

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
In vielen Fällen entwickeln Teams Eingabeaufforderungen in einem entspannte Art, ähnlich wie beim Schreiben informeller E-Mails. Dies ist ein natürlicher Prozess, über den nicht viel nachgedacht wird Strukturelemente. Dieser entspannte Ansatz ist angemessen für explorative Entwicklung oder sogar schnelle Entwicklung eines Prototyps.
Aber wenn man anfängt, eine Funktion zu verwenden, die auf einem Large Language Model basiert vor tatsächlichen Benutzern, Eingabeaufforderungen werden zu einem kritischer Aspekt. Wenn Aufforderungen nicht gut konzipiert sind, kann dies zu Fehlern führen, und die Antworten sind möglicherweise nicht konsistent, wichtige Informationen sind möglicherweise nicht enthalten und die Antworten sind möglicherweise nicht zuverlässig.
Darüber hinaus Debugging ist unerwartet komplex wenn ein Problem auftritt. Oft muss man herausfinden, ob das Problem mit dem zusammenhängt Modell, die Eingabe oder sogar die Eingabeaufforderung.
In diesem Beitrag wird der genaue Prozess beschrieben, den wir entwickelt haben, um Eingabeaufforderungen von „wahrscheinlich gut genug“ auf „definitiv gut genug für die Produktion“ zu übertragen. Dabei werden echte Kriterien, echte Bewertungsdatensätze und echte Benchmarks für mehrere Modelle verwendet. Keine Zauberei. Nur strukturierte Technik, angewendet auf Eingabeaufforderungen.
Wenn die meisten Leute an eine Aufforderung denken, denken sie an eine einfache Anfrage wie „Dieses Dokument zusammenfassen“ oder „Entitäten aus diesem Text extrahieren“. Aber in der realen Welt ist eine Aufforderung so viel mehr als das. Sie ist die grundlegende Schnittstelle zwischen Ihrem Programm und dem Verhalten des Modells. Ein guter Prompt erstellt die Persona für das Model, die Einsatzregeln, das Ausgabeformat und das Unerwartete.
Das Problem mit Eingabeaufforderungen ist, dass sie nicht gründlich getestet wurden. Sie werden entworfen, implementiert und dann einfach überprüft, ob sie funktionieren. Sie nehmen hier eine Änderung vor und fügen dort eine Regel hinzu. Dann hoffst du einfach, dass es okay ist. Manchmal funktioniert es. Normalerweise tut es das nicht. Wenn es fehlschlägt, tut es das einfach nicht. Vielleicht merkst du es nicht einmal.
Eine gute Aufforderung ist nicht nur klar, sondern auch strukturiert. Stellen Sie sich das wie einen API-Vertrag zwischen Ihnen und dem Modell vor. Es sollte definieren:
Wenn all dies vorhanden ist, verfügt das Modell über alles, was es benötigt, um für alle Eingaben und sogar für verschiedene Modellversionen konsistent, zuverlässig und vorhersehbar zu sein.

Folgendes haben wir bei schlechten Eingabeaufforderungen bei realen Bereitstellungen beobachtet:
Ausgaben, die richtig aussehen, es aber nicht sind : Das Modell gibt eine Antwort aus, die aussieht, als hätte sie das richtige Format, weist jedoch subtile Fehler auf, da die Spezifikation nicht klar war.
Modellübergreifende Fehler : Die Eingabeaufforderung funktioniert für GPT-4, hat aber inkonsistente Antworten für Claude- und OSS-Modelle. Niemand hat sie vor der Bereitstellung modellübergreifend getestet.
Stille Regressionen : Wenn Sie ein Wort ändern, um ein Problem zu beheben, treten drei weitere Probleme auf, die niemand bemerkt hat, bis sich jemand beschwert.
Das Problem ist immer dasselbe: Niemand hat die Aufforderung als etwas behandelt, das getestet und validiert werden muss. Wir haben diesen Prozess entwickelt, um das zu beheben.
Der Workflow besteht aus fünf Schritten. Jeder baut auf dem vorherigen auf. Wenn Sie einen überspringen, werden die Ergebnisse schnell unzuverlässig. So funktioniert es von Ende zu Ende.
Bevor wir also Änderungen vornehmen, möchten wir wissen, was kaputt ist. Wir verwenden eine strukturierte Evaluierungsengine, die bei jeder Aufforderung ausgeführt wird, sie anhand von fünf verschiedenen Dimensionen bewertet und eine Gesamtqualitätsbewertung im Bereich von 0 bis 100 liefert.
Wir verwenden kein subjektives Scoring. Wir haben klare Kriterien für alle Dimensionen. Wir haben strenge Einschränkungen. Wenn die Eingabeaufforderung beispielsweise keine Ausgabespezifikation enthält, gibt es einen maximalen Wert für die Ausgabespezifikation. Die Punktzahl kann hoch sein, auch wenn die Anweisungen in der Aufforderung gut geschrieben sind. Wenn die Punktzahl unter 75 liegt, ist es noch nicht produktionsbereit. Wenn es über 90 liegt, ist es in allen Dimensionen solide.
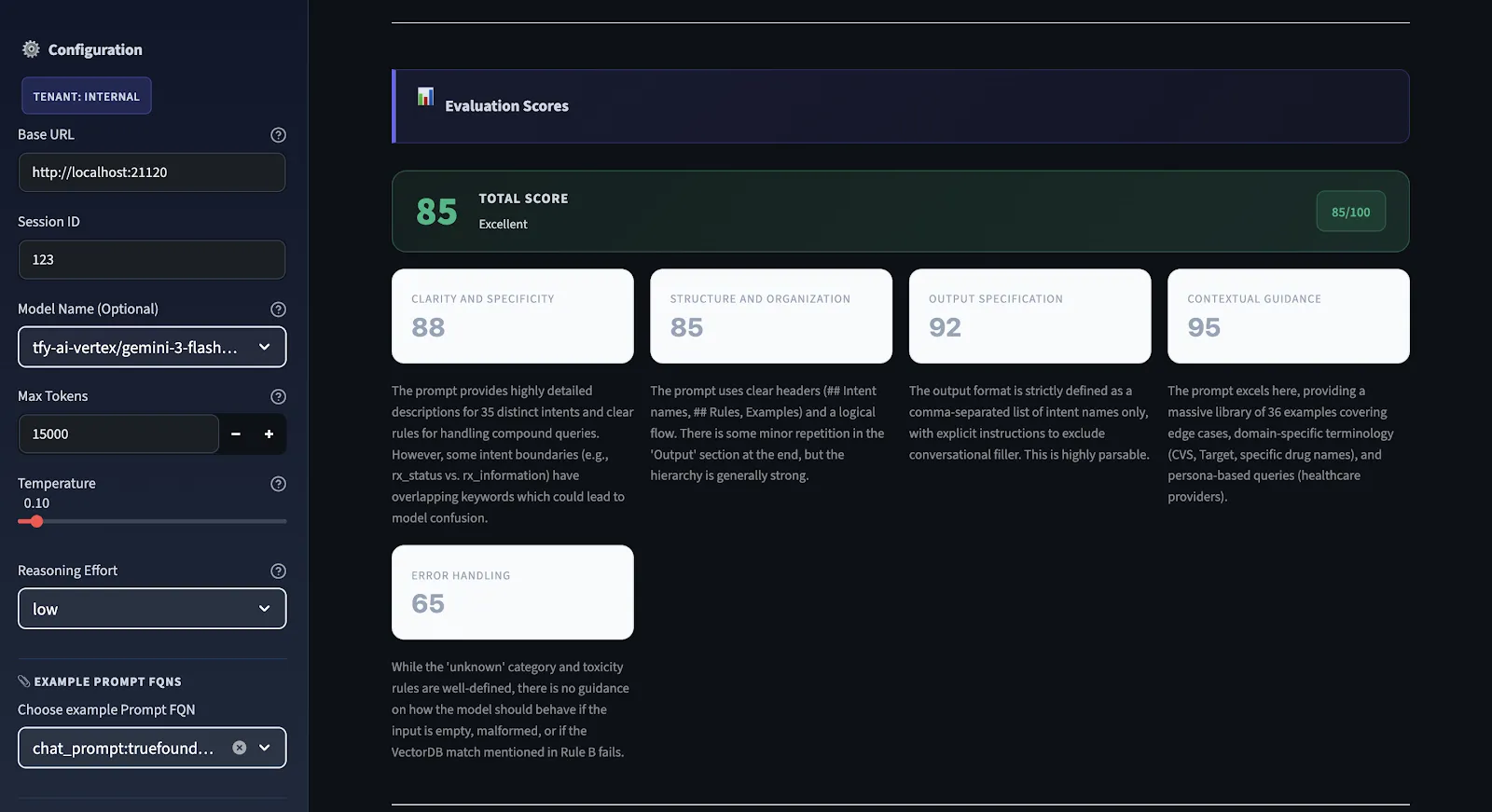
Dies ist die Diagnose-Engine des Workflows. Jede Aufforderung wird anhand von fünf spezifischen Kriterien mit 0—100 bewertet. Die Gesamtpunktzahl ist das arithmetische Mittel aller fünf Punkte. Hier ist, was jeder misst und warum es wichtig ist:
Sind die Anweisungen klar genug, dass zwei verschiedene Modelle sie genau auf die gleiche Weise verstehen? Vage Anweisungen führen mehr als jeder andere einzelne Faktor zu Inkonsistenzen. Wenn Sie sich nicht sicher sind, wie ein Mensch Ihre Aufforderung interpretieren könnte, sind Sie sich wahrscheinlich nicht sicher, wie ein Modell sie interpretieren wird. Wenn es mehr als eine Art gibt, wie ein Mensch sie interpretieren könnte, gibt es mehrere Möglichkeiten, wie ein Modell sie richtig oder falsch interpretieren könnte.
Folgt die Eingabeaufforderung logisch aus Kontext → Anweisungen → Einschränkungen → Ausgabeformat? Eine unorganisierte Aufforderung zwingt das Modell dazu, herauszufinden, worauf es ankommt und in welcher Reihenfolge. Eine gute Struktur erleichtert die Arbeit des Modells und macht Ihre Ergebnisse zuverlässiger.
Sind das erwartete Ausgabeformat, die Struktur und die Länge genau definiert? Wenn die Ausgabe von einem nachfolgenden Parser analysiert werden muss, gibt es dann keine Unklarheiten darüber, wie die Ausgabe aussehen wird? Dies überprüft die häufigste Fehlerbedingung: Ausgaben, die richtig aussehen, aber nicht analysiert werden können.
Bietet diese Aufforderung dem Modell ausreichend Kontext, um ohne Annahmen ausgeführt werden zu können? Modelle, die Annahmen treffen müssen, gehen immer von falschen Annahmen aus. Kontexte wie Fachterminologie, Grenzinformationen und Kontext werden diese Art von Fehlern vollständig ausschließen.
Sind Randfälle abgedeckt? Gibt diese Aufforderung an, was in Fällen zu tun ist, in denen die Eingabe mehrdeutig, unvollständig oder außerhalb der Grenzen ist? Diese Option wird am häufigsten übersehen und verursacht die meisten produktionsbezogenen Probleme. Halluzinationen, unerwartete Eingabeformate, fehlende Informationen — all das muss in dieser Aufforderung behandelt werden.
Bewertungsskala: 90—100 ist produktionsbereit. 75—89 weist Lücken auf, ist aber funktionsfähig. 50—74 funktioniert, ist aber unzuverlässig. Ein Wert unter 50 bedeutet erhebliche strukturelle Probleme, die vor dem Versand behoben werden müssen.
Wir haben die Ergebnisse und Erklärungen für jedes Kriterium. Als Nächstes erstellen wir eine konkrete Version der verbesserten Aufforderung. Die Empfehlungen sind nicht nur abstrakte Ideen. Sie entsprechen tatsächlichen Änderungen an der Struktur der Aufforderung. Zu diesen Änderungen gehören das Hinzufügen fehlender Ausgabespezifikationen, die Präzisierung unklarer Anweisungen, die Trennung von inhaltlichen und formatbezogenen Problemen und die explizite Festlegung von Fallbacks für Randfälle.
Die wichtigste Einschränkung, die wir auferlegen, ist die Wahrung der Absicht. Mit anderen Worten, wir schreiben die Aufforderung nicht neu. Vielmehr füllen wir die Lücken, die in der Bewertung aufgezeigt wurden, und behalten gleichzeitig die ursprüngliche Absicht und den ursprünglichen Bereich bei.
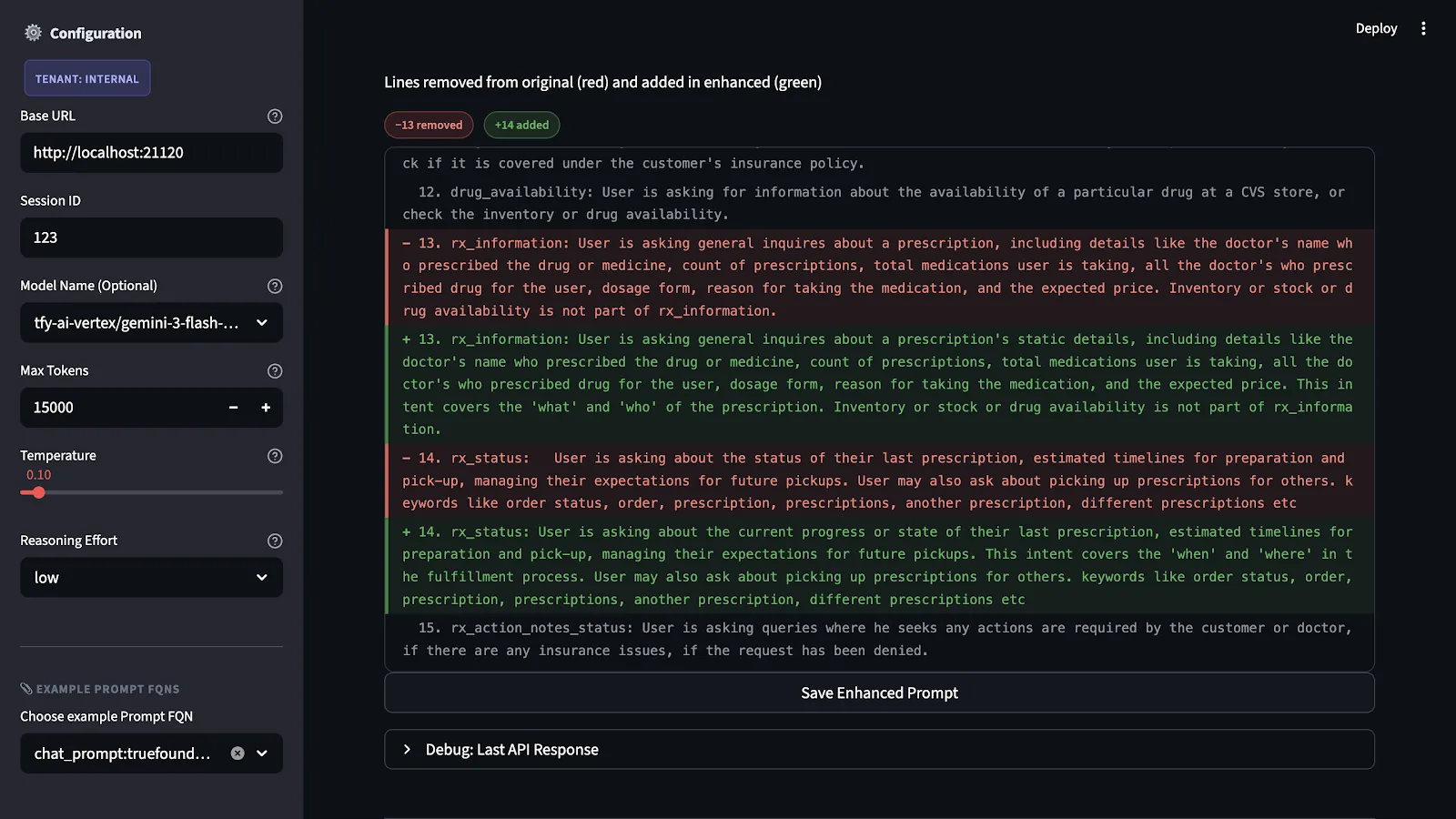
Die erweiterte Eingabeaufforderung wird erst ausgeführt, wenn sie zum ersten Mal getestet wird. Der Test wird anhand eines Benchmark-Datensatzes durchgeführt, der alle möglichen Szenarien und Fehler in Bezug auf die Anwendung abbildet.
Dieser Vorgang ist notwendig, da Änderungen an Eingabeaufforderungen, die theoretisch nützlich erscheinen, zu unbeabsichtigten Problemen bei der Anwendung führen können. Eine Verschärfung der Ausgabespezifikation kann zwar zu unbeabsichtigten Problemen bei der Anwendung führen, da sie in anderen Situationen von der Flexibilität des Modells abhängt. In Kombination mit bestimmten Eingabetypen kann dies jedoch zu Problemen führen.
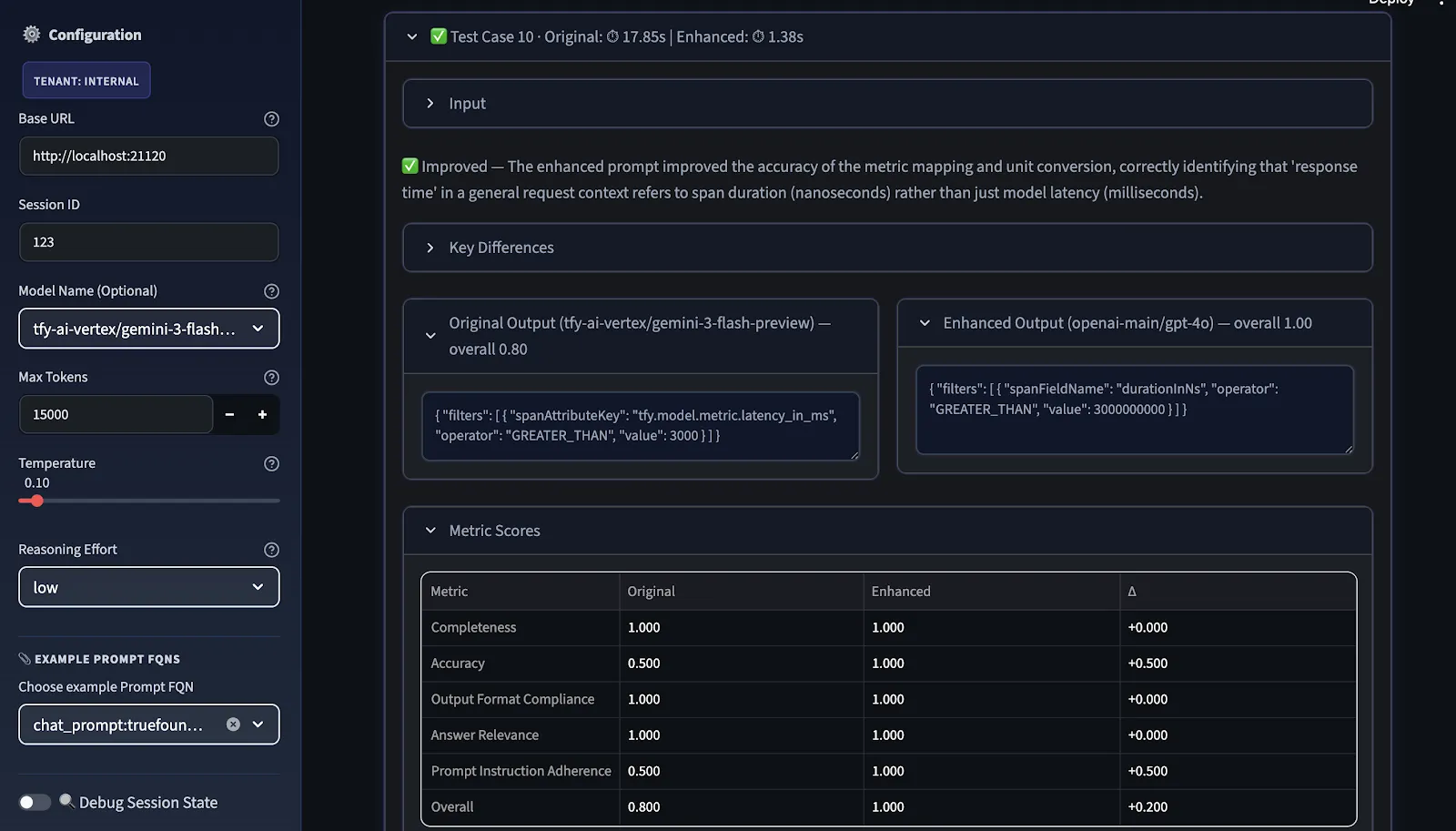
Der letzte Schritt ist das Benchmarking. Wir vergleichen die ursprünglichen und die verbesserten Eingabeaufforderungen in zwei Dimensionen:
Die Gesamtpunktzahl ist das arithmetische Mittel der ausgewählten Metriken; Benutzer können vor der Bewertung relevante Metriken auswählen.
Die Vergleichsansicht zeigt, wo die Verbesserung real ist, wo sie modellspezifisch ist und wo weitere Iterationen erforderlich sind, bevor die Aufforderung als anbieterübergreifend übertragbar betrachtet werden kann.
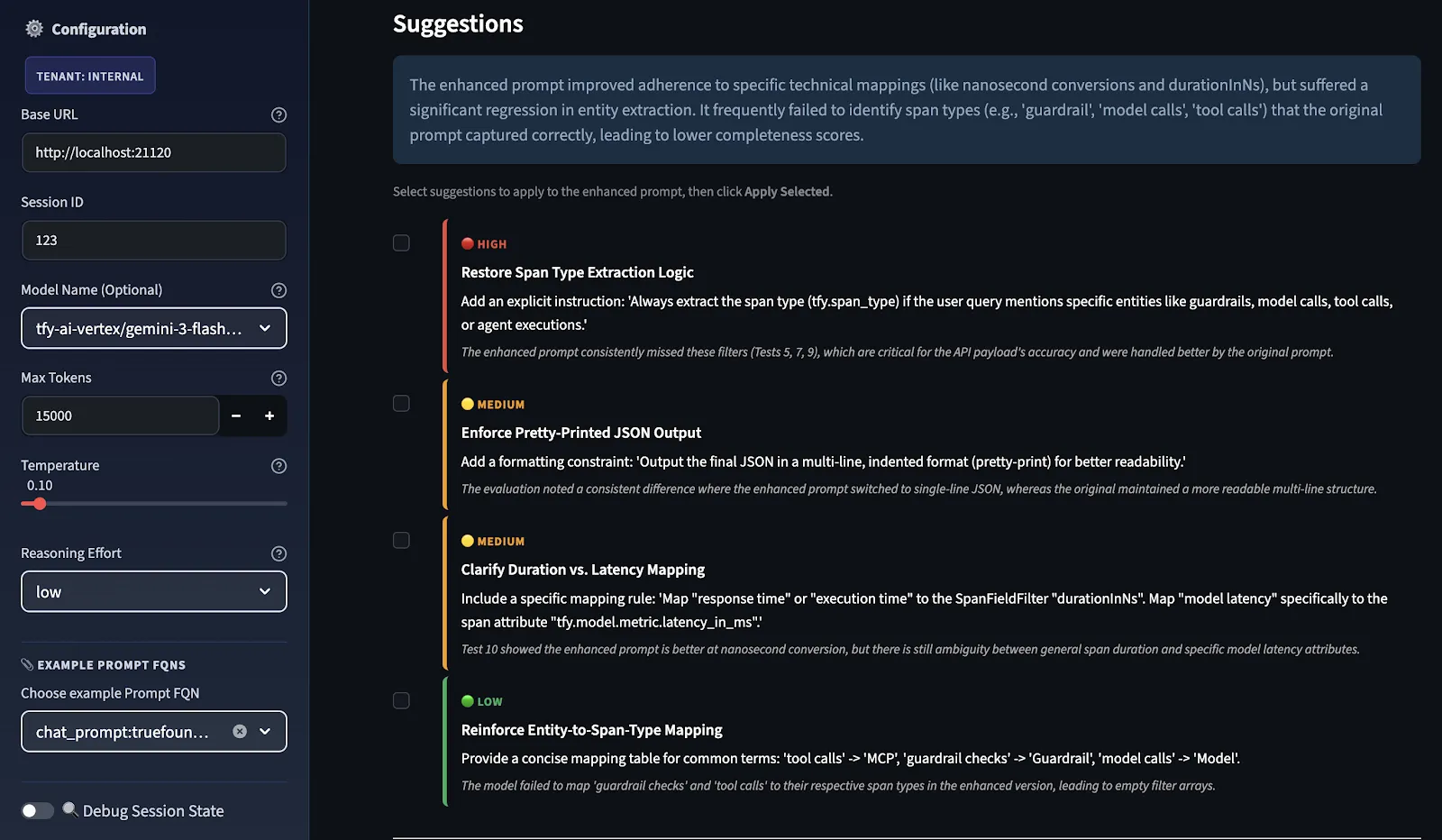
Anschließend bewertet der LLM-Judge beide Eingabeaufforderungen, und Verbesserungsvorschläge werden in der Reihenfolge ihrer Priorität bereitgestellt. Sie werden in die Kategorien HOCH, MITTEL und NIEDRIG eingestuft, je nachdem, wo das Punktedelta zwischen ursprünglich und verbessert am schwächsten war.
Sie wählen aus, welche Vorschläge als Empfehlung verwendet werden sollen, und das System sendet sie über dieselbe Erweiterungspipeline zurück, um eine verfeinerte erweiterte Aufforderung zu erstellen. Diese Feedback-Schleife verbessert den Prompt kontinuierlich, indem er neu bewertet und verfeinert wird.
Dies sind keine allgemeinen Vorschläge; sie sind testfallspezifisch. Der Grund dafür ist, dass das Evaluator-Modell bewertet, wie gut Ihre ursprünglichen und Ihre erweiterten Eingabeaufforderungen in Ihren Testfällen abgeschnitten haben. Diese Vorschläge, die Sie sehen, stehen in direktem Zusammenhang mit dem, was bei Ihrer Testfallbewertung gefehlt hat. Wenn Sie dieser Bewertung weitere Testfälle hinzufügen würden, werden Ihnen möglicherweise andere Vorschläge angezeigt.
Sie können diesen Vorgang beliebig oft wiederholen. In jedem Zyklus wird die zuvor verbesserte Eingabeaufforderung als neue Ausgangsbasis verwendet, sodass Verbesserungen noch verstärkt werden können. Die endgültige, überarbeitete Aufforderung kann direkt von der Benutzeroberfläche heruntergeladen und mithilfe von Das wahre Foundry Gateway.
Wenn wir über Technik sprechen, denken wir oft nicht an etwas. Die Sache ist, dass Modelle wie Gemini, GPT-5, Claude und LLama die Dinge nicht verstehen, die ihnen im Weg stehen. Das liegt daran, dass sie alle darin geschult wurden, aus verschiedenen Informationen zu lernen, und dass sie dazu gebracht wurden, die Dinge ein wenig anders zu machen. Wenn wir sie also etwas fragen, geben sie uns möglicherweise unterschiedliche Antworten. Das liegt nicht daran, dass die Frage schlecht ist. Weil jedes Modell seine eigene Art hat, Dinge zu tun.
Einige Models sind sehr gut darin, die Regeln zu befolgen und das zu tun, was wir sagen. GPT-4-Modelle zum Beispiel könnten sehr wörtlich genommen werden. Lama-Modelle könnten generativer sein. Versuche die Lücken zu füllen. Claude-Modelle könnten gut darin sein, komplizierte Fragen zu beantworten. Andere Modelle könnten besser darin sein, einfache Fragen zu beantworten.
Die einzige Möglichkeit, herauszufinden, wie sich eine Eingabeaufforderung modellübergreifend verhält, besteht darin, sie zu testen. Und die einzige Möglichkeit, diese Tests systematisch zu gestalten, ist ein Evaluierungsworkflow wie dieser.
Sobald Ihre Aufforderung evaluiert, verbessert und getestet wurde, benötigen Sie ein System, das sie im Laufe der Zeit verwaltet. Versionierung, umgebungsspezifische Bereitstellung und die Möglichkeit, fehlerhafte Änderungen rückgängig zu machen, ohne Ihre gesamte Anwendung erneut bereitzustellen.
Hier kommt das AI Gateway von TrueFoundry ins Spiel. TrueFoundry bietet ein zentralisiertes System zur Verwaltung von Eingabeaufforderungen mit integrierter Versionierung. Jede Änderung an einer Aufforderung wird verfolgt, und Sie können mithilfe von für Menschen lesbaren Aliasen wie v1-prod oder v2-staging auf bestimmte Versionen verweisen. Das Gateway löst die Prompt-Version zur Laufzeit auf, was bedeutet, dass für Prompt-Updates keine erneute Codebereitstellung mehr erforderlich ist.
Da der Workflow auf eine Vielzahl von Eingabeaufforderungen und Projekten angewendet wurde, wurden mehrere wichtige Punkte deutlich:
Das Ziel, auf das wir hinarbeiten, ist es, schnelle Qualität so messbar und überprüfbar zu machen wie jeden anderen Teil Ihres Software-Stacks. Das bedeutet automatische Regressionstests für Eingabeaufforderungen, wenn sich die zugrunde liegende Modellversion ändert, eine in Ihre Bereitstellungspipeline integrierte Prompt-Versionierung und Evaluierungs-Dashboards, die einen Überblick über die Leistung von Prompts im Laufe der Zeit geben.
Schnelles Ingenieurwesen wird nicht mehr als Handwerk, sondern als Wissenschaft betrachtet. Organisationen, die es als solches behandeln und einen formalen Prozess für Bewertung, Iteration und Testen implementieren, werden besser in der Lage sein, zuverlässigere KI-Systeme zu entwickeln als Unternehmen, die dies nicht tun. Der in diesem Arbeitsablauf beschriebene Prozess ist ein Versuch, dieses Ziel zu erreichen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




