

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
La proliferación de modelos lingüísticos extensos (LLM) y sistemas de agencia marca un momento crucial para la tecnología empresarial. El potencial de innovación es enorme, pero también lo son las dificultades. En muchas organizaciones, la adopción temprana ha sido caótica: fragmentada, no gestionada e insegura. Los equipos individuales establecen sus propias conexiones con varios proveedores de modelos, lo que da como resultado experimentos aislados sin supervisión central, controles de costos ni estándares de seguridad.
Para pasar de esta experimentación ad hoc a una estrategia de IA coherente para toda la empresa, necesitamos un paradigma arquitectónico deliberado, uno que se base en la seguridad, la gobernanza y la escalabilidad desde el primer día.
Una pila de aplicaciones de agencia ideal en el entorno actual debe ofrecer:
Desarrollo rápido de aplicaciones — La ejecución federada de baja latencia en agentes y entornos heterogéneos reduce el tiempo de generación de valor (TTV), lo que permite a los equipos ofrecer rápidamente capacidades listas para la producción sin centralizar todos los datos o el procesamiento.
Flexibilidad preparada para el futuro — una pila modular e interoperable que puede adaptarse a los modelos, protocolos y patrones de agentes emergentes a medida que evoluciona el panorama de la IA.
Seguridad y cumplimiento por defecto — Enmascaramiento de PII, aplicación de políticas y auditabilidad total.
Operaciones deterministas en sistemas no deterministas — barreras, marcos de evaluación y rutas de retroceso cuando los productos se desvían.
Gobernanza de costos con granularidad simbólica — presupuestos, devoluciones y límites de uso.
Fiabilidad y portabilidad — conmutación por error multimodelo, implementación híbrida o local y cero dependencia de proveedores mediante interfaces independientes del proveedor, artefactos exportables y planes de migración de reproducción a switch.
Observabilidad profunda — rastreos, métricas a nivel de token (TTFT, TPS), tasas de aciertos de caché y tendencias de uso.
Capacidades componibles — modelos, herramientas y agentes conectados mediante instrucciones, no mediante un código de pegamento quebradizo.
Velocidad con control — CI/CD para modelos, agentes y herramientas; lanzamientos por etapas con pruebas canarias o A/B.
Y debemos diseñar teniendo en cuenta las restricciones del mundo real, tales como:
Aquí es donde la arquitectura se convierte en la diferencia entre una demostración inspiradora y un sistema de producción. El plan debe constar de cuatro capas críticas: modelos, servidores MCP, agentes y avisos.
1. Modelos: potenciando la inteligencia central
En el centro de cualquier aplicación de generación de inteligencia artificial se encuentra el modelo en sí mismo: el motor de razonamiento de su sistema. El desafío no consiste simplemente en elegir el «mejor» modelo, sino en diseñarlo para un mundo en el que los modelos sean numerosos, estén en constante evolución y se adapten a diferentes propósitos.
Una pila sólida trata los modelos como si fueran activos de software normales: se versionan, se hace un seguimiento de los cambios en los datos y el código, y se mueven durante el desarrollo, la puesta en escena y la producción. El enrutamiento también debe tener en cuenta el costo y el rendimiento; a veces, un modelo más pequeño y económico es la mejor opción para una tarea específica que ejecutar todo en una tarea grande y costosa.
La trampa en la que muchos caen es la expansión de modelos: demasiados modelos sin seguimiento, actualizaciones opacas y ninguna ruta de retroceso cuando el rendimiento disminuye. En este caso, la arquitectura significa disciplina: tratar los modelos con el mismo rigor que el código de la aplicación principal.
2. Servidores MCP: capacidades de estandarización
Si los modelos son el cerebro, los servidores MCP (Model Context Protocol) son el cinturón de herramientas. Proporcionan a sus agentes un acceso estandarizado y preparado para la empresa a sistemas como Jira, GitHub, Postgres o a API propietarias.
En lugar de integraciones personalizadas por equipo (cada una con sus propias peculiaridades, brechas de seguridad y lógica duplicada), se puede reutilizar un único servidor MCP certificado por sistema en toda la empresa. La E/S tipada, la autenticación y las cuotas se vuelven consistentes, predecibles y seguras.
Cuando los equipos se saltan este paso, se produce el caos: políticas de seguridad inconsistentes, trabajo redundante e integraciones frágiles que no se pueden compartir ni mantener. Los servidores MCP hacen que las capacidades sean componibles, no accidentales.
3. Agentes: la fuerza laboral digital
Los agentes son el lugar donde los modelos entran en funcionamiento. No son solo canalizaciones, sino que son las contrapartes digitales de los empleados humanos, capaces de tomar medidas, coordinar tareas y utilizar herramientas.
Un buen diseño de los agentes implica dar a cada uno una identidad, permisos basados en los privilegios mínimos y un ciclo de vida claro desde el entorno de prueba hasta la producción. Deben estar orquestados, ser capaces de colaborar entre varios agentes y ser portátiles en todos los entornos.
El mayor riesgo operativo en este caso es el acceso descontrolado: credenciales integradas en las capas de la interfaz de usuario, herramientas accesibles sin límites y falta de propiedad ni de SLA. Los agentes bien diseñados llevan consigo sus credenciales y alcances, y no están vinculados al lugar en el que se invocan.
4. Indicaciones: la interfaz operativa
Las indicaciones son la forma en que les decimos a los modelos y agentes qué hacer. No son solo texto sin formato, sino que pueden ser plantillas estructuradas, incluir pasos de evaluación e incorporar comprobaciones de políticas.
En una configuración sólida, las solicitudes se tratan como un código: se controlan por versiones, se prueban y se protegen contra la inyección inmediata o los cambios involuntarios. Utilizando almacenamiento en caché semántico puede ahorrar tiempo y dinero al reutilizar las respuestas para consultas similares en lugar de volver a ejecutar todo el proceso.
Si no administras las solicitudes correctamente, corres el riesgo de que se produzcan problemas de seguridad, de que se divulguen datos confidenciales o de que tus solicitudes cambien lentamente con el tiempo de formas que no habías planeado. Gestionarlos correctamente garantiza un comportamiento coherente, seguro y fiable.
Cuando las capas principales (modelos, servidores MCP, agentes y mensajes) se crean y administran con cuidado, el sistema se vuelve más confiable, escalable y fácil de mantener. Sin embargo, en las grandes organizaciones, a menudo surgen problemas en la forma en que se coordinan todas estas partes, no solo en las partes en sí mismas.
Los registros centralizados son el tejido conectivo del conjunto de la generación de inteligencia artificial: el memoria institucional que mantiene todos los componentes detectables, compatibles e interoperables. Sin ellos, corre el riesgo de volver a caer en el caos que esta arquitectura pretendía evitar: trabajo duplicado, brechas de seguridad y desviaciones invisibles de los estándares.
Una capa de registro sólida proporciona:
En la práctica, esta capa abarca varios registros especializados:
El sistema de registro de sus modelos: seguimiento versiones, linaje (datos, código, métricas), el estado de la implementación (dev/shadow/prod) y quién puede promover o usar un modelo. Está integrado en canales de CI/CD para que las nuevas versiones se registren automáticamente y puedan implementarse de forma segura mediante pruebas canarias o A/B. Más allá de la capacidad de descubrimiento, impone una política disciplinaria: no hay «modelos misteriosos» en producción ni cambios sin seguimiento.
El catálogo de herramientas certificadas disponible para los agentes, documentando sus funciones, argumentos y esquemas. También codifica permisos de uso—no todos los agentes deberían tener acceso a sus sistemas financieros o bases de datos confidenciales. Un servidor MCP, creado una vez, se puede reutilizar en todos los equipos, ya que la puerta de enlace impone el control de acceso basado en funciones a nivel de herramienta.
Un directorio de sus fuerza laboral digital—rastrear la identidad (UUID), el propietario, el propósito, las habilidades, los modelos/herramientas permitidos y las credenciales de cada agente. Registra todo el ciclo de vida, desde la creación hasta la retirada, y garantiza que el acceso con los privilegios mínimos se aplique en tiempo real en la puerta de enlace. Esto evita que los agentes conserven privilegios excesivos u obsoletos, el modo de error habitual.
Un repositorio versionado de políticas de seguridad de entrada y salida, que abarca Enmascaramiento de PII, detección rápida de inyección, límites tópicos, filtros de toxicidad, y verificación de hechos reglas. Las políticas se gestionan como código, lo que significa que se pueden implementar de forma incremental mediante pruebas canarias o A/B. Las políticas agrupadas (por ejemplo, un «chatbot que cumpla con la HIPAA») se pueden aplicar de manera uniforme en todos los modelos, agentes y herramientas.
Los registros nos brindan el andamiaje de la memoria y la gobernanza. Pero la gobernanza sobre el papel no significa nada si no se hace cumplir en tiempo de ejecución—donde se envían las solicitudes, se consumen los tokens y se entregan las respuestas.
Incluso con los componentes correctos y los registros bien gestionados, un sistema de IA moderno no funciona en el vacío. En producción, la verdadera prueba no es si la arquitectura se ve bien sobre el papel, sino si sigue funcionando en condiciones de fallo, demanda variable y costes impredecibles.
Aquí es donde entran en juego los «matices operativos». No se trata de componentes independientes, sino de patrones transversales que añaden durabilidad, eficiencia y capacidad de respuesta a todo el conjunto.
Patrones de alta disponibilidad
En un sistema de IA activo, el fracaso no es una posibilidad, es una certeza. Los modelos dejarán de funcionar, los puntos finales cambiarán y las redes se comportarán mal. El trabajo de un arquitecto es asegurarse de que estos eventos no se traduzcan en interrupciones para el usuario.
Bloquear se evita con la práctica, no con la promesa. Trate la salida como una disciplina durante el tiempo de ejecución, no como un proyecto de última milla.
Puerta de enlace independiente del proveedor — normalice los esquemas de solicitud/respuesta y las etiquetas de capacidad para que las aplicaciones nunca se vinculen al SDK de un proveedor.
Reproducir para Switch — supervise de forma rutinaria una parte representativa de los rastros de producción hasta un proveedor alternativo o un modelo autohospedado; haga un seguimiento de los deltas en cuanto a latencia, costo y calidad para mantener la trampilla de escape caliente.
Artefacto abierto — almacene las indicaciones, los seguimientos, las evaluaciones, las incrustaciones y los conjuntos de datos de ajuste en formatos exportables; mantenga los índices vectoriales reconstruibles desde el código fuente.
Matriz de compatibilidad — mantener un cuadro de mando del proveedor/modelo (latencia/costo/calidad/características) para que las políticas de enrutamiento se basen en los datos.
Derechos contractuales y de datos — prefiera términos que permitan reemplazar el peso y volver a entrenar; haga un seguimiento del linaje de los conjuntos de datos en el Registro de modelos para que la salida no se detenga en función de su procedencia.
Lista de verificación de salida — claves/configuración desacopladas del código, puntos finales secundarios previamente examinados, conjunto de datos de reproducción mínimo definido, brechas conocidas documentadas.
Las cargas de trabajo de IA tienen un costo inherentemente variable y, sin una administración activa, los costos pueden aumentar vertiginosamente. El desafío consiste en aplicar la disciplina de costos sin introducir obstáculos que frustren a los desarrolladores o usuarios.
Estos matices garantizan que el sistema funcione sin problemas cuando algo va mal. También ayudan a mantener los costos bajo control. La combinación de los matices del respaldo, la redundancia y el costo requiere un plano de control unificado; eso es lo que hace AI Gateway: reúne todas estas piezas en una sola parte central de la arquitectura GenAI moderna.
Las pasarelas de IA gobiernan modelos, agentes, herramientas, indicaciones y fichas. Es un especializado plano de control de middleware para el tráfico de IA: proxy de egreso o inverso que entiende los tokens, la semántica y las herramientas.
Qué hace
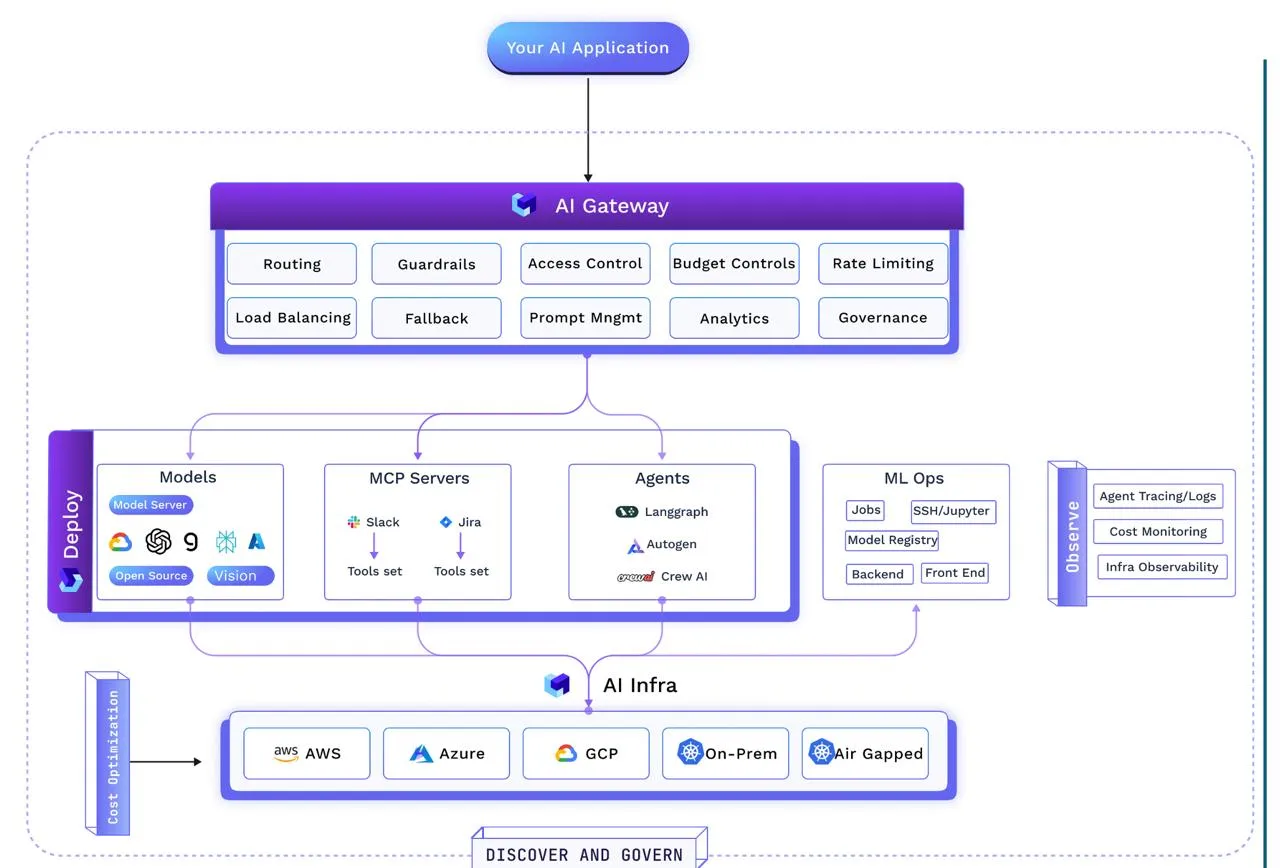
Una vez que se define el plan, se establecen los registros, se incorporan las salvaguardas operativas y AI Gateway las aplica en tiempo real, la pregunta es: ¿cómo ejecutamos realmente esta cosa?
Aquí es donde la conversación pasa de la arquitectura y la gobernanza a la ejecución: la capa de despliegue que puede mover el código y los modelos a la producción ayuno, guárdalos de confianza, y ejecútelos rentable—todo ello sin romper la disciplina operativa.
En este caso, la velocidad no significa tomar atajos. Un proceso moderno pasa de la confirmación al clúster en cuestión de minutos: las pruebas automatizadas validan los cambios, los contenedores, los modelos de paquetes, los agentes y los servidores MCP en imágenes inmutables, y los manifiestos los despliegan para el desarrollo, la puesta en escena o la producción con estrategias configurables. Las actualizaciones del registro garantizan que Gateway pueda descubrir y gestionar de inmediato las nuevas versiones. Las aplicaciones completas (modelo, backend, interfaz y herramientas) pueden implementarse en pilas preconfiguradas o incluso activarse mediante agentes de implementación conversacionales.
La confiabilidad está integrada a través de Mejores prácticas de SRE: escalado automático y conmutación por error instantáneos, supervisión proactiva, reversión y control de versiones a petición, registros de auditoría inmutables y cierre automático de entornos o IDE inactivos.
Las políticas aquí también se aplican reglas operativas como «no hay implementación de producción sin al menos dos réplicas» o «las cargas de trabajo de la GPU deben apagarse automáticamente cuando están inactivas».
La rentabilidad también es algo que hay que tener en cuenta: la capa utiliza sin problemas instancias puntuales con respaldo bajo demanda para ahorrar costos, escala las cargas de trabajo con HPA/VPA y escalado automático de clústeres, y aprovecha el escalado basado en eventos (por ejemplo, KEDA) para que los trabajadores estén conectados al instante cuando sea necesario y vuelvan a cero cuando están inactivos. Una función similar a la del piloto automático aplicaría los cambios de escalado o ubicación en tiempo real, equilibrando el ahorro de costes con la protección de los acuerdos de nivel de servicio.
El proceso de implementación estándar para una pila de IA agencial es el siguiente:
Los artefactos son imágenes OCI y los manifiestos son IaC simples; los puntos finales y las regiones están parametrizados. Esto mantiene las cargas de trabajo independientes de la nube y permite una reubicación rápida y basada en políticas sin tocar el código de la aplicación.
Con el sistema activo (modelos implementados en Kubernetes, agentes registrados y Gateway aplicando reglas de tiempo de ejecución), la arquitectura está operativa. Sin embargo, mantenerlo seguro, eficiente y alineado con las prioridades de la organización no es algo que se haga una sola vez. Las cargas de trabajo se moverán de un entorno a otro, se ampliarán y reducirán y evolucionarán con nuevas herramientas y modelos.
Si la gobernanza no avanza con ellos, se termina con un comportamiento paralelo: los agentes funcionan sin barreras, las cargas de trabajo se implementan sin redundancia o las GPU se quedan inactivas y se queman los costos. La respuesta es simple en principio, pero poderosa en la práctica:políticas que van acompañadas de la carga de trabajo.
Además, las barandillas no pueden vivir como scripts ad hoc enterrados en la base de código de un equipo. Deberían serlo política como código—versionado, revisado e implementado como cualquier otro artefacto central:
Las políticas no se centran solo en la seguridad de la IA. Pueden codificar estándares operativos para toda la organización:
Estas reglas garantizan que sus sistemas cumplan con los estándares básicos de confiabilidad y eficiencia por defecto, sin depender de las comprobaciones manuales ni de la memoria del equipo.
En muchos sectores regulados o de alta seguridad, la ejecución de grandes modelos patentados en producción se convierte en un desafío. La optimización de un modelo autohospedado más pequeño evita esa barrera y, al mismo tiempo, preserva la calidad. Además, dado que la puerta de enlace ya se encuentra en el flujo de tráfico, puede gestionar la migración, comparando el nuevo modelo con el anterior, realizando pruebas A/B y dirigiendo el tráfico en consecuencia una vez que el rendimiento converja. El uso a gran escala de LLM de código abierto con precisión para los casos de uso de la generación de inteligencia artificial también es rentable para las empresas.
The Gateway no solo trata de hacer cumplir la ley, sino también de motor modelo evolution. Al registrar las interacciones de alta calidad de un modelo grande y caro como el GPT-4o, crea un conjunto de datos que se ajusta con precisión para un modelo más pequeño y eficiente como Llama.
Este enfoque le permite:
Desde el punto de vista del arquitecto, esto convierte a AI Gateway en algo más que una capa de cumplimiento: se convierte en un motor modelo evolution, transformando silenciosamente los datos de tiempo de ejecución en la base de su IA de próxima generación, optimizada en cuanto a costos y lista para la producción.
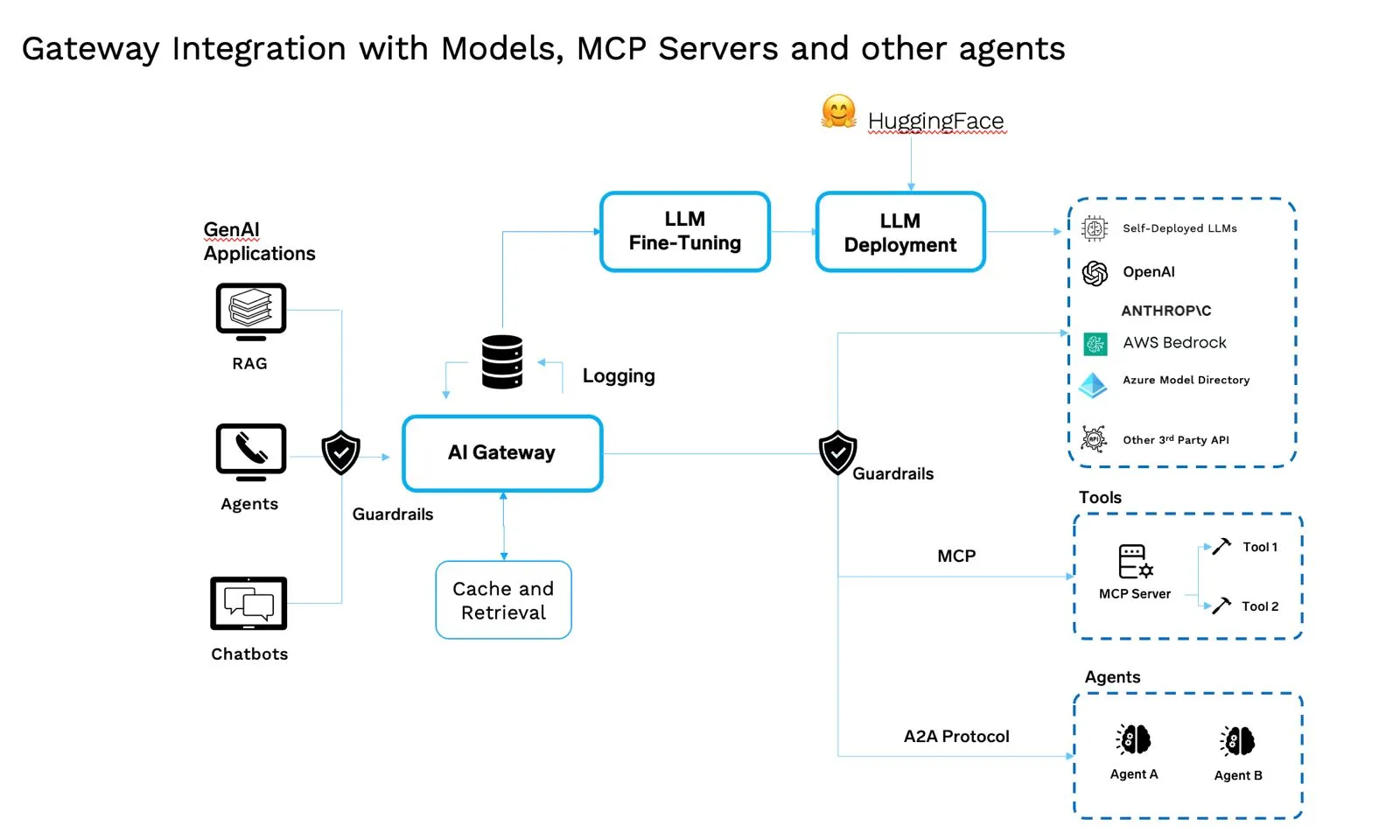
Cuando miras la pila como un todo, el valor no está en las piezas individuales sino en cómo funcionan juntas. Es necesario rastrear y versionar los modelos. Los servidores MCP los exponen de manera consistente. Los agentes aportan razonamiento y toma de decisiones. Las indicaciones les dan instrucciones claras. Los registros garantizan que sepa qué se está ejecutando y dónde. Las políticas operativas mantienen las cosas seguras y rentables. Kubernetes le brinda la escalabilidad y la confiabilidad necesarias para ejecutarlo todo.
El AI Gateway se encuentra en la parte superior para coordinar estas partes móviles, pero la verdadera fortaleza proviene de la integración: todas las capas están conectadas, administradas y son observables. Esto es lo que convierte un conjunto de herramientas en un sistema en el que las empresas pueden confiar y construir.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


