

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: May 29, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Los grandes modelos lingüísticos han cruzado un umbral importante. Lo que comenzó como experimentos aislados y proyectos piloto ahora se ha convertido en cargas de trabajo de producción integradas en los sistemas empresariales. La atención al cliente, la búsqueda interna de conocimientos, el desarrollo de software, la analítica y los agentes autónomos confían cada vez más en los LLM como elementos fundamentales, en lugar de como mejoras opcionales.
Este cambio ha expuesto una nueva clase de desafíos de infraestructura. Las cargas de trabajo de LLM se comportan de manera muy diferente a los servicios de aplicaciones tradicionales. Los costes aumentan en función de los tokens, no de las solicitudes, la latencia varía considerablemente según los proveedores y las regiones, y los modos de fallo (tiempos de espera, alucinaciones o respuestas parciales) suelen ser poco claros. A medida que las organizaciones adoptan varios modelos de diferentes proveedores, estos problemas se agravan rápidamente.
Para la mayoría de las empresas, las primeras integraciones de LLM se crearon con llamadas directas a la API y lógica a nivel de aplicación. Ese enfoque no es válido a escala. Los equipos se enfrentan rápidamente a costos de inferencia impredecibles, a una visibilidad limitada del uso, a la dependencia de los proveedores y a crecientes problemas de gobernanza. La optimización de las cargas de trabajo de LLM se vuelve cada vez más difícil cuando cada aplicación implementa su propio enrutamiento, reintentos, controles de costos y registros.
A medida que la adopción de la IA se expande horizontalmente entre los equipos y verticalmente entre los entornos, La optimización de la carga de trabajo de LLM pasa de ser un problema de aplicación a un problema de infraestructura. Las empresas necesitan una capa centralizada que pueda observar, controlar y optimizar la forma en que se utilizan los modelos de forma coherente y a escala. Esta necesidad ha impulsado la aparición de pasarelas de IA como un componente fundamental de la infraestructura de IA moderna.
La optimización de las cargas de trabajo de LLM es fundamentalmente diferente de la optimización de la computación o los microservicios tradicionales. Los desafíos son sistémicos, no localizados.
En primer lugar, la dinámica de costos no es lineal. Un pequeño cambio en la estructura de los mensajes, la lógica de reintento o el tamaño del contexto puede aumentar significativamente el consumo y el gasto de los tokens. Sin visibilidad centralizada y estructurada Solución de seguimiento de costos LLM, estos cambios suelen pasar desapercibidos hasta que los costos suben. Los controles a nivel de aplicación carecen del contexto global necesario para hacer cumplir los presupuestos o comparar la eficiencia entre equipos y casos de uso.
En segundo lugar, la variabilidad del rendimiento es inherente. Esto se hace aún más visible durante Inferencia de LLM, donde la latencia y el rendimiento varían según los modelos, los proveedores y las regiones, y fluctúan en función de la carga y la disponibilidad. La codificación rígida de un solo proveedor o modelo en una aplicación crea fragilidad. Cuando se producen interrupciones o se limitan las tasas, los equipos se ven obligados a adoptar soluciones reactivas en lugar de a realizar una optimización proactiva.
En tercer lugar, la adopción de varios modelos introduce complejidad operativa. Las empresas utilizan cada vez más una combinación de modelos de primera calidad para flujos de trabajo críticos y modelos de menor coste para tareas de gran volumen o no críticas. Administrar esta combinación de manera eficiente requiere decisiones de enrutamiento que equilibren el costo, la calidad y la latencia, decisiones que no deberían incluirse en el código de la aplicación.
Por último, gobernanza y las presiones de cumplimiento siguen aumentando. Las organizaciones deben hacer cumplir los controles de acceso, supervisar el uso, mantener los registros de auditoría y garantizar la residencia de los datos en todas las regiones. Estos requisitos afectan a todas las cargas de trabajo de la IA y no pueden abordarse de manera eficaz en función de cada aplicación.
En conjunto, estos factores dejan en claro que la optimización de la carga de trabajo de LLM no se puede resolver poco a poco. Requiere una capa de control centralizada que tenga visibilidad de todo el tráfico de inteligencia artificial y la autoridad necesaria para aplicar las políticas de manera coherente.
Las pasarelas de IA abordan este desafío al actuar como plano de control para cargas de trabajo de LLM. Ubicada entre las aplicaciones y los proveedores de modelos, una puerta de enlace de IA centraliza la forma en que se enrutan, observan, controlan y optimizan las solicitudes de LLM.
A diferencia de las pasarelas de API tradicionales, las pasarelas de IA están diseñadas específicamente para las características de las cargas de trabajo de LLM. Comprenden el comportamiento específico de cada modelo, los precios basados en fichas, las ventajas y desventajas de la latencia y la necesidad de una capacidad de observación detallada. Esto permite implementar las estrategias de optimización una vez en la capa de infraestructura y aplicarlas de manera uniforme en todas las aplicaciones.
A un alto nivel, las pasarelas de IA permiten la optimización de la carga de trabajo de LLM al:
Este enfoque arquitectónico desvincula la lógica de la aplicación de la administración de modelos. Los desarrolladores se centran en crear funciones basadas en la inteligencia artificial, mientras que los equipos de plataformas mantienen el control sobre el rendimiento, los costos y los riesgos.
A medida que las empresas amplían el uso de los LLM, esta separación se vuelve crítica. Sin ella, los esfuerzos de optimización son fragmentarios, reactivos y difíciles de mantener. Con él, las organizaciones obtienen una forma coherente, mensurable y repetible de ejecutar las cargas de trabajo de LLM de manera eficiente, independientemente del número de modelos, equipos o aplicaciones involucrados.
A medida que las organizaciones maduran en el uso de los LLM, las estrategias de optimización se vuelven más sistemáticas e impulsadas por la infraestructura. Para 2026, varios patrones se convertirán en práctica estándar entre las empresas que ejecutan cargas de trabajo de LLM a gran escala.
En lugar de tratar la selección de modelos como una opción fija, las empresas están adoptando orquestación rentable. En este modelo, las pasarelas de IA equilibran dinámicamente el costo, la calidad y la latencia en función del contexto de cada solicitud.
Por ejemplo:
Este enfoque permite a las organizaciones optimizar el gasto sin comprometer la experiencia del usuario. Con el tiempo, también crea un ciclo de retroalimentación en el que los datos de uso reales sirven de base para tomar mejores decisiones de orquestación.
Los requisitos normativos y las realidades geopolíticas están cambiando la forma en que se despliegan los sistemas de IA. Las empresas operan cada vez más pilas de IA geoparticionadas, donde las cargas de trabajo de LLM se aíslan por región para cumplir con los requisitos de residencia, soberanía y cumplimiento de los datos.
En la práctica, esto significa:
Las pasarelas de IA desempeñan un papel central en la aplicación de estas restricciones y, al mismo tiempo, proporcionan un modelo operativo unificado en todas las regiones.
A medida que aumenta el uso de la LLM, las organizaciones dejan de enviar repetidamente grandes contextos a los modelos. En cambio, están adoptando sistemas de IA basados en herramientas, donde los modelos recuperan información bajo demanda a través de interfaces controladas.
Este turno:
Las pasarelas de IA median cada vez más no solo en las llamadas a modelos, sino también en la ejecución de herramientas y API, lo que garantiza que los sistemas de IA interactúen con los datos empresariales de forma controlada y auditable.
El auge de los agentes autónomos y semiautónomos presenta nuevos desafíos de optimización. Los agentes suelen realizar llamadas a varios modelos, invocar herramientas y ejecutar flujos de trabajo prolongados.
Las organizaciones líderes están ampliando las estrategias de optimización a la capa de agentes de la siguiente manera:
Las pasarelas de IA están evolucionando para soportar este cambio y actúan como una capa de mediación tanto para la inferencia del modelo como para la ejecución de los agentes.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

La elección de una puerta de enlace de IA no es una decisión de herramientas, es una compromiso de infraestructura. Para la mayoría de las empresas, esta capa se encuentra en la ruta crítica de todas las aplicaciones impulsadas por el LLM, lo que hace que sus elecciones de diseño sean difíciles de revertir más adelante. Como resultado, la evaluación debería centrarse menos en las funciones a nivel de superficie y más en el ajuste arquitectónico, la madurez operativa y la flexibilidad a largo plazo.
A continuación se muestra un marco práctico que los ejecutivos técnicos pueden utilizar para evaluar las pasarelas de IA específicamente desde el punto de vista de la optimización de la carga de trabajo de LLM.
Una puerta de enlace de IA líder debería permitir un verdadero uso multimodelo sin obligar a las aplicaciones a cambiar cuando cambian los modelos o los proveedores.
Preguntas clave que debe hacerse:
Si la elección del modelo se filtra en la lógica de la aplicación, la optimización será lenta y frágil.
La optimización del LLM es imposible sin la visibilidad de los costos. Las pasarelas deben proporcionar información y hacer cumplir las normas en el nivel en el que se toman las decisiones.
Busque:
Una puerta de enlace que solo informe sobre el uso agregado no es suficiente para una optimización real.
Como la puerta de enlace se encuentra en la ruta activa, las características de rendimiento son importantes.
Evalúe:
Incluso una pequeña penalización del rendimiento puede agravarse a gran escala.
La optimización depende de los bucles de retroalimentación. La puerta de enlace debe actuar como el sistema de registro de la actividad de LLM.
Evalúe si la puerta de enlace proporciona:
Si la observabilidad parece afianzada, la optimización será reactiva en lugar de sistemática.
La optimización debe coexistir con los controles de riesgo empresariales.
Las consideraciones clave incluyen:
Una puerta de enlace que requiere un equilibrio entre la optimización y el cumplimiento no escalará en entornos regulados.
Por último, evalúe cómo se ajusta la puerta de enlace a su infraestructura y modelo operativo existentes.
Considera:
Cuanto más estrechamente se integre la puerta de enlace con su plataforma, más fácil será operar a largo plazo.
True Foundry la arquitectura se basa en una premisa clara: Optimización de cargas de trabajo de LLM es un problema de infraestructura, no una responsabilidad de la aplicación. Como resultado, su AI Gateway está diseñado como un plano de control de primera clase que se encuentra en el centro del conjunto de IA empresarial.
En una implementación de TrueFoundry, las aplicaciones y los agentes nunca interactúan directamente con los proveedores de modelos. En cambio, todo el tráfico de LLM fluye a través del Puerta de enlace de IA, que actúa como una interfaz única y estable para la inferencia, el enrutamiento, la observabilidad y la gobernanza.
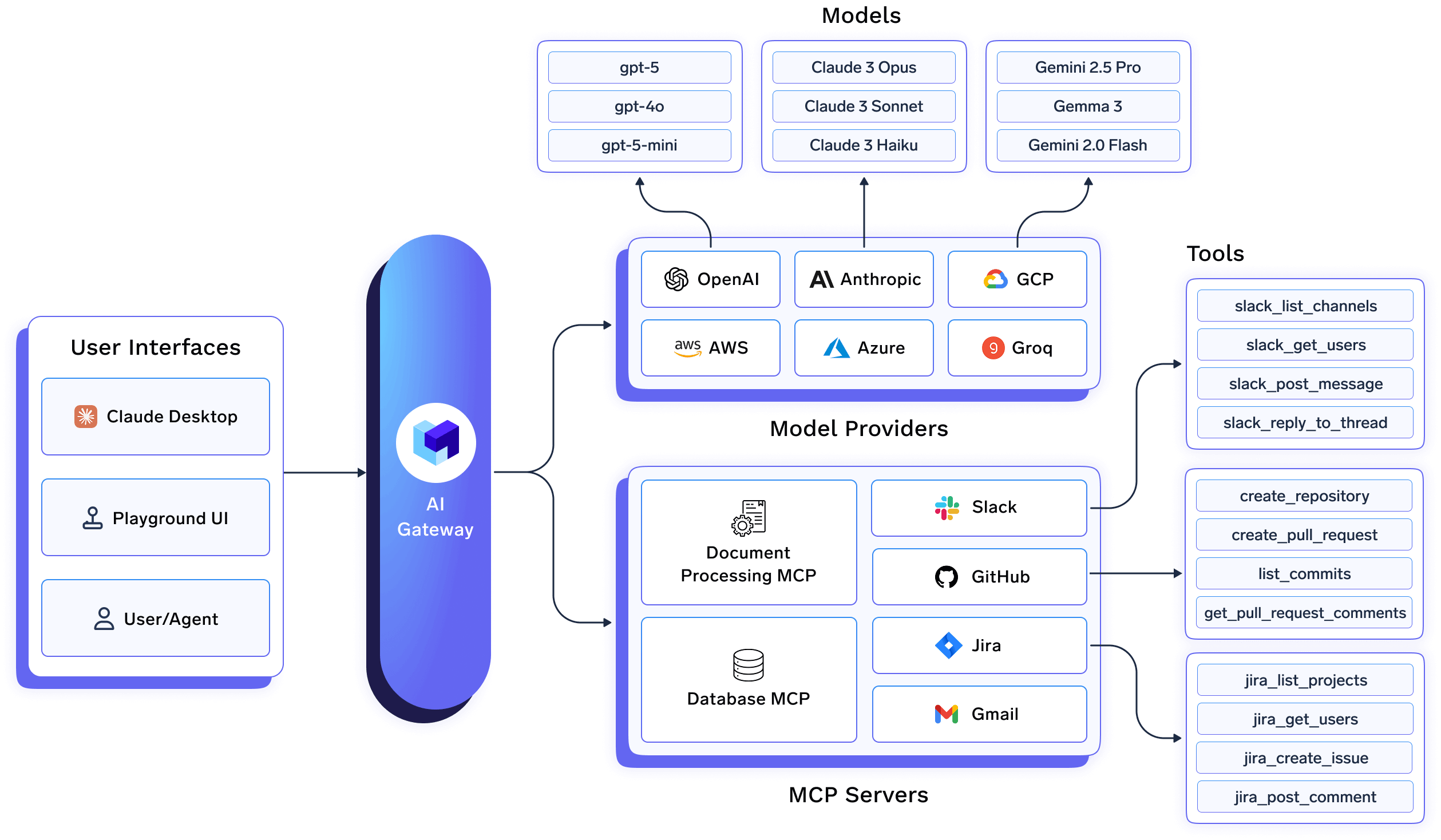
A nivel arquitectónico, esto significa:
Este diseño elimina las preocupaciones específicas del modelo del código de la aplicación y permite que las estrategias de optimización evolucionen de forma independiente.
La puerta de enlace de IA de TrueFoundry permite una verdadera operación multimodelo al abstraer las API específicas del proveedor en un solo contrato. Las decisiones de enrutamiento, como qué modelo usar, cuándo recurrir o cómo equilibrar el costo con la latencia, se gestionan de forma centralizada en la puerta de enlace.
En la práctica, esto permite a los equipos de la plataforma:
Como el enrutamiento se gestiona en la puerta de enlace, los cambios en los precios, el rendimiento o la disponibilidad de los proveedores se pueden abordar de inmediato, en lugar de requerir cambios a nivel de aplicación.
Un principio fundamental de la arquitectura de TrueFoundry es que la puerta de enlace de IA funciona como sistema de registro de todas las actividades de LLM. Cada solicitud que pasa por la pasarela se captura con metadatos detallados, que incluyen la selección del modelo, el uso de los tokens, la latencia y el contexto de la solicitud.
A diferencia de muchas plataformas que centralizan estos datos en sistemas gestionados por el proveedor, el diseño de TrueFoundry garantiza que:
Este enfoque evita el problema de la «caja negra» y permite a las organizaciones crear circuitos de retroalimentación de optimización a largo plazo utilizando sus propios datos.
True Foundry Puerta de enlace de IA incorpora los controles de costos y gobierno directamente en la ruta de solicitud. En lugar de depender de informes de facturación posteriores o de herramientas externas, la optimización y el cumplimiento se realizan en tiempo real.
Las capacidades arquitectónicas clave incluyen:
Como estos controles están centralizados, todas las aplicaciones impulsadas por LLM los heredan automáticamente. Esto permite escalar el uso de la IA en todos los equipos sin duplicar la lógica de gobierno.
La puerta de enlace de IA de TrueFoundry está diseñada para implementarse donde los datos empresariales ya residen. Puede ejecutarse en VPC privadas, entornos locales o regiones de nube controladas, lo que permite a las organizaciones cumplir con los estrictos requisitos reglamentarios y de residencia de datos.
Desde el punto de vista arquitectónico, esto admite:
Este diseño se alinea con las empresas que operan en distintas jurisdicciones, donde el movimiento de datos debe controlarse estrictamente.
La arquitectura centrada en las pasarelas de TrueFoundry también está alineada con el cambio hacia los sistemas de IA basados en agentes. A medida que los agentes organizan cada vez más los flujos de trabajo de varios pasos e invocan herramientas o API, la puerta de enlace se convierte en el punto de control natural.
Dentro de este modelo, el AI Gateway puede:
Esto posiciona la puerta de enlace no solo como una capa de inferencia, sino como un plano de control de ejecución más amplio para sistemas inteligentes.
La característica que define el enfoque de TrueFoundry es que la optimización, la gobernanza y la observabilidad se implementan una vez en la capa de infraestructura y se reutilizan en todas partes. Esto reduce la complejidad operativa, mejora la coherencia y permite a las organizaciones escalar las cargas de trabajo de LLM sin perder el control.
La conclusión más amplia es que AI Gateway de TrueFoundry no se posiciona como un complemento, sino como infraestructura de IA básica. Al tratar la puerta de enlace como una capa arquitectónica de larga duración, TrueFoundry se alinea con la forma en que las empresas ya piensan sobre los sistemas críticos, como las puertas de enlace de API, las plataformas de datos y la orquestación informática.
A medida que aumenta la adopción de la LLM, la optimización ya no es una cuestión de ajuste rápido o selección de modelos, sino de decisión de infraestructura. La volatilidad de los costos, la variabilidad del rendimiento y los requisitos de gobierno exigen una capa de control centralizada que pueda funcionar en todos los modelos, equipos y aplicaciones.
Las pasarelas de IA han surgido como esa capa. Al consolidar el enrutamiento, la observabilidad, los controles de costos y la aplicación de políticas, convierten la optimización de la LLM en una capacidad sistemática en lugar de en una carga operativa continua.
Plataformas como True Foundry reflejan este cambio al tratar el AI Gateway como una pieza central de la infraestructura de IA empresarial. Para los líderes técnicos, el mensaje es claro: la escala sostenible de la LLM depende menos de la elección del modelo correcto y más de la creación de la base adecuada para ejecutarlos.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


