

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Die Bereitstellung generativer KI auf der Google Cloud Platform (GCP) erfordert die Orchestrierung einer komplexen Reihe von Grundelementen: Google Kubernetes Engine (GKE), Cloud-TPUs und Scheitelpunkt-KI. GCP liefert zwar die Rohdatenverarbeitung, aber die Einbindung dieser Daten in eine konforme Internal Developer Platform (IDP) erfordert umfangreiche kundenspezifische Entwicklungen.
TrueFoundry fungiert als Infrastruktur-Overlay. Wir kümmern uns um die Orchestrierung, sodass Sie die Kontrolle über die VPC und die Datenresidenz behalten. In diesem Beitrag werden unsere Integrationsmuster mit GCP detailliert beschrieben, insbesondere in Bezug auf die Split-Plane-Architektur. Arbeitslast-Identitätsverbundund TPU-Management.
Wir verwenden eine Split-Plane-Architektur, um die Verwaltungsschnittstelle von Ihrer Workload-Ausführungsumgebung zu isolieren.
Sicherheitsgrenze Wir benötigen keine Firewallregeln für eingehenden Datenverkehr. Der Agent in Ihrem Cluster initiiert einen sicheren, nur ausgehenden WebSocket- oder gRPC-Stream zu unserer Control Plane. Er fragt nach Bereitstellungslisten und überträgt Telemetrie. Ihre VPC bleibt für externen eingehenden Datenverkehr privat.
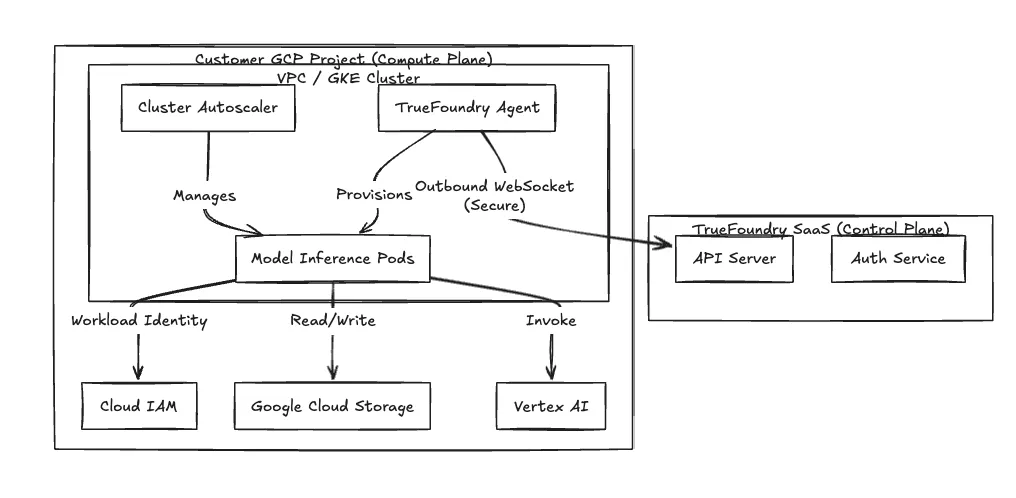
Abbildung 1: Die Split-Plane-Architektur isoliert die Datenverarbeitung innerhalb der Kunden-VPC.
Für eine hohe Leistung konfigurieren wir die zu verwendende Rechenebene VPC-native Cluster unter Verwendung von Alias-IPs. Alle Rechenressourcen befinden sich in privaten Subnetzen.
Ingress (Inferenzanfragen) Der Anwendungsdatenverkehr gelangt in die VPC über Cloud-Lastenausgleich (in der Regel ein Global External ALB). Der ALB beendet TLS und leitet Anfragen an den weiter Istio Ingress-Gateway läuft innerhalb des GKE-Clusters.
Privater Google-Zugang Um die Einhaltung der Vorschriften zu gewährleisten, wird der Datenverkehr zu den Google-APIs (Cloud Storage, Vertex AI) über Privater Google-Zugang. Dadurch wird der Datenverkehr zwischen Inferenz-Pods und GCP-verwalteten Diensten auf dem Google-Netzwerk-Backbone gehalten und das öffentliche Internet umgangen.
Austritt GKE-Worker-Knoten benötigen ausgehenden Zugriff, um Container-Images abzurufen Artefaktregister. Wir leiten diesen Verkehr durch Cloud-NAT an die privaten Subnetze angeschlossen.
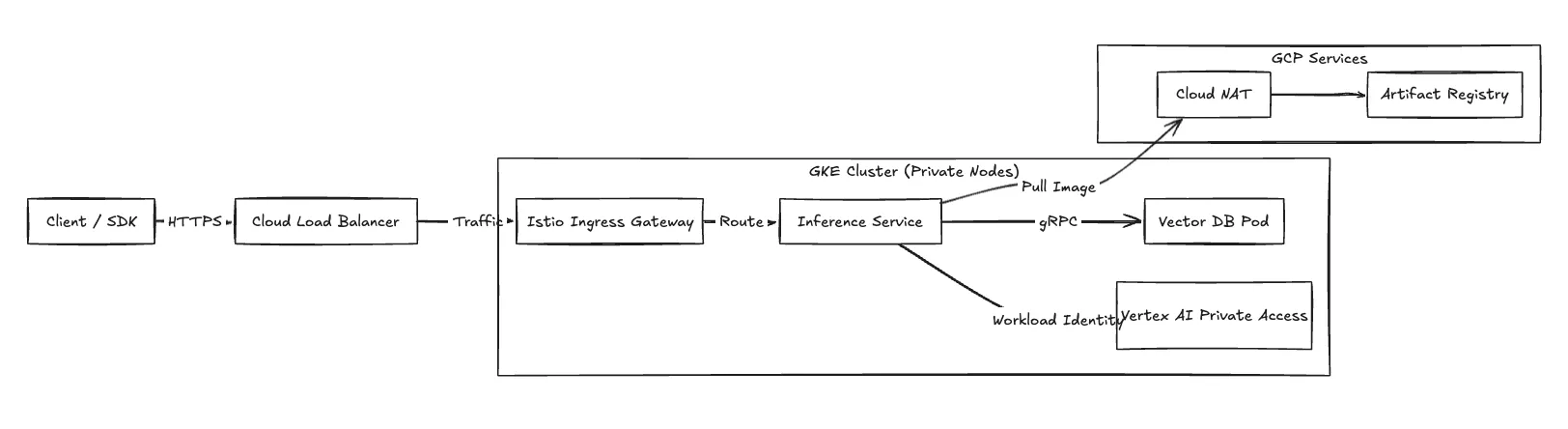
Abbildung 2: Netzwerkverkehrsfluss mit detaillierten Angaben zu eingehender und privater Konnektivität.
Wir erzwingen die Entfernung statischer Dienstkontoschlüssel (.json-Dateien). TrueFoundry implementiert GKE-Workload-Identität für die gesamte Workload-Authentifizierung.
Die Authentifizierungssequenz
Wenn ein Pod kompromittiert ist, ist der Explosionsradius strikt auf die IAM-Rollen beschränkt, die dieser bestimmten GSA zugewiesen wurden.
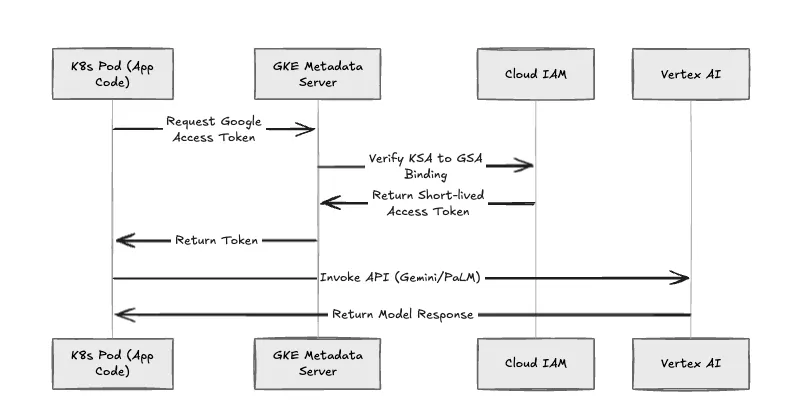
Abbildung 3: Der GKE Workload Identity-Authentifizierungsablauf.
Wir integrieren mit GKE-Knotenpools um NVIDIA-GPUs und Cloud-TPUs zu orchestrieren.
TPU-Orchestrierung Bei der Planung auf TPUs müssen bestimmte Topologieeinschränkungen berücksichtigt werden. TrueFoundry verwaltet den NodeSelector und die Toleranzen, die für die Planung von Pods auf TPU-Slices erforderlich sind (z. B. v4-8, v5e). Wir fügen automatisch die erforderlichen Treiber und Ressourcenbeschränkungen in das Bereitstellungsmanifest ein und abstrahieren so die Kubernetes-Konfiguration auf niedriger Ebene.
Spot-VM-Verwaltung Für Batch-Verarbeitungs- oder Entwicklungsworkloads verwalten wir Spot-VMs um die Kosten zu senken (in der Regel 60-90% im Vergleich zu On-Demand).
Verwaltung verschiedener Schlüssel für Modelle wie Gemini Pro verursacht betrieblichen Aufwand. TrueFoundry bietet ein AI-Gateway, das als einheitliche API-Schnittstelle fungiert.
Diese Integration ermöglicht es Ihrem Team, die Hardwarevorteile von GCP — insbesondere TPUs und Netzwerke mit hohem Durchsatz — voll auszuschöpfen, ohne sich in den betrieblichen Reibungen der reinen Kubernetes-Verwaltung zu verzetteln. TrueFoundry wirkt wie ein Multiplikator für Ihre Infrastruktur: Wir abstrahieren die Komplexität der GKE-Orchestrierung, während Sie die absolute Kontrolle über Sicherheit und Datenspeicherort behalten. Dieses Gleichgewicht ermöglicht es Ihnen, GEnAI-Workloads sofort zu operationalisieren und die Infrastruktur von einer Einschränkung in einen Geschwindigkeitsvorteil im Wettbewerb zu verwandeln.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




