Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.
9,9
Consideraciones sobre los costos del uso de una puerta de enlace de inteligencia artificial: optimización del gasto empresarial en inteligencia artificial
Gestionar el coste del uso de modelos lingüísticos extensos (LLM) se ha convertido en una preocupación fundamental para las empresas que implementan la IA a gran escala. A diferencia del software tradicional, los servicios basados en LLM suelen utilizar precios basados en fichas — los proveedores cobran por token de entrada/salida, lo que hace que la presupuestación sea difícil de predecir o controlar. Hay varios factores que contribuyen a esta complejidad:
Precios de diferentes modelos: Cada proveedor de LLM (OpenAI, Anthropic, Cohere, etc.) o tamaño de modelo tiene su propia tarifa por token, y los modelos más grandes (por ejemplo, la clase GPT-4) cuestan significativamente más por token que los más pequeños.
Patrones de uso impredecibles: El consumo de tokens puede variar enormemente según el usuario, la función o el flujo de trabajo: una función puede usar silenciosamente 10 veces más tokens que otra, y el uso puede aumentar inesperadamente con el comportamiento del usuario.
Canalizaciones de mensajes dinámicos: Los casos de uso avanzados, como la generación aumentada por recuperación (RAG), los agentes que utilizan herramientas o las cadenas de varios pasos, pueden ampliar inadvertidamente el tamaño de los mensajes y la longitud de la respuesta, multiplicando los tokens (y el costo) necesarios por consulta.
El resultado es que, sin la visibilidad y los controles adecuados, los equipos a menudo no se dan cuenta de la rapidez con la que se acumulan los costos hasta que llega la factura. No es raro que los gastos: globo inesperadamente, lo que pone en peligro los presupuestos de los proyectos e impide los esfuerzos de ampliación. Un informe reciente de Gartner también advierte que la falta de visibilidad y gobernanza de los costos puede provocar rápidamente sobrecostos presupuestarios en iniciativas de IA. En resumen, a medida que las organizaciones incorporan las LLM en los productos, controlar los costos de uso es tan importante como la precisión del modelo o el tiempo de actividad. Los precios basados en tokens introducen una incertidumbre que puede reducir el ROI a menos que se administre de forma activa.
Aquí es donde aparece el concepto de Puerta de enlace de IA entra. Un portal de IA se está convirtiendo en un componente clave para recuperar el control sobre el uso y el gasto de la LLM. Antes de profundizar en los factores que impulsan los costos y las soluciones, definamos qué es una puerta de enlace de inteligencia artificial y cómo influye en los costos.
¿Qué es una puerta de enlace de IA? (Y cómo afecta al costo)
Un Puerta de enlace de IA es una capa de middleware especializada que administra todas las interacciones entre sus aplicaciones y varios modelos o proveedores de IA. Considérela como una puerta de enlace de API creada específicamente para las cargas de trabajo de IA, una puerta de enlace que comprende los matices específicos del modelo, como la facturación basada en tokens, la latencia de inferencias y el enrutamiento dinámico. Proporciona un punto final unificado para todas las solicitudes de inteligencia artificial y dirige el tráfico de forma inteligente al backend del modelo correcto en función de las políticas de costo, rendimiento o disponibilidad.
Si bien la adición de una puerta de enlace implica gastos generales menores, como los costos de alojamiento y el esfuerzo de configuración, estos se ven compensados por el control y la visibilidad que proporciona. Al dirigir cada solicitud a una sola capa, las organizaciones pueden supervisar el uso, hacer cumplir los presupuestos y tomar decisiones en tiempo real sobre qué modelo ofrece la mejor relación costo-rendimiento. Gartner describe las pasarelas de IA como «controladores de tráfico inteligentes» que ayudan a las empresas a evaluar y optimizar el uso de los modelos en todas las aplicaciones.
La puerta de enlace de IA de TrueFoundry funciona como este plano de control que unifica el acceso entre modelos y proveedores al tiempo que aplica políticas empresariales como el control de acceso, la gobernanza de costes, el almacenamiento en caché y la observabilidad. Hace que el consumo de inteligencia artificial pase de ser un gasto impredecible a convertirse en un sistema gestionado, medible y optimizable.
Impulsores de costos clave en el uso de LLM
Cuando se utilizan modelos lingüísticos de gran tamaño en la producción, varios factores clave determinan el costo total de la operación. Comprender estos factores es el primer paso para gestionar y reducir los costos relacionados con la LLM:
Selección de modelo y tamaño: La elección del modelo tiene un impacto enorme en el costo. Los modelos más grandes y avanzados (con un mayor número de parámetros o más capacidades) suelen tener costos por token mucho más altos. Por ejemplo, el GPT-4 u otros modelos de «razonamiento» pueden costar un orden de magnitud más por token que los modelos más pequeños. El uso de un modelo de primer nivel para cada solicitud, incluidas las consultas triviales, aumentará los costos innecesariamente.
Uso del token (longitud del aviso y de la respuesta): La cantidad de tokens enviados en las solicitudes más los tokens generados en las respuestas impulsan directamente la facturación. Las conversaciones o los documentos prolongados, las ventanas de contexto demasiado largas o las solicitudes no optimizadas que incluyen información irrelevante acumulan puntos. Algunas funciones, como pedir al modelo que sea detallado o devolver explicaciones extensas, pueden aumentar su uso de manera exponencial. Efectivo ingeniería rápida mantener las indicaciones concisas y centrarse en los productos puede reducir significativamente los costos. Cada ficha es importante cuando pagas fracciones de céntimo por ficha millones de veces.
Volumen y patrones de tráfico: La frecuencia y el alcance del uso de las funciones de IA obviamente afectarán al costo, pero no se trata solo del volumen total, sino del patrón. El tráfico irregular e impredecible puede generar costos durante los picos de uso, lo que desborda el presupuesto mensual. La variabilidad entre los usuarios o las funciones significa que unos pocos usuarios avanzados o una herramienta interna podrían consumir secretamente la mayoría de los tokens. Los aumentos repentinos de uso (por ejemplo, el hecho de que una nueva función se vuelva viral) pueden generar facturas imprevistas si no se limitan. Aumentar el uso sin aumentar la supervisión de los costos es una receta para los sobrecostos.
Uso multimodelo y selección de proveedores: Muchos equipos utilizan una combinación de modelos, por ejemplo, un modelo de código abierto para algunas tareas y una API propia para otras, o diferentes proveedores para diferentes idiomas. Cada modelo/proveedor puede tener diferentes unidades de precios (algunos cobran por cada 1000 fichas, otros por solicitud, etc.) y, posiblemente, tarifas adicionales. Además, si un equipo siempre opta por defecto por el modelo más caro «por motivos de seguridad», pierde oportunidades de ahorrar. Seleccionando el modelo adecuado para cada tarea es una palanca de costos importante: una consulta simple no necesita un modelo caro de 175 B parámetros cuando bastaría con un modelo más pequeño (y más barato). Por el contrario, algunas tareas complejas podrían justificar el costo de un modelo superior. La estrategia (o la falta de ella) para enrutar el tráfico hacia los modelos es un factor importante de costos.
Infraestructura y gastos generales: También hay costos más allá de las tarifas por token. Si autohospedas las LLM de código abierto para evitar los costos de las API, pagas en infraestructura: servidores de GPU, memoria, mantenimiento y esfuerzo de MLOps. Como se expresó sucintamente en un análisis: «Los LLM de código abierto no son gratuitos, solo trasladan la factura de las licencias a la ingeniería, la infraestructura, el mantenimiento y el riesgo estratégico». Incluso si utiliza las API en la nube, es posible que necesite una infraestructura adicional para gestionar las solicitudes (por ejemplo, ejecutar un servicio o una puerta de enlace internos, bases de datos vectoriales para RAG, etc.), lo que implica costes de computación en la nube. Los gastos generales de integración y el tiempo de ingeniería son costes «ocultos» que pueden aumentar de forma gradual.
Tarifas de licencia o suscripción: Algunos modelos y servicios conllevan tarifas fijas además del uso. Por ejemplo, algunas API de IA empresariales requieren una suscripción o un compromiso mensual. Incluso los modelos de código abierto pueden tener restricciones de licencia que obliguen a las empresas a optar por opciones de pago. Si adoptas una plataforma de distribución de modelos propia, es posible que se produzcan costes de licencia. Estas tarifas deben tenerse en cuenta en el costo total de propiedad para usar un modelo determinado; a veces, un modelo «más barato por token» puede requerir una licencia costosa, lo que anula los ahorros.
Costos de integración e ineficiencia: Por último, la forma en que integras la IA en tus sistemas puede generar ineficiencias en los costos. Las llamadas redundantes, la falta de almacenamiento en caché o la mala administración de la carga pueden desperdiciar tokens. Las primeras empresas que la adoptaron descubrieron que el uso de una puerta de enlace de API estándar o una integración ad hoc conducía a sobrecostos significativos (en algunos casos, un 300% más que las proyecciones iniciales), porque la herramienta no tuvo en cuenta las optimizaciones específicas de la IA, como el almacenamiento en caché de solicitudes similares o el equilibrio de carga entre los modelos. Crear y mantener su propia infraestructura para el acceso y la supervisión de varios modelos conlleva un coste. Si cada equipo llama a las API de inteligencia artificial de forma independiente, se pierden las economías de escala y la supervisión centralizada, lo que a menudo se traduce en un gasto agregado mayor de lo necesario (por ejemplo, varios equipos utilizan el mismo modelo con la misma solicitud y pagan dos veces).
La comprensión de estos factores de coste pone de manifiesto por qué no basta con dar a los equipos acceso a una API de LLM: el uso no gestionado de muchas aplicaciones y usuarios provocará sorpresas casi inevitablemente. Cuanto más crucial y generalizado sea el uso de la IA, mayor será la necesidad de gobernanza.Aquí es donde las pasarelas de IA demuestran su valor: se dirigen directamente a estos generadores de costos, proporcionando mecanismos para controlar los costos sin sacrificar el rendimiento o la confiabilidad.
Administración y reducción de los costos de LLM con una puerta de enlace de inteligencia artificial
Un portal de IA ofrece un conjunto de herramientas y estrategias inteligentes para abordar los factores de costos mencionados anteriormente. Sirve como central capa de gobierno de costos para todos los usos de la IA. Según Gartner, las pasarelas de IA pueden mitigar el riesgo de «el aumento vertiginoso de los costos de la IA debido a una mala gobernanza» actuando como punto de control entre los consumidores y los proveedores de IA. AI Gateway de TrueFoundry, por ejemplo, incorpora numerosas funciones para monitorear y optimizar los costos. Analicemos en detalle cómo una puerta de enlace de inteligencia artificial ayuda a gestionar y reducir los costos de la LLM:
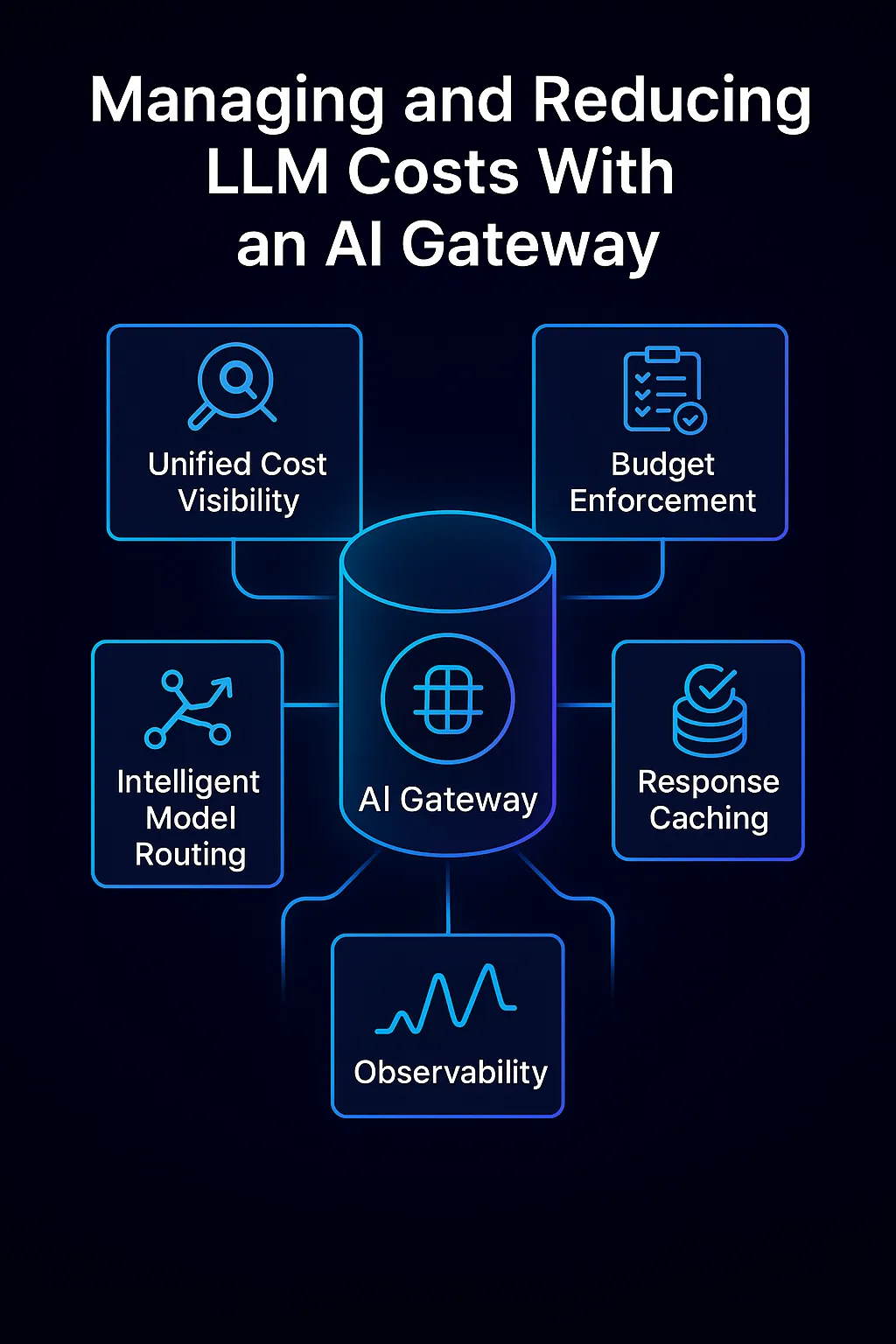
Visibilidad unificada de los costos: Todas las solicitudes se envían a través de la puerta de enlace, que registra métricas de uso detalladas para cada llamada: modelo utilizado, tokens consumidos, latencia, atribución de usuario/equipo, etc. Esto proporciona una visibilidad granular y en tiempo real de hacia dónde van a parar tus dólares simbólicos. Los líderes pueden responder por fin a la pregunta: «¿qué aplicaciones o casos de uso están generando la mayor parte de nuestra factura de OpenAI?» con precisión. Esta visibilidad entre aplicaciones es casi imposible de conseguir cuando los equipos llaman directamente a los modelos. Con una puerta de enlace, obtienes una única fuente de verdad panel de control para el uso y el gasto de la IA. Esta transparencia permite realizar una contabilidad de contracargos o devoluciones (asignar los costes a los departamentos), lo que a su vez impulsa la rendición de cuentas.
Aplicación del presupuesto y barandillas: La visibilidad por sí sola no es suficiente: la puerta de enlace también hace cumplir políticas para evitar un uso descontrolado. Puede definir límites de tasas y cuotas (por ejemplo, no más de N fichas o un gasto de X $ por día para un usuario o función determinados) y la pasarela rechazará o limitará las solicitudes más allá de esa fecha. Esto garantiza que un script que se comporte mal o un aumento de uso inesperado no supere el presupuesto. También puedes configurar alertas de presupuesto o cierre automático reglas: si el uso mensual de un equipo supera un límite, la pasarela puede enviar notificaciones o interrumpir temporalmente las llamadas hasta que se aprueben, lo que evita facturas inesperadas. Además, las pasarelas permiten control de acceso y restricciones de modelo — por ejemplo, es posible que solo permitas el uso de modelos caros como el GPT-4 en ciertos flujos de trabajo críticos, mientras que los usos menos críticos se restringen a los modelos más baratos. Otra forma de protección es el filtrado rápido, que bloquea las solicitudes que generarían resultados extremadamente largos o solicitudes que, de otro modo, serían poco rentables. Al aplicar estas reglas de gobierno de manera centralizada, las organizaciones crean límites estrictos a la exposición a los costos.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Modelo de enrutamiento inteligente: Quizás el mayor ahorro de costos sea la capacidad de la puerta de enlace para dirija dinámicamente cada solicitud al modelo o proveedor óptimo según el contexto. En lugar de ofrecer una solución única para todos los casos, la pasarela puede evaluar factores como la complejidad de la consulta, la precisión requerida, la latencia y el costo, y luego elegir (o incluso cambiar automáticamente) el modelo que mejor se adapta a las necesidades al menor costo. Por ejemplo, una pregunta fáctica simple podría responderse con un modelo más pequeño y económico sin ninguna diferencia de calidad perceptible, mientras que una tarea compleja se envía a un modelo más potente. Este tipo de selección de modelos en tiempo real reduce los costos al evitar la exageración. AI Gateway de TrueFoundry implementa esto mediante reglas de enrutamiento inteligente y equilibrio de carga: puede configurarlo de manera que, de forma predeterminada, las consultas vayan a un modelo de código abierto como Mistral para mayor velocidad y bajo coste, pero si la solicitud parece compleja o si la confianza del modelo más pequeño es baja, la puerta de enlace dirija esa solicitud a un modelo más grande, como GPT-4. En el caso de cientos de miles de solicitudes, este enrutamiento adaptativo puede generar enormes ahorros y, al mismo tiempo, mantener la calidad general. Supera la falsa dicotomía entre elegir un modelo de alto rendimiento o uno de bajo costo: usted puede tener ambos utilizando cada una de ellas donde tengan sentido.
Almacenamiento en caché de respuestas: Otra optimización de costos es almacenamiento en caché respuestas de IA repetidas o comunes. Si varios usuarios hacen la misma pregunta o tu sistema realiza consultas idénticas de forma repetida, una pasarela de IA puede devolver una respuesta almacenada en caché en lugar de volver a llamar al modelo, guardando esos tokens por completo. Incluso almacenar en caché los resultados parciales (como los costosos pasos intermedios) puede ayudar. Esto es especialmente útil para aplicaciones o tareas de back-end en las que se usa el mismo mensaje con frecuencia. El almacenamiento en caché no solo reduce los costos, sino que también mejora la latencia de esas consultas. True Foundry gateway admite tanto el almacenamiento en caché sencillo como el más avanzado almacenamiento en caché semántico — donde las solicitudes semánticamente similares se pueden tratar como visitas a la caché. (El almacenamiento en caché semántico debe usarse con cuidado, ya que las diferencias sutiles en las solicitudes podrían cambiar la respuesta, pero en los escenarios correctos puede aumentar las tasas de aciertos de la caché y reducir los costos). Los estudios han demostrado que los mecanismos de almacenamiento en caché semántico podrían reducir los costos de las API de LLM hasta 70% en casos de uso empresarial. En la práctica, incluso una caché más simple para solicitudes idénticas supone un ahorro de costes considerable para las aplicaciones de gran volumen
Observabilidad y detección de anomalías: Como la puerta de enlace monitorea todas las solicitudes, también puede detectar patrones de uso anómalos eso podría indicar un error o un abuso. Por ejemplo, si esta hora muestra 5 veces el uso del token en comparación con la última, o si de repente una aplicación comienza a enviar spam al modelo con mensajes grandes, la puerta de enlace (y sus paneles integrados) detectarán esa anomalía. La detección temprana significa que puede intervenir antes de que se agote el presupuesto. La observabilidad también contribuye a la confiabilidad: rastrea las tasas de error y las latencias, lo que ayuda a diferenciar las ralentizaciones relacionadas con los costos de los problemas del modelo. Algunas pasarelas, como la de TrueFoundry, se integran con herramientas como OpenTelemetry para que puedas combinar las métricas de uso de la LLM con tu conjunto de monitorización general. Esta observabilidad holística garantiza el mantenimiento de los costos y objetivos de rendimiento. También permite la devolución de cargos internos: dado que el uso se registra de forma centralizada, puedes hacer que los equipos rindan cuentas por la parte que les corresponde de la factura de la IA, lo que los incentiva a ser eficientes.
Cómo una puerta de enlace de IA administra y reduce los costos de LLM, combinando la visibilidad unificada, la aplicación del presupuesto, el enrutamiento inteligente de modelos, el almacenamiento en caché y la observabilidad en una sola capa de control.
Todas estas capacidades se combinan para hacer cumplir la disciplina de costos sin una supervisión manual constante. Al usar una puerta de enlace de inteligencia artificial, la administración de costos se vuelve proactiva y automatizada: tienes un costo limita en su lugar para que no pueda gastar de más, tiene información en tiempo real para ajustar los patrones de uso, y tienes optimizaciones automatizadas (enrutamiento, almacenamiento en caché) eliminando las ineficiencias sobre la marcha. Convierte lo que podría ser un centro de costos opaco y desbocado en una empresa de servicios públicos gobernada.
AI Gateway de TrueFoundry ejemplifica estos controles de costos en la práctica. Proporciona funciones integradas paneles de seguimiento de costos, configuración de políticas presupuestarias, enrutamiento multimodelo reglas y mecanismos de almacenamiento en caché, todo configurable a través de una interfaz apta para empresas. El resultado es que las empresas pueden adoptar más casos de uso de la IA sin el miedo a las facturas impredecibles. Por supuesto, el uso de una puerta de enlace de este tipo introduce algunas consideraciones sobre el rendimiento y la arquitectura, que analizaremos a continuación.
Equilibrar el costo, la precisión, la latencia y la complejidad
Cualquier estrategia para controlar los costos de manera agresiva debe equilibrarse con otros requisitos técnicos y comerciales. Compensaciones son inevitables. En el contexto de las implementaciones de LLM, las dimensiones clave que hay que equilibrar son el costo, la precisión (o la calidad de los resultados), la latencia (velocidad de respuesta) y la complejidad arquitectónica. Una pasarela de inteligencia artificial ayuda a gestionar estas ventajas y desventajas, pero es importante comprenderlas para establecer las políticas correctas:
Coste frente a precisión: Los modelos de mayor calidad generalmente significan costos más altos, pero no todas las tareas exigen un razonamiento de nivel GPT-4. Un modelo 7B más pequeño puede responder a la pregunta «¿Cuál es la capital de Francia?» con la misma precisión que un modelo emblemático, pero sin plantear una cuestión jurídica compleja. La clave es utilizar el inteligencia de enrutamiento de gateway para decidir cuándo vale la pena pagar por una precisión superior. Dirija las tareas cotidianas a modelos más pequeños y reserve los modelos de gama alta para razonamientos complejos. Con el tiempo, los análisis ayudan a refinar estos umbrales para lograr un equilibrio entre una precisión aceptable y un ahorro sustancial de costos.
Costo frente a latencia: Los modelos más baratos también suelen ofrecer respuestas más rápidas, especialmente cuando se alojan localmente. Sin embargo, el enrutamiento multimodelo ingenuo puede introducir latencia si el sistema prueba un modelo y luego recurre a otro. Gateway de TrueFoundry mitiga esto con enrutamiento basado en latencia y con reconocimiento de carga, garantizando que las solicitudes fluyan hacia el modelo más rápido y viable sin saltos innecesarios. Su arquitectura solo supone unos pocos milisegundos de sobrecarga (entre 3 y 4 ms por solicitud), lo que es insignificante en comparación con los tiempos de inferencia de los modelos, por lo que los equipos ganan en eficiencia sin comprometer la experiencia del usuario.
Costo frente a complejidad arquitectónica: La adición de una puerta de enlace de IA introduce una capa adicional de infraestructura, pero también ofrece una visibilidad, barandillas y confiabilidad de las que carecen las configuraciones de un solo modelo. Para equipos pequeños o prototipos, las llamadas directas al modelo pueden ser suficientes. Sin embargo, a medida que el uso aumenta, el enrutamiento centralizado, el almacenamiento en caché y la gestión de costes se vuelven esenciales.
En última instancia, equilibrar estos factores es un ejercicio continuo. La mejor práctica consiste en supervisar continuamente el impacto de las medidas de ahorro de costes en la calidad de los resultados del modelo y en la experiencia del usuario (lo que contribuye a la observabilidad de la puerta de enlace) y ajustar los botones (reglas de enrutamiento, configuración de la memoria caché, etc.) en consecuencia. La ventaja del enfoque de la pasarela de IA es que tú tener estas perillas para girar: no estás limitado al uso de un modelo único para todos. Puedes aumentar o reducir los gastos en determinadas áreas y, al mismo tiempo, conservar lo que más importa para tu aplicación, ya sea el tiempo de respuesta o la precisión de la respuesta.
Mejores prácticas para la optimización de costos de LLM mediante una puerta de enlace
Para obtener el máximo beneficio de una pasarela de IA, las organizaciones deben combinar la tecnología con estrategias de uso sólidas. Estas son algunas de las mejores prácticas para optimizar los costos de la LLM y, al mismo tiempo, mantener el rendimiento:
1. Optimice las indicaciones y las salidas. Recorta las fichas innecesarias y mantén las indicaciones enfocadas. Las instrucciones demasiado largas o detalladas desperdician fichas. Los formatos estructurados, como las viñetas o los esquemas JSON, hacen que las respuestas sean concisas y predecibles. Revisa y acorta las indicaciones contextuales comunes que aparecen antes de cada llamada. Esta optimización de «coste cero» reduce directamente el gasto.
2. Utilice un modelo de enrutamiento híbrido. Adopte una estrategia de modelo por niveles: dirija las consultas simples o de bajo riesgo a modelos más pequeños y económicos, y las complejas a los modelos premium. Muchos equipos siguen un patrón de 90/10: el 90% del tráfico se dirige a modelos rápidos y de bajo costo; el 10% a modelos de alta calidad para tareas críticas. El Gateway de TrueFoundry automatiza este proceso mediante un enrutamiento basado en reglas o en ML, lo que garantiza que nunca tendrás que pagar de más por una capacidad que no necesitas.
3. Agrupa y paraleliza llamadas. Al pagar por token o por llamada, minimice los gastos generales agrupando varias solicitudes en una sola solicitud. La API de inferencia por lotes de TrueFoundry te permite agrupar tareas relacionadas, lo que resulta ideal para trabajos periódicos, como resumir grandes conjuntos de documentos. En algunos casos, las solicitudes paralelas se pueden enviar tanto a modelos baratos como a modelos caros, cancelando la más costosa si el primero arroja un resultado satisfactorio.
4. Almacene en caché las consultas de alta frecuencia. Reutilice los resultados en lugar de volver a calcularlos. El Gateway admite el almacenamiento en caché semántico y de coincidencia exacta, donde las solicitudes similares pueden reutilizar las respuestas anteriores. Incluso las tasas de acierto de caché moderadas pueden ahorrar una cantidad considerable de fichas y, al mismo tiempo, mejorar la latencia, lo que supone una gran ventaja para los flujos de trabajo repetidos o las consultas comunes.
5. Afina o especializa los modelos. Para tareas repetitivas y específicas de un dominio, ajustar un modelo más pequeño o integrar RAG (generación aumentada por recuperación) puede acortar las solicitudes y reducir los tokens. La plataforma de TrueFoundry admite el ajuste y la implementación personalizada, lo que ayuda a los equipos a equilibrar la precisión y la eficiencia a escala.
6. Aproveche los modelos de código abierto o autohospedados. Con grandes volúmenes, puede resultar más económico alojar modelos de peso libre en GPU dedicadas en lugar de pagar por llamada a la API. El Gateway permite una implementación híbrida perfecta, ya que dirige parte del tráfico a modelos autohospedados y, al mismo tiempo, mantiene los controles unificados de registro y políticas. Esta configuración híbrida puede generar ahorros de costos sustanciales y, al mismo tiempo, preservar la flexibilidad.
Además de estas prácticas, siempre
monitorear e iterar
. Usa los datos de la pasarela para ver qué estrategias están teniendo el mayor impacto (por ejemplo, las tasas de aciertos de la caché, los tokens guardados al enrutar, etc.) y ajústalas en consecuencia. La optimización de costes no es algo que se tenga que configurar y olvidar una sola vez, sino que la pasarela le brinda las herramientas necesarias para que sea un esfuerzo continuo y manejable, en lugar de convertirse en una sorpresa de extinción de incendios.
El enfoque de TrueFoundry para el seguimiento y la gobernanza de los costos
Si bien la optimización de costos es un desafío universal en todas las implementaciones de LLM, La puerta de enlace de IA de TrueFoundry lo convierte en un proceso estructurado, mensurable y continuo. En lugar de basarse en la elaboración de presupuestos manuales o en informes de costes dispersos, TrueFoundry incorpora la gobernanza directamente a la capa de infraestructura, lo que garantiza que cada interacción de la IA se registre, se fije el precio y se atribuya en tiempo real. Esta infraestructura unificada permite estructurar Solución de seguimiento de costos LLM, lo que permite a las empresas supervisar el gasto a nivel de modelo, equipo y flujo de trabajo con total transparencia.
Interfaz de configuración de costos modelo de TrueFoundry
1. Atribución de costos en tiempo real
Cada solicitud que pasa por el Gateway de TrueFoundry es automática etiquetado y con precio. El sistema combina el recuento de tokens de entrada/salida con datos de precios específicos del modelo, ya sea a partir de API públicas o de tarifas negociadas por la empresa, para calcular el costo exacto por inferencia. Los equipos pueden filtrar estas métricas por modelo, equipo, entorno o usuario, lo que brinda una visibilidad precisa de quién o qué impulsa el gasto. Esto facilita la asignación de costes, la ejecución de contracargos internos o la justificación del ROI de las funciones de IA.
2. Modelos de precios y presupuestos configurables
TrueFoundry permite a las empresas definir precios personalizados por modelo, alineando el seguimiento interno con los contratos reales de los proveedores o los costos de computación autohospedados. Los administradores también pueden crear umbrales o cuotas presupuestarias para cada aplicación o entorno. Cuando el gasto supera un límite definido, el Gateway puede activar alertas automatizadas o incluso aplicar restricciones temporales para garantizar la contención de los costos sin intervención manual.
3. Observabilidad integrada
TrueFoundry exporta los datos de costos y uso a Prometheus y OpenTelemetry, que se integra sin problemas con las tuberías de monitoreo existentes. Esto permite que las métricas de costos, latencia y confiabilidad de la IA aparezcan en los mismos paneles que se usan para monitorear la infraestructura y las aplicaciones. El resultado es un panel de vidrio único donde los equipos de ingeniería, finanzas y productos comparten una visión unificada del rendimiento y los gastos.
4. Gobernanza desde el diseño
Porque cada llamada incluye etiquetado de metadatos (equipo, proyecto y entorno), las organizaciones pueden implementar una rendición de cuentas estructurada en todos los departamentos. Combinado con control de acceso basado en funciones (RBAC) y permisos a nivel de modelo, esto garantiza que los modelos de alto costo o alto riesgo solo sean accesibles para los equipos aprobados. Estas barreras garantizan el cumplimiento, la disciplina presupuestaria y la transparencia automático, no manual.
Cuando una puerta de enlace de IA puede no estar justificada
Las pasarelas de IA ofrecen un inmenso valor a escala, pero no todas las organizaciones necesitan una de inmediato. Para equipos pequeños o proyectos en fase inicial que utilizan un modelo único y volúmenes de solicitudes bajos, la implementación de una puerta de enlace completa puede resultar una sobrecarga innecesaria. Un prototipo que utilice un modelo de OpenAI con unos pocos miles de tokens al día se puede gestionar fácilmente mediante llamadas directas a la API y una supervisión básica.
Las directrices del sector sugieren que cuando el uso es limitado (decenas de miles de tokens al mes) y las necesidades de cumplimiento o confiabilidad son mínimas, puede bastar con un proxy ligero o un seguimiento manual. La verdadera ventaja de la pasarela surge a medida que las cargas de trabajo escalan o se diversifican según los modelos y los proveedores. Si su organización aún está experimentando con los LLM o tiene una infraestructura mínima, concéntrese primero en la iteración, pero planifique con antelación. El Gateway de TrueFoundry, por ejemplo, se puede reducir de manera eficiente, lo que ofrece una visibilidad y un gobierno tempranos sin necesidad de una configuración compleja. En resumen, evalúe su Madurez y escala de la IA: para los casos de uso de bajo volumen y modelo único, la creación de una pasarela puede resultar prematura; a medida que aumenta la adopción, rápidamente se convierte en algo esencial para el control de los costos, la confiabilidad y la gobernanza a largo plazo.
Conclusión
Controlar los costos de LLM en entornos empresariales es complejo, pero las pasarelas de IA están diseñadas para resolver exactamente eso. En lugar de dejar los costos al azar, una puerta de entrada como True Foundry incorpora la gestión de costes directamente en su arquitectura de IA. Mediante el seguimiento centralizado, las barreras de presupuestación, el enrutamiento inteligente y el almacenamiento en caché, convierte el control de costos en una capacidad integrada y no en una idea de último momento.
Informe sobre empresas que utilizan pasarelas de IA Reducción del 40 al 60% en los costos de inferencia, junto con una mayor confiabilidad y seguridad. Gateway de TrueFoundry, en particular, ofrece responsabilidad por diseño — brindando a los equipos una visibilidad detallada, atribución de costos y devoluciones de cargos, y reducción de riesgos a escala mediante límites automatizados y sistemas de seguridad. También proporciona transparencia total en los patrones de uso para que ningún problema de costo o latencia pase desapercibido.
Al unificar las políticas en todas las regiones y equipos, Gateway garantiza una gobernanza y un cumplimiento coherentes, algo fundamental para las industrias que manejan datos confidenciales. El resultado: los proyectos de IA pasan de la experimentación a la producción con un gasto predecible y una confianza operativa.
En resumen, las pasarelas de IA hacen que la adopción de la LLM sea sostenible. Los precios basados en tokens pueden ser impredecibles, pero con el plano de control centralizado de TrueFoundry, las empresas pueden optimizar el gasto, aplicar barreras y escalar de manera responsable. Así es como coexisten la innovación y la disciplina fiscal, lo que convierte a la IA en una capacidad gobernada, eficiente y preparada para la empresa.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga






























.png)

.webp)
.webp)
.webp)



.webp)
.webp)


