia.
En una configuración local, la puerta de enlace LLM actúa como capa de control central entre aplicaciones y modelos autohospedados. Todas las solicitudes pasan por esta capa, lo que garantiza una seguridad, una gobernanza y una observabilidad coherentes.
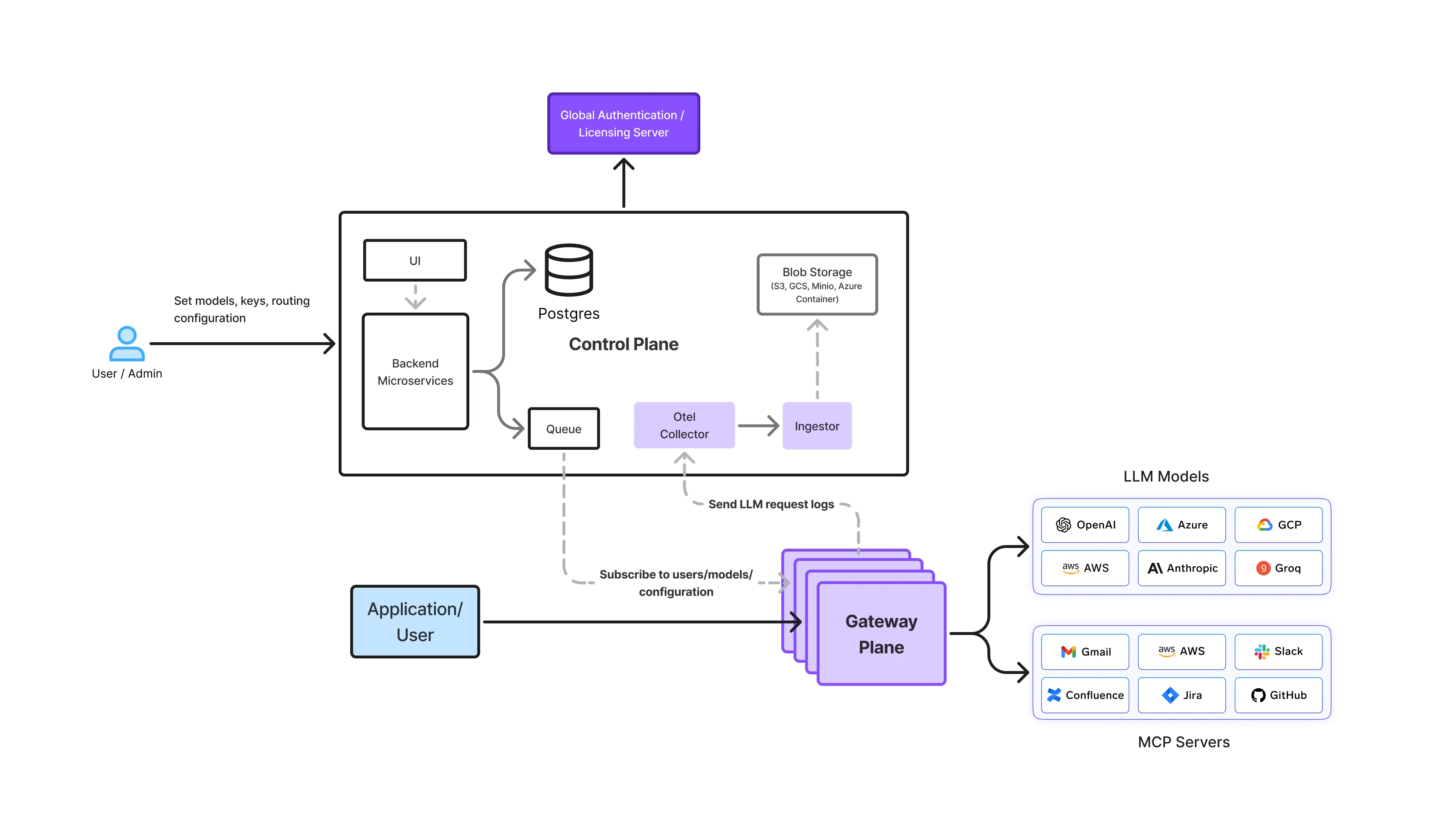
Las empresas implementan las pasarelas de LLM locales de diferentes maneras según los requisitos de seguridad, cumplimiento y conectividad. La arquitectura de las puertas de enlace sigue siendo la misma, el modelo de implementación cambia.
En entornos altamente regulados, la infraestructura funciona con sin acceso a una red externa.
En estas configuraciones, LLM Gateway proporciona un control total al tiempo que cumple con los estrictos requisitos de aislamiento.
Muchas empresas implementan pasarelas de LLM dentro de sus propias cuentas en la nube o redes privadas.
Este modelo es común para las organizaciones reguladas de SaaS y servicios financieros.
Algunas organizaciones dividen las cargas de trabajo en función de la sensibilidad.
La puerta de enlace garantiza políticas consistentes incluso cuando hay varios entornos de ejecución involucrados.
Si bien las pasarelas de LLM locales brindan control y cumplimiento, también presentan desafíos operativos que las empresas deben planificar.
La administración local de las cargas de trabajo de inferencia respaldadas por la GPU requiere una planificación cuidadosa de la capacidad. Sin la automatización, escalar modelos o gestionar los picos de tráfico puede resultar complicado desde el punto de vista operativo.
Los entornos locales tienen un procesamiento finito. Un enrutamiento deficiente o la falta de controles de solicitudes pueden provocar problemas de latencia o infrautilizar las GPU. La administración centralizada del tráfico es esencial para equilibrar el rendimiento y la eficiencia.
A medida que varios equipos adoptan las LLM, las reglas de gobierno pueden cambiar fácilmente si se aplican a nivel de aplicación. Mantener controles de acceso y políticas de uso coherentes en todos los entornos es difícil sin una puerta de enlace centralizada.
Las empresas deben mantener registros claros del uso de LLM sin sobrecargar el almacenamiento ni afectar el rendimiento. Lograr el equilibrio adecuado entre la observabilidad y los gastos generales es un desafío común.
Las empresas que tienen éxito con las implementaciones de LLM locales tratan la puerta de enlace como infraestructura básica, no solo un proxy de API.
Todas las aplicaciones y los agentes deben acceder a los modelos exclusivamente a través de la pasarela. Esto elimina las integraciones clandestinas y garantiza una seguridad y una gobernanza uniformes.
Las aplicaciones nunca deben depender de puntos finales de modelos específicos. La abstracción de los modelos detrás de la pasarela permite a los equipos intercambiar, actualizar o ajustar los modelos sin cambiar el código.
Los controles de acceso, los límites de velocidad y las reglas de uso deben residir en la capa de puerta de enlace, no dentro de la lógica de la aplicación. Esto evita que las políticas se desvíen entre equipos y entornos.
El desarrollo, la puesta en escena y la producción deben aislarse a nivel de infraestructura y políticas. Esto reduce el riesgo y hace que la experimentación sea más segura.
Capture suficiente telemetría para la auditabilidad y la optimización y, al mismo tiempo, oculte o limite los datos sensibles de las solicitudes cuando sea necesario. La observabilidad debería permitir el control, no introducir nuevos riesgos.
Seguir estas prácticas garantiza que las pasarelas de LLM locales permanezcan seguro, escalable y administrable a medida que crece la adopción.
A medida que las empresas van más allá de la experimentación e incorporan grandes modelos lingüísticos en los sistemas básicos, el control se vuelve tan importante como la capacidad. Las implementaciones locales abordan las necesidades de residencia, seguridad y cumplimiento de los datos, pero sin una capa de acceso centralizada, se fragmentan rápidamente y son difíciles de controlar.
Un Infraestructura local de LLM Gateway proporciona el plano de control que falta. Estandariza la forma en que las aplicaciones interactúan con los modelos, aplica políticas consistentes y brinda la visibilidad necesaria para operar los LLM de manera responsable y a escala.
Eligiendo el mejor puerta de enlace LLM para las implementaciones locales requiere equilibrar la gobernanza, el rendimiento y la simplicidad operativa en lugar de centrarse únicamente en el enrutamiento de solicitudes.
En lugar de tratar los modelos autohospedados como servicios aislados, las organizaciones que adoptan un enfoque centrado en la puerta de enlace convierten los LLM en una infraestructura empresarial gestionada: segura, observable y lista para el crecimiento a largo plazo.
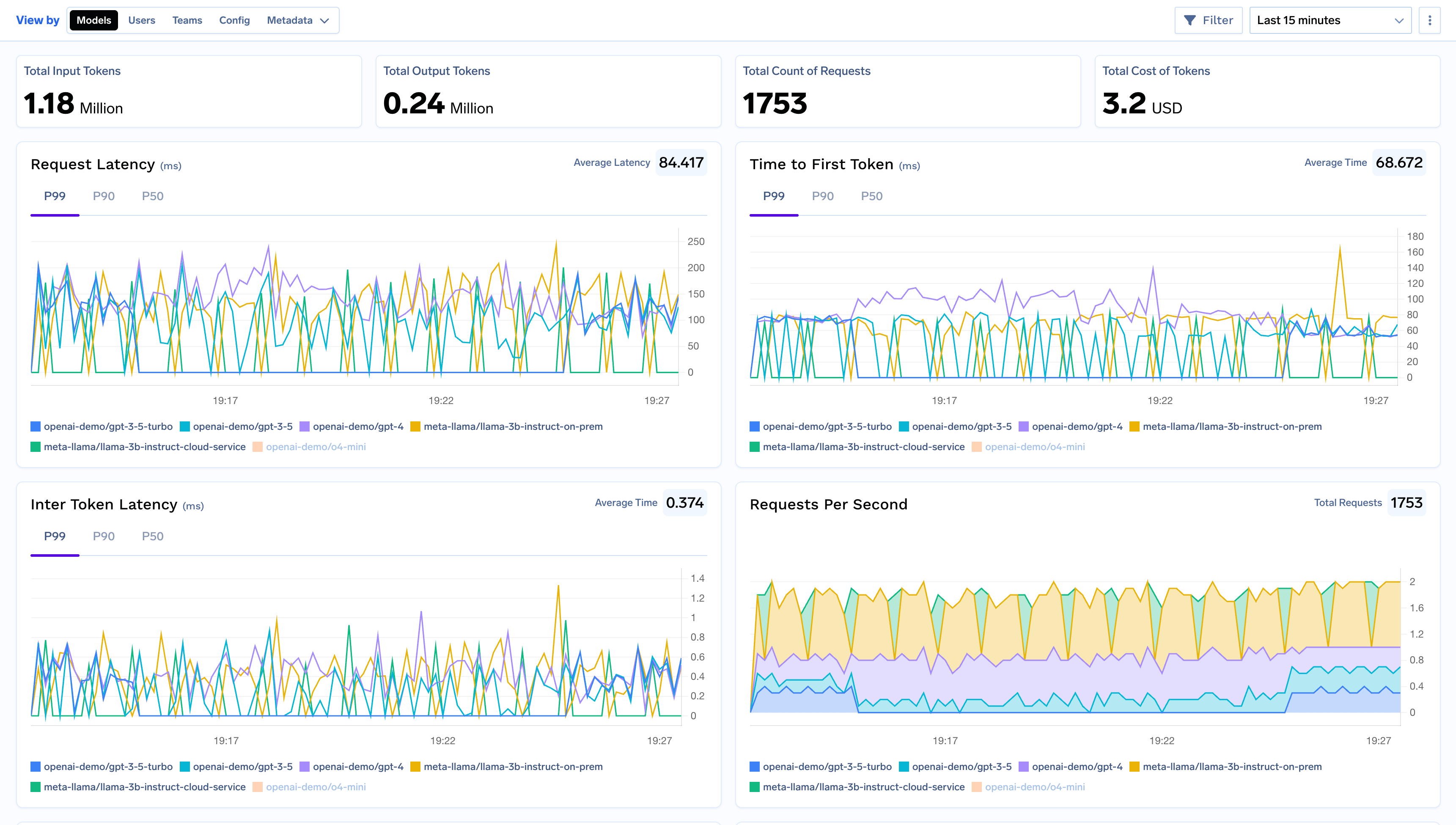
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


