




October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 23, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
OpenAI y Langchain han hecho que sea muy fácil crear una demostración para responder preguntas sobre sus documentos. Hay un montón de artículos en Internet explicando cómo hacerlo. También tenemos un cuaderno que funciona en caso de que quieras jugar con un sistema de principio a fin:
En este artículo, hablaremos sobre cómo producir un bot de preguntas y respuestas en tus documentos. También lo implementaremos en su entorno de nube y también permitiremos el uso de LLM de código abierto en lugar de OpenAI si la privacidad y la seguridad de los datos son uno de los requisitos principales.
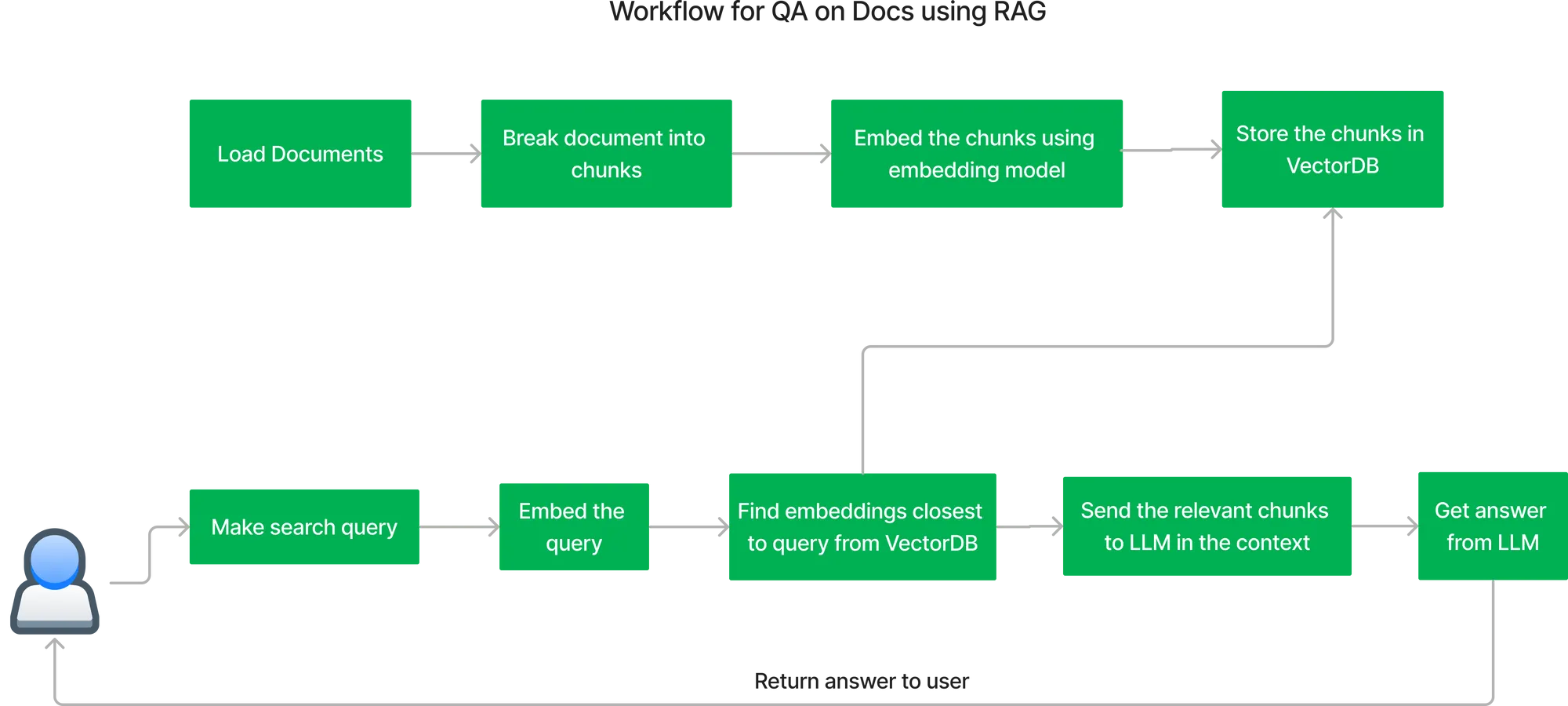
El flujo de trabajo clave para crear el sistema de control de calidad mediante RAG (Generación aumentada por recuperación) es el siguiente:
Flujo de documentos de indexación:
Obtener la respuesta a la consulta del usuario:
Para implementar todo el flujo descrito anteriormente, tenemos que implementar una serie de componentes juntos. Este es el diagrama de arquitectura para implementar RAG en su propia nube.
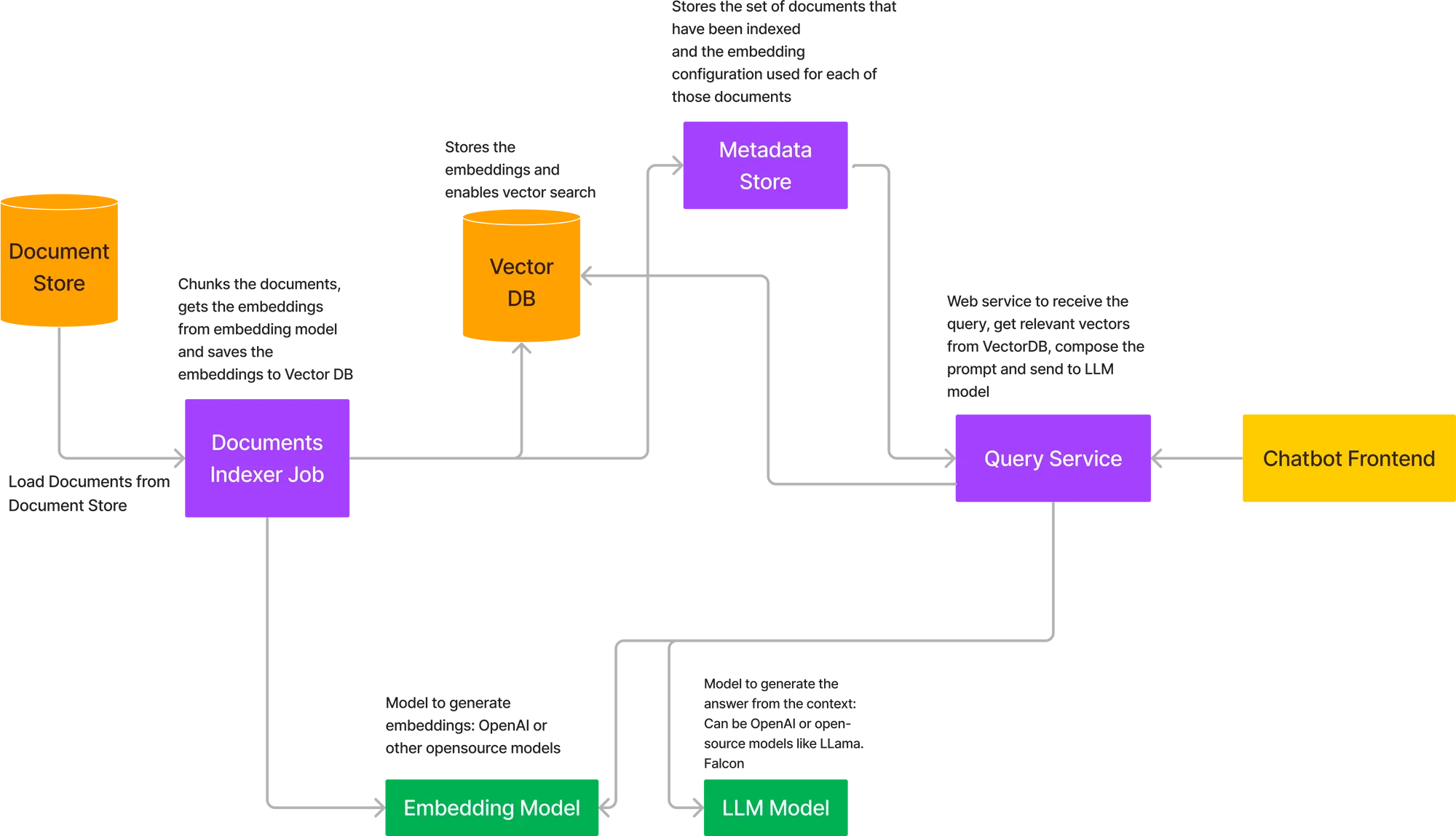
Los componentes clave de la arquitectura anterior son:
Aquí es donde se almacenarán los documentos. En muchos casos, será AWS S3, Google Storage Buckets o Azure Blob Storage. En algunos casos, estos datos también pueden provenir de las API si se trata de algo como los documentos de Confluence.
Esto se modelará de manera similar a un trabajo de entrenamiento en ML, que obtiene los documentos como entrada, los divide en fragmentos, llama al modelo de incrustación para incrustar los fragmentos y almacena los vectores en la base de datos. El modelo de incrustación se puede cargar en el propio trabajo o se puede llamar como API. Se prefiere la ruta de la API, ya que entonces el modelo de incrustación se puede ampliar de forma independiente en caso de que haya una gran cantidad de documentos. Los trabajos se pueden activar de forma puntual o de forma programada si hay un flujo entrante de documentos. Una vez que se complete el trabajo, el trabajo también debería almacenar el estado como Exitoso en un almacén de metadatos, junto con la configuración de incrustación.
Si utilizamos OpenAI o un modelo hospedado externamente, no necesitamos hospedar un modelo en este caso. Sin embargo, si utilizamos un modelo de código abierto, tendremos que alojarlo en nuestro entorno de nube y luego obtener las incrustaciones mediante la API.
Si utilizamos OpenAI o API de modelos alojados como Cohere y Anthropic, entonces no necesitamos implementar nada; de lo contrario, tenemos que implementar LLM de código abierto.
Puede tratarse de un servicio FastAPI que proporciona la API para enumerar todas las colecciones de documentos indexadas y permite al usuario realizar consultas sobre las colecciones de documentos. También habrá una API para activar un nuevo trabajo de indexación para una nueva colección de documentos.
Aquí podemos usar una solución alojada como PineCone o alojar uno de los VectorDB de código abierto como Qdrant o Milvus.
Esto es necesario para almacenar los enlaces a los documentos que se han indexado y cuál fue la configuración utilizada para incrustar los fragmentos en esos documentos. Esto ayuda al usuario a seleccionar el conjunto de documentos que desea consultar y puede admitir varios conjuntos de documentos en una organización.
Verdadera fundición es una plataforma en Kubernetes que facilita la implementación de trabajos y servicios de capacitación en aprendizaje automático al costo más óptimo. Con Truefoundry, podemos implementar todos los componentes de la arquitectura anterior en su propia cuenta en la nube. La implementación final en su nube tendrá un aspecto similar al siguiente:
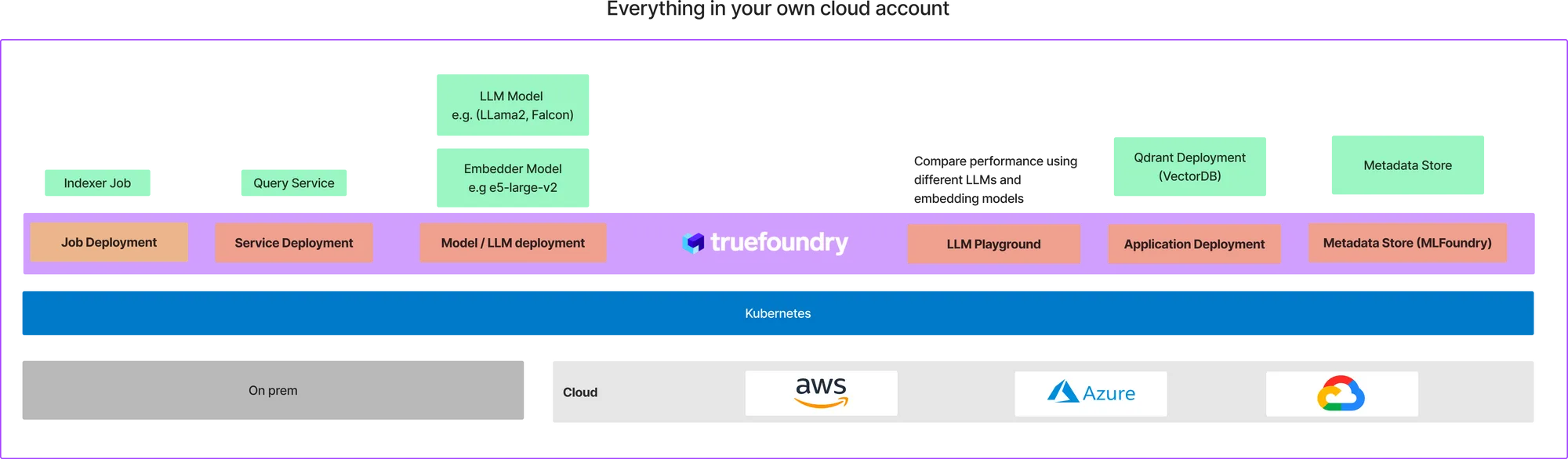
Esto puede parecer una gran cantidad de configuración, ya hemos creado una plantilla para que puedas empezar con esto en menos de 10 minutos. Suponemos que ya está incorporado a TrueFoundry. Si aún no se ha incorporado, siga esto guía para embarcarse. TrueFoundry funciona en los tres principales proveedores de nube: AWS, Azure y GCP, por lo que deberías poder configurarlo en cualquiera de estos proveedores de nube.
Hemos creado un bot de control de calidad de muestra para ti con el código para el trabajo de indexación, el servicio de consultas y una interfaz de chat usando streamlit en este repositorio de Github:
Puede implementarlo en TrueFoundry en su propia nube en 15 minutos. Esto permitirá una configuración a nivel de producción y también le brindará total flexibilidad para modificar el código según sus propios casos de uso.
Implementaremos toda la arquitectura en un clúster de Kubernetes. Puedes encontrar el código completo y las instrucciones de implementación en este repositorio de github.
TrueFoundry proporciona una abstracción fácil de usar sobre Kubernetes para implementar diferentes tipos de aplicaciones en Kubernetes. Repasaremos los diferentes pasos para implementar RAG en su nube.
Truefoundry incluye un almacén de metadatos en forma de repositorios de ML. Puede almacenar artefactos, metadatos y biblioteca de tuberías mlfoundry proporciona métodos para cargar y descargar los artefactos. Cada repositorio de ML está respaldado por el almacenamiento de blobs en la nube (AWS S3, GCS o Azure Blob Storage). En primer lugar, crearemos un repositorio de aprendizaje automático y, a continuación, subiremos nuestros documentos para indexarlos como artefactos. Para crear un repositorio de ML, sigue la guía que se encuentra aquí: https://docs.truefoundry.com/docs/creating-ml-repo-via-ui
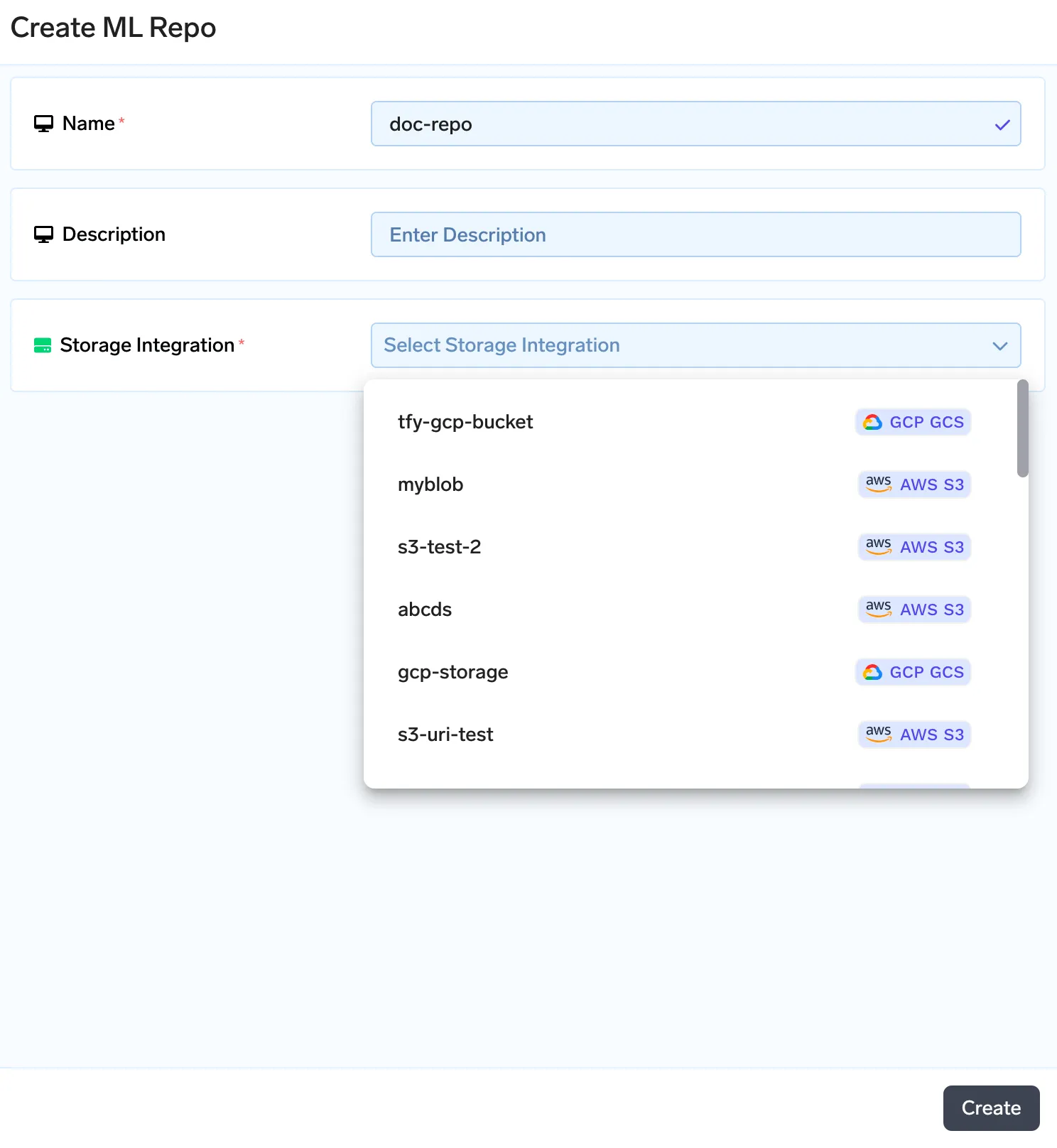
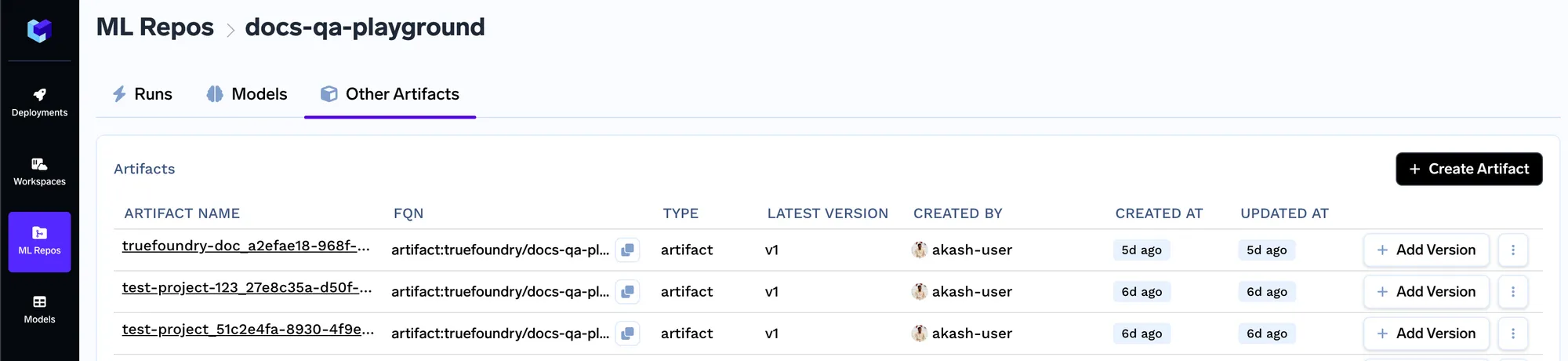
Una vez que creemos un artefacto, crearemos una nueva versión del artefacto. De esta forma, cada vez que cambie el conjunto de documentos, podrás subir el nuevo conjunto de documentos como una nueva versión. Puedes subir tus documentos en la siguiente pantalla.
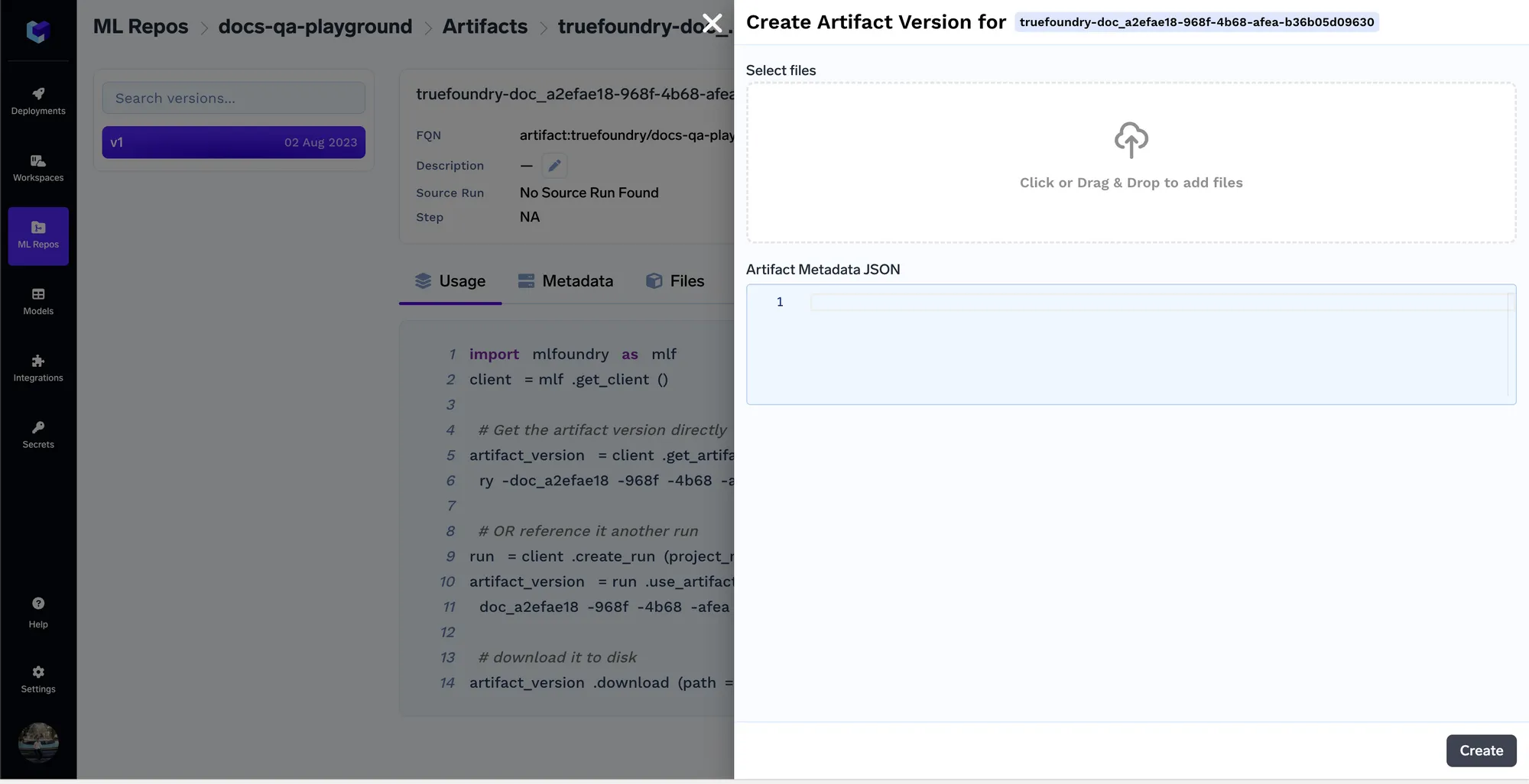
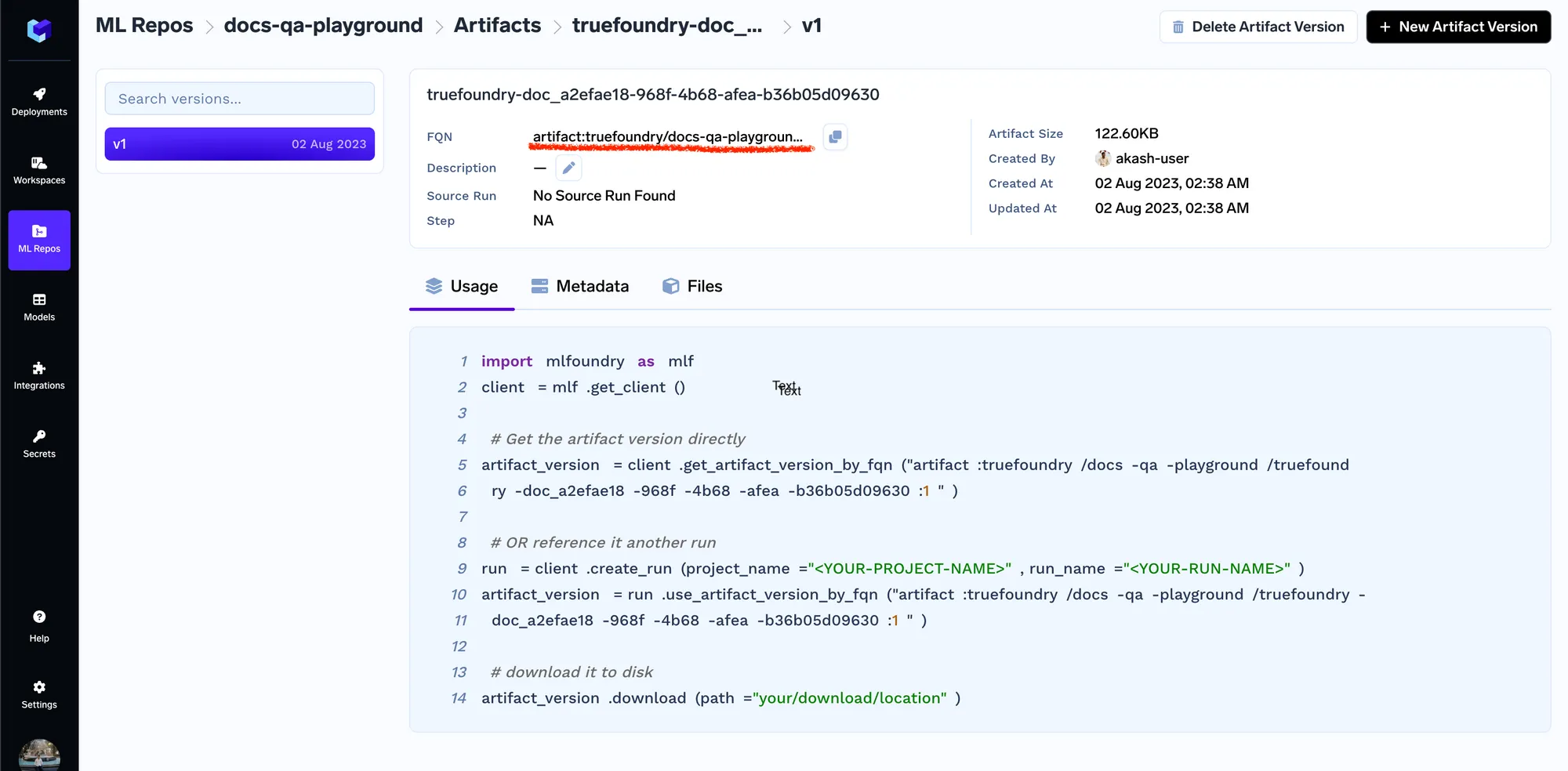
Una vez cargados los documentos, obtendremos la versión fqn del artefacto, con la que podremos consultar/descargar el artefacto en código en cualquier lugar.
Necesitaremos el modelo de incrustación para incrustar los fragmentos; puede omitir este paso si está utilizando OpenAI Embeddings. Puedes implementar cualquiera de los modelos de incrustación del catálogo de modelos; en general, hemos descubierto que el e5-large v2 funciona bastante bien.
Una vez que se implementa el modelo de incrustación, puede comprobar las API utilizando el área de juegos de OpenAPI en el panel de Truefoundry.
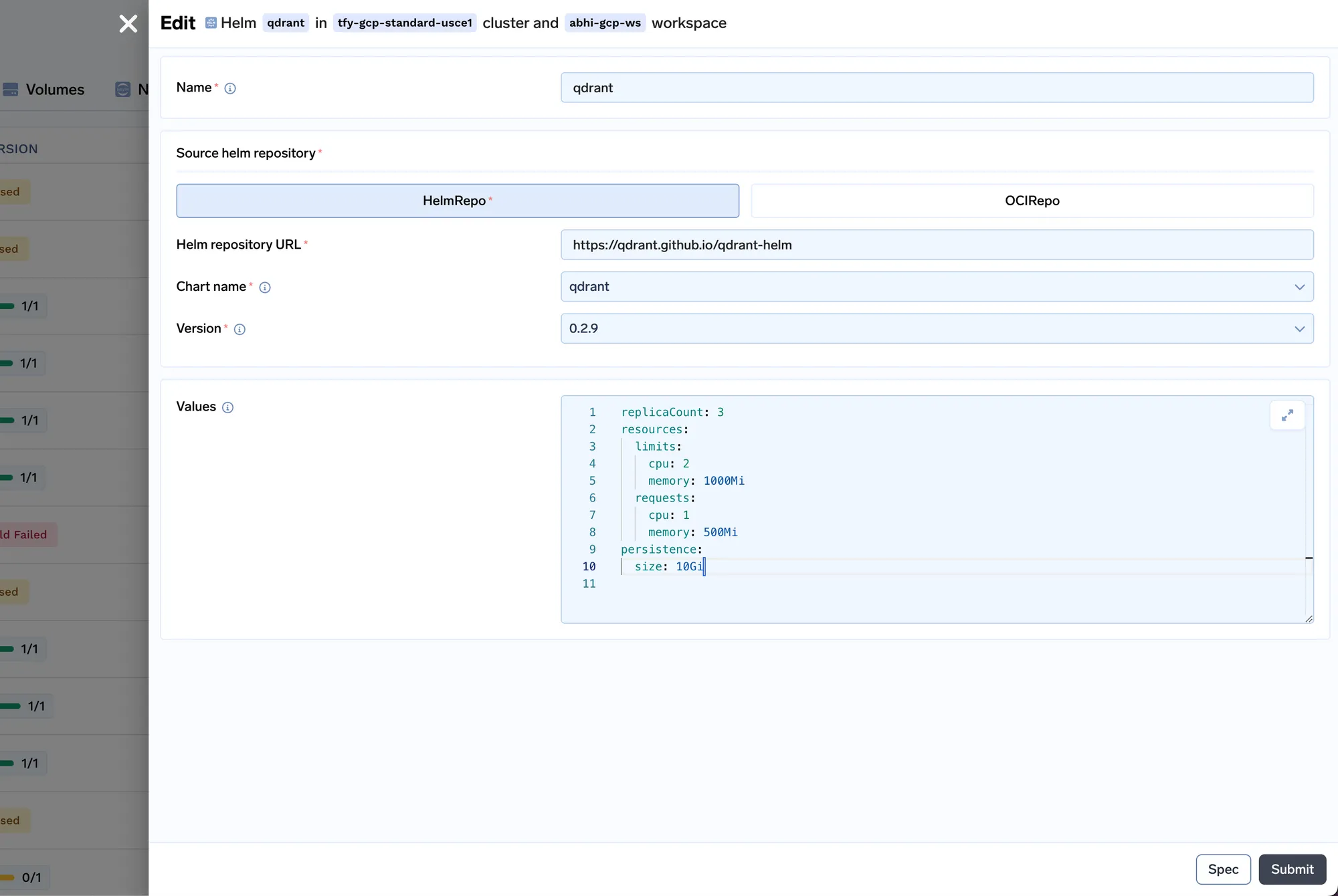
Vamos a implementar el Qdrant VectorDB.
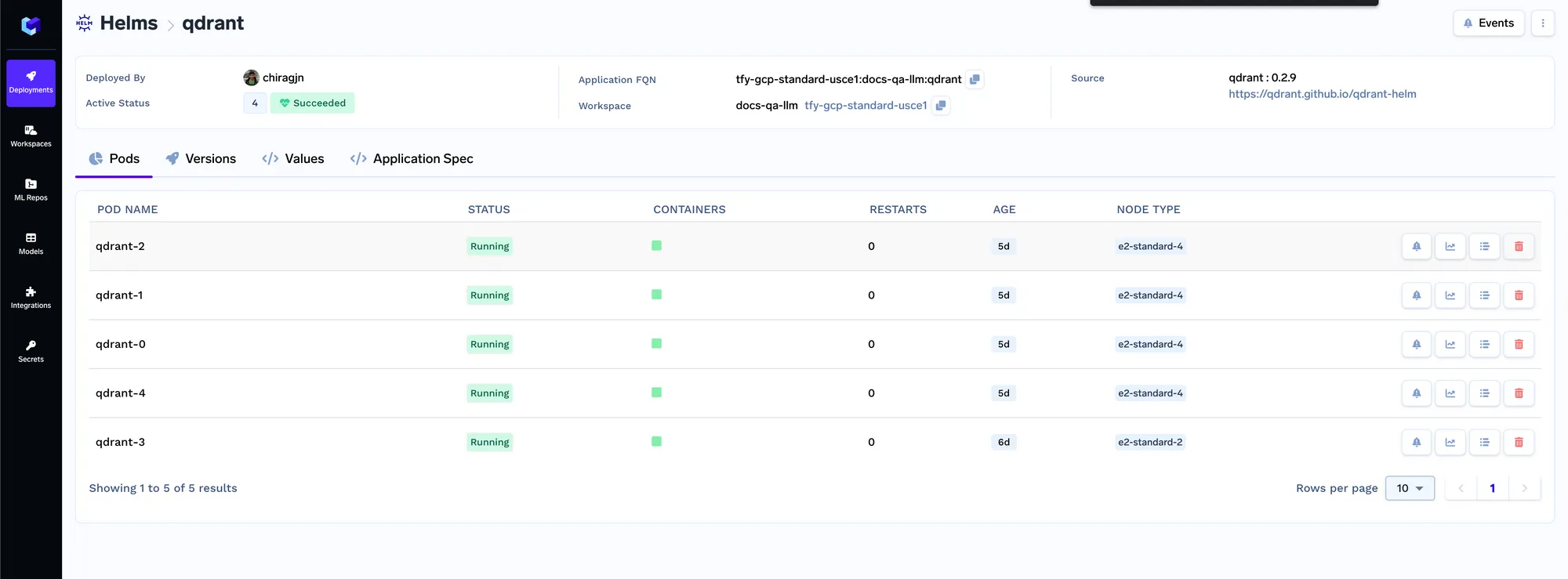
Ahora implementaremos el trabajo de indexación. El trabajo en Truefoundry nos permite ejecutar un script una vez o según lo programado y, a continuación, el procesamiento se detiene cuando finaliza el trabajo. El código del trabajo del indexador se puede encontrar aquí: https://github.com/truefoundry/docs-qa-playground/tree/main/backend/train. El trabajo de indexación permite cargar datos desde archivos locales o desde un artefacto de mlfoundry. También representa automáticamente un formulario en el que puede proporcionar argumentos para activar el trabajo. <artifact_fqn>Puede introducir el fqn del artefacto que copiamos en el paso 1 y pegarlo en el campo URI de origen como mlfoundry://. El nombre del repositorio puede ser cualquier cadena aleatoria que te ayude a identificar este trabajo de indexación. También tienes que introducir el nombre del repositorio de ML que creamos en el paso 1.
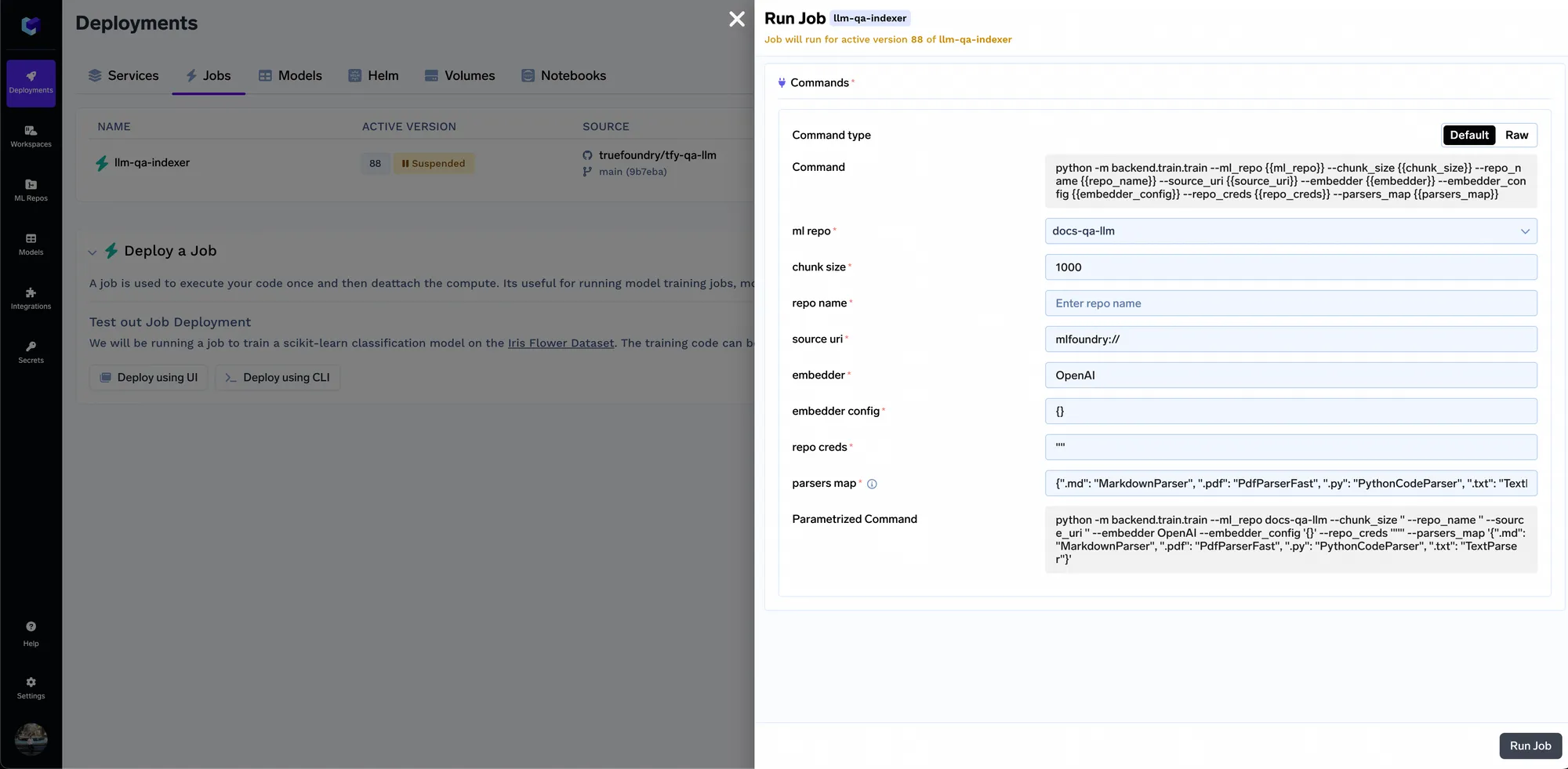
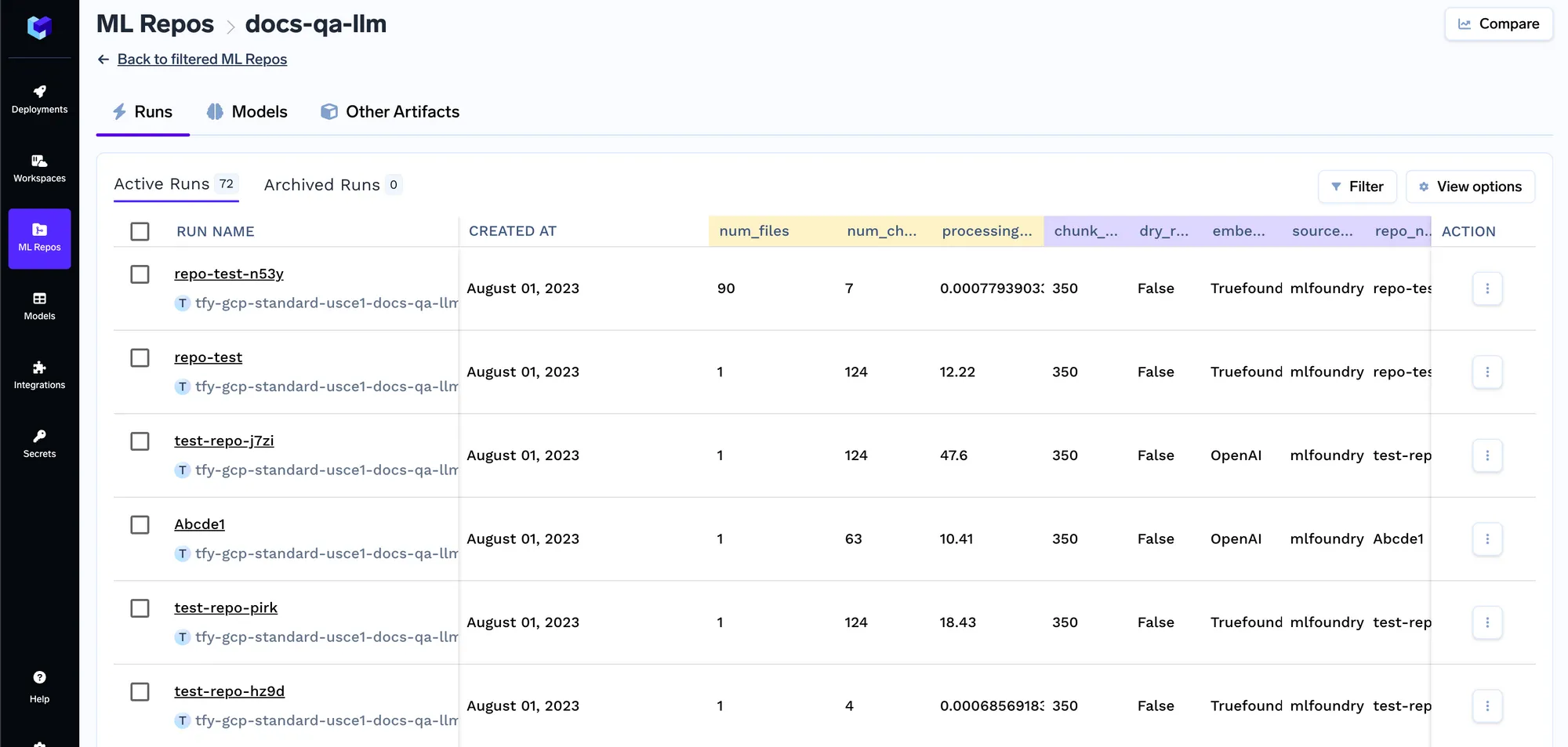
Una vez que el trabajo comience a ejecutarse, puede realizar un seguimiento de todas las ejecuciones del trabajo y sus registros:
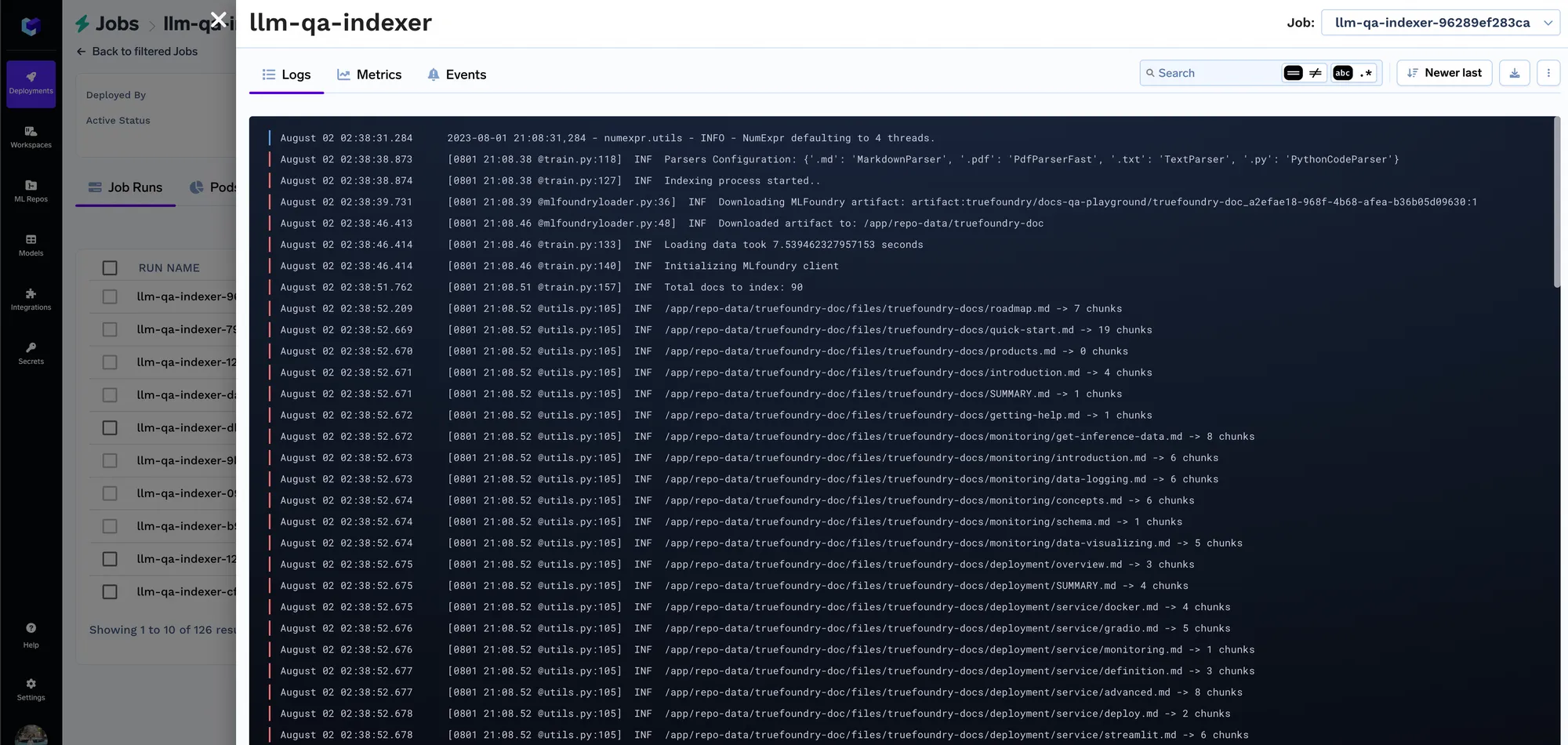
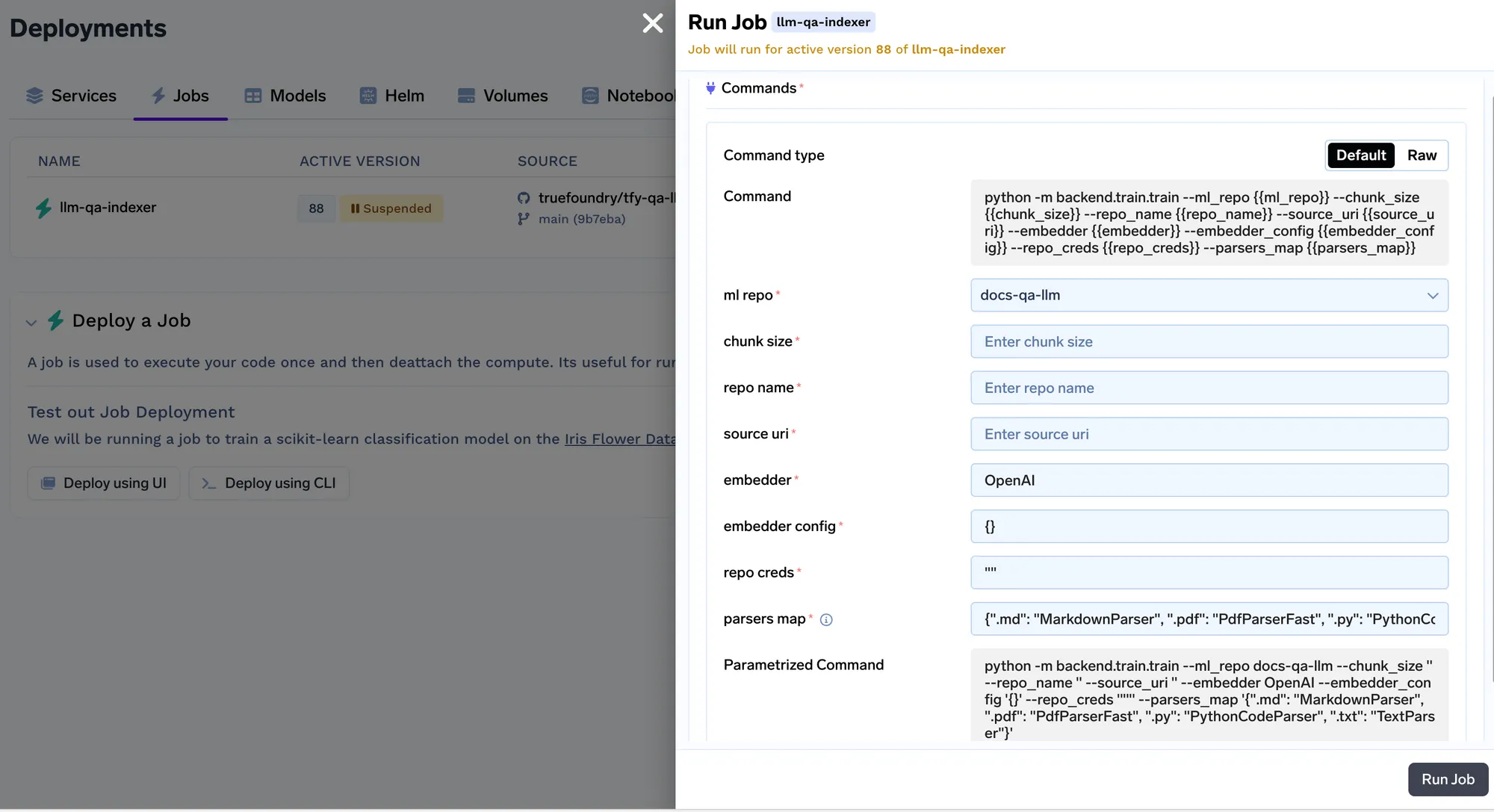
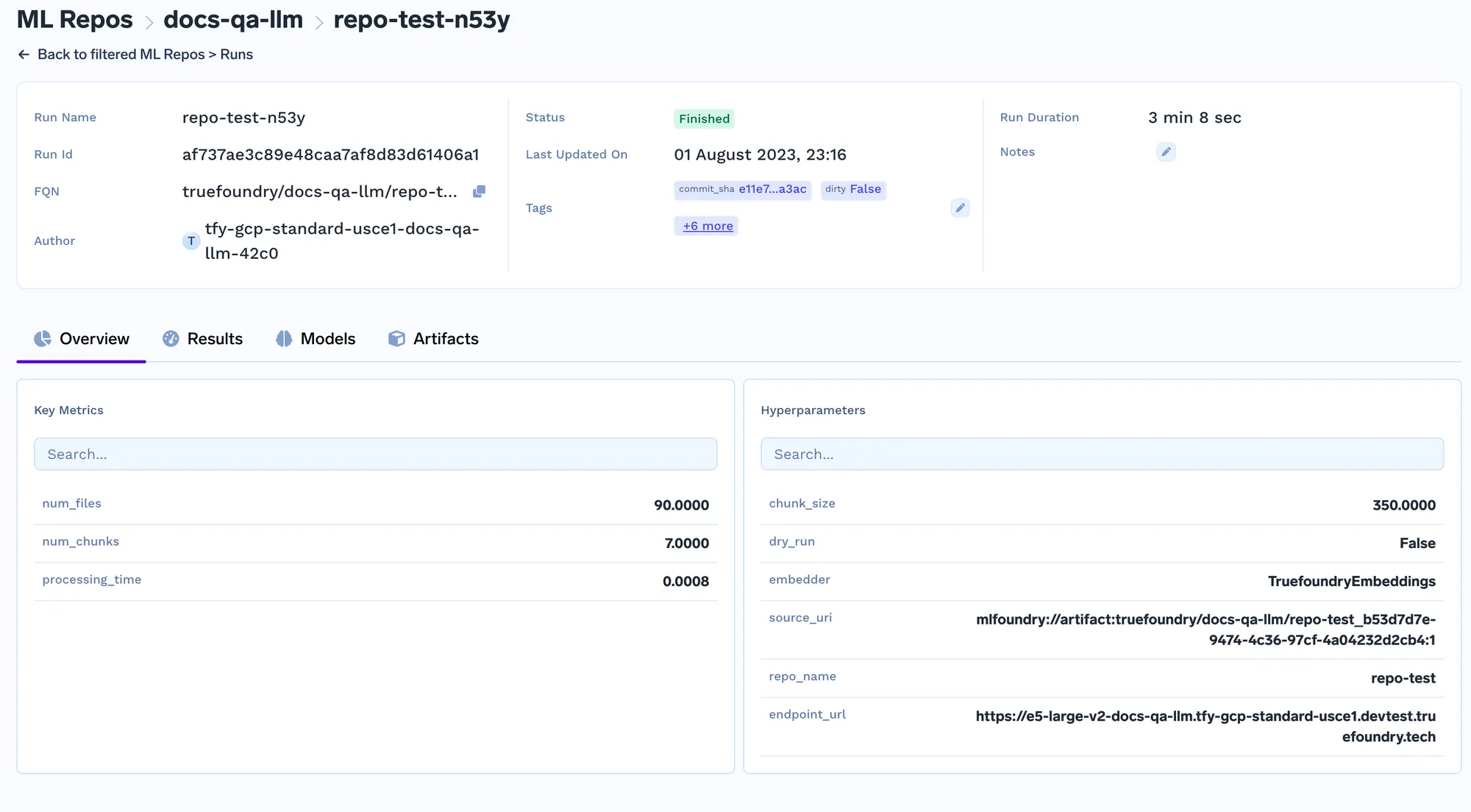
Cada vez que se ejecuta el trabajo, creamos una ejecución en el repositorio de ML que almacena todos los ajustes de incrustación y los parámetros del trabajo de indexación. Posteriormente, el servicio de consultas utiliza estas configuraciones para determinar la configuración de incrustación que se utilizará para incrustar la consulta. Puede realizar un seguimiento de los detalles de todos los trabajos de indexación en la pestaña de ejecuciones.
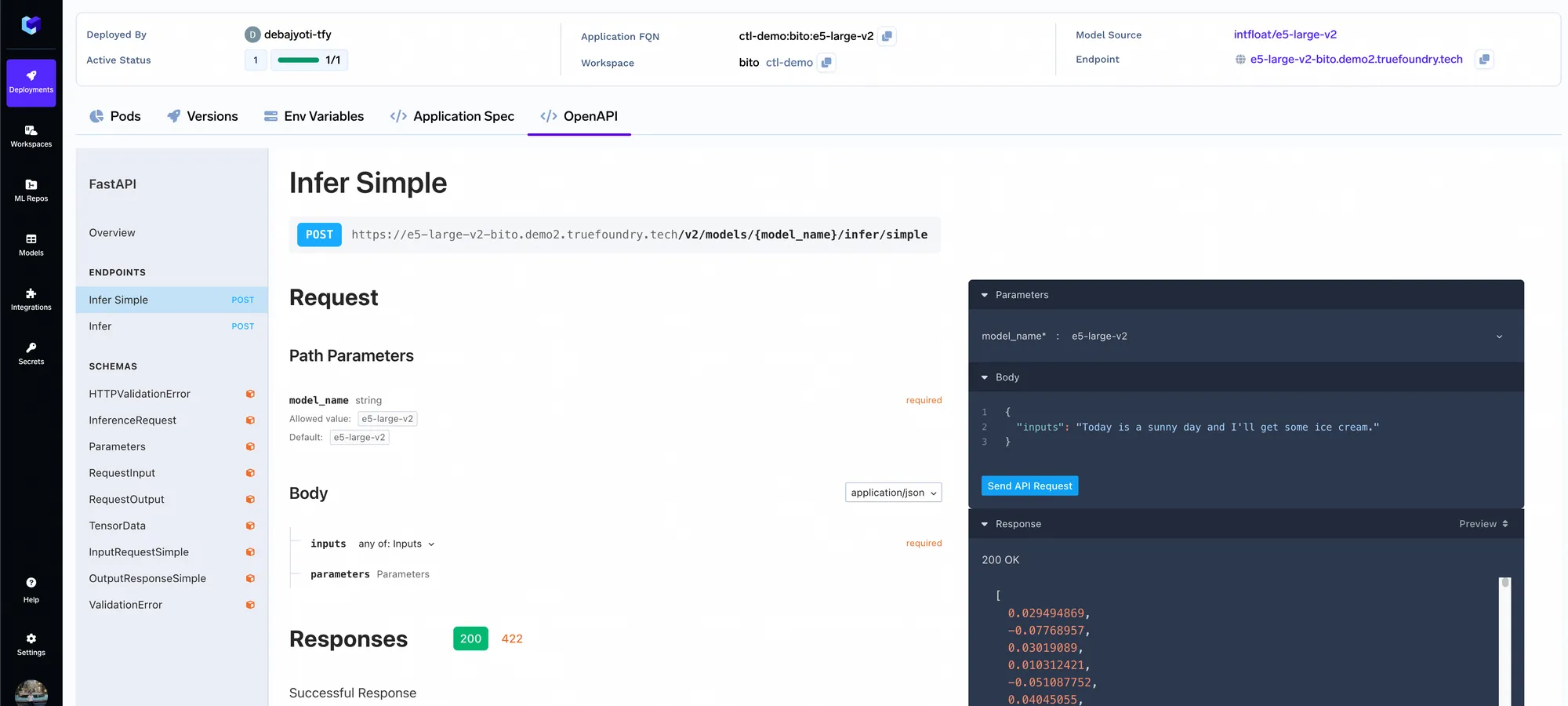
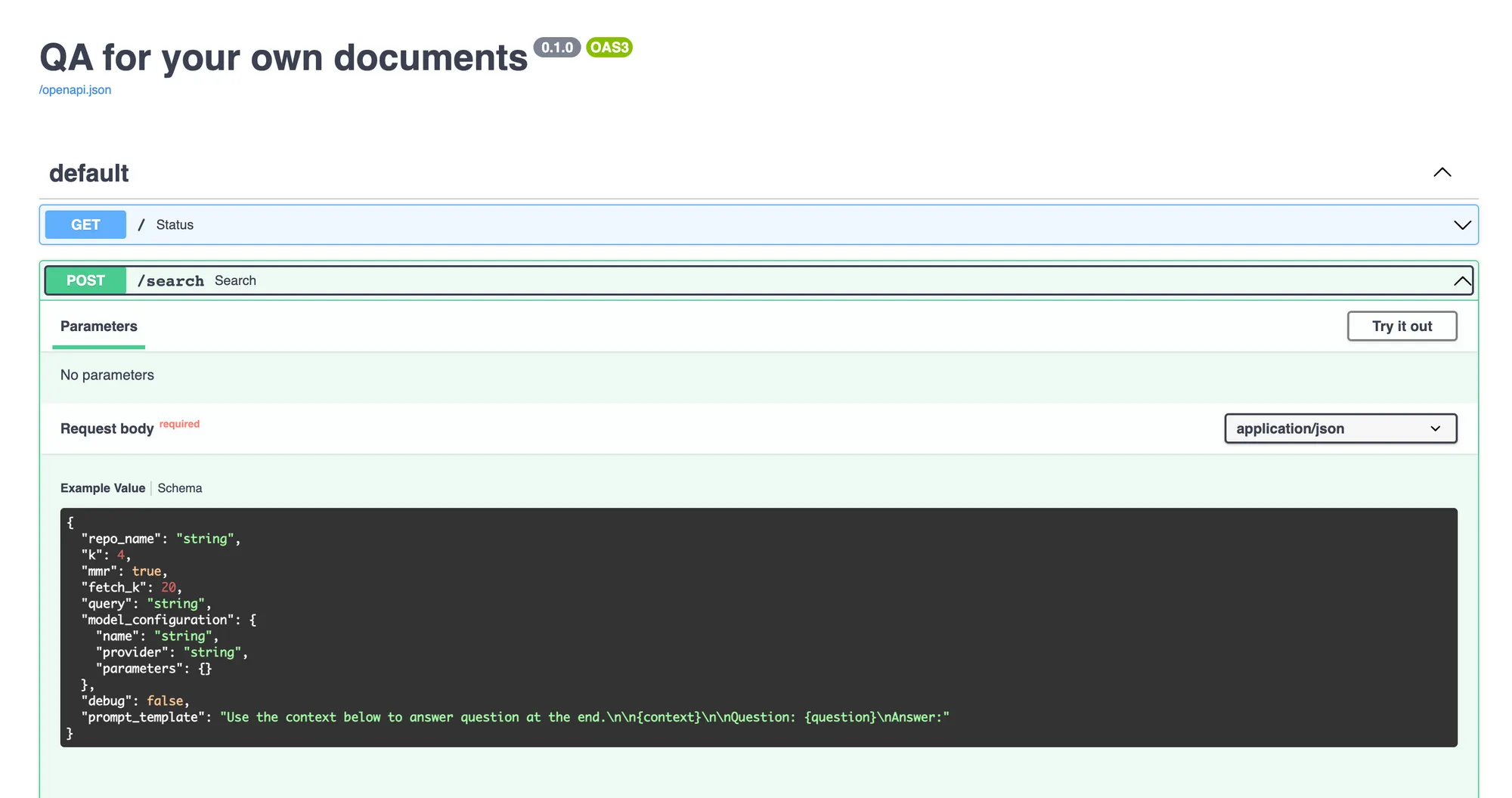
El servicio de consultas es un servidor fastapi que tiene una API para obtener la consulta y obtener la respuesta del LLM. Una vez que lo implemente, puede realizar consultas utilizando la interfaz de usuario de Swagger en fastapi.
Esto es necesario si planeas usar un LLM de código abierto y no OpenAI. Puede implementar el LLM desde el catálogo de modelos.
También ofrecemos una aplicación simplificada que se puede vincular a su backend de indexación, servicio de consultas y almacén de metadatos para enumerar todos los repositorios indexados y realizar consultas sobre ellos. Una demostración de muestra de esto está alojada en https://www.truefoundry.com/docs/introduction. Puedes encontrar el código en el repositorio de github aquí. Para que esta interfaz funcione, tendrás que vincularla a tu servicio de consultas y a tu trabajo mediante variables de entorno:
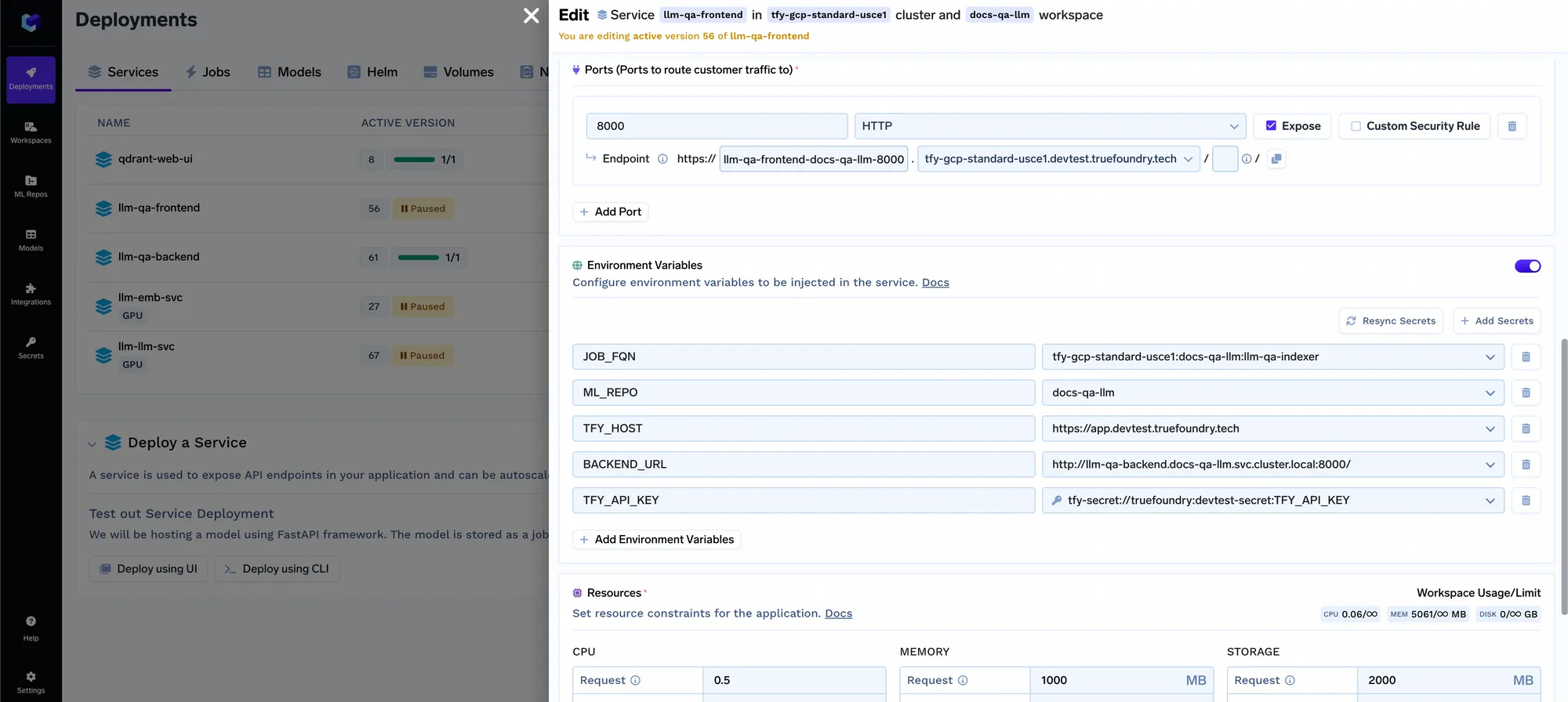
Ahora tenemos un sistema integral con una interfaz que se puede escalar a tantos casos de uso y conjuntos de documentos diferentes dentro de la organización. Hay algunas cosas que queremos incorporar en el futuro:
Esta arquitectura también permite tener un servicio central de indexación de documentos en una organización que depende de una biblioteca central de cargadores y analizadores de datos.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


