

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Es ist verlockend zu glauben, dass die größte Herausforderung bei KI-Agenten die Intelligenz ist. Für eine lange Zeit war das wahr. Die Modelle hatten Mühe, vernünftig zu denken, Werkzeuge waren spröde und mehrstufige Aufgaben fielen leicht auseinander. Aber diese Phase liegt größtenteils hinter uns.
Moderne Agenten können schon viel tun. Sie können in mehreren Schritten argumentieren, Tools aufrufen, MCP-Server aufrufen und sich sogar mit anderen Agenten abstimmen. Mit den richtigen Eingabeaufforderungen und Modellen können viele Teams in überraschend kurzer Zeit beeindruckende Agenten-Prototypen erstellen. Demos sehen überzeugend aus. Erste Ergebnisse fühlen sich magisch an.
Und doch, wenn dieselben Systeme zur realen Nutzung gedrängt werden, fangen sie an, auf leise, verwirrende Weise zu versagen.
Dies ist die Lücke, die die aufstrebende Wirtschaft von Agent zu Agent definiert. Kein Mangel an Intelligenz, sondern ein Mangel an Infrastruktur.
Die meisten frühen Agentenimplementierungen folgen einem täuschend einfachen Muster. Ein Benutzer sendet eine Eingabe, der Agent überlegt darüber, ruft optional ein Tool auf und gibt eine Antwort zurück. Dieser lineare Ablauf ist leicht zu verstehen und leicht zu debuggen. Es zeigt auch gut, wie Entwickler es gewohnt sind, über Anwendungen nachzudenken.
Hinter diesem Modell verbirgt sich jedoch eine Annahme, die den Kontakt mit der Realität nicht überlebt: dass die Hinrichtung von Agenten kurzlebig, isoliert und in sich abgeschlossen ist.
Sobald Agenten beginnen, mit anderen Agenten zu interagieren, wird diese Annahme zunichte gemacht. Ein Agent delegiert die Arbeit an einen anderen. Eine Folgeaktion wird später ausgelöst. Ein Aufruf eines Tools führt zu einer sekundären Entscheidung. Ausführungspfade verzweigen sich, verbinden sich wieder und werden manchmal ganz unterbrochen.
An diesem Punkt verhält sich das System nicht mehr wie eine Anwendungsfunktion und verhält sich wie ein verteiltes System, das aus autonomen Komponenten besteht.
Dieser Übergang ist subtil, aber entscheidend. Teams merken oft nicht, dass es passiert ist, bis etwas schief läuft.
Wenn Agentensysteme in der Produktion Probleme haben, sind die Ausfälle selten dramatisch. Das System stürzt nicht sofort ab. Stattdessen schwindet das Vertrauen langsam.
Eine Aktion wird ausgelöst, aber niemand ist sich sicher, warum.
Ein nachgeschalteter Agent wird ausgeführt, allerdings unter unklaren Berechtigungen.
Die Kosten steigen ohne ersichtlichen Grund.
Ein Arbeitsablauf stoppt auf halber Strecke, und es gibt keine klare Spur, die erklärt, wo oder warum.
Dies sind keine Argumentationsfehler. Der Agent hat angesichts der Informationen, die er hatte, möglicherweise eine absolut vernünftige Entscheidung getroffen. Das Problem ist, dass niemand zuverlässig erklären oder kontrollieren kann, was im gesamten System passiert ist.
Dies ist der Punkt, an dem viele Teams instinktiv versuchen, den Agenten selbst zu „reparieren“, indem sie Eingabeaufforderungen anpassen, Modelle austauschen oder mehr Logik hinzufügen. Diese Änderungen lösen jedoch selten die eigentliche Ursache, da das Problem nicht im Agenten selbst liegt.
Es lebt zwischen Agenten.
Wenn Intelligenz der wahre Blocker wäre, würden wir ein einfaches Muster erwarten: Bessere Modelle würden zu stabilen Produktionssystemen führen. Das ist nicht das, was wir sehen.
Stattdessen stellen wir fest, dass die Systeme um sie herum schwieriger zu verwalten sind, je leistungsfähiger die Agenten werden. Mehr Intelligenz führt zu mehr Autonomie, mehr Verzweigungsverhalten und mehr nachgelagerten Effekten. Ohne die richtige Infrastruktur erhöht diese zusätzliche Fähigkeit sogar das Risiko.
Die Agent-to-Agent-Wirtschaft verstärkt diesen Effekt. Wenn Agenten beginnen, andere Agenten anzurufen und in gemeinsam genutzten Tools und Umgebungen arbeiten, steigen die Kosten für fehlende Infrastruktur rasant an. Identität, Koordination, Durchsetzung von Richtlinien und Beobachtbarkeit sind keine fakultativen Belange mehr, sondern werden zu grundlegenden Anforderungen.
Hier wird eine Änderung der Denkweise notwendig. Agenten können nicht nur als ein weiteres Stück Anwendungslogik behandelt werden. In einem echten Agenten-Ökosystem sind Agenten langlebige Akteure, die an Arbeitsabläufen teilnehmen, Arbeit delegieren und unterschiedlichen Autoritäten unterstehen.
Plattformen wie Der Agenten-Hub von TrueFoundry spiegelt diesen Wandel wider. Anstatt davon auszugehen, dass es sich bei Agenten um private, eingebettete Logik handelt, behandelt Agent Hub sie als registrierte, auffindbare Komponenten mit expliziten Schnittstellen und Eigentümern. Agenten werden über eine gemeinsame Bedienoberfläche veröffentlicht, versioniert und aufgerufen, anstatt sich gegenseitig direkt über Ad-hoc-Codepfade aufzurufen.
Dieses Reframing macht die Agenten nicht intelligenter. Es macht das System um sie herum betriebsbereit.
Die Agent-to-Agent-Wirtschaft wartet nicht auf einen Durchbruch in der Argumentation. Sie wartet auf eine Infrastruktur, die Autonomie unterstützt, ohne die Kontrolle zu verlieren.
Der erste Schritt besteht darin, zu verstehen, wie sich Agentensysteme verändern, sobald sie in der Produktion sind, und warum traditionelle Ansätze scheitern. Von da an wird die Rolle von Steuerungsebenen, Gateways und expliziten Ausführungs-APIs unumgänglich. Hier beginnt die eigentliche Arbeit.
Bis ein Agentensystem die Produktion erreicht, haben die meisten Teams die offensichtlichen Probleme bereits gelöst.
Sie wissen, wie man Anfragen an einen LLM sendet.
Sie wissen, wie man Werkzeuge oder MCP-Server verkabelt.
Sie wissen, wie man einen Agenten anruft und eine Antwort zurückbekommt.
Diese Funktionen sind nicht mehr experimentell. Sie sind stabil, gut dokumentiert und leicht zu reproduzieren. Genau aus diesem Grund gewinnen Teams so schnell an Selbstvertrauen. Ein früher Erfolg erweckt den Eindruck, dass das System „größtenteils fertig“ ist.
In der Produktion zerbricht diese Illusion.
Was die Produktion wirklich tut, ist alles zu enthüllen, was Prototypen praktischerweise verbergen.
In einer Demo wird ein Agent normalerweise isoliert ausgeführt. Es bearbeitet eine einzelne Anfrage, führt eine kleine Anzahl von Aktionen aus und wird beendet. Es gibt einen Ausführungspfad und ein Ergebnis. Das Debuggen ist einfach, da der gesamte Kontext in den Kopf eines Entwicklers passt.
In der Produktion verhalten sich Agenten nicht so.
Sie laufen ununterbrochen.
Sie lösen Folgemaßnahmen aus.
Sie rufen andere Agenten an.
Sie arbeiten umgebungs-, team- und berechtigungsübergreifend.
Die Ausführung hört auf, eine einzelne Interaktion zu sein und wird zu einer Arbeitsablauf, oft eine, die sich im Laufe der Zeit entfaltet.
Hier beginnen Agentensysteme, verteilten Systemen zu ähneln, nicht weil sie Microservices oder Warteschlangen verwenden, sondern weil das Verhalten jetzt auf mehrere autonome Akteure verteilt ist.
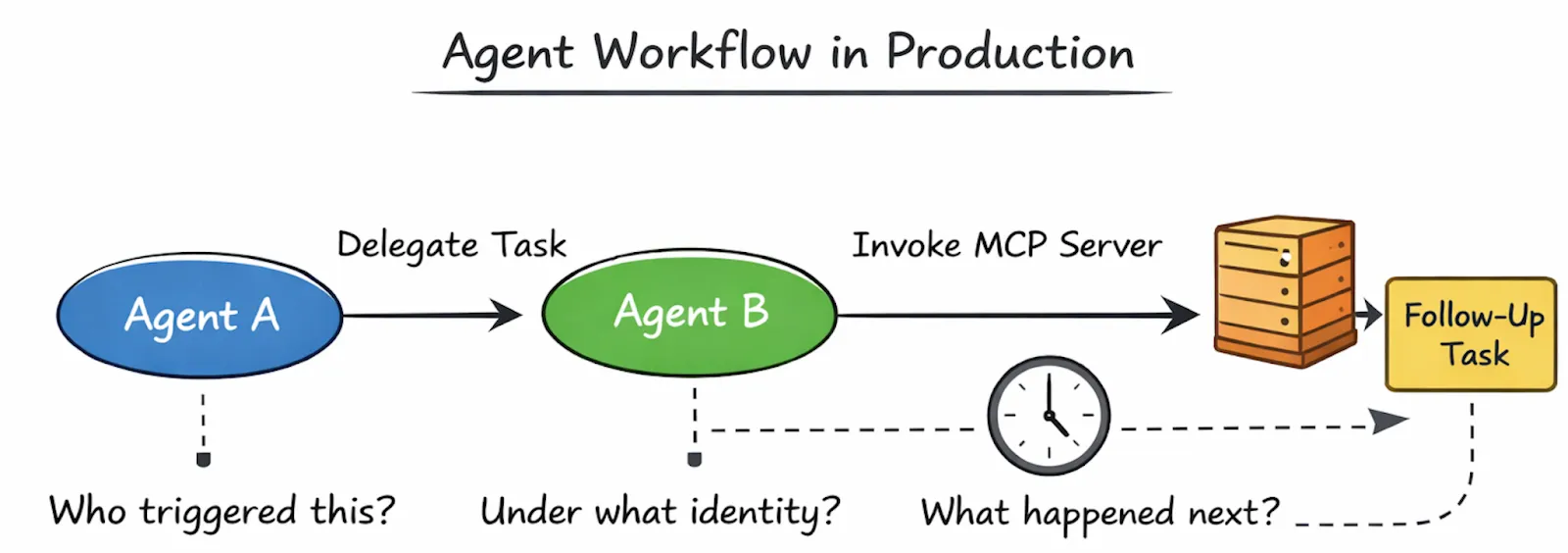
Wenn in der Produktion etwas schief geht, fragen die Teams nicht, ob der Agent „intelligent genug“ war. Stattdessen stellen sie Fragen, die jedem, der verteilte Systeme bedient hat, sehr bekannt vorkommen:
Was hat diese Aktion ausgelöst?
Welcher Agent hat die Entscheidung getroffen?
Unter welcher Identität lief es?
Warum fand die Hinrichtung hier statt?
Warum hat es ganz aufgehört?
Diese Fragen sind täuschend einfach und können ohne Infrastrukturunterstützung nicht zuverlässig beantwortet werden.
In den meisten frühen Agenten-Setups befindet sich der Ausführungskontext im Agenten selbst. Sobald ein Agent einen anderen Agenten anruft oder ein Tool aufruft, verschwindet dieser Kontext oft, es sei denn, jeder Entwickler verbreitet ihn sorgfältig. Mit der Zeit fragmentieren Protokolle, die Ablaufverfolgung wird unterbrochen und das System wird undurchsichtig.
Der Agent produziert vielleicht immer noch Ergebnisse, aber das System als Ganzes ist schwer zu verstehen.
Die natürliche Reaktion in diesem Stadium besteht darin, das Problem lokal zu beheben. Ein Team fügt die Protokollierung von Toolaufrufen hinzu. Ein anderes umhüllt Agenten mit Authentifizierungsprüfungen. Jemand fügt an einigen Stellen Wiederholungsversuche hinzu. Keine dieser Änderungen ist für sich genommen falsch.
Zusammengenommen bilden sie jedoch ein fragiles Netz aus Klebecode, in dem:
Dies ist der Punkt, an dem sich Teams langsam ausgebremst fühlen, nicht weil die Agenten nicht mehr tun können, sondern weil Änderungen unbeabsichtigte Folgen haben.
Was sich hier abzeichnet, ob die Teams es erkennen oder nicht, ist eine Kontrollebene. Es ist einfach zufällig und schlecht definiert.
Hier kommen Plattformen wie Wahre Gießerei ziehen Sie eine klare Grenze zwischen Agentenlogik und Systemverantwortung.
Mit dem Agenten-Hub, Agenten werden nicht mehr implizit durch lokale Funktionsaufrufen oder versteckte Abhängigkeiten aufgerufen. Sie werden über eine gemeinsame Schnittstelle registriert, auffindbar und ausgeführt. Mit dem Agenten-API, die Agentenausführung wird explizit, kontextabhängig und beobachtbar.
Anstatt dass ein Agent leise einen anderen Agenten anruft, wird die Ausführung als verwalteter Vorgang angezeigt.
# Using TrueFoundry's Agent API with registered MCP servers
import httpx
response = httpx.post(
"https://{controlPlaneURL}/api/llm/agent/chat/completions",
headers={
"Authorization": "Bearer {TFY_API_TOKEN}",
"Content-Type": "application/json"
},
json={
"model": "openai/gpt-4o",
"messages": [{"role": "user", "content": "Evaluate risk for transaction txn_123"}],
"mcp_servers": [{"integration_fqn": "common-tools", "tools": [{"name": "web_search"}, {"name": "sequential_thinking"}]}],
"stream": True
}
)# Connecting to MCP server through TrueFoundry Gateway
from fastmcp import Client
from fastmcp.client.transports import StreamableHttpTransport
async def main():
url = "https://{controlPlaneURL}/api/llm/mcp/common-tools/server"
transport = StreamableHttpTransport(
url=url,
auth="<tfy-api-token>",
)
async with Client(transport=transport) as client:
tools = await client.list_tools()
result = await client.call_tool("web_search", {"query": "What is Python?"})
return result
Hinweis: Der Agent Hub-API-Vertrag befindet sich derzeit in der aktiven Entwicklung. Die neueste Syntax und die neuesten Funktionen finden Sie in der Agenten-API-Dokumentation.
Das mag wie eine kleine Änderung aussehen, hat aber erhebliche Konsequenzen. Die Identität wird zusammen mit der Anfrage übertragen. Die Grenzen der Ausführung sind klar. Nachgelagerte Aktionen können bis zu ihrem Ursprung zurückverfolgt werden. Richtlinien können evaluiert werden, bevor der Agent ausgeführt wird, nicht nachdem etwas schief gelaufen ist.
Der Agent begründet immer noch und entscheidet, was zu tun ist. Die Plattform kümmert sich darum, wie diese Entscheidung sicher ausgeführt wird.
Sobald die Agenten die Produktion erreichen, geht es bei den schwierigen Problemen nicht mehr um Intelligenz. Es geht um Koordination, Identität, Sichtbarkeit und Kontrolle. Diese Bedenken gehören nicht in den Agentencode, da sie für alle Agenten, Workflows und Teams gelten.
Aus diesem Grund greifen viele Teams als Nächstes nach einer Abkürzung: Sie stellen ihren Agenten einen Router vor die Nase und hoffen, dass das ausreicht.
Das ist selten so.
Zu verstehen, warum dieser Ansatz scheitert, ist der nächste Schritt, um zu verstehen, wie eine echte Agenteninfrastruktur aussehen muss.
Sobald Teams erkennen, dass ihr Agentensystem immer schwieriger zu verwalten ist, ist der erste Instinkt in der Regel pragmatisch: Fügen Sie einen Router vor den Agenten hinzu.
Dieser Ansatz fühlt sich vertraut an. API-Gateways und Router sind gut verstanden. Sie haben für Microservices funktioniert. Warum also nicht dasselbe Muster für Agenten wiederverwenden? Stellen Sie eine Routing-Ebene in den Vordergrund, entscheiden Sie, welchen Agenten Sie anrufen möchten, und fahren Sie fort.
Für eine kurze Zeit funktioniert das. Dann beginnt sich das System auf eine Weise zu verbiegen, für die der Router nie konzipiert war.
Router sind für eine ganz bestimmte Welt gebaut. Sie gehen davon aus, dass Anfragen nur von kurzer Dauer sind, die Ausführungspfade größtenteils linear sind und die Identität entweder einheitlich ist oder erst am Netzwerkrand geklärt ist. Sie leiten den Verkehr effizient weiter, aber sie verstehen die Absicht nicht.
Agent-zu-Agent-Systeme verstoßen fast sofort gegen diese Annahmen.
Agenten antworten nicht nur auf Anfragen. Sie leiten Aktionen ein, delegieren Arbeit an andere Agenten und lösen Nebenwirkungen aus, die sich im Laufe der Zeit entfalten. Eine einzige Entscheidung kann zu mehreren nachgelagerten Ausführungen führen, von denen einige sofort, andere verzögert ausgeführt werden. Identität ist nicht mehr nur ein einziger Header, sondern etwas, das bewahrt und überlegt werden muss.
Ein Router kann eine Anfrage weiterleiten. Das kann es nicht erklären warum diese Anfrage existiert.
Mit dem Wachstum der Agentensysteme beginnen die Teams, mehr Verantwortung in den Router zu verlagern. Authentifizierungsregeln werden hinzugefügt. Die Modellauswahl wird in Routen kodiert. Richtlinienprüfungen sind in der Routing-Logik fest codiert. Der Kontext wird mithilfe von Überschriften und Konventionen zusammengefügt.
Nichts davon fühlt sich isoliert falsch an. Aber im Laufe der Zeit wird der Router zu einer Müllhalde für Bedenken, für die er nicht gedacht war. Es wird zu einer spröden Engstelle, an der:
Ironischerweise wird der Router, der das System vereinfachen sollte, zu dem Ding, das alle verlangsamt.
Das tiefere Problem ist, dass Agentensysteme nicht nur ein Verkehrsmanagement benötigen. Sie brauchen Verwaltung.
Sicherheits- und Compliance-Teams fragen nicht, welche Route eingeschlagen wurde. Sie fragen, wer auf was zugegriffen hat, unter welcher Autorität und warum. Produktteams wollen nicht nur wissen, wohin eine Anfrage gegangen ist, sie wollen auch verstehen, wie sich eine Entscheidung auf die Agenten und Tools ausgewirkt hat. Die Bediener müssen sehen, wie sich Kosten und Verhalten im gesamten Arbeitsablauf entwickeln, nicht nur am Netzwerkrand.
Diese Fragen können nicht allein durch Routing beantwortet werden, da sie von Absicht, Delegation und abgeleiteten Aktionen abhängen. Diese Konzepte sind in einem Router nicht selbstverständlich.
Hier wird der Unterschied zwischen einem Router und einer Steuerungsebene deutlich.
Mit Der Agenten-Hub von TrueFoundry, Agenten sind keine anonymen Endpunkte hinter einer Routing-Tabelle. Sie sind benannte, registrierte Entitäten mit expliziten Schnittstellen und Eigentümern. Wenn ein Agent einen anderen aufruft, geschieht dies über eine verwaltete Ausführungsebene und nicht über einen undurchsichtigen Netzwerk-Hop.
Das Agenten-API verstärkt diese Trennung. Die Ausführung ist nicht hinter einer Route versteckt; es handelt sich um einen expliziten Vorgang, bei dem Identität, Metadaten und Richtlinien-Evaluierung integriert sind. Das Gateway setzt Regeln konsistent durch und wahrt gleichzeitig den Kontext bei Interaktionen zwischen Agenten.
Dies beeinträchtigt nicht die Flexibilität. Es stellt sie wieder her. Indem sich das Routing auf den Verkehr konzentriert und die Steuerung in eine dedizierte Infrastruktur verlagert wird, können Teams das Verhalten der Agenten weiterentwickeln, ohne ihre Routing-Ebene in einen fragilen Monolithen zu verwandeln.
„Nur ein Router“ versagt nicht, weil er schlecht implementiert ist, sondern weil er das falsche Problem löst. Agent-to-Agent-Systeme sind keine Anforderungsrouter mit intelligenteren Endpunkten. Sie sind verteilte Systeme mit autonomem Verhalten.
Sobald die Teams das akzeptieren, folgt natürlich die nächste Erkenntnis: Agentensysteme verhalten sich wie verteilte Systeme, aber mit höheren Einsätzen.
Bis die Teams erkennen, dass ein Router nicht ausreicht, zeichnet sich in der Regel von selbst ein anderes Muster ab. Kleine Teile der Koordinationslogik tauchen überall auf. Ein Agent führt vor dem Aufrufen eines Tools Berechtigungsprüfungen durch. Ein anderer bettet beim Aufrufen eines Downstream-Agenten eine Wiederholungslogik ein. Ein drittes Team fügt eine benutzerdefinierte Protokollierung hinzu, um zu verfolgen, was nach dem Auslösen einer Aktion passiert ist.
Keine dieser Änderungen ist falsch. Tatsächlich sind sie praktische Antworten auf echte Probleme. Aber zusammengenommen weisen sie auf etwas Tieferes hin: Dem System fehlt eine Steuerungsebene.
Bei einer Kontrollebene geht es nicht darum, die Arbeit zu erledigen. Es geht darum, zu entscheiden wie Arbeit darf passieren.
In einem Agent-zu-Agent-System gibt es Fragen, die einfach nicht in die Agentenlogik gehören:
Wer darf diesen Agenten aufrufen?
Unter welchen Bedingungen?
Mit welchen Tools oder MCP-Servern?
Mit welchem Grad an Sichtbarkeit und Überprüfbarkeit?
Wenn diese Entscheidungen direkt in den Mitarbeitern verankert sind, werden sie doppelt getroffen und ändern sich im Laufe der Zeit. Zwei Agenten, die sich auf die gleiche Weise verhalten sollten, weichen langsam voneinander ab. Richtlinien werden inkonsistent durchgesetzt. Das Debuggen wird zum Rätselraten, da kein einziger Ort widerspiegelt, wie das System tatsächlich gesteuert wird.
Das ist genau das Problem Der Agenten-Hub von TrueFoundry wurde entwickelt, um zu lösen.
Agent Hub behandelt Agenten nicht als private Implementierungsdetails, sondern als registrierte, auffindbare Entitäten innerhalb eines gemeinsamen Systems. Es bietet unter anderem folgende Funktionen:
Jeder Agent wird mit einer klaren Oberfläche, Verantwortlichkeit und Ausführungsgrenze veröffentlicht. Andere Agenten „greifen“ nicht über Ad-hoc-Codepfade darauf zu. Sie rufen es explizit auf.
Dies verändert die Art der Interaktionen zwischen Agenten. Statt versteckter Abhängigkeiten werden Beziehungen sichtbar. Anstelle von implizitem Vertrauen erfolgt die Ausführung über eine verwaltete Ebene.
Eine nützliche Methode, dies zu visualisieren, besteht darin, Agent Hub in der Mitte des Systems zu platzieren:
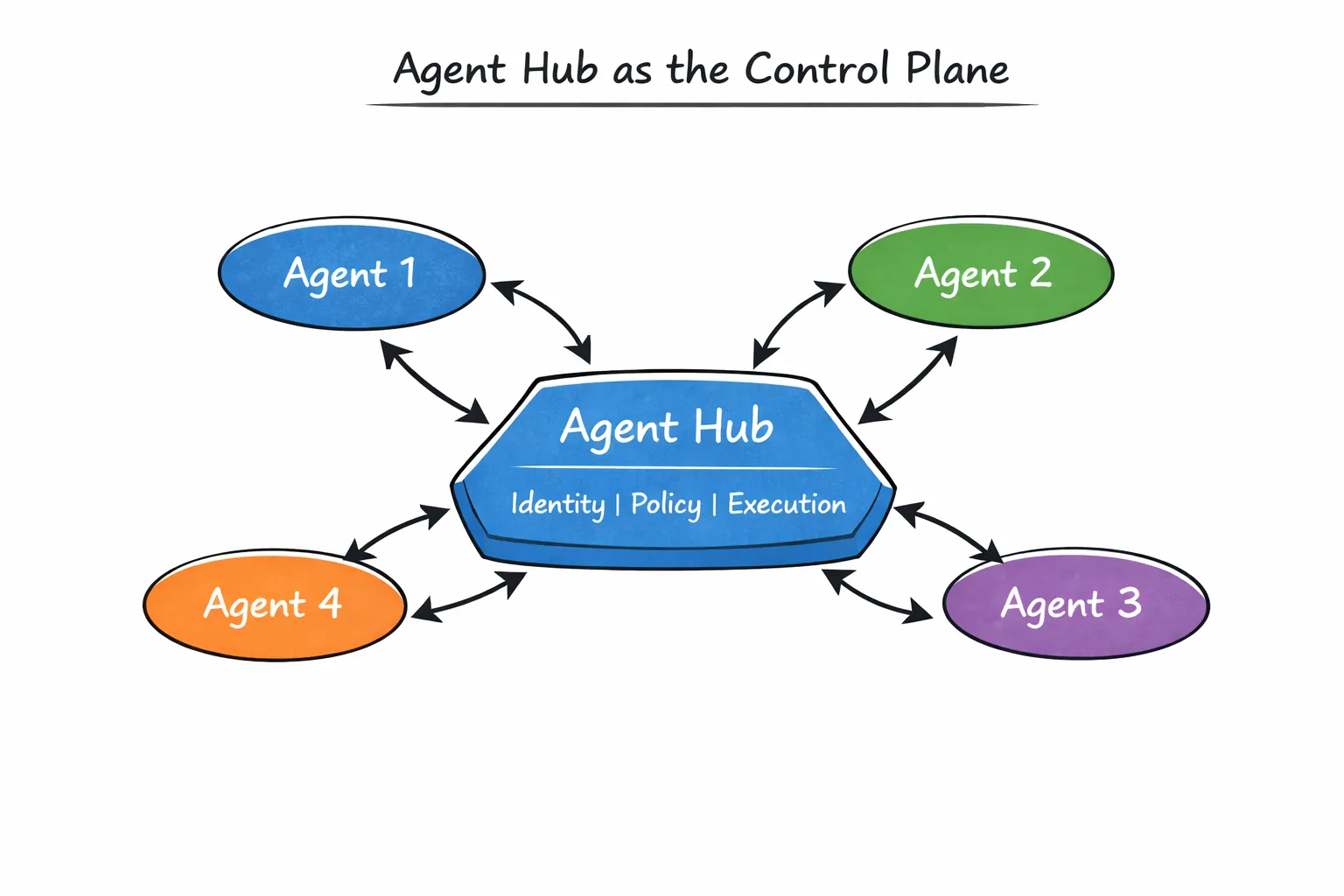
Wenn Systeme wachsen, bleiben Arbeitsabläufe selten einfach. Ein Agent könnte sich auf das Abrufen spezialisieren, ein anderer auf die Bewertung, ein anderer auf die Entscheidungsfindung. Diese Agenten ersetzen sich nicht gegenseitig; sie arbeiten zusammen.
Agent Hub unterstützt dies ausdrücklich durch Subagenten und Workflows mit mehreren Agenten. Anstatt die Orchestrierungslogik innerhalb eines einzelnen „Mega-Agenten“ fest zu programmieren, können Teams Workflows zusammenstellen, indem sie Agenten auf kontrollierte Weise miteinander verketten.
Dies hat zwei wichtige Auswirkungen. Erstens sorgt es dafür, dass die einzelnen Agenten konzentriert und verständlich bleiben. Zweitens zentralisiert es die Koordinationslogik, sodass Änderungen an der Art und Weise, wie Agenten interagieren, nicht dazu führen, dass alle beteiligten Agenten neu geschrieben werden müssen.
Das System lässt sich leichter weiterentwickeln, nicht schwieriger.
Ein weiterer unscheinbarer Vorteil einer zentralen Steuerungsebene ist die Sichtbarkeit. In vielen Organisationen vermehren sich Agenten schneller als die Unternehmensleitung. Teams erstellen, was sie benötigen, kopieren Anmeldeinformationen und setzen Agenten ein, wo immer sie können. Im Laufe der Zeit ist sich niemand ganz sicher, wie viele Agenten es gibt, auf welche Daten sie zugreifen oder wem sie gehören.
Agent Hub bietet eine gemeinsame Oberfläche, auf der Agenten registriert und erkannt werden. Das bremst Teams nicht aus; es gibt ihnen eine sichere Standardeinstellung. Wenn der offizielle Weg einfach und einsehbar ist, gibt es weit weniger Anreize, Agenten im Schatten zu bauen.
Es ist wichtig, sich darüber im Klaren zu sein, was eine Kontrollebene nicht ist. Es ist kein Ort, an dem alle Logik lebt, und es ist kein Engpass, den Teams bei jeder Änderung aushandeln müssen. Agent Hub sagt den Agenten nicht, was sie denken sollen. Es definiert, wie Agenten am System teilnehmen.
Agenten argumentieren immer noch unabhängig. Die Teams versenden immer noch schnell. Aber die Regeln für Engagement, Identität, Aufruf und Koordination werden im gesamten Ökosystem einheitlich gehandhabt.
Diese Trennung macht Wirkstoffsysteme nachhaltig, wenn sie wachsen.
Sobald eine Kontrollebene existiert, wird das letzte Puzzleteil offensichtlich: Die Ausführung muss zur Laufzeit erzwungen und beobachtet werden. An dieser Stelle kommen Gateways und explizite Agenten-APIs ins Spiel, und das werden wir uns als Nächstes ansehen.
Sobald eine Kontrollebene existiert, wird eine Frage unvermeidlich: wo wird diese Kontrolle tatsächlich durchgesetzt?
In Agentensystemen spielen Entscheidungen über Identität, Richtlinien und Routing keine Rolle, es sei denn, sie werden zur Laufzeit angewendet, genau in dem Moment, in dem ein Agent versucht zu handeln. An dieser Stelle werden Gateways und explizite Agenten-APIs entscheidend. Ohne sie ist eine Kontrollebene nur beratend. Mit ihnen wird es real.
Einer der häufigsten Fehlermodi in Agentensystemen ist die unsichtbare Ausführung. Ein Agent ruft einen anderen Agenten als lokale Funktion auf. Dieser Agent ruft ein Tool auf. Eine Nebenwirkung tritt auf. Alles „funktioniert“, aber niemand kann klar erkennen, was passiert ist oder warum.
Das Problem ist nicht, dass die Ausführung falsch ist. Es ist nur so, dass es versteckt ist.
True Foundry's Agenten-API erzwingt die explizite Hinrichtung von Agenten. Anstatt impliziter Aufrufe, die im Code verborgen sind, werden Agenteninteraktionen zu erstklassigen Operationen. Jeder Aufruf beinhaltet Identität, Kontext und Absicht und durchläuft jedes Mal dieselbe Infrastruktur.
# TrueFoundry Agent API - explicit, governed agent execution
import httpx
response = httpx.post(
"https://{controlPlaneURL}/api/llm/agent/chat/completions",
headers={
"Authorization": "Bearer {TFY_API_TOKEN}",
"Content-Type": "application/json"
},
json={
"model": "openai/gpt-4o",
"messages": [{"role": "user", "content": "Search for information about Python"}],
"mcp_servers": [
{"integration_fqn": "common-tools", "tools": [{"name": "web_search"}]}
]
}
)Hinweis: Der Agent Hub-API-Vertrag befindet sich derzeit in der aktiven Entwicklung. Die neueste Syntax und die neuesten Funktionen finden Sie in der Agenten-API-Dokumentation.
Dieser Aufruf mag einfach aussehen, stellt aber einen großen architektonischen Wandel dar. Der Agent agiert nicht mehr isoliert. Seine Ausführung wird vermittelt, verfolgt und gesteuert.
In herkömmlichen Systemen werden Gateways oft als Verkehrsrouter behandelt. In Agentensystemen ist dieser Rahmen zu eng gefasst. Gateways leiten nicht nur Anfragen weiter, sie sind Durchsetzung der Absicht.
Das AI Gateway von TrueFoundry befindet sich zwischen Agenten, Modellen und MCP-Servern. Jede Agentenausführung durchläuft es. Auf diese Weise kann das System Richtlinien evaluieren, bevor etwas passiert: ob ein Agent ausgeführt werden darf, auf welche Tools er zugreifen kann, welches Modell er verwenden sollte und was protokolliert oder eingeschränkt werden muss.
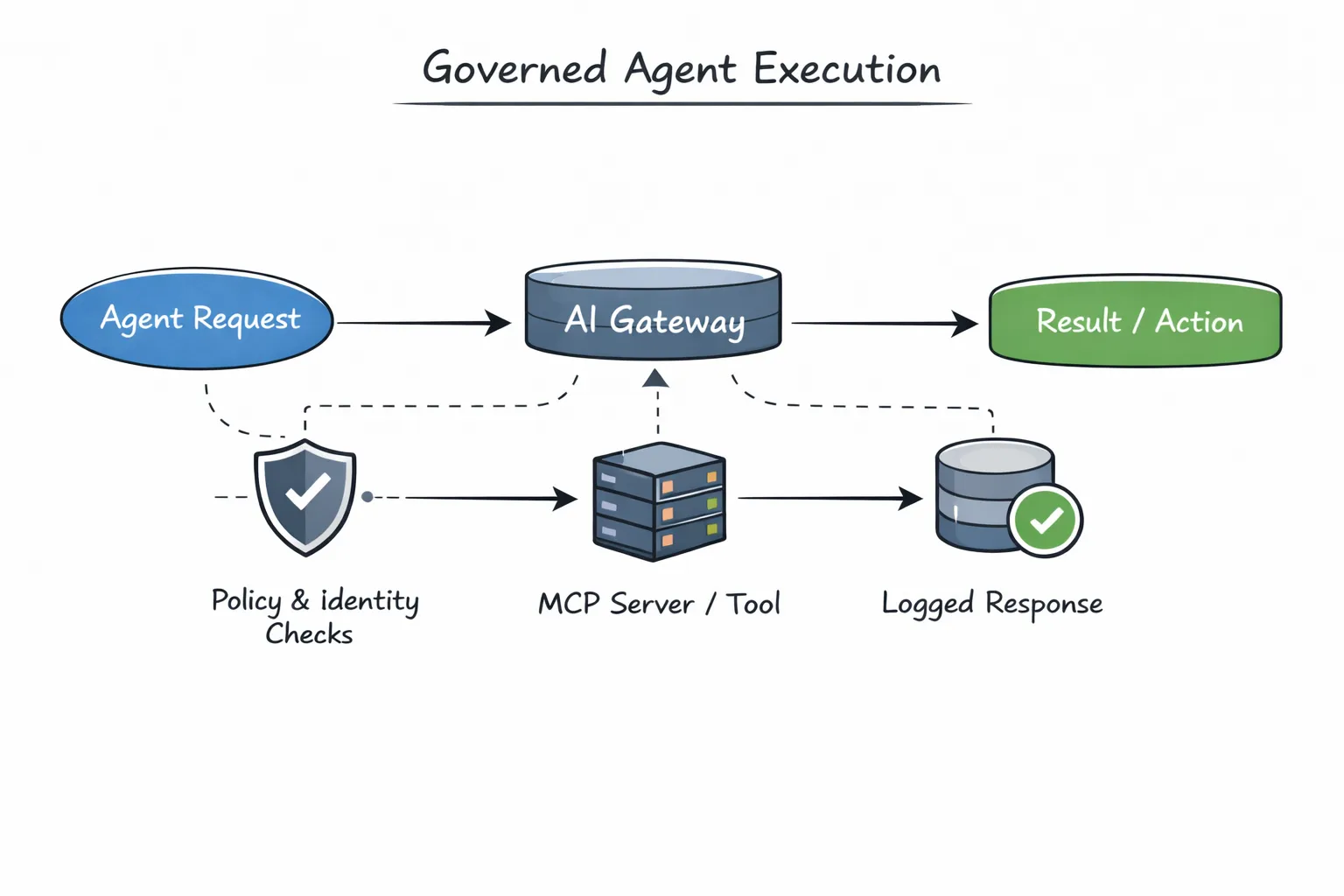
Da die gesamte Ausführung über ein gemeinsames Gateway erfolgt, ist die Durchsetzung standardmäßig konsistent. Es ist nicht erforderlich, dass jeder Agent Zugriffsprüfungen, Wiederholungsversuche oder Protokollierung erneut implementieren muss. Diese Bedenken befinden sich dort, wo sie hingehören, außerhalb der Agentenlogik.
Beim Zugriff auf Tools werden Agentensysteme oft gefährlich. Tools können Daten schreiben, externe Systeme auslösen oder irreversible Aktionen ausführen. Wenn Agenten Tools direkt aufrufen, werden Anmeldeinformationen und Zugriffslogik häufig kopiert, was zu Sicherheits- und Compliance-Risiken führt.
Die Agent-API integriert MCP-Server über das Gateway, was bedeutet, dass Tools unter kontrollierten Bedingungen aufgerufen werden. Unabhängig davon, ob ein MCP-Server auf der Plattform registriert ist oder extern bereitgestellt wird, wird der Zugriff vermittelt, authentifiziert und ist beobachtbar. Agenten erhalten die Funktionen, die sie benötigen, ohne dass sie Geheimnisse für sich behalten oder Richtlinien umgehen müssen.
Dies ist besonders wichtig in Workflows von Agent zu Agent, bei denen die Entscheidung eines Agenten in mehrere nachgelagerte Tool-Aufrufe münden kann.
Ein weiterer Vorteil der expliziten Ausführung ist die Sichtbarkeit. Da Agentenaufrufe über eine gemeinsame API und ein gemeinsames Gateway erfolgen, wird es möglich, das Verhalten von Anfang bis Ende zu verfolgen. Die Teams können sehen, welcher Agent eine Aktion initiiert hat, welche nachgelagerten Agenten und Tools daran beteiligt waren, wie lange die Ausführung gedauert hat und wo sich die Kosten angesammelt haben.
In Agentensystemen sind die Kosten nicht nur ein Fakturierungsproblem, sondern ein Verhaltenssignal. Eine kleine Änderung der Argumentation kann zu vielen Anrufen führen. Ohne Beobachtbarkeit verlieren Teams die Fähigkeit, diese Verstärkung zu verstehen oder zu kontrollieren.
Die explizite Ausführung stellt dieses Verständnis wieder her.
Das Ziel von Agenten-APIs und Gateways besteht nicht darin, die Möglichkeiten der Agenten einzuschränken. Es geht darum, autonomes Verhalten zu entwickeln bedienbar.
Agenten argumentieren immer noch unabhängig. Sie arbeiten immer noch zusammen und delegieren. Aber sie tun dies innerhalb eines Systems, das Regeln durchsetzen, Ergebnisse erklären und sich im Laufe der Zeit sicher weiterentwickeln kann.
An diesem Punkt wird das Kernmuster klar. Systeme von Agent zu Agent skalieren nicht allein anhand von Intelligenz. Sie skalieren, wenn Autonomie mit einer Infrastruktur kombiniert wird, die sie steuern kann.
Das bringt uns zur letzten Frage: Was bestimmt eigentlich den langfristigen Erfolg in einer Agent-to-Agent-Wirtschaft?
Da sich die Fähigkeiten der Agenten weiter verbessern, wird die Intelligenz zum uninteressantesten Teil des Systems werden. Bessere Modelle werden leichter zugänglich sein. Aufforderungstechniken werden sich schnell verbreiten. Was sich heute als fortgeschritten anfühlt, wird morgen zur Grundvoraussetzung.
Das eigentliche Unterscheidungsmerkmal wird nicht darin bestehen, wie intelligent die einzelnen Agenten sind. Es wird darum gehen, ob die Systeme um sie herum Autonomie unterstützen können, ohne die Kontrolle zu verlieren.
Die Wirtschaft von Agent zu Agent führt zu einer neuen Klasse von Komplexität. Entscheidungen breiten sich zwischen den Akteuren aus. Aktionen lösen nachgelagerte Effekte aus. Kosten und Risiken nehmen schneller zu, als Menschen eingreifen können. Ohne Infrastruktur werden diese Systeme undurchsichtig, fragil und es ist schwer, ihnen zu vertrauen.
Was Agentensysteme nachhaltig macht, ist nicht mehr Logik in den Agenten, sondern klare Trennung der Belange:
Hier kommt es auf Plattformen an.
Der Agent Hub und die Agent API von TrueFoundry versuchen nicht, Agenten intelligenter zu machen. Sie bieten die fehlende Infrastrukturebene, die es Agentensystemen ermöglicht, sich wie gut verwaltete verteilte Systeme zu verhalten und nicht wie unvorhersehbare Ansammlungen von Skripten. Agenten werden auffindbar, zusammensetzbar und funktionsfähig. Autonomie wird zu etwas, dem Teams vertrauen können.
Die Agent-to-Agent-Wirtschaft lässt sich nicht durch Punktlösungen oder clevere Demos gewinnen. Sie wird auf Plattformen basieren, die Autonomie in großem Maßstab zuverlässig machen. Die Intelligenz wird sich standardisieren. Die Infrastruktur wird sich differenzieren.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




