

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Con la gran expansión de la gama de casos de uso del aprendizaje automático en los últimos años, la necesidad de escalar las operaciones en torno a la formación, el despliegue y la supervisión de estos modelos también se ha vuelto muy importante. Muchos de estos problemas son similares a los que se han «resuelto» en los casos de uso general del software. Kubernetes es uno de esos programas de código abierto que ha consolidado el ecosistema nativo de la nube en torno a sí mismo al servir como plataforma subyacente.
Por lo tanto, es imperativo explorar si es útil que Kubernetes se aproveche para un caso de uso de aprendizaje automático. Comencemos primero con Kubernetes en sí y lo que tiene de interesante.

Crédito: Kubernetes
💡 Kubernetes es un motor de orquestación de contenedores de código abierto para automatizar el despliegue, el escalado y la administración de aplicaciones en contenedores.
En términos más sencillos, Kubernetes proporciona una forma sencilla y estandarizada de ejecutar y operar cargas de trabajo que deben escalarse dinámicamente en varias máquinas.
Repasemos algunas de las funciones más populares -
Estas son solo algunas de las funciones que están disponibles de forma predeterminada. De hecho, las herramientas creadas con Kubernetes como capa subyacente resuelven una gran cantidad de casos de uso. Hablaremos de herramientas específicas en un número posterior.
Con la comprensión de qué es Kubernetes y cuáles son las principales funciones que proporciona en un escenario de desarrollo de software, analicemos cuáles son los problemas específicos que puede resolver en el flujo de trabajo de un científico de datos.
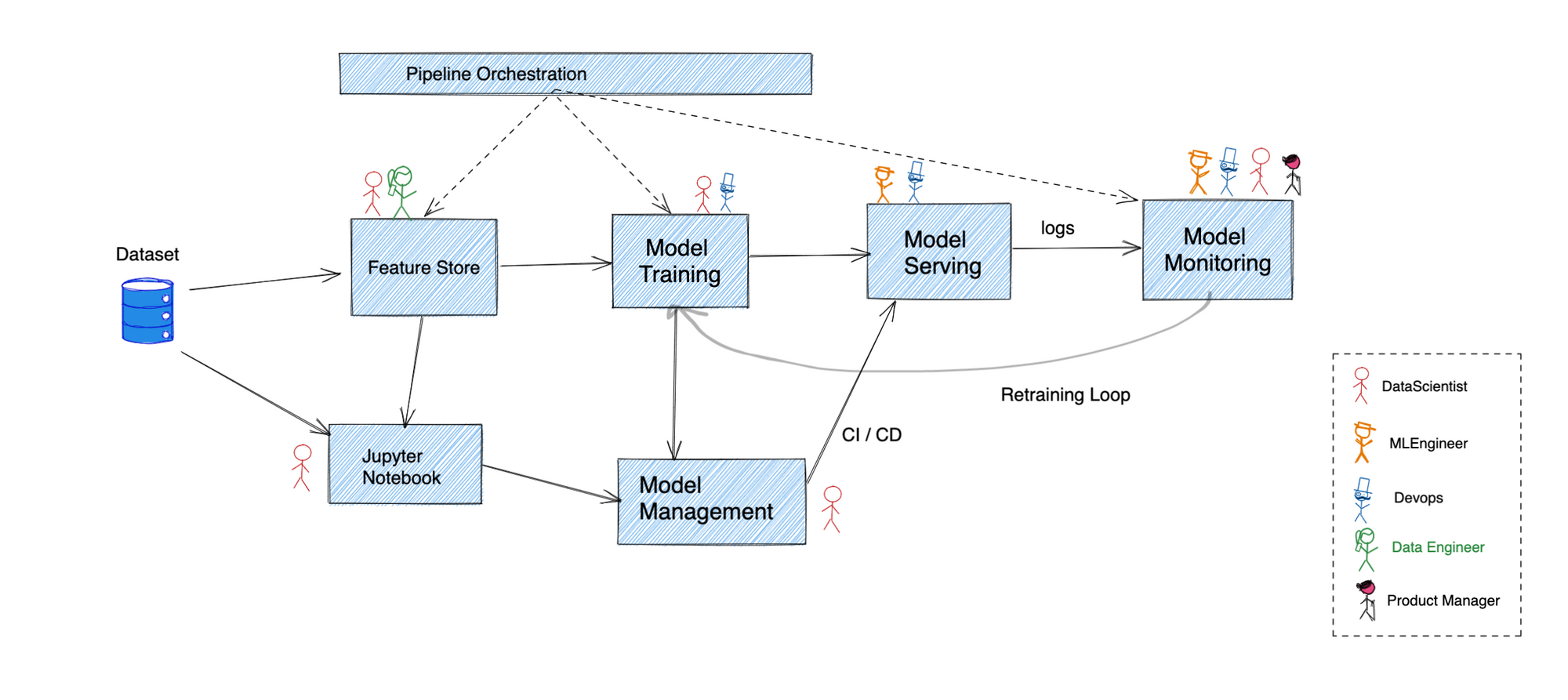
La figura anterior ofrece un resumen general de cómo funciona una canalización típica de ciencia de datos. Muchas empresas han optado por utilizar una amplia variedad de soluciones a medida con funciones superpuestas para unirlas todas.
Realizaremos cada uno de estos pasos para tratar de entender dónde encaja Kubernetes a la perfección:
Antes de que los datos sin procesar puedan ser útiles, primero deben transformarse en entradas desinfectadas para el proceso de capacitación del modelo. Aquí es donde los almacenes de funciones entran en escena al realizar la transformación, el almacenamiento y el servicio de los datos de las funciones.
Kubernetes admite el despliegue de cargas de trabajo con estado y se integra muy bien con los proveedores de nube para proporcionar persistencia sin problemas.
La mayoría del desarrollo de modelos comienza con un ingeniero de aprendizaje automático que escribe código en un cuaderno Jupyter y, para muchos, eso es casi todo lo que se necesita. Proporciona una interfaz REPL para ejecutar el código python. Esto empieza por estar alojado en ordenadores portátiles personales, pero es mejor tener un grupo centralizado de cuadernos jupyter alojados que pueden usar varias personas.
El modelo declarativo de Kubernetes, junto con la compatibilidad con los sistemas de almacenamiento persistentes, hacen que sea trivial alojar un conjunto de ordenadores portátiles y permitir el control de acceso a los ordenadores portátiles individuales para garantizar una colaboración eficaz.
Cualquier algoritmo escrito en un cuaderno debe alimentarse con datos de entrenamiento para obtener un artefacto modelo como resultado. Esto se puede hacer en el propio portátil en casos de uso más pequeños, pero se requiere una canalización mucho más potente para conjuntos de datos más grandes. Por lo general, la validación con el conjunto de datos de prueba también se realiza aquí antes de que el artefacto se utilice para realizar inferencias en producción.
Existen varias soluciones para organizar una canalización de DAG en kubernetes. Airflow tiene soporte nativo para kubernetes, mientras que Kubeflow se ha creado completamente sobre kubernetes. Todas las principales soluciones de monitoreo brindan una integración de primera clase con Kubernetes, lo cual es esencial para ejecutar tuberías aptas para la producción.
Esta etapa se encarga de almacenar y versionar el conjunto de datos y el modelo. Esto garantiza que cualquier artefacto del modelo siga siendo reproducible durante el tiempo que sea necesario. Se puede establecer un paralelismo con la forma en que se realiza la administración del código con git.
Si bien el almacén de datos subyacente para dichos sistemas de administración se puede alojar en el propio Kubernetes, en muchos casos es mejor utilizar una solución gestionada de un proveedor de nube. En estos casos, la mayoría de los proveedores de servicios en la nube integran sin problemas sus sistemas de IAM con los de Kubernetes, lo que permite acceder de forma segura a los datos desde fuera del clúster sin tener que almacenar las credenciales de acceso.
Finalmente, el artefacto modelo se prepara para que un sistema de producción pueda hacer inferencias sobre él. Por lo general, esto implica incluir un modelo en un marco de API y permitir que otros servicios llamen al modelo para hacer inferencias. Aquí entran en juego cuestiones similares a las de la ingeniería de software, como authn/authz, la escalabilidad, la confiabilidad, etc.
Aquí es donde brilla Kubernetes. La mayoría de las funciones de las que hablamos en la sección anterior se vuelven críticas en esta etapa.
Como cualquier sistema de producción, la supervisión continua del modelo actualmente implementado es esencial para asegurarse de que su sistema se comporte de la manera esperada. Las métricas a tener en cuenta pueden incluir todo, desde la precisión real de las predicciones hasta la latencia y el rendimiento que el sistema puede soportar.
Muchas soluciones de monitoreo se integran estrechamente con Kubernetes. Descubre un objetivo para extraer métricas, realizar cálculos sobre él y almacenarlo para su uso posterior se puede realizar sin ninguna dependencia externa.
Todo el panorama en torno a Kubernetes ha estado explotando y ya existen muchas herramientas. Sin embargo, hay algunos escollos que cualquier organización debe tener en cuenta antes de adoptarlo al por mayor. En el próximo número hablaremos de ellos y de cómo se pueden mitigar.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


