

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Jeden Freitag tippe ich dasselbe:
„Ich bin Prathamesh. Leitender Softwareingenieur bei TrueFoundry. Ich arbeite am Speicherdienst. Format: was ich versendet habe, was ist in Bearbeitung, Blocker. Halte es kurz.“
Dann frage ich nach meinem wöchentlichen Update.
Die KI schreibt es perfekt. Aber nächsten Freitag? Das gleiche Ritual. Es wird sich nicht an meinen Namen, meine Rolle, mein Projekt erinnern oder daran, dass ich denselben Blocker drei Wochen hintereinander erwähnt habe.
Ich habe diesen Assistenten selbst gebaut: einfache Chat-UI, TrueFoundrys AI Gateway im Backend. Es verarbeitet Standups, E-Mails, Slack-Nachrichten und Dokumentationsentwürfe. Es ist wirklich nützlich. Aber jede Sitzung beginnt bei Null. Ich verwende den Speicher der KI nicht. ICH bin das Gedächtnis der KI.
ChatGPT hat dies mit eingebautem Speicher gelöst. Aber wenn Sie Ihre eigene LLM-Anwendung erstellen, existiert diese Infrastruktur nicht. Sie sind auf sich allein gestellt. Es sei denn, du baust es selbst.
Also habe ich es getan. Echtes Mem ist eine persistente Speicherschicht für KI-Anwendungen. Es bietet jedem LLM-Langzeitgedächtnis, das sitzungsübergreifend und sogar modellübergreifend funktioniert. Du musst dich nicht mehr wiederholen. Die KI erinnert sich tatsächlich.
Die offensichtlichen Lösungen haben offensichtliche Probleme.
Der eingebaute Speicher von ChatGPT ist im OpenAI-Ökosystem eingeschlossen. Sie können nicht programmgesteuert darauf zugreifen, es mit anderen Modellen verwenden oder überprüfen, was gespeichert wird. Das KI-Gateway von Truefoundry hilft uns, auf mehrere Modelle zuzugreifen und zu überprüfen, was gespeichert wird. Für jeden, der seine eigenen Anwendungen erstellt, ist das ein Kinderspiel.
Augmentierte Generierung (RAG) löst ein anderes Problem. RAG ruft Informationen aus Dokumenten ab. Es beantwortet die Frage „Was steht in diesem PDF?“ Das Benutzergedächtnis unterscheidet sich grundlegend. Es ist persönlich, entwickelt sich und basiert auf Beziehungen. Die Fakten, die ich im Gespräch teile, sind keine Dokumente, die indexiert werden müssen; sie sind ein Kontext, der jede zukünftige Interaktion prägen sollte.
Das Erweitern von Kontextfenstern ist der Brute-Force-Ansatz: Beziehen Sie den gesamten Konversationsverlauf ein. Moderne Modelle unterstützen 128K Token oder mehr, warum also nicht? Da Tokens teuer sind, bedeutet mehr Kontext eine langsamere Inferenz, und alles verschwindet, wenn die Sitzung endet. Sie zahlen eine Prämie für Amnesie mit zusätzlichen Schritten.
Was wir brauchen, ist eine dedizierte Ebene, die destillierte Fakten über Benutzer dauerhaft speichert und nur das abruft, was für jede Abfrage relevant ist. Das ist die Lücke Echtes Mem Füllungen.
Das menschliche Gedächtnis funktioniert nicht, indem es jedes Gespräch wörtlich speichert. Wir haben ein Arbeitsgedächtnis für die aktuelle Aufgabe und ein Langzeitgedächtnis für persistentes Wissen. Die beiden Systeme interagieren ständig: Das Langzeitgedächtnis gibt Auskunft darüber, wie wir neue Informationen interpretieren, während wichtige neue Erfahrungen im Langzeitspeicher konsolidiert werden.
Echtes Mem spiegelt diese Architektur mit zwei unterschiedlichen Komponenten wider: Kurzzeitgedächtnis (STM) für den Gesprächskontext und Langzeitgedächtnis (LTM) für persistente Nutzerfakten.
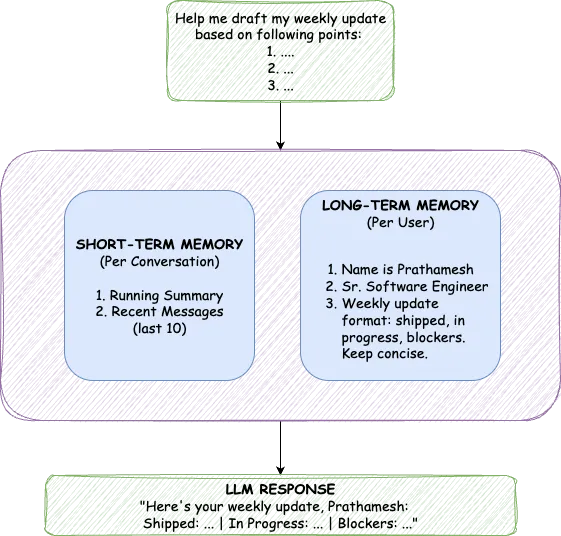
Die Trennung ist wichtig, da diese Speichertypen unterschiedlichen Zwecken dienen. STM erfasst, was gerade passiert, den gesamten Ablauf der aktuellen Konversation. LTM speichert destillierte Fakten, die über alle Konversationen hinweg Bestand haben. STM ist immer im Kontext enthalten; LTM wird auf der Grundlage der semantischen Relevanz abgerufen. Der Versuch, beide mit einem Mechanismus zu lösen, zwingt zu einem Kompromiss. Der duale Ansatz vermeidet dies vollständig.
Innerhalb einer einzigen Chat-Sitzung muss sich die KI merken, was Sie vor fünf Minuten besprochen haben. Dies ist die Aufgabe von STM, und es enthält zwei Komponenten: eine fortlaufende Zusammenfassung älterer Nachrichten und die letzten zwanzig Nachrichten in voller Genauigkeit.
Wenn eine Konversation wächst, verfolgen wir kontinuierlich die Gesamtzahl der Token. Wenn ein Schwellenwert überschritten wird, komprimiert ein Hintergrund-Worker ältere Nachrichten zu einer fortlaufenden Zusammenfassung, wobei die letzten Nachrichten intakt bleiben.

Die Zusammenfassung ist asynchron, sodass Benutzer nie darauf warten. Wenn der Schwellenwert überschritten wird, ruft ein Hintergrundjob unzusammengefasste Nachrichten ab, kombiniert sie mit einer vorhandenen Zusammenfassung und generiert eine aktualisierte, umfassende Zusammenfassung. Diese Nachrichten werden als „zusammengefasst“ markiert und der Zyklus wird fortgesetzt. Progressive Komprimierung bedeutet, dass selbst stundenlange Konversationen innerhalb angemessener Kontextgrenzen bleiben.
Der Gesprächskontext allein reicht jedoch nicht aus. Was passiert, wenn der Benutzer morgen zurückkehrt? Hier kommt das Langzeitgedächtnis ins Spiel.
LTM speichert Fakten über Benutzer, die auf unbestimmte Zeit bestehen bleiben: ihren Namen, Beruf, Vorlieben, Kommunikationsstil und alles andere, an das man sich in Gesprächen erinnern sollte. Diese werden nicht als Rohtext gespeichert. Sie werden in Vektoreinbettungen umgewandelt, was Semantik ermöglicht Ähnlichkeitssuche.
Wenn ein Benutzer fragt „Welche Programmiersprache sollte ich verwenden?“ , wir vergleichen keine Stichwörter mit gespeicherten Erinnerungen. Wir betten die Abfrage ein und finden Erinnerungen, die semantisch verwandt sind. Erinnerungen wie „Der Benutzer bevorzugt Python“ und „Funktioniert mit ML-Infrastruktur“ tauchen auf, weil sie konzeptionell relevant sind, auch ohne gemeinsame Schlüsselwörter.
Das System füllt LTM über zwei Kanäle. Explizite Erinnerungen entstehen durch direkte Anfragen: „Denken Sie daran, dass ich Stichpunkte bevorzuge“ oder „Vergessen Sie nicht, dass ich allergisch gegen Erdnüsse bin“. Wir erkennen Auslöserphrasen, extrahieren die Kernfakten und speichern sie mit maximaler Wichtigkeit. Diese Erinnerungen werden niemals automatisch gelöscht.
Automatische Erinnerungen stammen aus der Gesprächsanalyse. Wenn ein Benutzer erwähnt: „Ich habe das ML-Plattform-Team geleitet“, ist das auch ohne eine ausdrückliche Speicheranfrage ein wertvoller Kontext. Nach jeder Interaktion untersucht ein Mitarbeiter im Hintergrund die Konversation und extrahiert Fakten, die es wert sind, gespeichert zu werden. Jede dieser Informationen ist mit einer Wichtigkeitsbewertung versehen.
Die Wichtigkeitswerte reichen von eins bis fünf. Eine Fünf steht für wichtige Informationen, die niemals vergessen werden sollten: ausdrückliche Benutzeranweisungen, starke Präferenzen, Allergien. Eine Vier steht für wichtige persönliche Fakten wie Beruf oder Standort. Dreien sind allgemeine Kontexte wie Hobbys und Interessen. Zwei behandeln temporäre Informationen wie aktuelle Projekte. Eins sind geringfügige Details. Explizite Erinnerungen erhalten automatisch eine Fünf; automatische Extraktionen erzielen in der Regel zwischen eins und vier, je nachdem, wie wichtig die Tatsache erscheint.
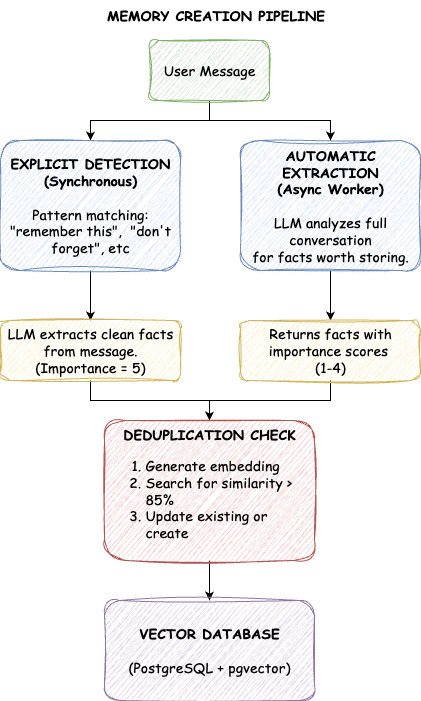
Bei der automatischen Extraktion entsteht eine Herausforderung: Was ist, wenn ein Benutzer in einer Sitzung „Ich mag Python“ und in einer anderen „Ich bevorzuge Python gegenüber JavaScript“ sagt? Naiver Speicher erzeugt Duplikate. TrueMem löst dies mit semantischer Deduplizierung. Vor dem Speichern suchen wir nach vorhandenen Speichern mit einer Ähnlichkeit von über 85%. Wenn fast ein Duplikat existiert, aktualisieren wir es, anstatt einen neuen Eintrag zu erstellen. Die Datenbank bleibt sauber, und jeder Fakt erscheint genau einmal in seiner vollständigsten Form.
Der Datenschutz wird durch Transparenz gewährleistet. Benutzer können jeden gespeicherten Speicher anzeigen, bearbeiten und löschen. Alle Speicher sind pro Benutzer strikt isoliert. Bei Unternehmensbereitstellungen läuft das gesamte System auf Ihrer Infrastruktur. Nichts verlässt Ihre Umgebung.
Was ist mit der Extraktionsgenauigkeit? Verschiedene Mechanismen lösen dieses Problem: Durch Wichtigkeitsbewertung werden automatische Extraktionen vor expliziten Erinnerungen entfernt; Benutzer können Fehler überprüfen und korrigieren; und korrekte Informationen, die in Konversationen verstärkt werden, gewinnen an Bedeutung, während einmalige Fehlextraktionen durch natürliches Bereinigen verschwinden.
Erinnerungen zu speichern ist nur das halbe Problem. Wenn ein Benutzer eine Nachricht sendet, benötigen wir die richtige Teilmenge: nicht alles, nur das, was relevant ist. Ein Power-User könnte 150 gespeicherte Fakten haben; wenn man sie alle einbezieht, würde das Kontextfenster explodieren.
Der Prozess bettet die Nachricht des Benutzers ein, führt eine Kosinusähnlichkeitssuche durch und gibt die zehn besten Treffer zurück. Bei richtiger Indizierung dauert dies weniger als 10 Millisekunden.
Eine Ausnahme: neue Nutzer. Wenn jemand weniger als zehn Erinnerungen hat, beziehen wir alle ein, unabhängig von ihrer Ähnlichkeit. Zu Beginn einer Beziehung ist jeder Kontext wichtig. Sobald die Anzahl zehn übersteigt, wechseln wir zum reinen Abruf auf Ähnlichkeitsbasis.
Dieser Abruf ist Teil einer größeren Kontextvorbereitung und muss schnell sein.
Eine Speicherebene ist nur nützlich, wenn sie keine merkliche Latenz verursacht. Benutzer reagieren empfindlich auf Verzögerungen; selbst 200 Millisekunden fühlen sich träge an. Unser Ziel für die Kontextvorbereitung lag bei unter 80 ms.
Der Schlüssel ist Parallelisierung. Die Kontextvorbereitung umfasst mehrere unabhängige Operationen: das Generieren einer Einbettung, das Abrufen aktueller Nachrichten, das Überprüfen auf explizite Trigger und das Durchsuchen von Langzeitgedächtnissen. Anstatt sequentiell zu laufen, starten wir sie parallel.
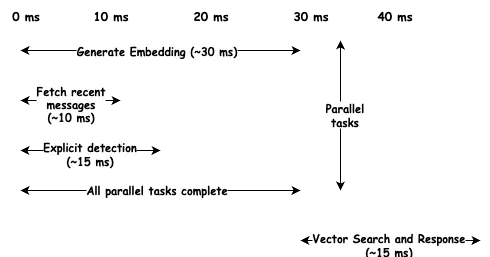
Die Generierung der Einbettung ist mit etwa 30 Millisekunden am langsamsten, aber sie läuft parallel zu Datenbankabfragen, die in 10 ms abgeschlossen sind. Wir zahlen für die längste Operation, nicht für die Summe. Die Gesamtlatenz liegt bei etwa 45 ms und damit deutlich unter dem Zielwert.
Schwere Operationen wie Zusammenfassung und Speicherextraktion werden asynchron ausgeführt, nachdem die Antwort gesendet wurde. Der Benutzer wartet nie; die Verarbeitung erfolgt im Hintergrund. Diese Trennung zwischen dem schnellen synchronen Pfad und dem langsamen asynchronen Pfad ist für den Einsatz in der Produktion unerlässlich.
Da der Speicher zuverlässig funktionierte, zeigte sich ein unerwarteter Vorteil: Wir hatten versehentlich etwas Modellunabhängiges gebaut.
Folgendes haben wir nicht erwartet. Sobald der Speicher außerhalb des Modells gespeichert ist, sind Sie nicht mehr an einen einzigen Anbieter gebunden.
Von GPT-4 zu Claude wechseln? Ihr Gedächtnis bleibt bestehen. Verwenden Sie verschiedene Modelle für verschiedene Aufgaben, z. B. komplexes Denken mit einer und kreatives Schreiben mit einer anderen? Sie alle teilen das gleiche Verständnis von dir. Ein benutzerdefiniertes Modell verfeinern? Es erbt vom ersten Tag an bestehende Benutzerbeziehungen.
Die Speicherschicht wird zu Ihrer Konstante; Modelle werden austauschbar.
Die Integration bleibt minimal: Rufen Sie den Kontext vor dem LLM-Aufruf ab und protokollieren Sie die Interaktion danach. Zwei API-Aufrufe verwandeln jedes statuslose Modell in ein Modell mit persistentem Speicher. Keine SDK-Abhängigkeit, keine komplexe Integration. Nur HTTP-Endpunkte, die zu jeder Architektur passen.
Natürlich können Erinnerungen nicht ewig wachsen. Ein System ohne Lifecycle-Management würde in veralteten Fakten untergehen.
Jede Erinnerung hat einen Wichtigkeitswert von eins bis fünf. Explizite Anweisungen erhalten eine Fünf. Wichtige persönliche Fakten erhalten eine Vier. Der allgemeine Kontext erhält eine Drei. Temporäre Informationen erhalten eine Zwei. Kleine Details erhalten eine Eins.
Wenn die Zählung ein weiches Limit überschreitet (standardmäßig 150), wird das Beschneiden aktiviert. Das System erreicht nie die Wichtigkeit 4 oder höher. Unter den Erinnerungen mit niedrigerer Bedeutung entfernt es die niedrigste Punktzahl zuerst, wobei das Alter als Entscheidungsgrund verwendet wird.
Explizite Benutzeranweisungen sind auf unbestimmte Zeit gültig. Automatische Extraktionen von geringem Wert werden recycelt, um Platz für neue Informationen zu schaffen. Der Speicher bleibt auch ohne manuelles Kuratieren relevant.
Ein Benutzer öffnet einen Chat und gibt Folgendes ein: „Hilf mir, mein wöchentliches Update zu verfassen, basierend auf folgenden Punkten...“
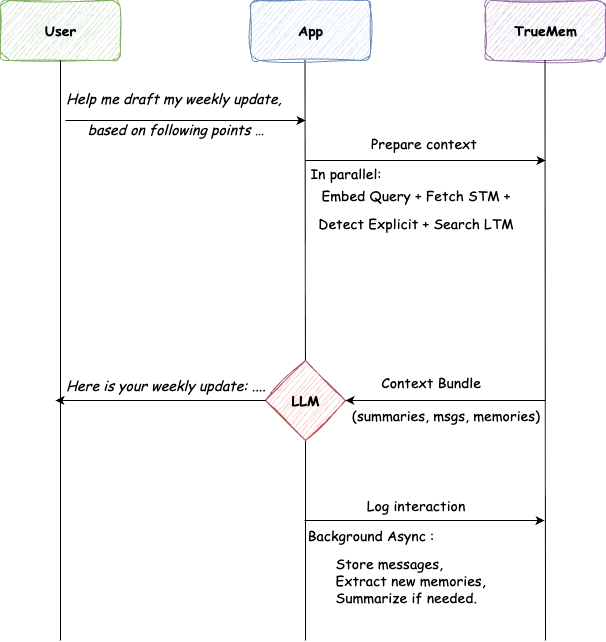
Die App ruft TrueMem für den Kontext auf. TrueMem stellt STM und relevante LTM zusammen, darunter „Name ist Prathamesh“, „Senior ML Engineer“, „Working on Memory Service“. Das dauert 45 Millisekunden.
Das LLM generiert eine personalisierte Antwort: „Hier ist dein wöchentliches Update, Prathamesh...“ Kein Ritual. Keine Wiedereinführung. Die KI weiß, wer fragt.
Nach der Antwort protokolliert die App die Interaktion. Mitarbeiter im Hintergrund speichern Nachrichten, extrahieren alle neuen Fakten und aktualisieren Zusammenfassungen nach Bedarf. Schweres Heben passiert unsichtbar.
Wir haben uns aus pragmatischen Gründen für PostgreSQL mit pgvector gegenüber dedizierten Vektordatenbanken entschieden. Die meisten Teams verwenden Postgres bereits. Mit vollen ACID-Garantien stehen neben Benutzerdaten auch Erinnerungen zur Verfügung. Für Sammlungen von 100-200 Vektoren pro Benutzer bietet pgvector eine Ähnlichkeitssuche unter 10 ms. Für benutzerspezifischen Speicher ist es die richtige Wahl.
Hintergrund-Worker laufen in Redis-gestützten Warteschlangen, weil LLM-Aufrufe Sekunden dauern — viel zu lange, um Anfragen zu blockieren. Mitarbeiter können Fehler und Batch-Operationen wiederholen und unabhängig voneinander skalieren, ohne dass die Latenz für die Benutzer beeinträchtigt wird.
Erinnerst du dich an das Freitagsritual? „Ich bin Prathamesh. Leitender Softwareingenieur. Ich arbeite am Speicherdienst.“
Mit TrueMem passiert das einmal. Die KI erinnert sich. Das Update vom nächsten Freitag funktioniert einfach. Der E-Mail-Entwurf des nächsten Monats kennt meine Signatur. Der Kontext ist immer da.
Noch besser: Wechseln Sie zu einem anderen Modell und der Speicher wird übernommen. Der tägliche Assistent wird ohne zusätzliche Arbeit modellunabhängig.
Das ist das Ziel. KI, die sich an dich erinnert. Nicht weil du es ständig daran erinnerst, sondern weil es das tatsächlich tut.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




