

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
.webp)
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Die Entwicklung von Modellen ist zwar rationeller geworden, aber die Bereitstellung, Skalierung und Verwaltung von ML-Modellen in der Produktion stellt nach wie vor eine große Hürde dar. Plattformteams sind dafür verantwortlich, dass ML-Modelle nahtlos in mehreren Umgebungen bereitgestellt, überwacht, skaliert und optimiert werden können, während gleichzeitig die Infrastrukturkosten minimiert und die Zuverlässigkeit gewahrt bleibt.
Herkömmliche ML-Bereitstellungsansätze erfordern oft umfangreiches Kubernetes-Fachwissen, manuelles GPU-Ressourcenmanagement und ineffiziente Skalierungsmechanismen, was zu einem hohen Betriebsaufwand für Plattformteams führt. Als Antwort auf diese Herausforderungen bietet TrueFoundry eine ML Deployment as a Service-Lösung an, die darauf ausgelegt ist, die Infrastrukturauswahl zu automatisieren, die Bereitstellung zu vereinfachen, die Leistung zu optimieren und die Beobachtbarkeit zu verbessern.
Für die Bereitstellung von ML-Modellen müssen die richtigen GPU-Instanzen, Modellserver und Kubernetes-Konfigurationen ausgewählt werden. Ohne intelligente Automatisierung müssen Plattformteams Ressourcen manuell zuweisen, was zu fehleranfälligen, zeitaufwändigen Bereitstellungen führt.
Der aktuelle Prozess beinhaltet häufig mehrere Übergaben zwischen Datenwissenschaftlern, ML-Ingenieuren und DevOps-Teams. Plattformingenieure greifen häufig ein, um bei der Konfiguration, Skalierung und Überwachung von Kubernetes zu helfen, was zu Ineffizienzen und Engpässen führt.
Herkömmlichen ML-Bereitstellungen fehlen integrierte GPU-Autoscaling-Mechanismen. Ohne dynamische Skalierung auf der Grundlage von Anfragen pro Sekunde (RPS), Auslastung oder zeitbasierten Triggern wird die Infrastruktur entweder zu wenig ausgelastet (was zu verschwendeten Ausgaben führt) oder zu viel bereitgestellt (was zu Leistungsengpässen führt).
Wählen Sie das effizienteste Modell servieren Der Ansatz erfordert zusammen mit dem richtigen Modellserver (z. B. vLLM, sGLang, Triton, FastAPI, TensorFlow Serving) fundiertes Fachwissen in den Bereichen Leistungsbenchmarking, Speicheroptimierung und Lastenausgleich.
ML-Bereitstellungen generieren Protokolle, Metriken und Ereignisse auf mehreren Plattformen. Die Behebung von Leistungsproblemen oder Ausfällen ist mühsam, da die Protokolle oft verstreut sind, was es für Plattformteams schwierig macht, Probleme schnell zu identifizieren und zu lösen.
Ohne automatische Ressourcenoptimierung müssen Plattformteams inaktive Modelle manuell überwachen und verwalten, was zu unnötigen Cloud-Ausgaben führt. Herkömmliche ML-Bereitstellungsmethoden unterstützen weder automatisches Herunterfahren noch dynamische Skalierung.
Unternehmen benötigen Modell-Upgrades ohne Ausfallzeiten, aber bei herkömmlichen Methoden fehlen fortlaufende Updates, Canary-Releases und Blue-Green-Bereitstellungen. Dadurch steigt das Risiko von Betriebsunterbrechungen bei der Bereitstellung neuer Modellversionen.
TrueFoundry beseitigt diese Herausforderungen durch die Bereitstellung einer vollständig verwaltete ML-Bereitstellungsplattform, aktivierend Self-Service-Bereitstellungen, intelligente Ressourcenauswahl, Kostenoptimierung und verbesserte Beobachtbarkeit. So geht's:
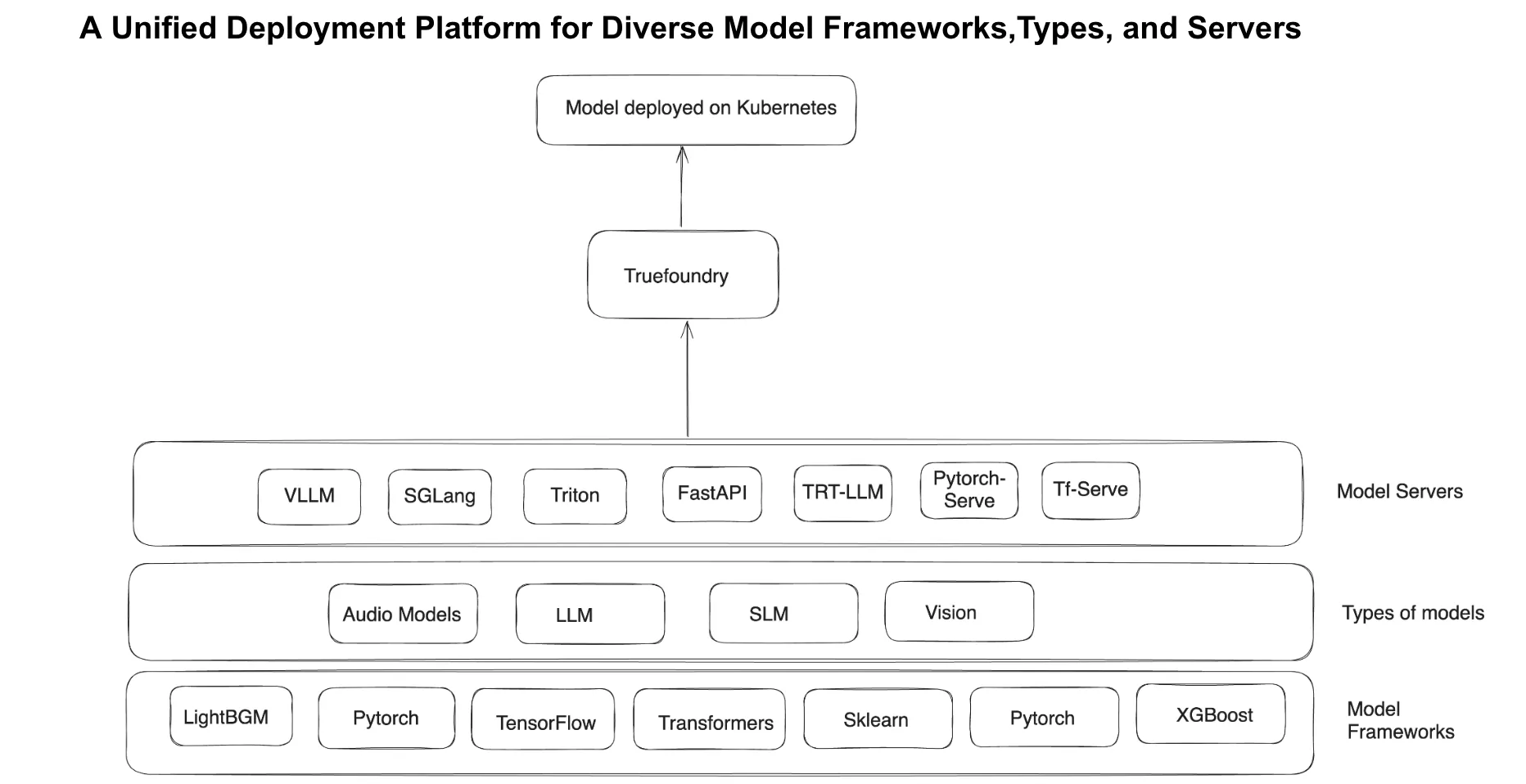
TrueFoundry ermöglicht es Plattformteams, ML-Modelle mit einem einzigen Klick bereitzustellen, sodass kein Kubernetes-Fachwissen erforderlich ist. Die Plattform wählt intelligent die besten Infrastrukturkonfigurationen aus und wählt die optimalen GPU-Instanztypen, Modellserver und Skalierungsstrategien auf der Grundlage der Workload-Anforderungen aus.
Darüber hinaus stellt die GitOps-Integration sicher, dass alle Bereitstellungen automatisiert und reproduzierbar sind, mit integrierter YAML-Generierung für einfache CI/CD-Workflows. Durch die Abstraktion der Komplexität der Infrastruktur ermöglicht TrueFoundry Datenwissenschaftlern und ML-Ingenieuren, Modelle unabhängig voneinander bereitzustellen, wodurch die betriebliche Belastung der Plattformteams verringert wird.
Die fortschrittliche GPU-basierte Autoskalierung von TrueFoundry passt die Ressourcen dynamisch an den Bedarf in Echtzeit an. Modelle werden je nach RPS, GPU-Auslastung oder geplanten Triggern hoch- und herunterskaliert und sorgen so für optimale Leistung und Kosteneffizienz. Die Plattform bietet außerdem:
Darüber hinaus unterstützt TrueFoundry fortschrittliche Bereitstellungsstrategien, einschließlich fortlaufender Updates, Canary-Releases und Blue-Green-Bereitstellungen, sodass Plattformteams neue Modellversionen ohne Ausfallzeiten einführen können.
TrueFoundry bietet zentrale Beobachtbarkeit und bietet Protokolle, Metriken und Ereignisse an einem Ort, wodurch die Effizienz bei der Fehlerbehebung erheblich verbessert wird. Dieses einheitliche Dashboard hilft Plattformteams bei:
Sticky Routing für LLMs erhöht den Durchsatz weiter um 50% und gewährleistet so eine effiziente Bearbeitung von Anfragen, während die Modellkatalogunterstützung (derzeit in Hugging Face integriert) eine einfache Möglichkeit bietet, Modellversionen und Registries zu verwalten.
Darüber hinaus optimieren die automatisierten Infrastrukturvorschläge von TrueFoundry die CPU-, Speicher- und Autoscaling-Konfigurationen auf der Grundlage von Verkehrsmustern und optimieren so das Bereitstellungsmanagement weiter.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




