

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: May 29, 2026
.webp)
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Las operaciones financieras (FinOps) se han convertido en una disciplina esencial en la era de la nube, ya que reúne a los equipos de ingeniería, finanzas y negocios para maximizar el valor del gasto en tecnología. A medida que las empresas adoptan IA y modelos lingüísticos de gran tamaño (LLM) a gran escala, los principios de FinOps ahora también son cruciales para las cargas de trabajo de la IA.
¿Por qué? Porque la IA presenta nuevos desafíos de costos que la administración tradicional de costos en la nube no fue diseñada para manejar. En un mundo impulsado por la IA, controlar el gasto es tan importante como la precisión de los modelos o el tiempo de actividad. Estos son algunos de los desafíos de costos únicos que presentan las iniciativas modernas de inteligencia artificial:
FinOps: es la disciplina de la gestión financiera en la nube y sus principios fundamentales son visibilidad, responsabilidad, y mejoramiento. FinOps para la IA significa aplicar esos mismos principios a estos desafíos específicos de la IA. En las secciones siguientes, analizaremos cómo se aplica cada principio de FinOps a la IA y, lo que es más importante, cómo la plataforma de TrueFoundry ayuda a implementarlos de una manera práctica y fácil de usar desde el punto de vista de la ingeniería.
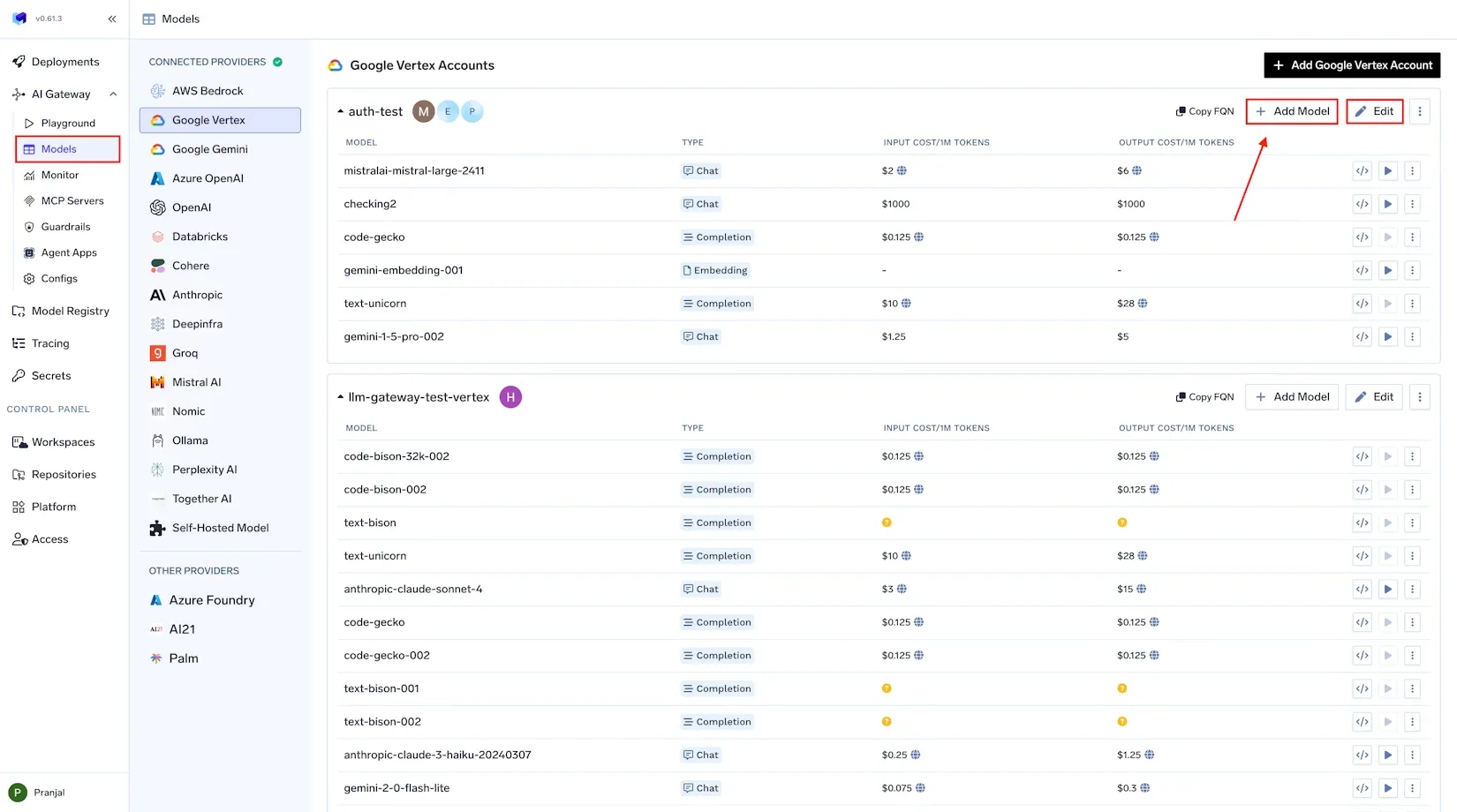
El primer pilar de FinOps es visibilidad — «No se puede mejorar lo que no se mide». En el contexto de la IA, la visibilidad significa capturar datos exhaustivos sobre cada invocación del modelo, para que sepas exactamente a dónde van tus presupuestos de fichas y GPU. Es más fácil decirlo que hacerlo cuando el uso se distribuye entre varios proveedores e infraestructuras. TrueFoundry aborda este problema a través de una solución centralizada Puerta de enlace de IA por el que se canalizan todas las solicitudes de IA.
Puerta de enlace de IA unificada: True Foundry Puerta de enlace de IA actúa como un único punto de entrada (proxy) para todas las llamadas a modelos de IA, ya sea que accedas a una API externa como OpenAI o Anthropic, o a un modelo autohospedado que se ejecute en tu infraestructura. Al enrutar todas las solicitudes de inferencia a través de una puerta de enlace, se establece un «panel de vidrio único» para la observabilidad y seguimiento de costos. La pasarela es consciente de los matices específicos del modelo, como el recuento de tokens y la latencia, y registra cada solicitud de forma estructurada. Esto elimina los puntos ciegos derivados de la fragmentación de las herramientas: independientemente del modelo o proveedor que se utilice, el seguimiento del uso se realiza de forma centralizada.
Metadatos y registro granulares: Cada solicitud que pasa por AI Gateway de TrueFoundry se registra automáticamente con metadatos enriquecidos para su atribución. Esto incluye el nombre del modelo, la marca de tiempo, el recuento de tokens de entrada/salida, la latencia, el usuario o la clave de API que realiza la solicitud, etc. Los equipos también pueden adjuntar etiquetas o metadatos personalizados a cada solicitud, como customer_id, application, environment o feature_name.
Por ejemplo, puedes etiquetar las solicitudes con la función del producto o el equipo interno responsable. TrueFoundry facilita esta tarea al permitir a los desarrolladores incluir un encabezado X-TFY-METADATA en las llamadas a la API. Por ejemplo, con el SDK de Python:
client = OpenAI(api_key="...", base_url="https://llm-gateway.truefoundry.com/api/inference/openai")
response = client.chat.completions.create(
model="openai-main/gpt-4",
messages=[{"role": "user", "content": "Hello"}],
extra_headers={
"X-TFY-METADATA": '{"application":"booking-bot","environment":"staging","customer_id":"123456"}',
"X-TFY-LOGGING-CONFIG": '{"enabled": true}'
}
)
En este fragmento, la solicitud se etiqueta con un nombre de aplicación, un entorno y un identificador de cliente como metadatos. Todos los valores son cadenas (128 caracteres como máximo) y puede incluir tantos campos como sea necesario. Estas etiquetas viajan con la solicitud a través de la pasarela y se registran en registros y métricas.
Recolección de métricas en tiempo real: El AI Gateway no solo registra datos sin procesar, sino que también emite métricas estructuradas para la supervisión. Para cada solicitud, TrueFoundry rastrea métricas como la cantidad de tokens de entrada, los tokens de salida y el costo estimado de esa solicitud. Estas métricas se etiquetan con dimensiones como el nombre del modelo, el nombre de usuario (o servicio) y cualquier etiqueta de metadatos personalizada que hayas habilitado como etiquetas.
Por ejemplo, llm_gateway_request_total_cost es una contramétrica que acumula el costo de los tokens utilizados, etiquetados por modelo, usuario y metadatos personalizados, como customer_id. Esto significa que puedes desglosar el costo de forma instantánea según las categorías que sean importantes para tu empresa (equipo, cliente, función, etc.) en tus herramientas de monitoreo.
Integración con paneles de monitoreo: La observabilidad de TrueFoundry está diseñada para conectarse a su sistema de monitoreo existente. La pasarela muestra un punto final de /metrics con métricas compatibles con Prometheus y también puede enviar métricas a través de OpenTelemetry. Con algunos ajustes de configuración, puedes hacer que la pasarela publique las métricas en tu backend de Prometheus o Datadog en tiempo real. Una vez ingeridas, estas métricas se pueden visualizar en los paneles de Grafana o en cualquier plataforma de análisis que utilice su organización.
De hecho, TrueFoundry proporciona métricas prediseñadas del panel JSON de Grafana para AI Gateway, que cubren las vistas por modelo, usuario y regla de configuración.
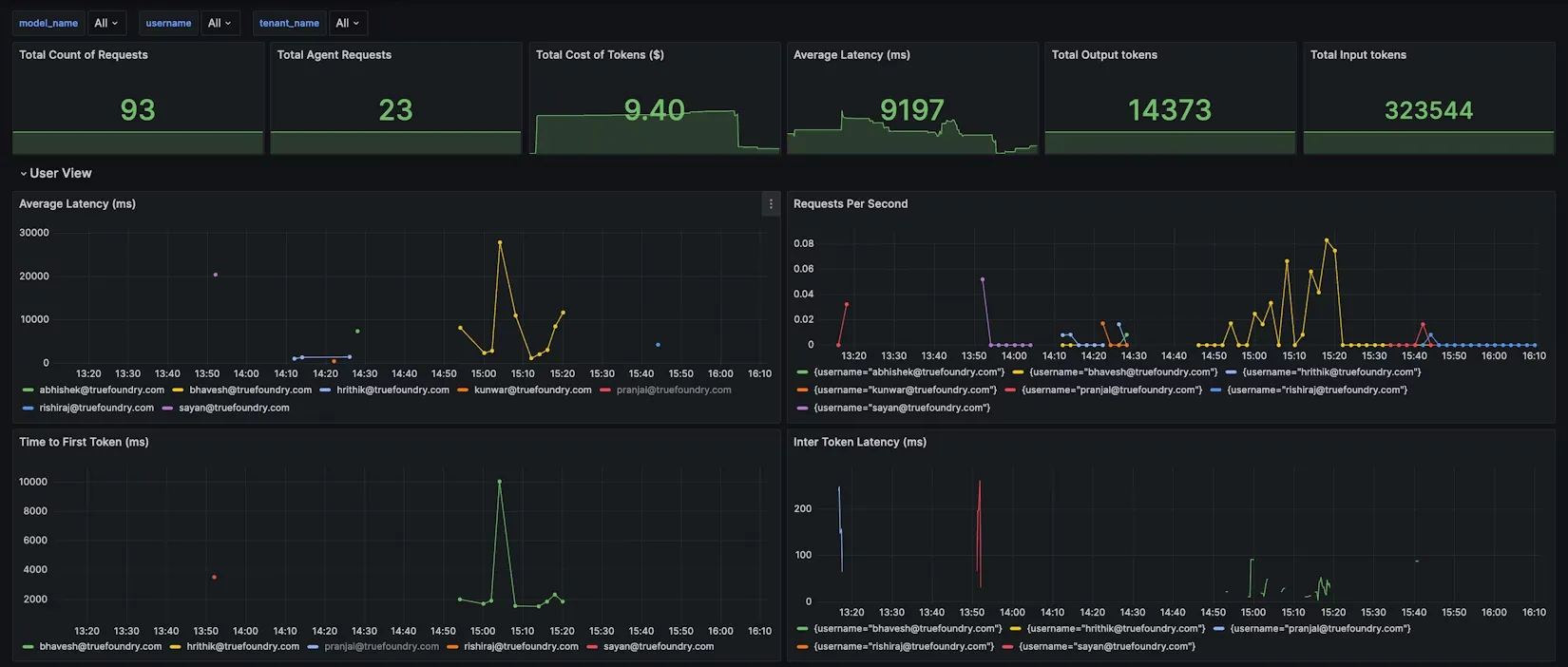
Por ejemplo, el Vista del modelo podría mostrar el uso de los tokens y la latencia por modelo, mientras que Vista de usuario desglosa el uso por nombre de usuario para identificar a los usuarios habituales. Incluso puedes añadir filtros de panel personalizados para tus etiquetas de metadatos (por ejemplo, filtrar todos los gráficos por ID de cliente o proyecto) para obtener informes de costes a pedido de un cliente o proyecto determinado.
Al centralizar todos estos datos, usted logra visibilidad completa hacia el consumo de IA. Resulta trivial responder a preguntas como: ¿Qué equipo generó la mayor cantidad de fichas GPT-4 esta semana? ¿Cuánto costó nuestra nueva función de chatbot en las llamadas a la API? ¿Qué clientes o usuarios están impulsando el mayor uso? Con TrueFoundry, puedes simplemente cambiar un filtro o ejecutar una consulta para obtener estas respuestas. Este nivel de transparencia es la base de FinOps en el campo de la IA: arroja luz sobre cada ficha y hora de GPU, lo que convierte la incertidumbre en información práctica.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

La visibilidad prepara el escenario, pero FinOps también requiere responsabilidad y proactivo gobernanza del gasto. En las FinOps en la nube, se alienta a los equipos a que sean dueños de su uso y se ajusten a los presupuestos. En las FinOps de IA, dada la imprevisibilidad del uso, es fundamental hacer cumplir algunas barandas para que los costos no se reduzcan debido a un error o un experimento que se ha vuelto loco. La plataforma de TrueFoundry se construye gobierno de costos directamente en la capa de infraestructura de IA, por lo que puede controlar el uso en tiempo real en lugar de simplemente informar sobre él después del hecho.
Atribución y devoluciones de cargo por solicitud: Como TrueFoundry etiqueta y rastrea cada solicitud con metadatos del equipo y del proyecto, puedes atribuir los costos a un nivel detallado en tiempo real. Esto permite utilizar modelos internos de devolución o devolución, por ejemplo, mostrar a cada equipo de producto cuánto gastan sus funciones en inteligencia artificial o cobrar a un cliente externo por su uso específico.
Las métricas de costos de TrueFoundry se pueden filtrar según estos atributos para producir desgloses instantáneos (costo por usuario, por función, por cliente, etc.). Compartir estos informes genera responsabilidad: los equipos pueden ver el impacto de su código y sus indicaciones en la factura, y las finanzas pueden garantizar que los gastos se asignen a las unidades de negocio o a los clientes.
Control de acceso y permisos basados en roles: Parte de la gobernanza consiste en garantizar únicamente el uso autorizado de recursos costosos. La pasarela de nivel empresarial de TrueFoundry admite el control de acceso basado en roles (RBAC) y la administración de claves de API. Esto significa que puede restringir quién puede llamar a ciertos modelos de alto coste o limitar el acceso a las funciones experimentales.
Por ejemplo, puede permitir que un entorno de control de calidad o de ensayo utilice un modelo más pequeño, pero solo la producción puede llamar a la costosa API GPT-4. O puedes limitar la clave de API de un desarrollador junior a un modelo de espacio aislado. Al restringir el acceso, evitas el uso accidental de modelos costosos por parte de personas equivocadas. En combinación con registros de auditoría y metadatos detallados, también se crea un registro de auditoría para comprobar el cumplimiento (es decir, se sabe exactamente qué usuario o servicio hizo cada solicitud).
Políticas de limitación de tarifas: Una de las barandillas FinOps más poderosas es límite de velocidad. El AI Gateway de TrueFoundry te permite configurar reglas flexibles de límite de velocidad para limitar el uso en varias dimensiones: por usuario, equipo, modelo o incluso etiquetas personalizadas.
Por ejemplo, puedes decir «El usuario X solo puede hacer 1000 solicitudes de GPT-4 por día» o «Todas las solicitudes del proyecto ABC están limitadas a 50 000 fichas por hora». La configuración se define en un formato YAML simple. Este es un fragmento de ejemplo que ilustra algunas reglas:
name: ratelimiting-config
type: gateway-rate-limiting-config
rules:
# 1. Limit a specific user to 1000 requests/day on the GPT-4 model
- id: "limit-gpt4-user1-daily"
when:
subjects: ["user:[email protected]"]
models: ["openai-main/gpt4"]
limit_to: 1000
unit: requests_per_day
# 2. Limit each project (by metadata tag) to 50k tokens per hour
- id: "project-{metadata.project_id}-hourly"
when: {}
limit_to: 50000
unit: tokens_per_hourEn la regla #1 anterior, un usuario específico (identificado por su clave de API o nombre de usuario) tiene un límite de 1000 solicitudes GPT-4 por día. En la regla #2, imponemos un límite de 50 000 tokens/hora por proyecto, siempre que cada solicitud incluya un project_id en sus metadatos. La sintaxis {metadata.project_id} significa que la puerta de enlace aplicará un bucket diferente para cada ID de proyecto único que encuentre. En la práctica, esa regla evita que un solo proyecto consuma accidentalmente más de 50 000 tokens en una hora (por ejemplo, si una integración se cancela o un cliente tiene un pico inesperado). La pasarela evalúa las solicitudes entrantes en función de estas reglas en orden y, si una solicitud supera un límite, estrangulado o rechazado en el acto.
Alertas y cuotas presupuestarias: Además de los límites de tasas brutas, TrueFoundry permite establecer umbrales presupuestarios. Puedes definir límites de gastos mensuales o diarios para un equipo o una aplicación. Por ejemplo, podrías presupuestar 1000$ al mes para que un equipo de desarrollo experimente con los LLM. El Gateway puede hacer un seguimiento del coste acumulado de las solicitudes y, una vez que se supera el umbral, puede enviar alertas o inhabilitar el uso posterior hasta que intervenga un administrador. Básicamente, esto es ejecución automática del presupuesto. En lugar de descubrir al final del mes que el equipo A gastó de más, te quedas con (digamos) el 80% del presupuesto y puedes tomar medidas.
La puerta de enlace de TrueFoundry puede incluso aceleración automática o pausa solicita cuando se agota un presupuesto, lo que evita un gasto excesivo y notifica a las partes interesadas. Los equipos financieros aprecian este tipo de red de seguridad, ya que convierte la gestión de los costes en un proceso activo y continuo, en lugar de en un análisis posterior a los hechos.
Validación y barandillas rápidas: Otro aspecto de la gobernanza es hacer cumplir las mejores prácticas en cuanto a las indicaciones y los patrones de uso para evitar la explosión de costos. La plataforma de TrueFoundry incluye funciones de protección para, por ejemplo, bloquear ciertas indicaciones inseguras o ineficientes. Puedes configurar reglas para rechazar las solicitudes que superen la longitud máxima de un token o que contengan contenido no permitido.
Del mismo modo, TrueFoundry admite esquemas de salida estructurados y plantillas rápidas que ayudan a mantener las respuestas concisas y predecibles, controlando indirectamente el uso de los tokens.
El principio final de FinOps es mejoramiento — mejorar continuamente la rentabilidad sin sacrificar el rendimiento ni los resultados. Tras lograr la visibilidad y establecer la gobernanza, las organizaciones pueden centrarse en obtener más valor de cada dólar gastado en IA. TrueFoundry ofrece múltiples vías para optimizar las cargas de trabajo de la IA, desde el enrutamiento inteligente de solicitudes a nivel de modelo hasta la utilización eficiente de la infraestructura de GPU.
Selección inteligente de modelos (modelos con el tamaño correcto): No todas las tareas necesitan el modelo más caro. Una característica distintiva de la optimización de costos de la IA es el uso del más barato, suficiente modelo para cada trabajo. AI Gateway de TrueFoundry es compatible enrutamiento de modelo híbrido estrategias para que pueda dirigir automáticamente las solicitudes a diferentes modelos en función de las políticas de costo o complejidad.
Por ejemplo, puedes dirigir las consultas simples o las solicitudes de baja prioridad a un modelo más pequeño y económico (como un modelo 7B de código abierto o un nivel GPT-3.5 de OpenAI) y enviar solo consultas complejas o de alto riesgo a un modelo premium como el GPT-4. Muchos equipos descubren que un gran porcentaje de su tráfico puede gestionarse con modelos más económicos, por lo que se reservan el modelo más caro para los pocos casos en los que realmente se necesita una capacidad superior. TrueFoundry hace que esto sea posible al permitir el enrutamiento basado en reglas (o incluso el enrutamiento dinámico basado en ML) en la configuración de la puerta de enlace. El resultado es evitar pagar de más por modelos «exagerados»: usted nunca pague de más por una capacidad que no necesita cuando la puerta de enlace puede cambiar automáticamente a un modelo más económico para los escenarios correctos.
Procesamiento por lotes y almacenamiento en caché: Cuando pagas por solicitud o por token, vale la pena eliminar el trabajo redundante. La plataforma de TrueFoundry proporciona funciones para procesamiento por lotes y almacenamiento en caché de respuestas para mejorar la eficiencia. Con el API de inferencia por lotes, puede combinar varias solicitudes o entradas en una sola solicitud para amortizar los gastos generales.
Optimización y truncamiento rápidos: Otra vía de optimización es reducir el tamaño de los anuncios. Gracias a la observabilidad, es posible que descubras que ciertas solicitudes son innecesariamente largas (por ejemplo, si incluyen un contexto irrelevante). Técnicas como la compresión de mensajes, el uso de un historial más corto o la generación aumentada por recuperación (en la que se obtienen conocimientos externos de forma relevante en lugar de incluir un documento completo en el mensaje) pueden reducir el número de fichas.
TrueFoundry admite los flujos de trabajo de RAG e incluso las herramientas de administración de prontas (como el control rápido de versiones y las pruebas) para ayudar a los equipos a avanzar hacia solicitudes más eficientes. Por ejemplo, en lugar de que una conversación con un usuario envíe todo el historial de chat por turno, puedes resumir o eliminar el contexto antiguo cuando ya no sea relevante, cambiando un poco de precisión por un gran ahorro de costes. De TrueFoundry Prompt Playground y los análisis pueden ayudar a analizar cómo la longitud rápida se correlaciona con el costo, destacando dónde se puede reducir la grasa.
Optimización del uso de la GPU: Para los equipos que ejecutan modelos autohospedados o que realizan trabajos de capacitación, la optimización de la infraestructura de GPU es crucial para FinOps. La plataforma ML de TrueFoundry está diseñada para maximizar la utilización de la GPU y eliminar el desperdicio. Las capacidades clave incluyen:
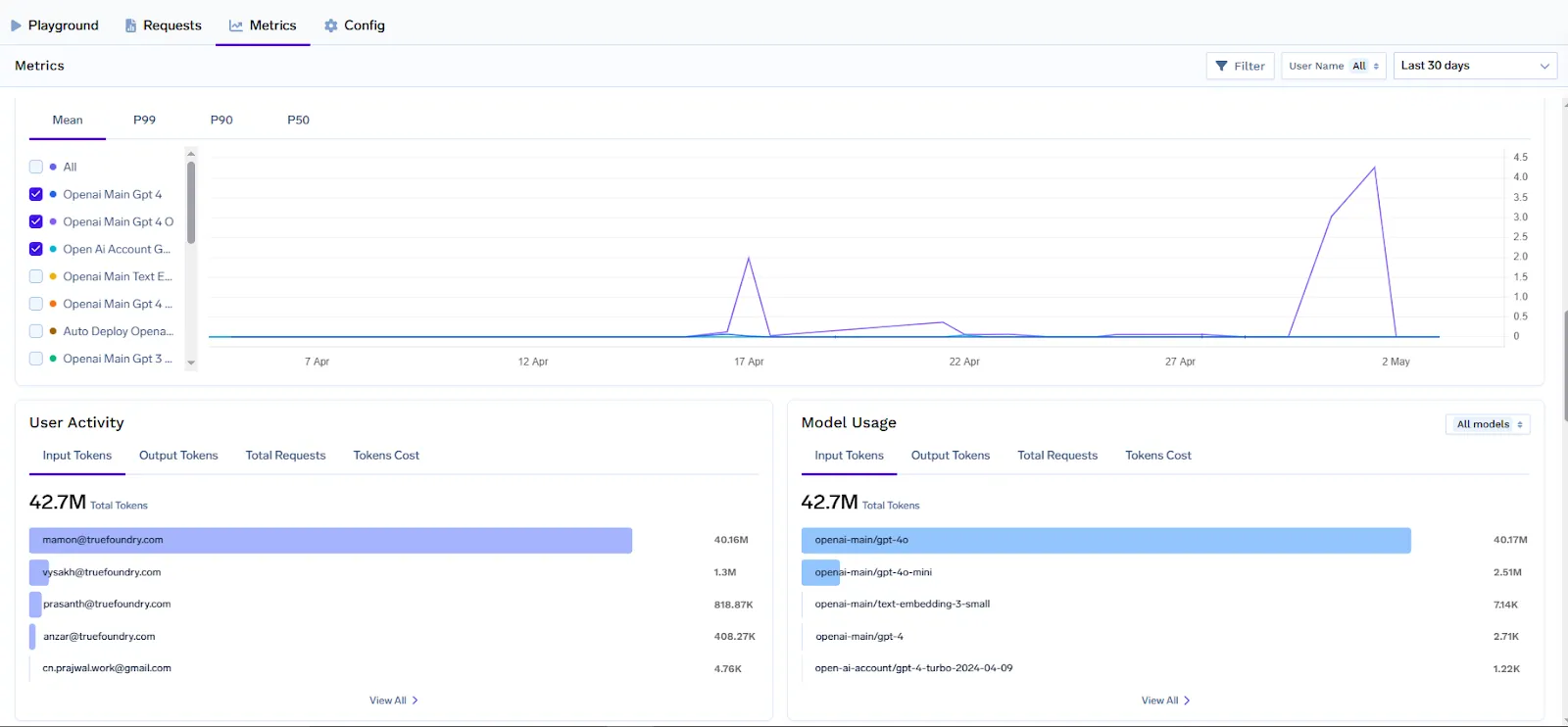
Una iniciativa práctica de FinOps se beneficia de informes y paneles claros que reúnen las métricas y los conocimientos empresariales. TrueFoundry simplifica la creación de Tableros de FinOps para IA proporcionando todos los datos y puntos de integración necesarios listos para usar para las herramientas más populares.
Con las métricas exportadas por AI Gateway, los equipos pueden crear paneles en Grafana, Datadog o cualquier herramienta de BI para visualizar las tendencias de uso y gasto de la IA. Por ejemplo, dado que cada solicitud está etiquetada con el nombre «equipo» y «modelo», puedes crear un panel de Grafana que muestre «Costo por equipo (últimos 7 días)» consultando la métrica llm_gateway_request_total_cost agrupada por tenant_name (team). Otro panel podría mostrar «Fichas por solicitud por modelo» para identificar qué modelos consumen muchos tokens y es posible que sea necesario optimizarlos. De TrueFoundry panel Grafana prediseñado ya incluye vistas para analizar el uso por modelo, usuario y reglas de configuración (por ejemplo, para ver si algún límite de velocidad se alcanza con frecuencia). Puedes ampliarlos con metadatos personalizados; por ejemplo, añadir un filtro para customer_id como variable, de modo que las partes interesadas puedan seleccionar un cliente específico y ver el uso y el coste de sus tokens a lo largo del tiempo.
La integración con otras herramientas de monitoreo y APM es posible a través de OpenTelemetry. Si su organización usa Datadog, puede reenviar las métricas de la pasarela a las métricas de Datadog (ya que Datadog puede incorporar las métricas de OpenTelemetry o Prometheus). Esto significa que tus métricas de costos de IA pueden coincidir con las métricas de costos de tu infraestructura. Resulta fácil correlacionar, por ejemplo, un aumento en el uso de tokens con una implementación o el lanzamiento de una función en particular, porque se puede acceder a todos los datos en un solo lugar.
TrueFoundry también ofrece un API de análisis para los datos de uso, por lo que si prefieres transferir los datos a un panel financiero personalizado o a una hoja de cálculo, puedes hacerlo. Muchas empresas exportan datos sin procesar (TrueFoundry incluso permite la descarga en formato CSV de los datos de costos) para combinarlos con los registros de facturación, lo que permite obtener una imagen completa del costo por proyecto si se añaden gastos generales, como el almacenamiento o las redes.
La clave es que, con las bases que establece TrueFoundry (etiquetado de metadatos, métricas en tiempo real), crear estos conocimientos de FinOps no requiere crear una canalización de datos desde cero. Obtiene datos precisos y ricos en atribuciones en tiempo real, lo que supone un gran paso adelante con respecto a la espera de la factura de la nube de fin de mes. Los líderes de ingeniería, aprendizaje automático y finanzas pueden revisar juntos los paneles que responden a las preguntas técnicas y empresariales sobre el uso de la IA. Esta visibilidad interfuncional promueve una cultura de conciencia de los costos
La implementación de FinOps para la IA es un proceso continuo. Todo comienza con conciencia y se convierte en una disciplina integrada en el ciclo de vida del desarrollo de la IA. Al establecer prácticas de visibilidad, responsabilidad y optimización, las organizaciones avanzan hacia la madurez de las FinOps, desde los informes de costos reactivos hasta el control de costos en tiempo real y, finalmente, la optimización predictiva. Y lo que es más importante, crear un Cultura de FinOps en torno a la IA garantiza la sostenibilidad. La adopción de la IA se estancará si los costos aumentan sin control o de manera impredecible. Al analizar la IA desde el punto de vista de las FinOps, las organizaciones consideran que el acceso a los modelos y el tiempo dedicado a la GPU son recursos valiosos que deben gestionarse, no como algo mágico ilimitado. Las herramientas posibilitan este cambio cultural: cuando los equipos tienen acceso de autoservicio a las métricas y a los informes de costes, pueden asumir la responsabilidad. True Foundry La solución acelera esta adopción cultural al hacer uso de la IA transparente y regido por el diseño — la visibilidad de los costos y los controles se incorporan a la plataforma, no como una idea de último momento.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


