

July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Da große Sprachmodelle (LLMs) die Art und Weise, wie Anwendungen erstellt werden, weiter verändern, einschließlich KI-Copiloten und Chat-Schnittstellen für Unternehmen, besteht ein wachsender Bedarf an strukturierter Infrastruktur und Prozessen, um diese effizient zu verwalten. Diese neue Disziplin ist als LLMOPs bekannt. Ähnlich wie MLOps traditionelle Workflows für maschinelles Lernen diszipliniert hat, konzentriert sich LLMops auf die Lösung der einzigartigen betrieblichen Herausforderungen, die mit der Arbeit mit Basismodellen im großen Maßstab verbunden sind.
LLMops ist nicht darauf beschränkt, ein Modell über eine API bereitzustellen. Es umfasst den gesamten Lebenszyklus, einschließlich zeitnaher Entwicklung, Feinabstimmung, erweiterter Generierung (Retrieval-Augmented Generation, RAG), Versionskontrolle, Leistungsüberwachung, Kostenoptimierung und Durchsetzung sicherer Zugriffsrechte. Aufgrund der Größe und Komplexität von LLMs ist eine dedizierte Architektur erforderlich, um zuverlässige, skalierbare und wartbare Bereitstellungen zu gewährleisten.
Dieser Artikel untersucht die Grundlagen der LLMOps-Architektur. Wir werden die wichtigsten Komponenten aufschlüsseln, Referenzmuster untersuchen, die in realen Systemen verwendet werden, und die Tools hervorheben, die eine schnelle Entwicklung und Steuerung unterstützen. Ganz gleich, ob Sie einen Assistenten für den Kundensupport, eine Engine zum Abrufen von Wissen oder eine KI-gestützte Agentenplattform entwickeln, das Verständnis der LLMOPS-Architektur ist für die Entwicklung effizienter, skalierbarer und produktionsreifer Lösungen unerlässlich.
LLMOPs Architektur bezieht sich auf das strukturierte Design und den Satz von Komponenten, die zur Verwaltung des Lebenszyklus großer Sprachmodelle in Produktionsumgebungen erforderlich sind. Sie ist die Grundlage, die es Teams ermöglicht, von Experimenten mit LLMs zur Entwicklung skalierbarer, sicherer und wartbarer Anwendungen überzugehen, die auf diesen Modellen basieren.
Im Gegensatz zu herkömmlichen MLOps, die sich hauptsächlich mit strukturierten Datensätzen und Modelltrainingspipelines befassen, müssen LLMOPs einzigartige Herausforderungen wie schnelle Orchestrierung, erweiterte Generierung durch Abruf, umfangreiche Modellversionierung und Inferenzlatenz in Echtzeit berücksichtigen. Die Architektur muss auch dynamische Workloads unterstützen, Routing mit mehreren Modellenund sicherer Zugriff für Benutzer und Teams.
Die LLMOPS-Architektur kombiniert Infrastruktur, Automatisierung und Beobachtbarkeit, um eine zuverlässige Bereitstellung und Steuerung zu gewährleisten. Sie beinhaltet in der Regel:
Diese Architektur ist so konzipiert, dass sie sowohl vortrainierte Modelle, die als APIs dienen, als auch benutzerdefinierte, fein abgestimmte Modelle unterstützt, die in privaten Umgebungen eingesetzt werden. Da die Nutzung von LLM in allen Domänen zunimmt, wird eine gut strukturierte Architektur für schnelle Iterationen, Kosteneffizienz und das Vertrauen der Benutzer unerlässlich.
Das Verständnis der LLMOPS-Architektur hilft Teams dabei, Systeme zu entwickeln, die skalierbar sind und gleichzeitig flexibel, konform und auf die tatsächlichen Geschäftsergebnisse ausgerichtet sind.
Die LLMOPS-Architektur bietet Struktur und Skalierbarkeit für den Einsatz großer Sprachmodelle. Im Gegensatz zu herkömmlichen MLOps befasst sie sich mit einzigartigen Komplexitäten im Zusammenhang mit der schnellen Orchestrierung, den Abruf-Pipelines und dem Modellverhalten zur Laufzeit. Eine robuste Architektur verbindet mehrere Kernschichten, von denen jede eine wichtige Funktion erfüllt.
Verwaltung der Daten
LLMs sind auf vielfältige, qualitativ hochwertige Daten angewiesen, um eine gute Leistung zu erzielen. Diese Komponente umfasst die Beschaffung, Bereinigung, Formatierung und Speicherung umfangreicher Text- oder Dokumentdaten. Für fein abgestimmte Modelle sind möglicherweise auch beschriftete Datensätze erforderlich. Die Versionierung von Daten und die Nachverfolgung der Herkunft sind entscheidend, um die Rückverfolgbarkeit über Modelliterationen hinweg sicherzustellen.
Modellentwicklung
Diese Ebene konzentriert sich auf die Auswahl des Basismodells und die Anwendung von Anpassungen durch Feinabstimmung, Anweisungsoptimierung oder Prompt-Engineering. Benchmarking-Frameworks werden verwendet, um die Leistung verschiedener nachgelagerter Aufgaben zu validieren. Tools wie LoRa und PEFT tragen dazu bei, die Kosten und den Rechenaufwand bei Modellaktualisierungen zu reduzieren.
Inferenz und Einsatz
Für die Bereitstellung von LLMs ist eine skalierbare Infrastruktur erforderlich. Dazu gehören optimierte APIs, Modellquantisierung, Streaming auf Token-Ebene und Autoscaling auf GPUs. Observability-Tools überwachen die Kosten, die Latenz und den Durchsatz der Inferenz. Produktionseinrichtungen umfassen häufig A/B-Tests, Rollback-Strategien und Routing mit mehreren Modellen.
Sicherheit und Compliance
LLMOPs müssen Sicherheitsanforderungen auf Unternehmensebene erfüllen. Verschlüsselung, Zugriffskontrolle, Datenpseudonymisierung und Prüfprotokolle sind unerlässlich, um Compliance-Standards wie HIPAA, GDPR oder SOC 2 zu erfüllen.
Unternehmensführung und verantwortungsvolle KI
Diese Ebene verwaltet die schnelle Versionierung, das Halluzinations-Tracking und die Erkennung von Verzerrungen. Durch das Protokollieren aller Interaktionen und das Anwenden von Filtern nach schädlichen Inhalten wird ein ethisches und konsistentes Verhalten bei der Produktion gewährleistet.
Bewährte Verfahren und Zukunftsfähigkeit
Effektive LLMOPs umfassen modulare Pipelines, Bewertungsschleifen und schnelle Rückverfolgbarkeit. Mit Blick auf die Zukunft werden die Architekturen weiterentwickelt, um den Abruf in Echtzeit, die kontinuierliche Feinabstimmung und die Koordination mehrerer Agenten zu unterstützen.
Durch die Abstimmung dieser Komponenten können Teams LLM-Anwendungen bereitstellen, die robust, anpassungsfähig und unternehmenstauglich sind.
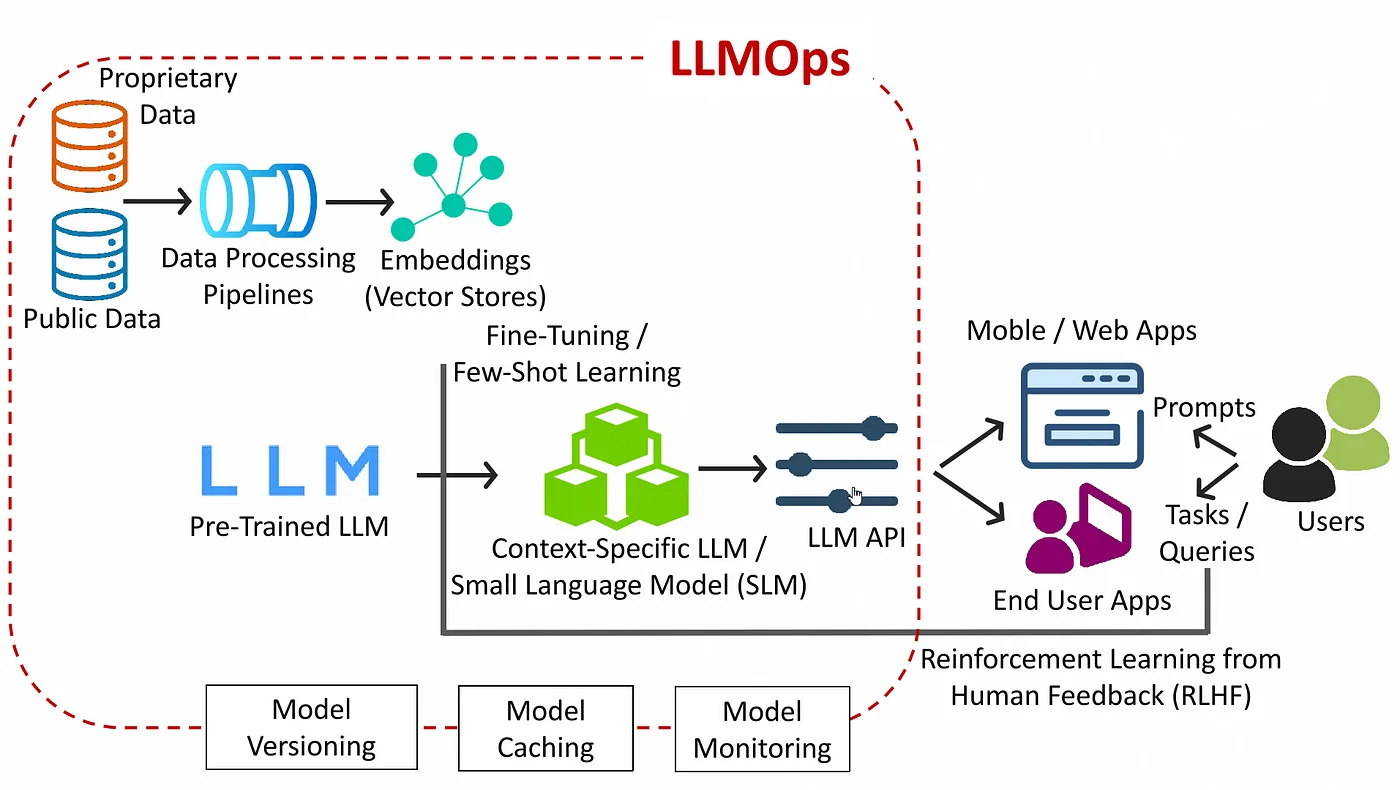
Dieses Bild stellt eine moderne LLMOPS-Architektur vor, die die gesamte Pipeline von der Rohdatenaufnahme über die Produktionsbereitstellung bis hin zur Benutzerinteraktion und zum feedback-gesteuerten Lernen abdeckt. Es zeigt, wie große Sprachmodellsysteme in der realen Welt in Teams und Umgebungen aufgebaut und verwaltet werden.
Datenerhebung und -verarbeitung: Die Architektur beginnt mit öffentlichen und proprietären Datenquellen. Dazu können Textkorpora, Dokumente, CRM-Daten, interne Wissensdatenbanken oder Kundengespräche gehören. Alle Daten durchlaufen eine Datenverarbeitungspipeline, in der sie für nachgelagerte Aufgaben bereinigt, normalisiert und angereichert werden. Dazu gehört auch die Konvertierung von Text in Vektoreinbettungen, die in Vektordatenbanken oder Einbettungsspeichern für einen schnellen Abruf auf Grundlage der Ähnlichkeit gespeichert werden.
Modellauswahl und Anpassung: Ein vortrainiertes LLM (wie GPT, LLama oder Falcon) wird als Basismodell ausgewählt. Durch Feinabstimmung oder Lernen in wenigen Schritten erstellen die Teams ein kontextspezifisches LLM- oder Small Language Model (SLM), das auf ihre Domäne oder ihren Anwendungsfall zugeschnitten ist. Dies ermöglicht eine bessere Abstimmung auf die spezifische Sprache, den Tonfall, die Aufgaben und die Datenstruktur, die für die Anwendung relevant sind.
LLM-Gateway
Das Herzstück der Architektur ist das LLM Gateway. Es bietet eine einheitliche API-Oberfläche für alle Modellendpunkte und übernimmt Authentifizierung, Routing, Batching und Protokollübersetzung. Das Gateway setzt Ratenbegrenzungen und Kontingente durch, wendet Vorlagen für Eingabeaufforderungen an und orchestriert das Fallback- oder A/B-Routing zwischen Modellversionen. Es erfasst außerdem detaillierte Metriken zu Anzahl, Latenzen und Fehlerraten von Anfragen, bevor Anrufe an die Inferenzschicht weitergeleitet werden.
LLM-API-Bereitstellung: Das benutzerdefinierte Modell wird über eine LLM-API bereitgestellt, die als primäre Schnittstelle für Anwendungen dient. Diese APIs sind für die Interaktion in Echtzeit konzipiert und ermöglichen die Inferenzoptimierung durch Batching, Quantisierung und Latenzkontrolle. Die Architektur umfasst auch Modell-Caching zur Reduzierung von Redundanz und Modellüberwachung, um Zuverlässigkeit und Kosteneffizienz zu gewährleisten.
Benutzeranwendungen und Feedback-Schleife
Mobil- und Webclients senden Eingabeaufforderungen an das Gateway, erhalten generierte Antworten und präsentieren sie den Endbenutzern. Interaktionsdaten werden für das RLHF- oder Offline-Training erfasst, wodurch sich der Kreis der kontinuierlichen Modellverbesserung schließt.
Unternehmensführung und Lebenszyklusmanagement: Die Architektur umfasst zentrale Betriebsfunktionen wie Modellversionierung, Audit-Trails, schnelle Nachverfolgung und sichere Zugriffsrichtlinien. Diese stellen sicher, dass LLM-Systeme im Laufe der Zeit reproduzierbar, interpretierbar und konform bleiben.
Dieses Diagramm erfasst effektiv den gesamten Lebenszyklus der LLM-Bereitstellung und -Optimierung innerhalb einer LLMOPS-Pipeline für die Produktion.
Die LLMOPS-Architektur beginnt damit, dass öffentliche und proprietäre Daten durch Verarbeitungspipelines fließen, um Einbettungen zu generieren, die in Vektordatenbanken gespeichert werden. Ein vorab trainiertes großes Sprachmodell wird dann durch Lernen in wenigen Schritten fein abgestimmt oder angepasst, um ein kontextspezifisches Modell zu erstellen. Dieses Modell wird hinter einer optimierten LLM-API eingesetzt, die Mobil- und Webanwendungen in Echtzeit bereitstellt. Benutzer interagieren mit diesen Anwendungen, indem sie Aufforderungen senden und intelligente Antworten erhalten. Das Feedback aus Benutzerinteraktionen wird durch Reinforcement Learning from Human Feedback (RLHF) genutzt, während Modellversionierung, Caching und Überwachung die Systemleistung, Rückverfolgbarkeit und Steuerung sicherstellen.
Die LLMOps-Architektur ist keine Universallösung. Je nach Umfang, Fachgebiet und regulatorischen Anforderungen des Unternehmens ergeben sich unterschiedliche Muster, um LLMs effektiv zu operationalisieren. Diese Muster helfen Teams dabei, Leistung, Kosten, Unternehmensführung und Entwicklungsgeschwindigkeit in Einklang zu bringen. Im Folgenden finden Sie einige häufig verwendete Referenzmuster in realen Bereitstellungen.
API-zentrierte LLM-Bereitstellung
Dies ist das gängigste Muster für Teams in der Frühphase oder für einfache Anwendungsfälle. Ein vorab trainiertes oder fein abgestimmtes LLM wird hinter einer REST-API gehostet, und nachgelagerte Anwendungen stellen synchrone Anfragen. Die Vorlagen für Aufforderungen sind versioniert und es wird eine minimale Orchestrierung verwendet. Dieses Muster ist einfach zu implementieren und eignet sich gut für die Generierung von Inhalten, Zusammenfassungen oder einfache Chat-Benutzeroberflächen.
RAG-Muster (Retrieval-Augmented Generation)
Diese Architektur wird in wissensintensiven Umgebungen verwendet und kombiniert ein LLM mit einer Vektordatenbank, die kontextrelevante Informationen abruft. Die Eingaben werden zunächst durch eingebettete Abfragen aus internen oder externen Wissensdatenbanken angereichert und dann an das LLM weitergegeben. Dieses Muster verbessert die sachliche Grundlage und die Domänenspezifität. Es ist ideal für den Kundensupport, die Analyse von Rechtsdokumenten oder die Unternehmenssuche.
LLM + Workflow-Orchestrierungsmuster
In komplexeren Systemen werden LLMs mithilfe von Orchestrierungs-Frameworks wie LangChain, LangGraph oder Airflow in größere Workflows eingebettet. In diesen Architekturen sind mehrere Schritte miteinander verknüpft: Abrufen, Formatieren von Eingabeaufforderungen, Inferenz, Nachbearbeitung und Aktionsauslöser. Dies ermöglicht dynamische Entscheidungsfindung, Systeme mit mehreren Agenten und die autonome Ausführung von Aufgaben. Es wird in agentischer KI, KI-Copiloten und Multiturn-Anwendungen eingesetzt.
Fein abgestimmtes privates LLM-Muster
Für stark regulierte Branchen oder Anwendungsfälle mit sensiblen Daten können Unternehmen Open-Source-LLMs optimieren und sie in ihrer eigenen Infrastruktur oder VPC hosten. Die Architektur umfasst Datenanonymisierung, Feinabstimmung von Pipelines, isolierte Inferenzumgebungen sowie vollständige Überwachung und Zugriffskontrolle. Dieses Muster ist in den Bereichen Gesundheitswesen, Finanzen und Verteidigung weit verbreitet.
Hybrides Cloud-Edge-Muster
Dieses Muster, das in Edge-KI-Szenarien auftaucht, hält das Haupt-LLM in der Cloud, überträgt jedoch Light-Modelle oder Prompt-Verarbeitungslogik auf Edge-Geräte. Es reduziert die Latenz und die Bandbreitennutzung und sorgt gleichzeitig dafür, dass sensible Daten lokal gespeichert werden. Es wird zunehmend für IoT-, Automobil- und mobile Erlebnisse eingesetzt.
Diese Muster spiegeln die Flexibilität und Anpassungsfähigkeit von LLMOPs wider und bieten Wege zu
Das LLMOPS-Ökosystem wächst rasant und kein einziges Tool kann alle Anforderungen abdecken. Leistungsstarke Teams erstellen modulare Stacks, die auf ihre Infrastruktur und Arbeitsabläufe abgestimmt sind. TrueFoundry ist das Herzstück vieler Stacks für Unternehmen und spielt eine zentrale Rolle, da es Unterstützung auf allen Ebenen der Bereitstellung, Beobachtbarkeit, Orchestrierung und Automatisierung bietet. Im Folgenden finden Sie eine Aufschlüsselung der wichtigsten Ebenen und der Tools, die sie unterstützen.
1. Daten- und Einbettungsschicht
Diese Ebene kümmert sich um die Bereinigung, Transformation, Aufschlüsselung und Einbettung von Daten für die Generierung mit Abruf (Retrieval-Augmented Generation, RAG). Sie ermöglicht es LLMs, kontextsensitiv zu arbeiten.
Diese Tools ermöglichen es Modellen, zum Zeitpunkt der Inferenz relevante Informationen abzurufen, wodurch die Faktenbasis und die Outputqualität verbessert werden.
2. Modellbereitstellungs- und Inferenzschicht
Dies ist das Rückgrat des LLMOPS-Stacks. Es enthält die Komponenten, die für das effiziente Hosten und Bereitstellen von Modellen, die Verwaltung der GPU-Nutzung und die Skalierung von APIs erforderlich sind.
Diese Ebene stellt sicher, dass LLM-Antworten schnell und kostengünstig bereitgestellt werden, auch wenn der Produktionsverkehr stattfindet.
3. Ebene für Eingabeaufforderung und Orchestrierung
Diese Ebene verwaltet Vorlagen für Aufforderungen, Agentenabläufe und dynamische Interaktionen. Sie hilft dabei, Logik weiterzuleiten und mehrstufige Prozesse innerhalb von LLM-Anwendungen zu verketten.
Eine schnelle Orchestrierung gibt Teams die Kontrolle darüber, wie sich LLMs in komplexen Geschäftsanwendungsfällen verhalten.
4. Überwachungs-, Feedback- und Steuerungsebene
Zuverlässigkeit, Transparenz und Ethik erfordern robuste Überwachungs- und Steuerungssysteme. Diese Ebene erfasst Ergebnisse, Benutzerfeedback und Leistungskennzahlen.
5. Arbeitsablauf- und Automatisierungsebene
Diese letzte Ebene verwaltet Schulung, Bewertung, Bereitstellungsautomatisierung und CI/CD. Sie ermöglicht nachvollziehbare, wiederholbare Workflows, die eine iterative Entwicklung unterstützen.
Wenn diese Tools auf mehreren Ebenen ausgerichtet sind, verwandeln sie LLMOPs von verstreuten Experimenten in eine wiederholbare, skalierbare technische Disziplin. Anstatt sich auf eine einzige Komplettlösung zu verlassen, stellen moderne Teams zusammensetzbare Stacks zusammen, die ihren Infrastruktur-, Skalierungs- und Compliance-Anforderungen entsprechen.
Der Schlüssel liegt in der Interoperabilität, der Auswahl von Tools, die sich reibungslos integrieren, wichtige Phasen automatisieren und Transparenz über den gesamten Modelllebenszyklus hinweg bieten. Mit dem richtigen Stack können sich LLMs von Prototypen zu serienreifen Systemen entwickeln, die zu aussagekräftigen Geschäftsergebnissen führen.
LLMops entwickelt sich schnell zu einer grundlegenden Disziplin für Teams, die Anwendungen entwickeln, die auf großen Sprachmodellen basieren. Da sich LLMs von experimentellen Anwendungen hin zu produktionskritischen Systemen verlagern, benötigen Unternehmen eine strukturierte Architektur, spezielle Tools und wiederholbare Workflows, um Komplexität, Kosten und Leistung zu bewältigen. Eine gut durchdachte LLMOps-Architektur beschleunigt nicht nur die Bereitstellung, sondern gewährleistet auch die ethische Ausrichtung, Datenverwaltung und kontinuierliche Verbesserung durch Feedback.
Durch den Einsatz modularer Tools auf den Ebenen Datenmanagement, Inferenz, Orchestrierung und Überwachung gewinnen Teams an Flexibilität und Kontrolle über jeden Aspekt des LLM-Lebenszyklus. Egal, ob Sie ein Open-Source-Modell bereitstellen oder ein proprietäres Modell optimieren, skalierbare LLMOps-Praktiken sind das Rückgrat nachhaltiger KI-Systeme.
Die Zukunft von LLMOPs liegt in seiner Fähigkeit, mit der schnellen Modellentwicklung, neuen Risiken und der wachsenden Unternehmensnachfrage Schritt zu halten. Für Unternehmen, die bereit sind, verantwortungsbewusst zu skalieren, ist die Investition in die LLMOps-Architektur nicht mehr optional, sondern ein strategischer Vorteil.
Eine LLMOps-Architektur ist das strukturelle Framework, das entwickelt wurde, um den gesamten Lebenszyklus großer Sprachmodelle in einer Produktionsumgebung zu verwalten. Sie bietet die notwendige Infrastruktur für die Datenaufnahme, die schnelle Versionierung und die Modellorchestrierung, sodass KI von einfachen Experimenten zur zuverlässigen Bereitstellung im Unternehmen übergeht. Diese Architektur stellt sicher, dass Anwendungen auch bei ihrer Weiterentwicklung skalierbar, sicher und wartbar bleiben.
Eine LLMOPS-Architektur besteht aus mehreren kritischen Ebenen: Vektordatenbanken für den RAG-basierten Kontext, Prompt-Management-Systeme für die Versionskontrolle und einem zentralisierten KI-Gateway für die Modellbereitstellung. Darüber hinaus muss sie Observability-Module zur Überwachung der Latenz und der Token-Nutzung sowie Feinabstimmungs-Pipelines für spezielle Aufgaben enthalten. TrueFoundry vereint diese Komponenten auf einer einzigen Steuerungsebene und vereinfacht so die Komplexität der Verwaltung eines fragmentierten KI-Stacks.
Der Hauptunterschied in der LLMOPS-Architektur ist der Übergang von trainingsintensiven Workflows zu orchestrierungsintensiven Pipelines. Während sich herkömmliche MLOps auf die Erstellung benutzerdefinierter Modelle und Feature-Engineering konzentrieren, priorisiert LLMops die Verwaltung vorab trainierter Basismodelle durch Prompt Engineering and Retrieval-Augmented Generation (RAG). TrueFoundry bietet eine Plattform, die beide Paradigmen unterstützt und es Teams ermöglicht, auf generative KI umzusteigen, ohne etablierte Betriebsstandards aufzugeben.
Zu den Standardtools innerhalb einer LLMOPS-Architektur gehören Vektorspeicher wie Pinecone oder Weaviate, Orchestrierungs-Frameworks wie LangChain und spezielle Monitoring-Suites. Wenn diese jedoch als separate Einheiten verwaltet werden, entstehen häufig Integrationssilos. TrueFoundry fungiert als umfassende Orchestrierungsebene und bietet die notwendige Infrastruktur, um Modellbereitstellungen, geheime Rotationen und kostenbewusstes Routing über alle Cloud-Anbieter hinweg zu verwalten.
TrueFoundry ist eine ideale Plattform für die LLMOPS-Architektur, da es eine entwicklerorientierte Steuerungsebene bietet, die nativ in Ihrer eigenen sicheren Cloud-Umgebung ausgeführt wird. Es abstrahiert die Komplexität von Kubernetes und der Infrastrukturbereitstellung und bietet gleichzeitig leistungsstarke Gateways und umfassende Beobachtbarkeit. Durch die Speicherung der Daten in Ihrer VPC und die Automatisierung der Ressourcenoptimierung wird sichergestellt, dass die Skalierung von Unternehmens-KI sowohl sicher als auch kostengünstig bleibt.
Die LLMOPS-Architektur besteht typischerweise aus mehreren Schichten: der Datenschicht, der Modellschicht, der Anwendungsschicht und der Infrastrukturschicht. Die Datenschicht verwaltet Datensätze, die Modellebene kümmert sich um Training oder Inferenz, die Anwendungsebene integriert KI in Produkte und die Infrastrukturebene unterstützt Bereitstellung, Skalierung, Überwachung und Systemverwaltung.
LLMops umfasst eine strukturierte Versionierung für Eingabeaufforderungen, Modelle und Iterationen zur Feinabstimmung. Die Versionskontrolle gewährleistet die Reproduzierbarkeit, erleichtert das Rollback und ermöglicht Experimente, ohne die Produktionssysteme zu stören. Teams können Verbesserungen verfolgen, die Modellleistung vergleichen und die Einhaltung der Prüf- und behördlichen Anforderungen sicherstellen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.





.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




