Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.
A medida que las organizaciones implementan más aplicaciones impulsadas por la LLM en todos los equipos, surge una nueva capa de infraestructura esencial: la Puerta de enlace de IA. Una puerta de enlace de IA se encuentra entre sus aplicaciones y los servicios o modelos de IA subyacentes, y actúa como un plano de control central para el tráfico de IA. Proporciona acceso unificado a docenas o cientos de modelos y, al mismo tiempo, aplica las políticas empresariales en materia de seguridad, costo y observabilidad. Esto es cada vez más importante a medida que aumenta el uso: para 2026, se espera que más del 80% de las empresas utilicen inteligencia artificial generativa, y Gartner predice que, para 2028, el 70% de los equipos de ingeniería que creen aplicaciones multimodelo dependerán de las pasarelas de inteligencia artificial para mejorar la confiabilidad y controlar los costos. Sin una puerta de enlace, cada llamada de un cliente de IA debe gestionarse de forma individual, lo que se traduce en un gasto de fichas no gestionado, un registro fragmentado y brechas de seguridad. En este entorno, una puerta de enlace de IA bien diseñada se convierte en nueva capa de control para la IA empresarial, proporcionando la coherencia, la gobernanza y la eficiencia de las que carecen las pasarelas de API tradicionales.
Qué es una puerta de enlace de IA y por qué es importante
Un Puerta de enlace de IA es una capa de middleware especializada que administra el tráfico entre las aplicaciones y los modelos de IA. A diferencia de las pasarelas de API convencionales, está diseñada específicamente para las cargas de trabajo de IA. Maneja Preocupaciones específicas de la IA como la limitación de velocidad a nivel de token, las respuestas de transmisión y las comprobaciones de seguridad rápidas, que las puertas de enlace HTTP normales no abordan. En la práctica, una aplicación envía primero todas las solicitudes de IA a la puerta de enlace: a continuación, la puerta de enlace autentica la solicitud, aplica los filtros o barreras de protección de contenido, la redirige al modelo apropiado y, por último, devuelve la respuesta (posiblemente con su propio procesamiento posterior) a la aplicación. Esta capa centralizada permite funciones como la orquestación de modelos (el equilibrio o la conmutación por error entre diferentes proveedores de IA) y la facturación unificada.
Gartner ha identificado cuatro tareas fundamentales que una puerta de enlace de IA debe funcionar en las empresas modernas: enrutamiento, seguridad/barandillas, control de costos, y observabilidad.
Enrutamiento: Dirige las solicitudes al modelo o proveedor más adecuado en función de las políticas (por ejemplo, elegir entre modelos más rápidos pero caros o más baratos).
Seguridad: Aplica la autenticación, la administración de claves y el filtrado de contenido desde un único punto de control. Esto incluye evitar problemas como la inyección inmediata o la filtración de datos confidenciales mediante la aplicación de barreras centralizadas en las entradas y salidas.
Control de costos: Realiza un seguimiento del uso de los tokens por solicitud y aplica los presupuestos o las cuotas para evitar sobrecostos. Por ejemplo, puede almacenar en caché las solicitudes duplicadas para guardar los tokens y redirigir las solicitudes si un modelo supera el presupuesto.
Observabilidad: Registra todas las llamadas de IA y expone las métricas/rastreos para que los equipos puedan monitorear el rendimiento, las tendencias de uso y detectar anomalías en todos los modelos y aplicaciones.
Al integrar estas funciones, una puerta de enlace de IA convierte el tráfico de IA en un plano de políticas programable — tal como lo hizo Kubernetes con los contenedores. Esto resuelve problemas clave al pasar de los experimentos con IA a la producción: sin una puerta de enlace, es fácil perder la visibilidad del gasto en fichas, aplicar controles de seguridad inconsistentes y tener datos de rendimiento fragmentados. Una puerta de enlace garantiza que cada La solicitud de IA está regulada y es medible. Como señala una guía para analistas, «sin esta capa, las organizaciones tienen dificultades para controlar los costos, mantener la seguridad y monitorear el rendimiento a gran escala». En resumen, una puerta de enlace de inteligencia artificial hace que el uso de la IA esté preparado para las empresas al agregar los controles y la telemetría que requieren los equipos grandes.
¿Cuándo necesita una organización una puerta de enlace de IA?
No todos los proyectos pequeños de IA necesitan una puerta de enlace completa, pero tan pronto como surgen varios equipos, modelos o patrones de uso, una puerta de enlace se vuelve valiosa. Es probable que necesites una puerta de enlace de IA cuando:
Usas varios proveedores o modelos de IA. Cuando sus aplicaciones llaman a más de una API de LLM (por ejemplo, si combinan OpenAI, Azure o modelos personalizados), una puerta de enlace le permite acceder a ellas a través de una interfaz única y coherente. Esto evita que cada equipo reinvente la lógica de acceso y garantiza políticas de seguridad uniformes.
El uso es escalable o entre equipos. Si docenas de desarrolladores de todos los departamentos están integrando los LLM, corres el riesgo de una «IA oculta», es decir, un uso incontrolado en varias cuentas. Una pasarela de IA unifica ese tráfico, lo que permite saber quién llama a qué modelo. Gartner predice que el uso de las pasarelas aumentará significativamente a medida que se propaguen las aplicaciones multimodelo.
Los costos y los presupuestos son importantes. Cada solicitud de IA consume fichas que cuestan dinero. Un solo mensaje puede usar miles de fichas. A medida que aumenta el uso, es fácil gastar mucho dinero sin que nadie se dé cuenta. Una pasarela de IA monitoriza el uso de los tokens por solicitud y puede imponer presupuestos por equipo o por proyecto, lo que evita costes desorbitados. Si tu equipo de finanzas o plataformas se queja de que el gasto en IA es impredecible, es hora de crear una pasarela.
La seguridad y el cumplimiento son obligatorios. Para las industrias reguladas (finanzas, atención médica, etc.), necesita una auditoría central de las interacciones de la IA, controles de acceso estrictos y comprobaciones de seguridad del contenido. Una pasarela de IA proporciona exactamente eso: por ejemplo, puede bloquear la PII en las salidas o forzar la desinfección de las entradas. Si necesita cumplir con la HIPAA/SOC2 o debe integrarse con los sistemas SIEM, es esencial contar con una puerta de enlace con seguridad de nivel empresarial.
Tiene cargas de trabajo multiinquilino o de agencia. Si varias unidades de negocio o clientes utilizan la misma infraestructura de IA, es necesario aislar la carga de trabajo. El verdadero soporte multiusuario (espacios de trabajo separados, RBAC, claves de API) viene con una puerta de enlace. Del mismo modo, si despliegas agentes de IA (que utilizan protocolos como el MCP/Model Context Protocol), una puerta de enlace diseñada para los agentes puede gestionar esas llamadas a herramientas o modelos de forma centralizada.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Características clave que debe buscar en una puerta de enlace de IA
Al comparar las soluciones de puerta de enlace de IA, concéntrese en las funciones que garantizan escalabilidad, seguridad, observabilidad, y rentabilidad. Entre las capacidades importantes se incluyen:
API multimodelo unificada: La puerta de enlace debe presentar un punto final único compatible con OpenAI para modelos de llamadas, incluso si provienen de diferentes proveedores. Esto significa que puede traducir tus solicitudes a proveedores como OpenAI, Azure OpenAI, Amazon Bedrock, Gemini, Groq o incluso a modelos autohospedados mediante una interfaz estándar v1/chat/completions. Es fundamental contar con una amplia cobertura de los modelos: compruebe la compatibilidad de los principales modelos de forma inmediata y una forma sencilla de incorporar modelos nuevos o personalizados. Lo ideal sería poder cambiar de modelo mediante encabezados o cambios en la configuración sin tocar el código de la aplicación. Esta interfaz unificada simplifica el desarrollo y permite experimentar con diferentes modelos sin problemas.
Alto rendimiento y escalabilidad: Dado que la puerta de enlace envía por proxy todas las llamadas de IA de producción, debe ser rápida y escalable. Busque una sobrecarga de latencia mínima (lo ideal sería añadir unos pocos milisegundos por solicitud). La puerta de enlace debe admitir un alto nivel de RPS (solicitudes por segundo) incluso con recursos modestos; por ejemplo, una puerta de enlace bien diseñada puede gestionar cientos de RPS por núcleo de CPU. El escalado automático y la implementación en varias regiones también son fundamentales: la puerta de enlace debería poder activar módulos o instancias adicionales según la demanda y funcionar en distintas zonas o regiones para reducir la latencia para los equipos globales. Desde el punto de vista arquitectónico, muchas pasarelas implementan comprobaciones de límite de velocidad y equilibrio de carga en la memoria (no hay llamadas externas en la ruta de solicitud) para lograr latencias inferiores a 50 ms. Confirme las afirmaciones comparativas del proveedor (por ejemplo, X RPS por pod) y pruébelo con la carga esperada.
Enrutamiento, equilibrio de carga y confiabilidad: La puerta de enlace debe distribuir el tráfico de forma inteligente. Entre las funciones principales se incluyen el equilibrio de carga ponderado o basado en la latencia entre los proveedores y réplicas de modelos, los reintentos automáticos y los modelos alternativos en caso de error, y el almacenamiento en caché de las solicitudes con reconocimiento semántico. ¿Fuerte Equilibrio de carga LLM las capacidades garantizan que el tráfico se distribuya de manera inteligente entre los proveedores para mantener el rendimiento, reducir los picos de latencia y mejorar la confiabilidad de la producción. Deberías poder definir límites de tarifas por usuario o equipo para evitar el abuso, y tener cuotas o presupuestos (basados en fichas o en dólares) por proyecto. La compatibilidad con políticas de enrutamiento avanzadas (por ejemplo, enviar tráfico de alta prioridad a modelos premium o enrutar en función del tiempo de espera de las solicitudes) es una ventaja. En general, asegúrate de que la puerta de enlace pueda funcionar como un proxy resiliente para que una interrupción o un pico de API descendente no bloquee tu aplicación.
Observabilidad sólida: Cada solicitud a través de la puerta de enlace debe generar registros y métricas detallados. Las funciones esenciales de observabilidad incluyen el seguimiento de las solicitudes con metadatos detallados (texto del mensaje, modelo utilizado, tokens de entrada/salida, identidad del usuario, latencia, etc.) y paneles históricos o en tiempo real que muestran las tendencias de uso y rendimiento. La pasarela debería ofrecer ventajas de integración para tu sistema de monitorización, por ejemplo, la compatibilidad con OpenTelemetry y la fácil exportación de registros y métricas a Grafana, Prometheus, Datadog, etc. Preguntas clave: ¿Se pueden filtrar los registros y las métricas por usuario, equipo o modelo? ¿Se pueden desglosar los errores (4xx/5xx) o los eventos alternativos? Las verdaderas soluciones empresariales le permiten dividir los datos de costo y uso de la forma que necesite (por modelo, por departamento, etc.) para que pueda asignar los presupuestos con precisión. La lista de verificación de la evaluación sugiere verificar que métricas de costos y métricas de rendimiento (como el tiempo hasta el primer token) están disponibles en niveles granulares.
Seguridad, barandillas y gobernanza del acceso: La seguridad debe estar integrada. Busque la compatibilidad integrada con el filtrado de mensajes y de contenido (listas de palabras clave, reglas de expresiones regulares, políticas que tengan en cuenta el contexto) para evitar resultados inseguros o no deseados. La pasarela debería poder integrarse con filtros de contenido externos o herramientas TRism (por ejemplo, los proveedores de AWS Content Moderation o AI Guardrail). Todas las solicitudes de API se deben registrar con registros de auditoría completos y se deben poder asignar permisos detallados: por ejemplo, limitar qué equipos o usuarios pueden llamar a qué modelos. El control de acceso basado en roles (RBAC) es imprescindible: asegúrate de que la puerta de enlace admite la integración con tu SSO/IDP (SAML, OIDC, etc.) y de que las funciones y políticas se pueden sincronizar desde allí. Compruebe el cifrado de los datos en reposo o en tránsito y las certificaciones de cumplimiento (como SOC2, GDPR o HIPAA, si las necesita) en la solución SaaS o local del proveedor.
Administración de costos: Además del seguimiento de los tokens sin procesar, los controles de costos avanzados son fundamentales. La pasarela debe mantener tablas de precios (o permitir precios personalizados) para los principales proveedores, de modo que pueda calcular el coste en dólares de cada solicitud. Debe hacer cumplir las políticas de gastos, por ejemplo, enviar alertas o bloquear las solicitudes cuando un equipo alcanza el 80% de su presupuesto. Algunas pasarelas permiten preestablecer tarifas personalizadas para planes empresariales o modelos autohospedados y aplicarlas para calcular los costos. El almacenamiento semántico en caché de las respuestas (por ejemplo, mediante incrustaciones) también puede reducir drásticamente el uso, por lo que es una buena opción para ahorrar costes. En última instancia, busca la capacidad de generar informes de costos por usuario o proyecto y para ver el gasto simbólico en tiempo real.
Experiencia e integraciones de desarrolladores: Una buena puerta de enlace es perfecta para los desarrolladores. Debería ser compatible con los marcos y agentes de IA habituales, por ejemplo, con LangChain, Llamaindex o las herramientas populares sin código (n8n, Flowise) a través de su API. Comprueba si ofrece un parque de mensajes unificado o una herramienta de control de versiones para gestionar los mensajes de forma centralizada. La compatibilidad multimodal (gestión del texto, las imágenes, el audio y las incrustaciones) a través de la misma interfaz es valiosa si tus casos prácticos implican algo más que el chat. Por último, la pasarela debe proporcionar una API REST o unos SDK claros para la gestión: por ejemplo, para crear claves de API, configurar modelos, establecer presupuestos, etc. La pasarela TrueFoundry, por ejemplo, ofrece un campo de juego rápido y gestión de claves de API y funciona de forma inmediata con todos los principales marcos de LLM.
Flexibilidad de implementación: Según su postura de seguridad, es posible que necesite la puerta de enlace como una solución SaaS o autohospedada. Verifique si la puerta de enlace puede ejecutarse en la nube o en las instalaciones (TrueFoundry admite ambas) y qué infraestructura requiere (Kubernetes, etc.). Tenga en cuenta cómo se administra la configuración: busque el soporte de Terraform/Helm y la integración con GitOps si utiliza esas prácticas. Comprueba también las capacidades de implementación regional o perimetral para minimizar la latencia para los equipos globales. Por ejemplo, el SaaS de TrueFoundry se distribuye a nivel mundial y su puerta de enlace local se puede colocar en cualquier región de la nube, lo que mantiene los tiempos de respuesta por debajo de los 5 ms en la práctica.
En resumen, su evaluación debe cubrir enrutamiento y orquestación, rendimiento, observabilidad, seguridad, control de costos, y despliegue. Como paso práctico, utilice una lista de verificación estructurada para calificar cada puerta de enlace en función de estas dimensiones.
El enfoque de TrueFoundry para el diseño de pasarelas de IA
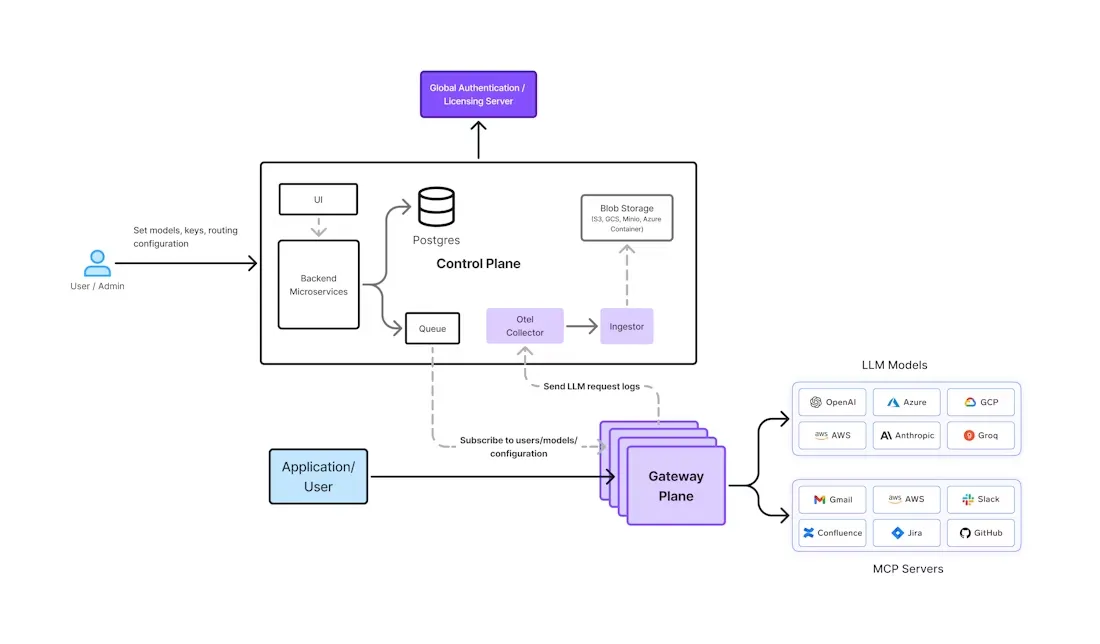
El propio portal de IA de TrueFoundry se creó desde cero teniendo en cuenta estos requisitos empresariales. Proporciona un interfaz unificada para más de 1000 LLM (OpenAI, Anthropic, Gemini, Bedrock, modelos de código abierto y más) al tiempo que incorpora la seguridad, la observabilidad y la gobernanza en su esencia. La arquitectura separa las funciones del plano de control (interfaz de usuario, base de datos de políticas, etc.) de los módulos de puerta de enlace sin estado que gestionan el tráfico de inferencias (consulte la figura siguiente).
Figura 1: Arquitectura de la puerta de enlace de IA de TrueFoundry. Un plano de control central (izquierda) lleva la configuración a los módulos de puerta de enlace distribuidos por todo el mundo (derecha). Todas las comprobaciones de políticas (autenticación, límites de velocidad, enrutamiento) se realizan en la memoria de cada pod.
True Foundry Los módulos de pasarela se suscriben a un flujo de mensajes NATS desde el plano de control. Los cambios en las políticas (como los nuevos permisos de usuario, las configuraciones del modelo o las reglas de equilibrio) se publican en NATS y están disponibles de inmediato para todos los pods. Cuando una solicitud llega a un pod de gateway, todas las comprobaciones críticas se realizan en la memoria sin saltos de red adicionales — esto incluye la autenticación JWT, las comprobaciones de RBAC, la aplicación de límites de velocidad y las decisiones modelo de equilibrio de carga. Como resultado, las pruebas de TrueFoundry muestran que los gastos de latencia son del orden de unos pocos milisegundos por solicitud. Incluso con un seguimiento completo (registrando cada número de solicitudes y fichas), el hardware moderno gestiona cientos de solicitudes por segundo por pod, y el sistema escala linealmente añadiendo más pods.
Entre bastidores, las solicitudes aprobadas se envían al proveedor de IA o punto final del modelo elegido. Si la respuesta es satisfactoria, se devuelve inmediatamente al cliente. Al mismo tiempo, los metadatos de la solicitud y la respuesta (los tokens utilizados, la latencia, el usuario y el modelo) se publican de forma asincrónica en la cola de mensajes. Un servicio de análisis de backend incorpora estos eventos a ClickHouse (a través de un almacenamiento de bloques) para calcular las métricas de uso y costes. Esta canalización asíncrona significa que el registro y el análisis nunca bloquean la ruta del tráfico en tiempo real. Los clientes del panel de control y de la API pueden entonces consultar la telemetría agregada (mediante los estándares de OpenTelemetry) para realizar un seguimiento del uso por modelo, equipo o período de tiempo.
La seguridad se aplica en todo momento. La puerta de enlace de TrueFoundry utiliza métodos detalladosRBAC para que los equipos vean e invoquen solo los modelos que pueden usar. Todas las claves y tokens de la API se pueden administrar de forma centralizada y detallada registros de auditoría capturar cada acción (marcas de tiempo, identificaciones de usuario, modelo utilizado, etc.). Contenido personalizado barandas se puede definir en el portal (por ejemplo, filtros de palabras clave o reglas que tengan en cuenta el contexto) y la puerta de enlace bloqueará o marcará cualquier respuesta que infrinja la política. TrueFoundry también se integra con los proveedores de identidad empresariales, por lo que puedes sincronizar las funciones desde tu IdP (SSO mediante SAML/OIDC) y aplicarlas automáticamente a los permisos de las pasarelas.
Otras capacidades incluyen el soporte multimodal (la misma API gestiona el texto, las imágenes, el audio y las incrustaciones sin problemas) y un sistema de administración de mensajes integrado. La puerta de enlace ofrece una Prompt Playgroundpara versionar y probar las solicitudes de forma centralizada, lo que resulta especialmente útil para los equipos que repiten las solicitudes de producción. También proporciona controles globales de presupuesto y límites de velocidad: por ejemplo, puedes establecer una cuota mensual en dólares por equipo o imponer presupuestos basados en fichas por proyecto. En la práctica, las organizaciones que utilizan la pasarela de TrueFoundry obtienen una visibilidad inmediata del gasto simbólico (incluso desglosadas por proveedor y modelo) y pueden detener o notificar automáticamente a los usuarios cuando se superan los presupuestos.
La flexibilidad de implementación es un sello distintivo del diseño de TrueFoundry. El AI Gateway puede ejecutarse como un SaaS administrado (con nodos en varias regiones de nube para lograr una baja latencia y una alta disponibilidad) o instalarse en su propio entorno de nube o local. En ambos casos, el impacto en el rendimiento es mínimo: una pregunta frecuente reciente señala que el SaaS de TrueFoundry añade menos de unos 5 ms de sobrecarga por solicitud. Como se puede implementar en cualquier clúster de Kubernetes (o incluso en el borde), puedes colocar los módulos de puerta de enlace cerca de tus aplicaciones o fuentes de datos para reducir aún más el tiempo de ida y vuelta. TrueFoundry también admite operaciones locales seguras: los únicos datos que se envían al servidor de licencias en la nube son las métricas de uso anonimizadas, y la implementación completa en el plano de control puede permanecer detrás del firewall si es necesario.
Cómo elegir la puerta de enlace adecuada para su caso de uso
Ninguna puerta de enlace de IA es perfecta para todos los escenarios, así que alinea tu elección con tus prioridades:
Casos de uso sensibles a los costos: Si es fundamental un control estricto del presupuesto, priorice las pasarelas con políticas de gasto incorporadas. Asegúrese de que puede aplicar precios personalizados (por ejemplo, que reflejen los descuentos de su empresa) y activar alertas dentro de los límites presupuestarios. TrueFoundry, por ejemplo, te permite precargar las tarifas de los proveedores públicos y definir tarifas personalizadas para tus contratos o modelos autohospedados, con notificaciones automatizadas a medida que se aproximan los umbrales.
Requisitos de alta seguridad y cumplimiento: En los sectores regulados, busque funciones como la auditabilidad total (registros a prueba de manipulaciones), el RBAC granular y la administración de claves de cifrado. La puerta de enlace de TrueFoundry admite los flujos de trabajo de SOC2 e HIPAA de forma inmediata (mediante opciones locales y almacenamiento seguro de claves) y puede integrarse con las herramientas de SIEM. Funciones como la detección de información personal identificable y la redacción de datos pueden ser decisivas si se manejan datos confidenciales.
Rendimiento extremadamente alto/baja latencia: Para las aplicaciones en tiempo real (por ejemplo, los chatbots de clientes o los sistemas de negociación), el rendimiento de la pasarela es fundamental. Consulta los puntos de referencia del proveedor o ejecuta una prueba piloto: la arquitectura de TrueFoundry puede ofrecer más de 250 RPS por pod con una latencia añadida mínima, y puede ampliarse fácilmente a muchos miles con más réplicas. Si necesitas una latencia ultrabaja, es importante implementar los módulos de puerta de enlace en la misma región (o incluso en las zonas periféricas) que tus usuarios, ya que la opción SaaS o local multirregional de TrueFoundry lo permite.
Entornos híbridos o multinube: Si usa varios proveedores de nube o tiene requisitos estrictos de residencia de datos, elija una puerta de enlace que pueda conectarse con ellos. TrueFoundry admite la implementación en cualquier infraestructura local o en la nube, y puede sincronizar las políticas a nivel mundial. Esto significa que un plano de control puede administrar las pasarelas implementadas en diferentes regiones o nubes.
Aplicaciones multimodales o agenciales: Si su caso de uso involucra agentes (herramientas, acciones) a través de los protocolos MCP/A2A, o si necesita un soporte perfecto para imágenes y audio, verifique que la puerta de enlace tenga esas capacidades. TrueFoundry está ampliando activamente su pasarela para virtualizar los servidores MCP y unificar las herramientas de IA en una sola API. En la actualidad, ya ofrece «servidores MCP virtuales» en los que se pueden combinar herramientas y modelos de varios agentes en una sola interfaz (próximamente en GA). En el caso de los modelos multimodales, TrueFoundry admite de manera uniforme los modelos de texto, imagen, audio e incrustación.
Adaptación del desarrollador y del ecosistema: Considera lo que usan tus equipos de desarrollo. Si confían en los marcos LangChain o LLM, elige una pasarela conocida que funcione con ellos de forma inmediata. La facilidad de incorporación (documentos de API, SDK de clientes) es importante para la adopción. TrueFoundry proporciona API abiertas y bibliotecas cliente en varios idiomas, y su API unificada significa que el código existente basado en OpenAI a menudo funciona sin cambios. Compruebe también si la puerta de enlace se integra con las herramientas de CI/CD o de infraestructura que utilice (por ejemplo, la compatibilidad con Terraform en TrueFoundry).
En todos los casos, compare estos requisitos con su lista de verificación de evaluación. Asigne ponderaciones a los criterios en función de lo que es más importante para su proyecto (seguridad frente a costo frente a características). El marco de evaluación de TrueFoundry se puede personalizar (está disponible como un CSV público) para que puedas puntuar a los proveedores en función de las funciones exactas que necesitas. El objetivo es elegir la pasarela que no solo satisfaga las necesidades actuales, sino que también pueda crecer con sus iniciativas de inteligencia artificial.
Conclusión
A medida que crece la adopción de la IA, una puerta de enlace diseñada específicamente se está convirtiendo rápidamente en una capa de control imprescindible. Pone orden en lo que, de otro modo, sería una combinación caótica de API, costos y riesgos de seguridad. Al gestionar el enrutamiento, la observabilidad, la presupuestación y el cumplimiento en un solo lugar, una puerta de enlace de inteligencia artificial convierte la infraestructura de inteligencia artificial en una plataforma confiable y gobernada. La puerta de enlace de IA de TrueFoundry se basa en estos principios y ofrece una interfaz unificada para cientos de modelos con controles de seguridad, supervisión y políticas de nivel empresarial.
Al elegir una puerta de enlace, utilice un enfoque estructurado: comprenda sus cargas de trabajo, consulte la lista de verificación de evaluación y compare cómo se compara cada opción con respecto a la flexibilidad, el rendimiento, la observabilidad, los controles de costos y las funciones de gobierno del enrutamiento. De este modo, puede seleccionar la solución que servirá como «plano de control de IA» para las aplicaciones de LLM y basadas en agentes de su organización. Una puerta de enlace sólida no solo protege los presupuestos y los datos, sino que también acelera el desarrollo al proporcionar una base coherente y escalable para todos los servicios de IA. En última instancia, invertir en la puerta de enlace de IA adecuada allana el camino para llevar los casos de uso de la IA de forma segura desde la fase experimental a la realidad a escala empresarial.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga

































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


